
Maison >développement back-end >Tutoriel Python >Résumé pratique de l'utilisation de Python pour créer rapidement des scripts de test automatisés d'interface
Résumé pratique de l'utilisation de Python pour créer rapidement des scripts de test automatisés d'interface

- 王林avant
- 2023-04-11 22:28:051894parcourir
Introduction aux exigences de test
Habituellement, dans nos projets, nos exigences de test d'interface consistent généralement à construire différentes données de requête, puis à envoyer la requête à l'interface, et après avoir obtenu le retour de l'interface, à extraire et vérifier les champs renvoyés, et enfin stockez les résultats dans un tableau Excel pour une référence facile. L'interface est généralement une requête http ou https, et la structure envoyée est généralement un corps json ou json combiné avec certaines pièces jointes. Les résultats de retour de la requête sont tous au format json. Nos cas de test peuvent être enregistrés dans Excel ou dans une base de données. les résultats peuvent être enregistrés dans la base de données ou exister directement dans Excel, ce qui suit démontera spécifiquement les exigences et présentera le processus de mise en œuvre étape par étape.
Personnalisation du corps de la requête et envoi de la requête
Construire le contenu de la requête envoyé à chaque fois et envoyer automatiquement la requête à l'interface est au cœur de la construction du script de test automatisé. Nous implémentons cette étape principalement en utilisant la bibliothèque de requêtes de python. Faisons-le en détail ci-dessous.
1. Envoyez une simple demande de publication http
Avant d'envoyer la demande, nous devons clarifier le corps de la demande. Notre corps est json. Le contenu spécifique est le suivant :
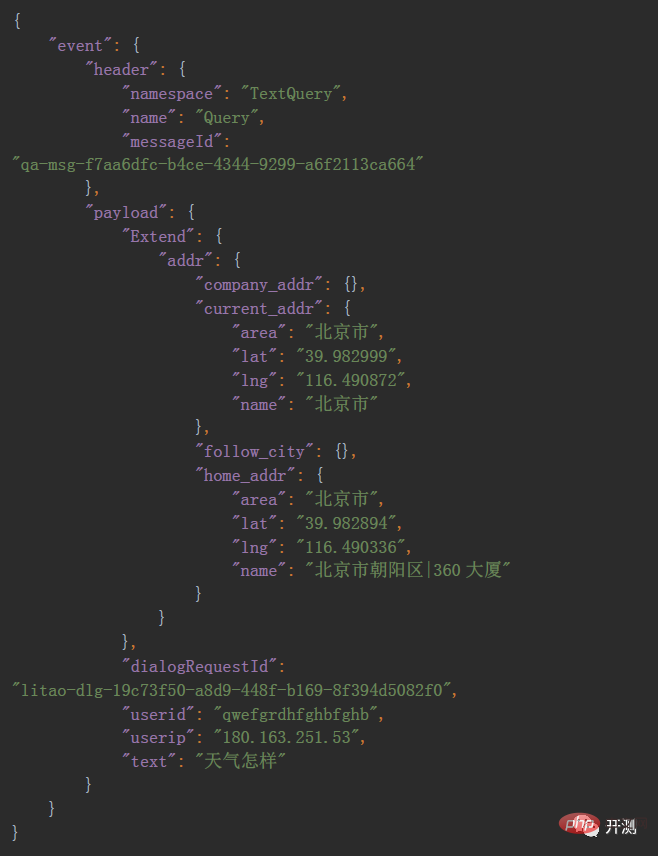
Nous pouvons l'enregistrer en tant que fichier. Fichier text.json comme modèle En tant que modèle, il peut être lu directement pour préparer la construction ultérieure du corps de la requête. Nous pouvons gérer cette étape comme ceci. Avec l'aide du package yaml, nous pouvons convertir json en dictionnaire, ou nous pouvons utiliser le json fourni avec python, et l'effet est le même.

Après avoir obtenu le modèle de corps de requête, nous obtenons la variable request_body, qui est une donnée de type dictionnaire. Nous pouvons la paramétrer pour construire le corps de requête dont nous avons besoin. Par exemple, nous voulons modifier l'identifiant de la requête, le nom d'utilisateur. , et le contenu textuel de cette requête, vous pouvez le faire. Le côté gauche est le champ qui doit être modifié et le côté droit est la variable dont nous avons besoin.

Après avoir construit les données à envoyer, vous pouvez vous préparer à envoyer la requête. Avant d'envoyer la requête, nous avons encore du travail à faire, qui consiste à définir certains paramètres de l'interface de requête et à personnaliser certains en-têtes de requête. Nous donnons ici un exemple simple comme suit :

Nous avons personnalisé les paramètres de la requête et les en-têtes de la requête, puis nous pouvons envoyer une requête similaire à l'URL suivante :

Nous ajoutons ensuite le corps précédemment construit, puis utilisez la méthode post de la bibliothèque de requêtes pour envoyer la requête. , le paramètre data dans la méthode est utilisé ici. Il reçoit un json, donc les variables du dictionnaire précédentes doivent être converties avant l'envoi. Ici, la bibliothèque json qui vient. avec python est utilisé et la méthode dumps est utilisée. Convertissez le dictionnaire en json :

À ce stade, une requête de publication http de base a été envoyée. Notez que nous avons un objet Response nommé r. Nous pouvons obtenir toutes les informations que nous souhaitons à partir de cet objet.
2. Requêtes plus complexes
Nous avons introduit plus tôt la requête de publication http la plus simple Sur cette base, nous avons parfois besoin de requêtes plus complexes, comme apporter un fichier, une requête https, etc. Expliquons brièvement comment la mise en œuvre :
Pour. Par exemple, nous voulons envoyer un fichier audio au format pcm à l'interface, et l'interface est https.
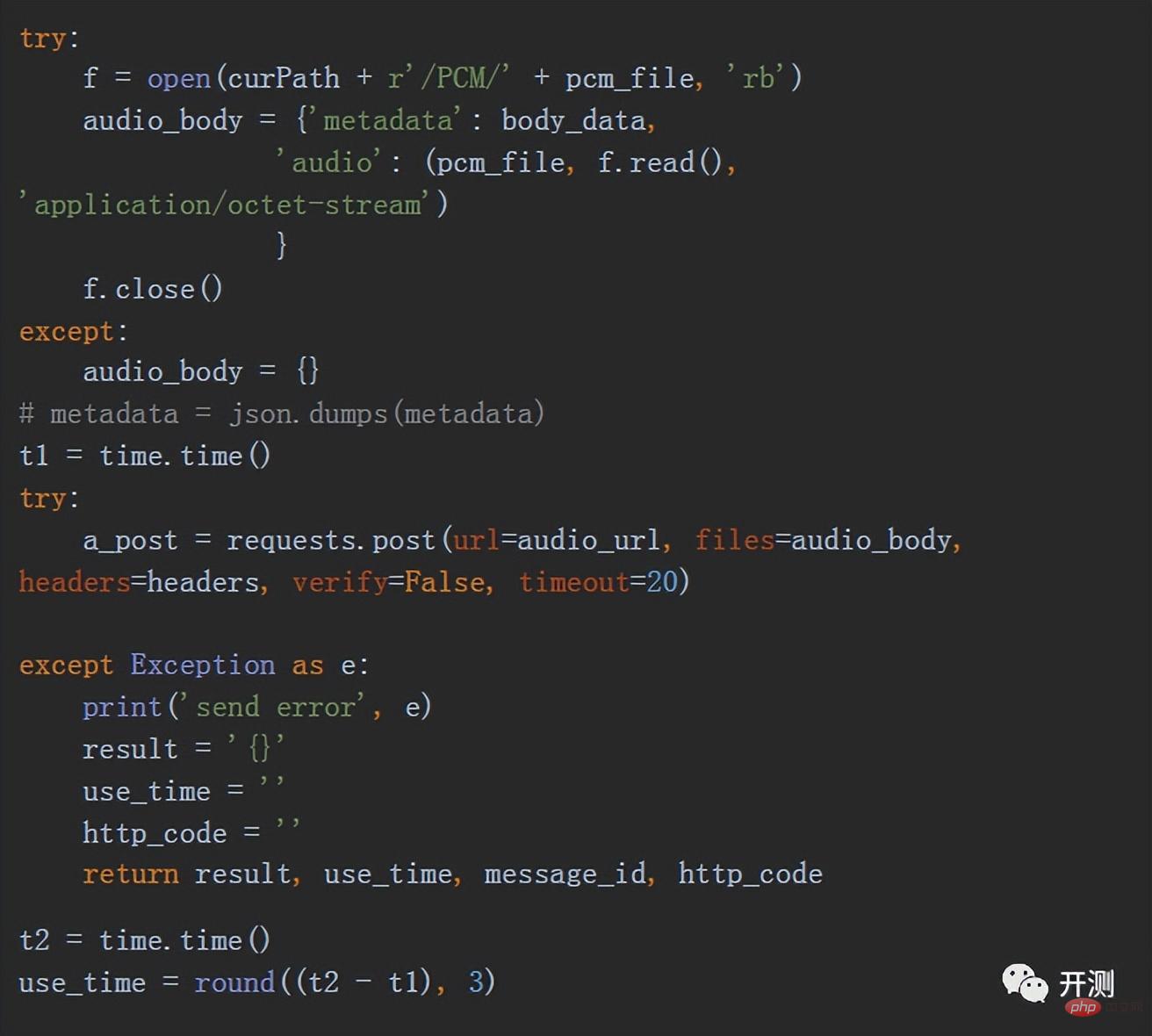
Notez que l'envoi de requêtes https nécessite une authentification SSL. Utilisez le paramètre verify dans la méthode. La valeur par défaut de ce paramètre est True. Généralement, si la vérification n'est pas requise, vous devez la définir sur False. Une autre chose à noter est que nous avons défini un délai d'attente pour éviter que le processus de demande n'expire et que le programme ne réponde plus.
Capturez les données clés des données de retour de la requête
Dans l'étape d'envoi de la requête, nous avons un objet Response nommé r. Nous pouvons obtenir toutes les informations que nous souhaitons à partir de cet objet.
Il existe plusieurs méthodes pour obtenir du contenu, que nous pouvons utiliser selon nos propres besoins :

