
Maison >Périphériques technologiques >IA >BERT peut-il également être utilisé sur CNN ? Les résultats de recherche de ByteDance sélectionnés pour ICLR 2023 Spotlight
BERT peut-il également être utilisé sur CNN ? Les résultats de recherche de ByteDance sélectionnés pour ICLR 2023 Spotlight

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-11 23:04:021342parcourir
Comment exécuter BERT sur un réseau de neurones convolutifs ?
Vous pouvez directement utiliser SparK - Designing BERT for Convolutional Networks: Sparse and Hierarchical Mask Modeling proposé par l'équipe technologique ByteDance, qui a récemment été reconnue par l'intelligence artificielle Inclus dans le document de discussion Spotlight :

Lien papier :
https://www.php.c n/link/e38e37a99f7de1f45d169efcd b288dd1
Code source ouvert :
https://www.php.cn/link/9dfcf16f0adbc5e2a55ef02db36bac7f
C'est aussi le premier succès de BERT sur Réseau de neurones convolutifs (CNN). Ressentons d’abord les performances de SparK en pré-entraînement.
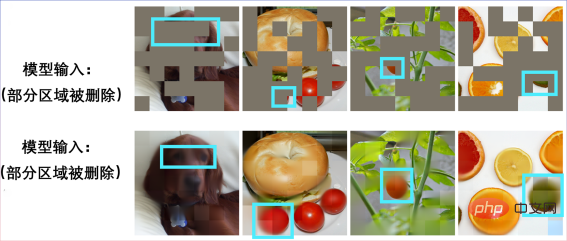
Entrez une photo incomplète :

Restaurer un chiot :

Autre photo incomplète :

Il s'est avéré qu'il s'agissait d'un sandwich bagel :

D'autres scènes peuvent également réaliser une restauration d'image :

