
Maison >développement back-end >Tutoriel Python >Un guide complet sur le nettoyage des données avec Python
Un guide complet sur le nettoyage des données avec Python

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-11 20:16:212451parcourir
Vous devez avoir entendu cette célèbre citation de la science des données :
Dans un projet de science des données, 80 % du temps est consacré au traitement des données.
Si vous n’en avez pas entendu parler, rappelez-vous : le nettoyage des données est le fondement du flux de travail de la science des données. Les modèles d'apprentissage automatique fonctionnent en fonction des données que vous leur fournissez. Des données désordonnées peuvent entraîner de mauvaises performances, voire des résultats incorrects, tandis que des données propres sont une condition préalable à de bonnes performances du modèle. Bien entendu, des données propres ne signifient pas toujours de bonnes performances. La sélection correcte du modèle (les 20 %) restants est également importante, mais sans données propres, même le modèle le plus puissant ne peut pas atteindre le niveau attendu.
Dans cet article, nous énumérerons les problèmes qui doivent être résolus lors du nettoyage des données et présenterons les solutions possibles. Grâce à cet article, vous pourrez apprendre comment effectuer le nettoyage des données étape par étape.
Valeurs manquantes
Lorsque l'ensemble de données contient des données manquantes, certaines analyses de données peuvent être effectuées avant le remplissage. Parce que la position de la cellule vide elle-même peut nous fournir des informations utiles. Par exemple :
- Les valeurs NA n'apparaissent qu'à la fin ou au milieu de l'ensemble de données. Cela signifie qu'il peut y avoir eu des problèmes techniques lors du processus de collecte de données. Il peut être nécessaire d'analyser le processus de collecte de données pour cette séquence d'échantillons particulière et d'essayer d'identifier la source du problème.
- Si le nombre de NA dans une colonne dépasse 70 à 80 %, vous pouvez supprimer la colonne.
- Si les valeurs NA se trouvent dans une colonne en tant que question facultative du formulaire, cette colonne peut en outre être codée comme ayant répondu à l'utilisateur (1) ou sans réponse (0).
missingno Cette bibliothèque python peut être utilisée pour vérifier la situation ci-dessus, et elle est très simple à utiliser. Par exemple, la ligne blanche dans l'image ci-dessous est NA :
import missingno as msno msno.matrix(df)

Il existe de nombreuses méthodes pour remplir. valeurs manquantes, telles que :
- Moyenne, Médiane, Mode
- kNN
- Zéro ou constante, etc.
Différentes méthodes ont des forces et des faiblesses les unes par rapport aux autres, et il n'y a pas de « meilleure » technique qui fonctionne dans tous les cas. situations. Pour plus de détails, veuillez vous référer à nos articles précédents
Outliers
Les valeurs aberrantes sont des valeurs très grandes ou très petites par rapport à d'autres points de l'ensemble de données. Leur présence affecte grandement les performances des modèles mathématiques. Regardons cet exemple simple :
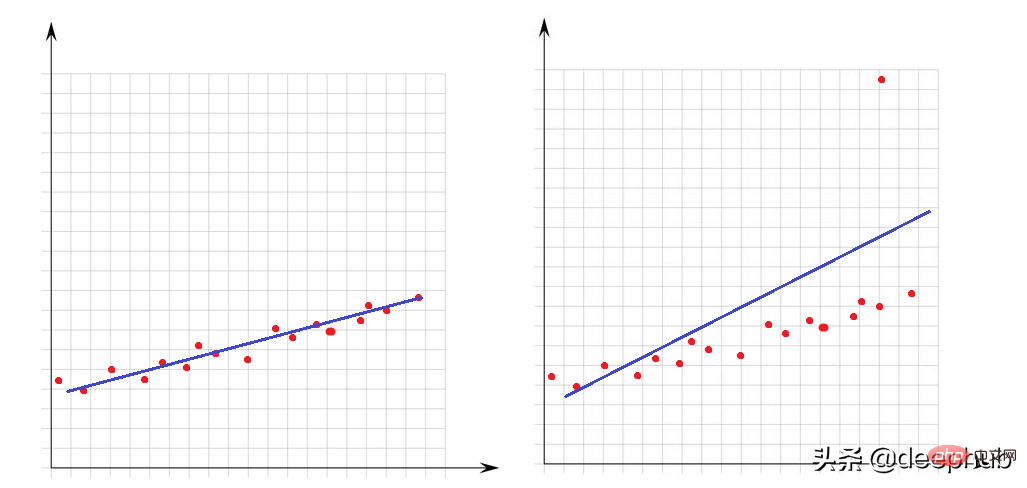
Dans l'image de gauche, il n'y a pas de valeurs aberrantes et notre modèle linéaire s'adapte très bien aux points de données. Dans l'image de droite, il y a une valeur aberrante, lorsque le modèle tente de couvrir tous les points de l'ensemble de données, la présence de cette valeur aberrante modifie la façon dont le modèle s'ajuste et rend notre modèle non adapté pour au moins la moitié des points.
Pour les valeurs aberrantes, nous devons présenter comment déterminer les anomalies. Cela nécessite de clarifier ce qui est maximum ou minimum d'un point de vue mathématique.
Toute valeur supérieure à Q3+1,5 x IQR ou inférieure à Q1-1,5 x IQR peut être considérée comme une valeur aberrante. L'IQR (intervalle interquartile) est la différence entre Q3 et Q1 (IQR = Q3-Q1).
La fonction suivante peut être utilisée pour vérifier le nombre de valeurs aberrantes dans l'ensemble de données :
def number_of_outliers(df): df = df.select_dtypes(exclude = 'object') Q1 = df.quantile(0.25) Q3 = df.quantile(0.75) IQR = Q3 - Q1 return ((df < (Q1 - 1.5 * IQR)) | (df > (Q3 + 1.5 * IQR))).sum()
Une façon de gérer les valeurs aberrantes est de les rendre égales à Q3 ou Q1. La fonction lower_upper_range ci-dessous utilise les bibliothèques pandas et numpy pour rechercher des plages avec des valeurs aberrantes en dehors d'elles, puis utilise la fonction clip pour découper les valeurs dans la plage spécifiée.
def lower_upper_range(datacolumn): sorted(datacolumn) Q1,Q3 = np.percentile(datacolumn , [25,75]) IQR = Q3 - Q1 lower_range = Q1 - (1.5 * IQR) upper_range = Q3 + (1.5 * IQR) return lower_range,upper_range for col in columns: lowerbound,upperbound = lower_upper_range(df[col]) df[col]=np.clip(df[col],a_min=lowerbound,a_max=upperbound)
Données incohérentes
Le problème des valeurs aberrantes concernait les caractéristiques numériques, examinons maintenant les caractéristiques de type caractère (catégorielles). Des données incohérentes signifient que des classes uniques de colonnes ont des représentations différentes. Par exemple, dans la colonne genre, il y a à la fois h/f et homme/femme. Dans ce cas, il y aurait 4 classes, mais il y a en réalité deux classes.
Il n'existe actuellement aucune solution automatique à ce problème, une analyse manuelle est donc requise. La fonction unique des pandas est préparée pour cette analyse. Regardons un exemple de marque de voiture :
df['CarName'] = df['CarName'].str.split().str[0] print(df['CarName'].unique())
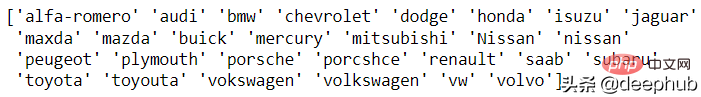
maxda-mazda, Nissan-nissan, porcshce-porsche, toyota-toyota, etc. peuvent toutes être fusionnées.
df.loc[df['CarName'] == 'maxda', 'CarName'] = 'mazda' df.loc[df['CarName'] == 'Nissan', 'CarName'] = 'nissan' df.loc[df['CarName'] == 'porcshce', 'CarName'] = 'porsche' df.loc[df['CarName'] == 'toyouta', 'CarName'] = 'toyota' df.loc[df['CarName'] == 'vokswagen', 'CarName'] = 'volkswagen' df.loc[df['CarName'] == 'vw', 'CarName'] = 'volkswagen'
Données invalides
Les données invalides représentent une valeur qui n'est pas du tout logiquement correcte. Par exemple,
- L'âge d'une personne est de 560 ans ;
- Une certaine opération a pris -8 heures
- La taille d'une personne est de 1 200 cm, etc.
