
Maison >Périphériques technologiques >IA >Aborder la pratique d'optimisation de l'inférence du modèle d'apprentissage profond de l'IA du service de normalisation
Aborder la pratique d'optimisation de l'inférence du modèle d'apprentissage profond de l'IA du service de normalisation

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-11 19:28:111796parcourir
Introduction
Le deep learning a été largement mis en œuvre dans des scénarios commerciaux réels dans des domaines tels que le traitement du langage naturel, et l'optimisation de ses performances d'inférence est devenue une partie importante du processus de déploiement. Amélioration des performances de raisonnement : d'une part, il peut exploiter pleinement les capacités du matériel déployé, réduire le temps de réponse des utilisateurs et réduire les coûts, d'autre part, il peut utiliser des modèles d'apprentissage en profondeur avec des structures plus complexes tout en conservant le temps de réponse ; inchangé. améliorant ainsi les indicateurs de précision des affaires.
Cet article effectue un travail d'optimisation des performances d'inférence pour le modèle d'apprentissage profond dans le service de normalisation d'adresses. Grâce à des méthodes d'optimisation telles que des opérateurs hautes performances, la quantification et l'optimisation de la compilation, la vitesse d'inférence de bout en bout du modèle d'IA peut être améliorée jusqu'à 4,11 fois sans réduire l'indice de précision. 1. Méthodologie d'optimisation des performances d'inférence de modèle