Le texte obtenu est généralement au format json :
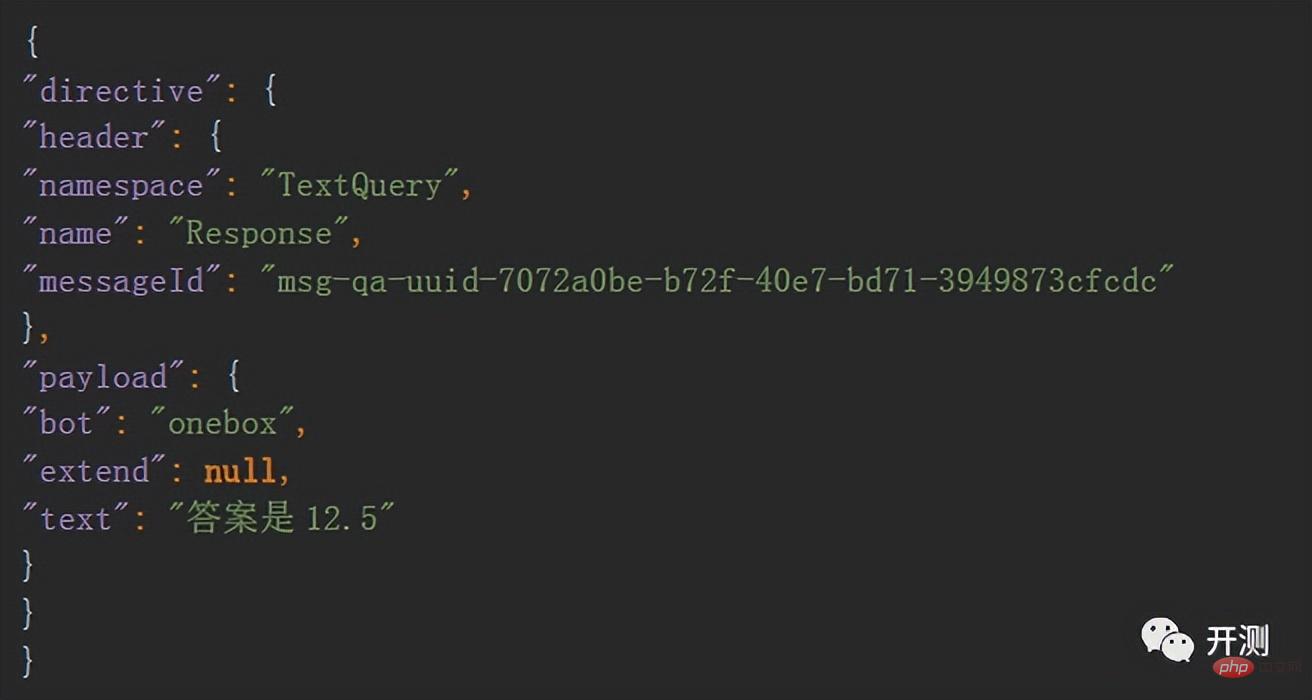
Nous pouvons convertir json et utiliser la méthode json.loads , convertissez un objet json en dictionnaire python, afin que nous puissions facilement obtenir certains des champs souhaités. Cette étape est très simple et ne sera pas présentée en détail.
Comment exécuter un cas et stocker les résultats des tests
Tout d'abord, jetons un coup d'œil à notre cas. Notre cas est écrit en utilisant Excel, comme suit :

1080×112 39.8 KB
Comment lire Excel et obtenir. Et les cas ? Nous avons utilisé la bibliothèque pandas en python. Cette bibliothèque est très puissante et dispose de nombreuses méthodes de traitement des données. Nous utilisons uniquement la méthode de lecture d'Excel. Le code spécifique est le suivant :
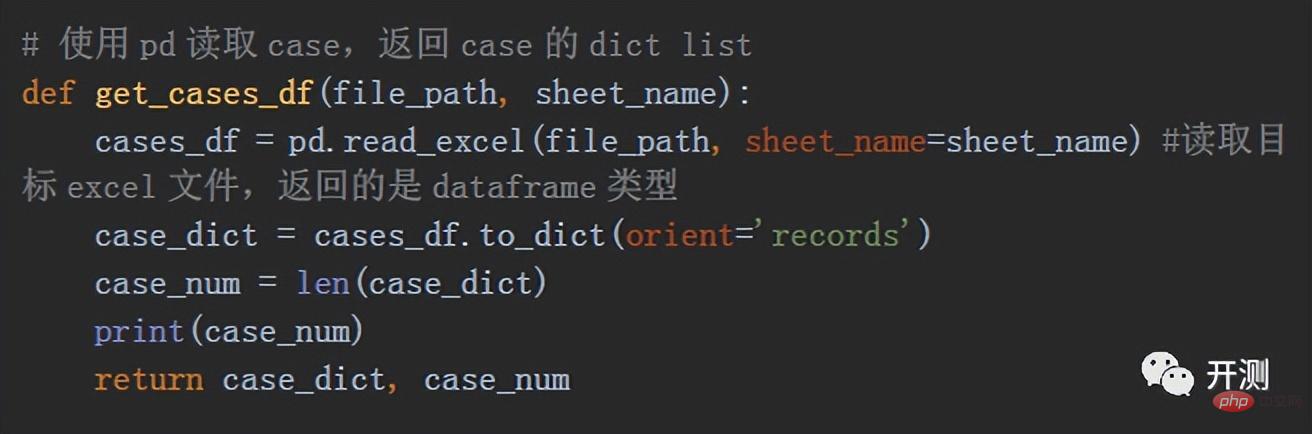
De cette façon, nous convertissons les données du tableau en une liste, et chaque liste. est un format de dictionnaire, c'est-à-dire dans notre cas, le format spécifique est le suivant :