Pour les colonnes numériques, la fonction de description des pandas peut être utilisée pour identifier ces personnes ; Erreur :
df.describe()
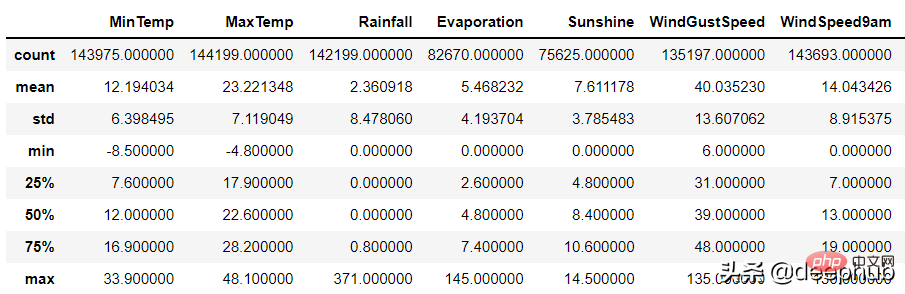
Il peut y avoir deux raisons pour des données invalides :
1 Erreur de collecte de données : par exemple, la plage n'est pas jugée lors de la saisie, et 1799 cm est saisi au lieu de 179 cm lors de la saisie de la hauteur, mais le programme. ne juge pas l’étendue des données.
2. Erreur d'opération de données
数据集的某些列可能通过了一些函数的处理。 例如,一个函数根据生日计算年龄,但是这个函数出现了BUG导致输出不正确。
以上两种随机错误都可以被视为空值并与其他 NA 一起估算。
重复数据
当数据集中有相同的行时就会产生重复数据问题。 这可能是由于数据组合错误(来自多个来源的同一行),或者重复的操作(用户可能会提交他或她的答案两次)等引起的。 处理该问题的理想方法是删除复制行。
可以使用 pandas duplicated 函数查看重复的数据:
df.loc[df.duplicated()]
在识别出重复的数据后可以使用pandas 的 drop_duplicate 函数将其删除:
df.drop_duplicates()
数据泄漏问题
在构建模型之前,数据集被分成训练集和测试集。 测试集是看不见的数据用于评估模型性能。 如果在数据清洗或数据预处理步骤中模型以某种方式“看到”了测试集,这个就被称做数据泄漏(data leakage)。 所以应该在清洗和预处理步骤之前拆分数据:
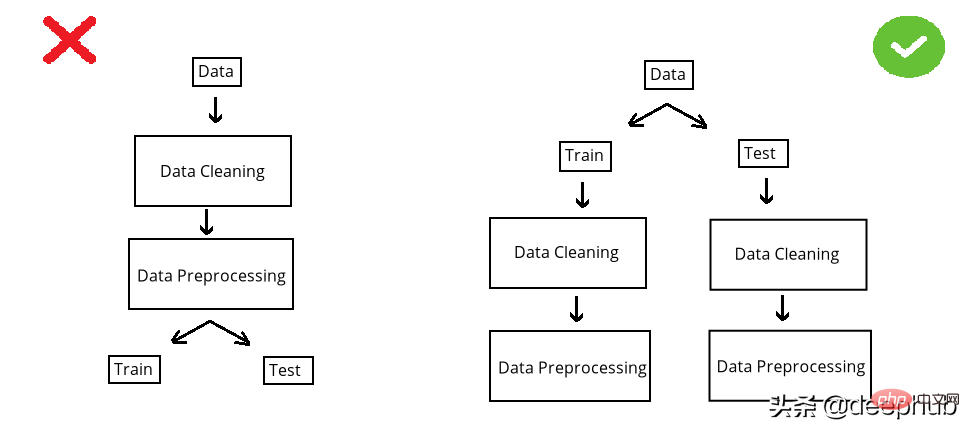
以选择缺失值插补为例。数值列中有 NA,采用均值法估算。在 split 前完成时,使用整个数据集的均值,但如果在 split 后完成,则使用分别训练和测试的均值。
第一种情况的问题是,测试集中的推算值将与训练集相关,因为平均值是整个数据集的。所以当模型用训练集构建时,它也会“看到”测试集。但是我们拆分的目标是保持测试集完全独立,并像使用新数据一样使用它来进行性能评估。所以在操作之前必须拆分数据集。
虽然训练集和测试集分别处理效率不高(因为相同的操作需要进行2次),但它可能是正确的。因为数据泄露问题非常重要,为了解决代码重复编写的问题,可以使用sklearn 库的pipeline。简单地说,pipeline就是将数据作为输入发送到的所有操作步骤的组合,这样我们只要设定好操作,无论是训练集还是测试集,都可以使用相同的步骤进行处理,减少的代码开发的同时还可以减少出错的概率。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!