L'optimisation des performances d'inférence de modèle est l'un des aspects importants lors du déploiement de services d'IA. D'une part, cela peut améliorer l'efficacité de l'inférence de modèle et libérer pleinement les performances du matériel. D’un autre côté, cela peut permettre à l’entreprise d’adopter des modèles plus complexes tout en conservant le délai de raisonnement inchangé, améliorant ainsi l’indice de précision. Cependant, il existe certaines difficultés à optimiser les performances de raisonnement dans des scénarios réels.1.1 Difficultés d'optimisation des scénarios de traitement du langage naturel
Dans les tâches typiques de traitement du langage naturel (NLP), le réseau neuronal récurrent (RNN) et le BERT[7] (représentations d'encodeur bidirectionnel de Transformers.) sont deux types de modèles structures avec des taux d’utilisation élevés. Afin de faciliter le mécanisme de mise à l'échelle élastique et la rentabilité élevée du déploiement de services en ligne, les tâches de traitement du langage naturel sont généralement déployées sur des plates-formes CPU x86 telles que les processeurs Intel® Xeon®. Cependant, à mesure que les scénarios commerciaux deviennent plus complexes, les exigences en matière de performances de calcul d'inférence des services deviennent de plus en plus élevées. En prenant les modèles RNN et BERT ci-dessus comme exemples, les défis de performances lorsqu'ils sont déployés sur la plate-forme CPU sont les suivants :
RNN
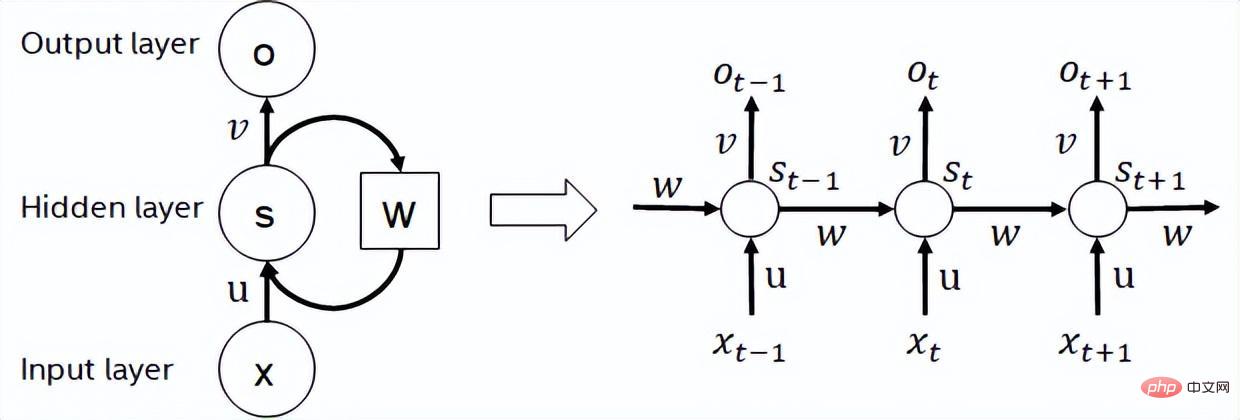
- Le réseau neuronal récurrent est un type de réseau neuronal qui prend les données de séquence comme entrée. Un réseau neuronal récursif qui effectue une récursion dans le sens de l'évolution et tous les nœuds (unités cycliques) sont connectés dans une chaîne. Les RNN couramment utilisés incluent LSTM, GRU et certains dérivés. Pendant le processus de calcul, comme le montre la figure ci-dessous, chaque sortie d'étape suivante dans la structure RNN dépend de l'entrée correspondante et de la sortie de l'étape précédente. Par conséquent, RNN peut effectuer des tâches de type séquence et a été largement utilisé dans le domaine de la PNL et même de la vision par ordinateur ces dernières années. Comparé à BERT, RNN nécessite moins de calculs et partage les paramètres du modèle, mais sa dépendance temporelle de calcul rend impossible l'exécution de calculs parallèles sur la séquence.
Diagramme schématique de la structure RNN
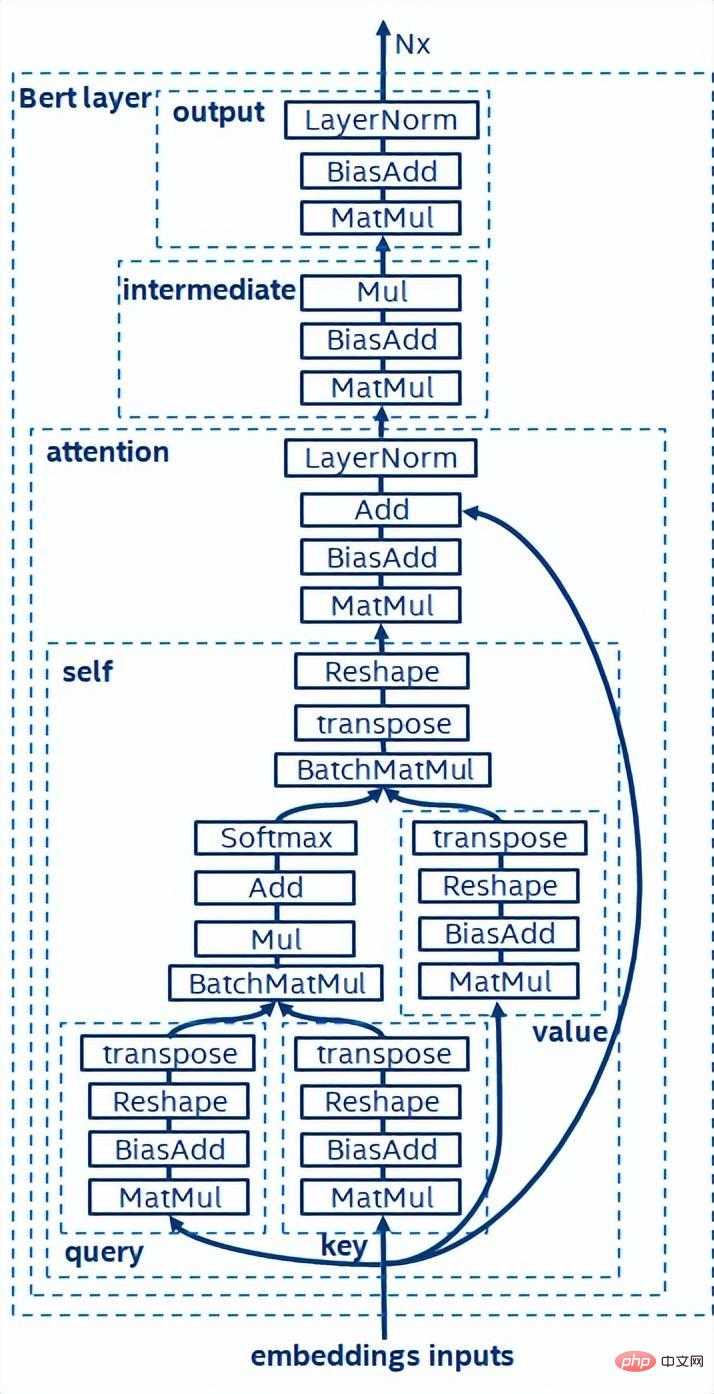