BERT et Transformer Un match parfait
"Toute grande action et pensée a un début humble."
Derrière l'algorithme de pré-entraînement BERT se cache une conception simple et profonde. BERT utilise "cloze" : supprimez aléatoirement plusieurs mots dans une phrase et laissez le modèle apprendre à récupérer.
BERT s'appuie fortement sur le modèle de base dans le domaine NLP - Transformer.
Transformer est naturellement adapté au traitement de données de séquence de longueur variable (comme une phrase anglaise), il peut donc facilement faire face à la "suppression aléatoire" de BERT cloze.
CNN dans le domaine visuel veut aussi profiter de BERT : Quels sont les deux défis ?
En regardant l'histoire du développement de la vision par ordinateur, le modèle de réseau neuronal convolutif condense l'essence de nombreux modèles classiques tels que l'équivariance translationnelle, la structure multi-échelle, etc., et peut être décrit comme le pilier du monde du CV. Mais ce qui est très différent de Transformer, c'est que CNN est intrinsèquement incapable de s'adapter aux données qui sont « creusées » par le cloze et pleines de « trous aléatoires », de sorte qu'il ne peut pas profiter des dividendes de la pré-formation BERT à première vue.
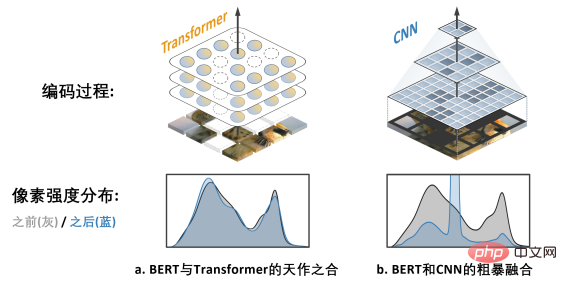
L'image ci-dessus a. montre le travail de MAE (Les auto-encodeurs masqués sont des apprenants visuels évolutifs Puisqu'il utilise le modèle Transformer au lieu du modèle CNN, cela peut être). flexible Gérer les entrées avec des trous est une "correspondance naturelle" avec BERT.
L'image de droite b. montre une manière approximative de fusionner les modèles BERT et CNN - c'est-à-dire "noircir" toutes les zones vides et saisir cette image "mosaïque noire" dans CNN, le résultat peut être imaginé , entraînera de sérieux problèmes de décalage de distribution de l'intensité des pixels et entraînera de très mauvaises performances (vérifiées plus tard). C'est le
challenge 1 qui entrave la réussite de l'application du BERT sur CNN. De plus, l'équipe de l'auteur a également souligné que l'algorithme BERT issu du domaine de la PNL n'a naturellement pas les caractéristiques du « multi-échelle », et la structure pyramidale multi-échelle peut être décrite comme le « gold standard » dans la longue histoire de la vision par ordinateur. Le conflit entre le BERT à échelle unique et le CNN naturel à plusieurs échelles est le
Défi 2. Solution SparK : Modélisation de masques clairsemés et hiérarchiques
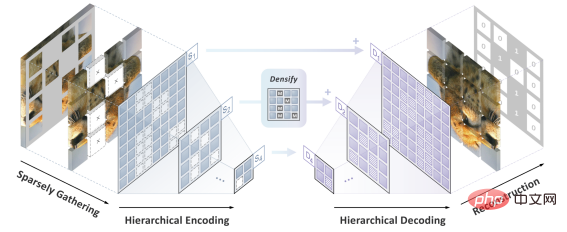
L'équipe d'auteur a proposé SparK (Sparse et h modélisation masquée hiérarchique) pour résoudre les deux défis antérieurs.
Tout d'abord, inspirée par le traitement des données de nuages de points tridimensionnels, l'équipe d'auteurs a proposé de traiter les images fragmentées après opération de masquage (opération d'évidement) comme des nuages de points clairsemés, et d'utiliser une convolution clairsemée sous-variété (Submanifold Sparse Convolution) à coder. Cela permet au réseau convolutif de gérer les images supprimées de manière aléatoire.
Deuxièmement, inspirée par le design élégant d'UNet, l'équipe d'auteurs a naturellement conçu un modèle d'encodeur-décodeur avec des connexions latérales pour permettre aux fonctionnalités multi-échelles de circuler entre plusieurs niveaux du modèle. étalon-or multi-échelle de la vision par ordinateur.
À ce stade, SparK, un algorithme de modélisation de masques clairsemé et multi-échelle adapté aux réseaux convolutifs (CNN), est né.
SparK est
générique : Il peut être directement appliqué à n'importe quel réseau convolutif sans aucune modification de sa structure ni introduction de composants supplémentaires - Qu'il s'agisse du ResNet classique familier ou Avec le récent modèle avancé ConvNeXt, vous pouvez directement bénéficier de SparK. De ResNet à ConvNeXt : améliorations des performances sur trois tâches visuelles majeures
L'équipe d'auteurs a sélectionné deux familles de modèles convolutionnels représentatives, ResNet et ConvNeXt, et les a utilisées dans la classification des images. des tests ont été menés sur des tâches de détection de cibles et de segmentation d’instances.
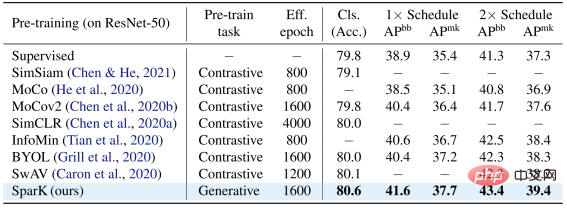
Sur le modèle classique ResNet-50, SparK sert de seul pré-entraînement génératif,
atteint le niveau de pointe :
Sur le modèle ConvNeXt, SparK est toujours en tête . Avant la pré-formation, ConvNeXt était à égalité avec Swin-Transformer ; après la pré-formation, ConvNeXt a largement surpassé Swin-Transformer dans trois tâches :
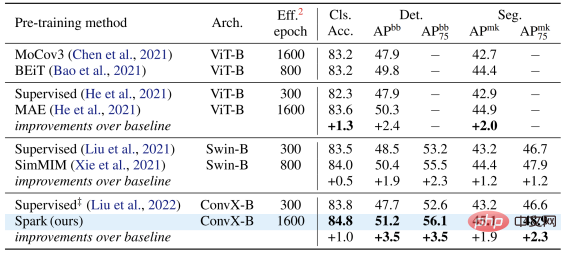
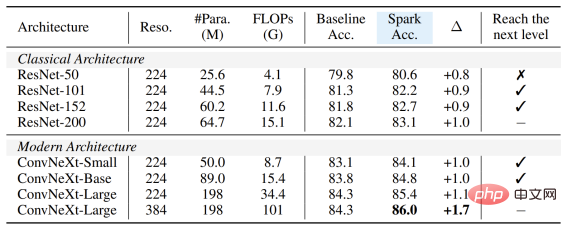
Du petit au grand, dans son intégralité. En vérifiant SparK sur la famille de modèles, vous pouvez observer :
Peu importe que le modèle soit grand ou petit, nouveau ou ancien, vous pouvez bénéficier de SparK, et à mesure que la taille du modèle/les frais généraux de formation augmentent, l'augmentation est encore plus élevée, reflétant la capacité de mise à l'échelle de l'algorithme SparK :
Enfin, l'équipe d'auteur a également conçu une expérience d'ablation de confirmation, à partir de laquelle nous pouvons voir masque clairsemé et Structure hiérarchique Les lignes 3 et 4) sont toutes deux des conceptions très critiques. Une fois manquantes, elles entraîneront une grave dégradation des performances :
.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI