
Maison >développement back-end >Tutoriel Python >Huit boîtes à outils de visualisation Python populaires, laquelle préférez-vous ?
Huit boîtes à outils de visualisation Python populaires, laquelle préférez-vous ?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-11 23:43:212222parcourir

Bonjour à tous, je suis une technologie d'intelligence artificielle Python
Les amis qui aiment utiliser Python pour réaliser des projets seront inévitablement confrontés à cette situation : lors de la création de graphiques, quel type de boîte à outils de visualisation esthétique et pratique faut-il utiliser ? Lorsque de beaux graphiques apparaissent dans des articles précédents, les lecteurs laissent toujours des messages en arrière-plan demandant quel outil a été utilisé pour créer le graphique. Ci-dessous, l'auteur présente huit packages d'outils de visualisation implémentés en Python, dont certains peuvent également être utilisés dans d'autres langages. Venez essayer lequel préférez-vous ?
Il existe de nombreuses façons de créer des graphiques en Python, mais quelle est la meilleure méthode ? Avant de procéder à la visualisation, nous devons d'abord clarifier quelques questions sur la cible de l'image : Voulez-vous avoir une compréhension préliminaire de la distribution des données ? Vous voulez impressionner les gens lors de votre présentation ? Peut-être souhaitez-vous montrer à quelqu’un une image intérieure, une image intermédiaire ?
Cet article présentera certains packages de visualisation Python couramment utilisés, y compris les avantages et les inconvénients de ces packages et les scénarios auxquels ils conviennent. Cet article ne s'étend qu'aux graphiques 2D, laissant un peu de place pour la prochaine présentation sur les graphiques 3D et les rapports commerciaux (tableau de bord). Cependant, de nombreux packages dont je parlerai cette fois peuvent bien prendre en charge les graphiques 3D et les rapports commerciaux.
Matplotlib, Seaborn et Pandas
Il y a plusieurs raisons de regrouper ces trois packages : Premièrement, Seaborn et Pandas sont construits sur Matplotlib Lorsque vous utilisez df.plot() dans Seaborn ou Pandas. en fait utilisé du code écrit par quelqu'un d'autre utilisant Matplotlib. Par conséquent, les graphiques sont similaires en termes d’embellissement, et la syntaxe utilisée lors de la personnalisation des graphiques est également très similaire.
Quand il s'agit de ces outils de visualisation, trois mots me viennent à l'esprit : Exploratoire, Données et Analyse. Ces packages sont parfaits pour explorer des données pour la première fois, mais ils ne suffisent pas pour les présentations.
Matplotlib est une bibliothèque de niveau inférieur, mais le niveau de personnalisation qu'elle prend en charge est incroyable (alors ne l'excluez pas simplement du package de démonstration !), mais il existe d'autres outils mieux adaptés aux démonstrations.
Matplotlib permet également la sélection de styles, qui simule des outils d'embellissement populaires tels que ggplot2 et xkcd. Voici un exemple de graphique que j'ai réalisé à l'aide de Matplotlib et des outils associés :
Lors du traitement des données salariales de l'équipe de basket-ball, je voulais trouver l'équipe avec le salaire médian le plus élevé. Pour montrer les résultats, j'ai codé par couleur les salaires de chaque équipe dans un graphique à barres pour illustrer quelle équipe un joueur aurait intérêt à rejoindre.
import seaborn as sns
import matplotlib.pyplot as plt
color_order = ['xkcd:cerulean', 'xkcd:ocean',
'xkcd:black','xkcd:royal purple',
'xkcd:royal purple', 'xkcd:navy blue',
'xkcd:powder blue', 'xkcd:light maroon',
'xkcd:lightish blue','xkcd:navy']
sns.barplot(x=top10.Team,
y=top10.Salary,
palette=color_order).set_title('Teams with Highest Median Salary')
plt.ticklabel_format(style='sci', axis='y', scilimits=(0,0))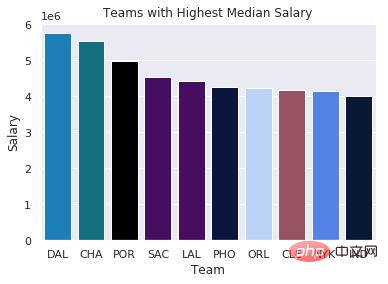
Le deuxième graphique est le tracé Q-Q des résidus de l'expérience de régression. L'objectif principal de ce diagramme est de montrer comment créer un diagramme utile avec le moins de lignes possible, même s'il n'est peut-être pas aussi beau.
import matplotlib.pyplot as plt
import scipy.stats as stats
#model2 is a regression model
log_resid = model2.predict(X_test)-y_test
stats.probplot(log_resid, dist="norm", plot=plt)
plt.title("Normal Q-Q plot")
plt.show()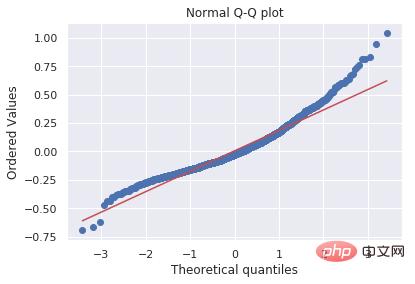
Il s'avère que Matplotlib et ses outils associés sont très efficaces, mais ce ne sont pas les meilleurs outils en termes de présentation.
ggplot(2)
Vous pouvez demander : "Aaron, ggplot est le package de visualisation le plus couramment utilisé dans R, mais ne voulez-vous pas écrire un package Python ?". Les gens ont implémenté ggplot2 en Python, reproduisant tout ce qui concerne ce package, de l'embellissement à la syntaxe.
Dans tous les documents que j'ai consultés, tout ressemble beaucoup à ggplot2, mais la bonne chose à propos de ce package est qu'il repose sur le package Pandas Python. Cependant, le package Pandas Python a récemment rendu obsolète certaines méthodes, ce qui a entraîné des versions Python incompatibles.
Si vous souhaitez utiliser un vrai ggplot dans R (l'apparence, la convivialité et la syntaxe sont les mêmes sauf pour les dépendances), j'en ai discuté dans un autre article.
En d'autres termes, si vous devez utiliser ggplot en Python, alors vous devez installer la version 0.19.2 de Pandas, mais je vous suggère de ne pas baisser la version de Pandas afin d'utiliser un package de traçage de niveau inférieur.
La raison pour laquelle ggplot2 (je pense qu'il inclut également le ggplot de Python) est important est qu'ils utilisent la "grammaire graphique" pour construire des images. Le principe de base est que vous pouvez instancier un graphique, puis ajouter différentes fonctionnalités séparément ; c'est-à-dire que vous pouvez embellir le titre, les axes, les points de données, les lignes de tendance, etc. séparément.
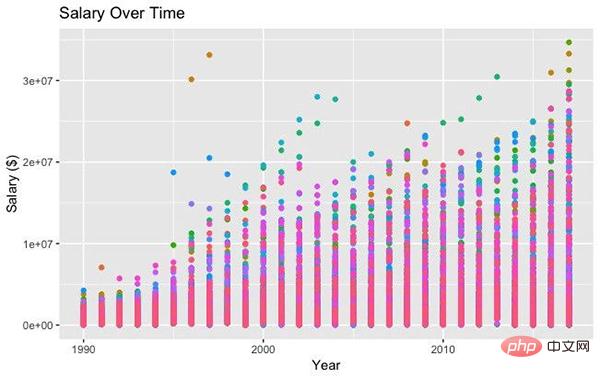
Vous trouverez ci-dessous un exemple simple de code ggplot. Nous instancions d'abord le tracé avec ggplot, définissons les propriétés et les données d'embellissement, puis ajoutons des points, des thèmes et des étiquettes d'axe et de titre. De plus, recherchez le compte public Linux et répondez « git books » en arrière-plan pour obtenir un coffret cadeau surprise.
#All Salaries ggplot(data=df, aes(x=season_start, y=salary, colour=team)) + geom_point() + theme(legend.position="none") + labs(title = 'Salary Over Time', x='Year', y='Salary ($)')
Bokeh
Bokeh 很美。从概念上讲,Bokeh 类似于 ggplot,它们都是用图形语法来构建图片,但 Bokeh 具备可以做出专业图形和商业报表且便于使用的界面。为了说明这一点,我根据 538 Masculinity Survey 数据集写了制作直方图的代码:
import pandas as pd from bokeh.plotting import figure from bokeh.io import show # is_masc is a one-hot encoded dataframe of responses to the question: # "Do you identify as masculine?" #Dataframe Prep counts = is_masc.sum() resps = is_masc.columns #Bokeh p2 = figure(title='Do You View Yourself As Masculine?', x_axis_label='Response', y_axis_label='Count', x_range=list(resps)) p2.vbar(x=resps, top=counts, width=0.6, fill_color='red', line_color='black') show(p2) #Pandas counts.plot(kind='bar')
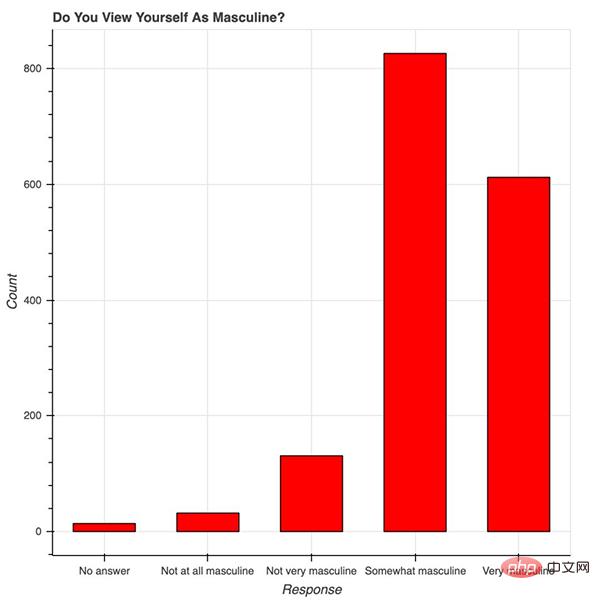
用 Bokeh 表示调查结果
红色的条形图表示 538 个人关于「你认为自己有男子汉气概吗?」这一问题的答案。9~14 行的 Bokeh 代码构建了优雅且专业的响应计数直方图——字体大小、y 轴刻度和格式等都很合理。
我写的代码大部分都用于标记坐标轴和标题,以及为条形图添加颜色和边框。在制作美观且表现力强的图片时,我更倾向于使用 Bokeh——它已经帮我们完成了大量美化工作。
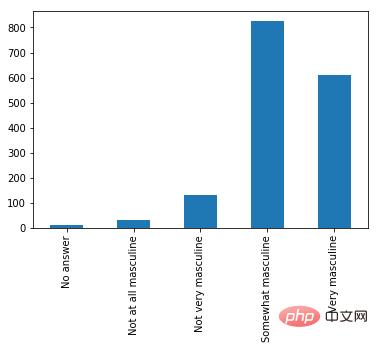
用 Pandas 表示相同的数据
蓝色的图是上面的第 17 行代码。这两个直方图的值是一样的,但目的不同。在探索性设置中,用 Pandas 写一行代码查看数据很方便,但 Bokeh 的美化功能非常强大。
Bokeh 提供的所有便利都要在 matplotlib 中自定义,包括 x 轴标签的角度、背景线、y 轴刻度以及字体(大小、斜体、粗体)等。下图展示了一些随机趋势,其自定义程度更高:使用了图例和不同的颜色和线条。
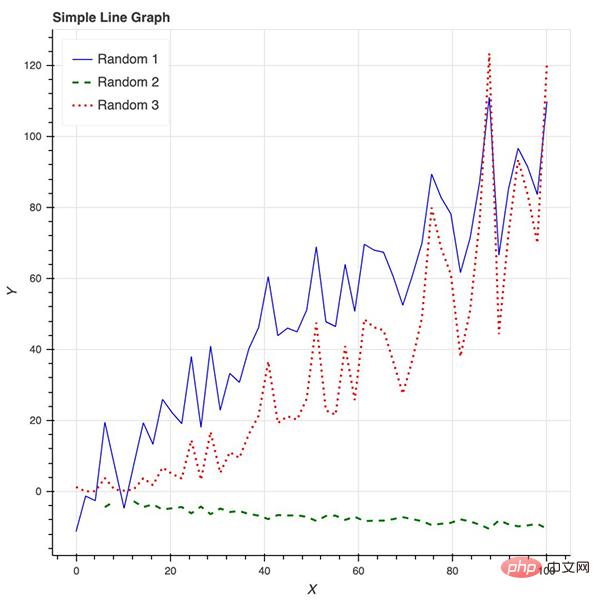
Bokeh 还是制作交互式商业报表的绝佳工具。
Plotly
Plotly 非常强大,但用它设置和创建图形都要花费大量时间,而且都不直观。在用 Plotly 忙活了大半个上午后,我几乎什么都没做出来,干脆直接去吃饭了。我只创建了不带坐标标签的条形图,以及无法删掉线条的「散点图」。Ploty 入门时有一些要注意的点:
- 安装时要有 API 秘钥,还要注册,不是只用 pip 安装就可以;
- Plotly 所绘制的数据和布局对象是独一无二的,但并不直观;
- 图片布局对我来说没有用(40 行代码毫无意义!)
但它也有优点,而且设置中的所有缺点都有相应的解决方法:
- 你可以在 Plotly 网站和 Python 环境中编辑图片;
- 支持交互式图片和商业报表;
- Plotly 与 Mapbox 合作,可以自定义地图;
- 很有潜力绘制优秀图形。
以下是我针对这个包编写的代码:
#plot 1 - barplot # **note** - the layout lines do nothing and trip no errors data = [go.Bar(x=team_ave_df.team, y=team_ave_df.turnovers_per_mp)] layout = go.Layout( title=go.layout.Title( text='Turnovers per Minute by Team', xref='paper', x=0 ), xaxis=go.layout.XAxis( title = go.layout.xaxis.Title( text='Team', font=dict( family='Courier New, monospace', size=18, color='#7f7f7f' ) ) ), yaxis=go.layout.YAxis( title = go.layout.yaxis.Title( text='Average Turnovers/Minute', font=dict( family='Courier New, monospace', size=18, color='#7f7f7f' ) ) ), autosize=True, hovermode='closest') py.iplot(figure_or_data=data, layout=layout, filename='jupyter-plot', sharing='public', fileopt='overwrite') #plot 2 - attempt at a scatterplot data = [go.Scatter(x=player_year.minutes_played, y=player_year.salary, marker=go.scatter.Marker(color='red', size=3))] layout = go.Layout(title="test", xaxis=dict(title='why'), yaxis=dict(title='plotly')) py.iplot(figure_or_data=data, layout=layout, filename='jupyter-plot2', sharing='public') [Image: image.png]
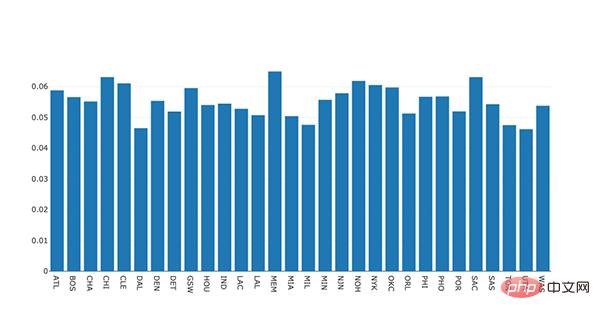
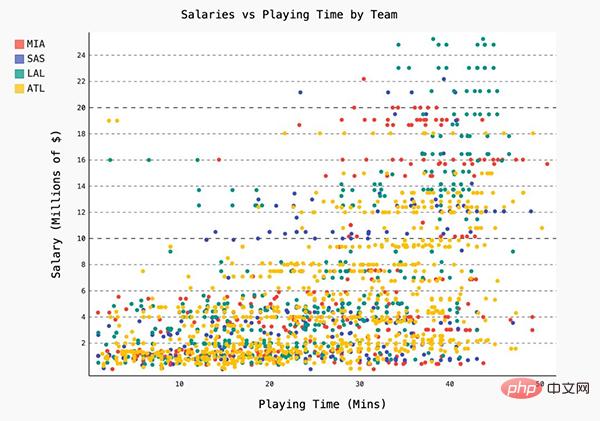
表示不同 NBA 球队每分钟平均失误数的条形图。
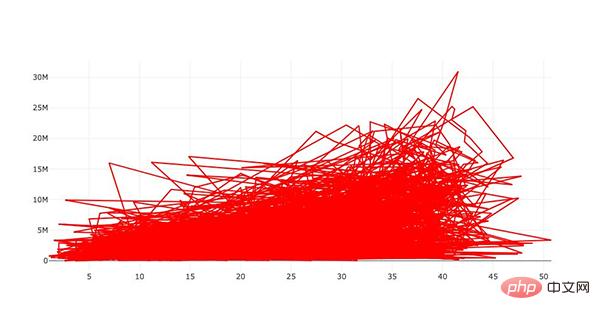
表示薪水和在 NBA 的打球时间之间关系的散点图
总体来说,开箱即用的美化工具看起来很好,但我多次尝试逐字复制文档和修改坐标轴标签时却失败了。但下面的图展示了 Plotly 的潜力,以及我为什么要在它身上花好几个小时:
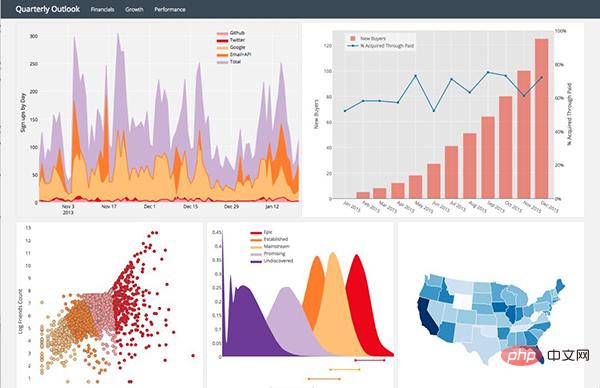
Plotly 页面上的一些示例图
Pygal
Pygal 的名气就不那么大了,和其它常用的绘图包一样,它也是用图形框架语法来构建图像的。由于绘图目标比较简单,因此这是一个相对简单的绘图包。使用 Pygal 非常简单:
- 实例化图片;
- 用图片目标属性格式化;
- 用 figure.add() 将数据添加到图片中。
我在使用 Pygal 的过程中遇到的主要问题在于图片渲染。必须要用 render_to_file 选项,然后在 web 浏览器中打开文件,才能看见我刚刚构建的东西。
最终看来这是值得的,因为图片是交互式的,有令人满意而且便于自定义的美化功能。总而言之,这个包看起来不错,但在文件的创建和渲染部分比较麻烦。
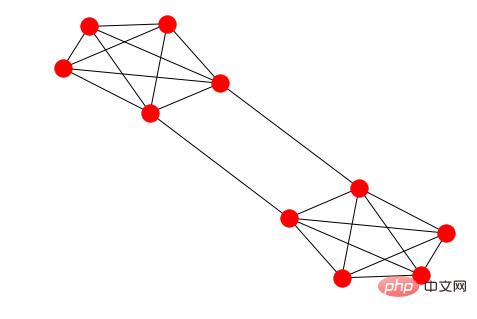
Networkx
虽然 Networkx 是基于 matplotlib 的,但它仍是图形分析和可视化的绝佳解决方案。图形和网络不是我的专业领域,但 Networkx 可以快速简便地用图形表示网络之间的连接。以下是我针对一个简单图形构建的不同的表示,以及一些从斯坦福 SNAP 下载的代码(关于绘制小型 Facebook 网络)。
我按编号(1~10)用颜色编码了每个节点,代码如下:
options = {
'node_color' : range(len(G)),
'node_size' : 300,
'width' : 1,
'with_labels' : False,
'cmap' : plt.cm.coolwarm
}
nx.draw(G, **options)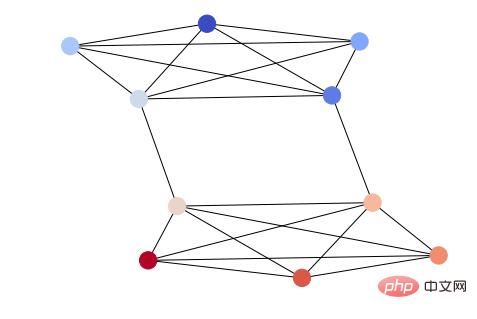
用于可视化上面提到的稀疏 Facebook 图形的代码如下:
import itertools
import networkx as nx
import matplotlib.pyplot as plt
f = open('data/facebook/1684.circles', 'r')
circles = [line.split() for line in f]
f.close()
network = []
for circ in circles:
cleaned = [int(val) for val in circ[1:]]
network.append(cleaned)
G = nx.Graph()
for v in network:
G.add_nodes_from(v)
edges = [itertools.combinations(net,2) for net in network]
for edge_group in edges:
G.add_edges_from(edge_group)
options = {
'node_color' : 'lime',
'node_size' : 3,
'width' : 1,
'with_labels' : False,
}
nx.draw(G, **options)
这个图形非常稀疏,Networkx 通过最大化每个集群的间隔展现了这种稀疏化。
有很多数据可视化的包,但没法说哪个是最好的。希望阅读本文后,你可以了解到在不同的情境下,该如何使用不同的美化工具和代码。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!