Le but est que nous pouvons mapper l'en-tête du tableau à chaque cas pour former un dictionnaire, afin que nous puissions fonctionner de manière plus flexible cas et comparer les données.
Avec la liste de cas et les étapes précédentes d'envoi des requêtes et d'obtention des résultats, nous pouvons effectuer des tests d'interface par lots. Ici, nous pouvons utiliser une boucle for pour exécuter par lots :
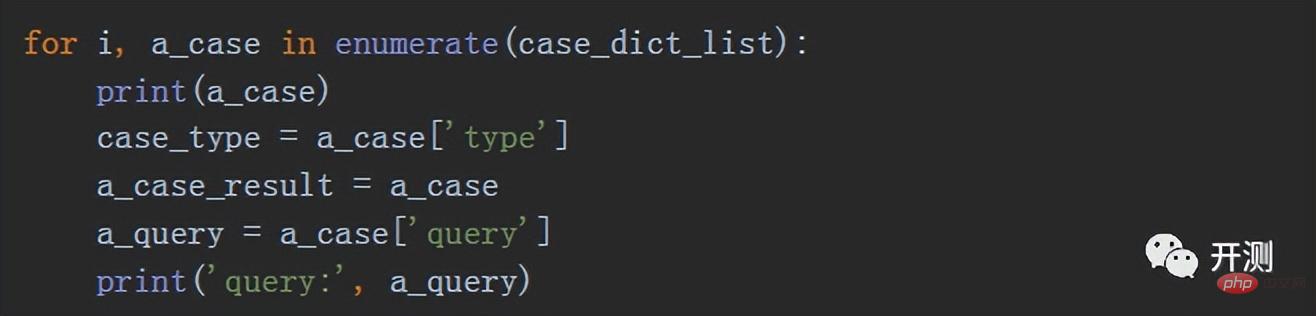
Nous renverrons les résultats à chaque fois, épissés. dans un dictionnaire selon le format de cas, qui est nos données de résultat. Stockez chaque dictionnaire de résultats dans une liste pour obtenir la liste complète des dictionnaires de résultats. Nous l'appelons actuellement case_result_list. La bibliothèque pandas peut convertir cette liste. au format dataframe :

Ensuite, nous enregistrons le dataframe sous forme de fichier Excel :

À ce stade, nous avons tout terminé, de l'obtention du dossier à l'envoi d'une demande pour obtenir les résultats et à l'enregistrement du processus de résultats. .
Identifier les données de résultat
Après les opérations ci-dessus, nous avons terminé le processus d'envoi des demandes par lots et d'obtention de résultats. Si nous devons effectuer certains traitements sur les cellules de résultat, comme les marquer en rouge et en gras, etc., nous pouvons faire les résultats des tests. Le message d'erreur est plus évident, que dois-je faire ? Ici, nous utilisons la bibliothèque openpyxl en python. Cette bibliothèque peut également lire et écrire des tableaux Excel et insérer des formules et des styles. Ce que nous utilisons ici, c'est une opération de style. Nous mettons en évidence les résultats en rouge et en gras en fonction des données dans la cellule :
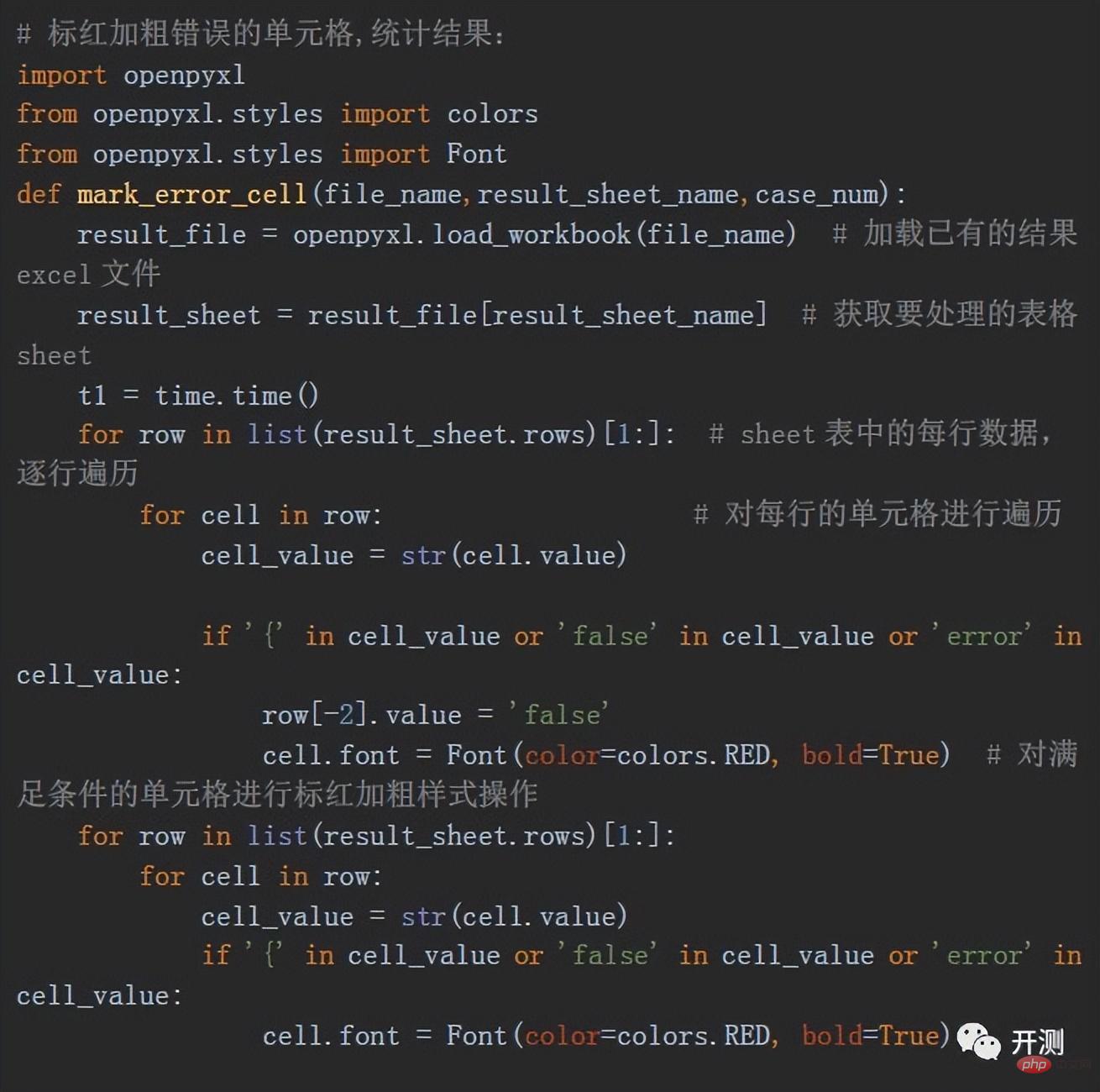
Les résultats finaux du test sont les suivants. En utilisant openpyxl, nous pouvons également ajouter des lignes aux résultats, Ajoutez des informations statistiques sur les résultats des tests, telles que le nombre de cas, le nombre d'erreurs, le taux d'erreur et le taux de précision, etc.
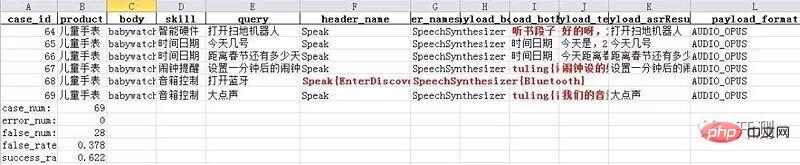
1080×224 61.6 Ko
Ce qui précède est une construction complète de script de test d'automatisation d'interface, qui peut réaliser une requête automatique, obtenir des résultats, une analyse de comparaison des données, exporter les résultats vers Excel et d'autres fonctions. Chaque étape est relativement simple et peut. être rapidement mis en place. Créez des scripts de test automatisés qui répondent à vos besoins pour vérifier rapidement l’interface du serveur.
La bibliothèque de requêtes et la bibliothèque pandas utilisées sont des bibliothèques couramment utilisées en python et sont très puissantes. Vous pouvez vous référer à leurs documents officiels pour une compréhension approfondie.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!