- BERT [7] a prouvé qu'il peut effectuer une pré-formation non supervisée (Unsupervised Pre-training) sur de grands ensembles de données avec un structure de réseau plus profonde, puis fournir un modèle pour affiner des tâches spécifiques. Cela améliore non seulement la précision des performances de ces tâches spécifiques, mais simplifie également le processus de formation. La structure du modèle BERT est simple et facile à étendre. En approfondissant et en élargissant simplement le réseau, vous pouvez obtenir une meilleure précision que la structure RNN. D’un autre côté, l’amélioration de la précision se fait au prix d’une charge de calcul plus importante. Il existe un grand nombre d’opérations de multiplication matricielle dans le modèle BERT, ce qui constitue un énorme défi pour le processeur.
Diagramme schématique de la structure du modèle BERT
Sur la base de l'analyse des défis de performances d'inférence ci-dessus, nous pensons que l'optimisation de l'inférence de modèle à partir du niveau de la pile logicielle comprend principalement les éléments suivants stratégies :
Compression du modèle : y compris quantification, sparse, élagage, etc.
- Opérateurs hautes performances pour des scénarios spécifiques
- Optimisation du compilateur IA
- Quantisation
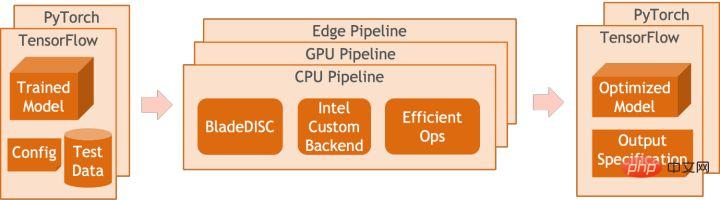
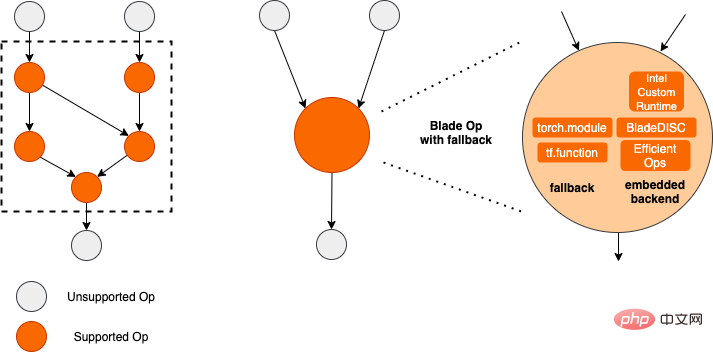
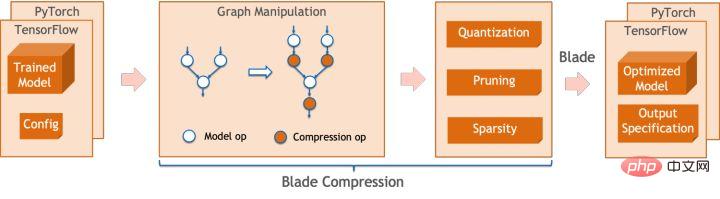
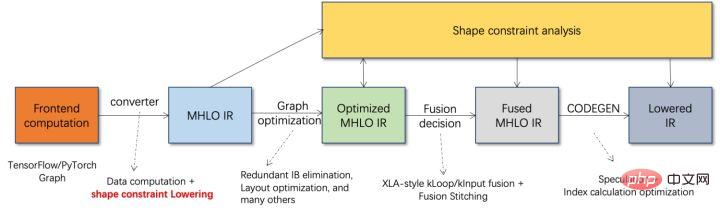
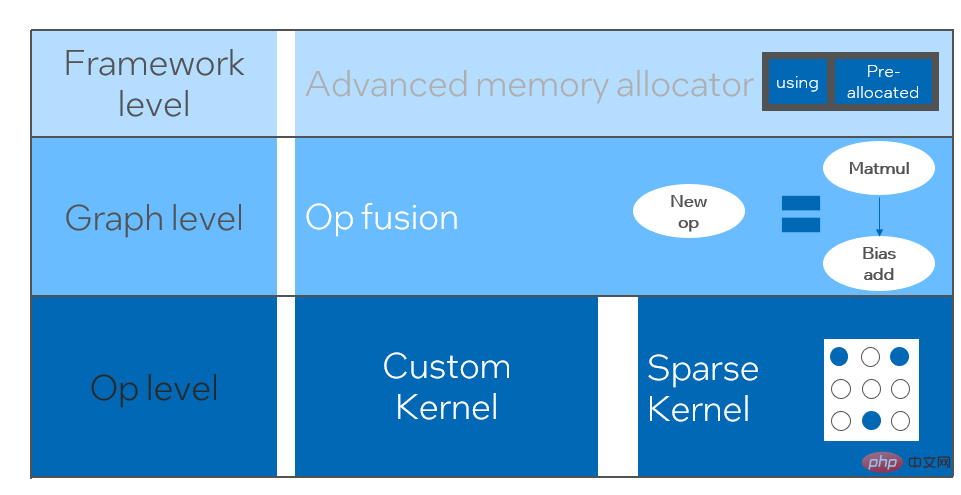
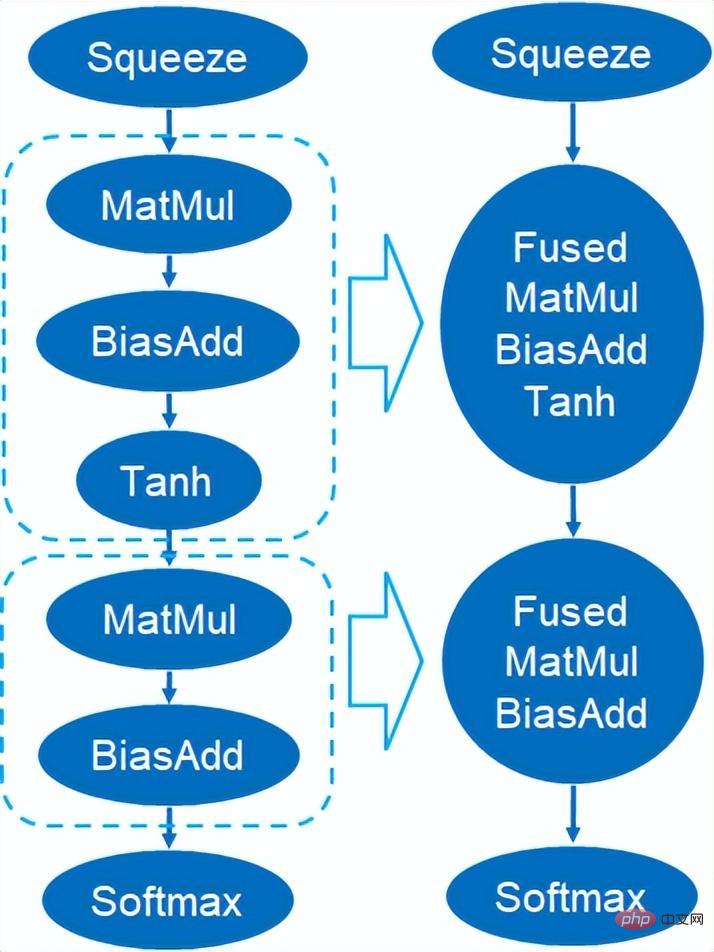
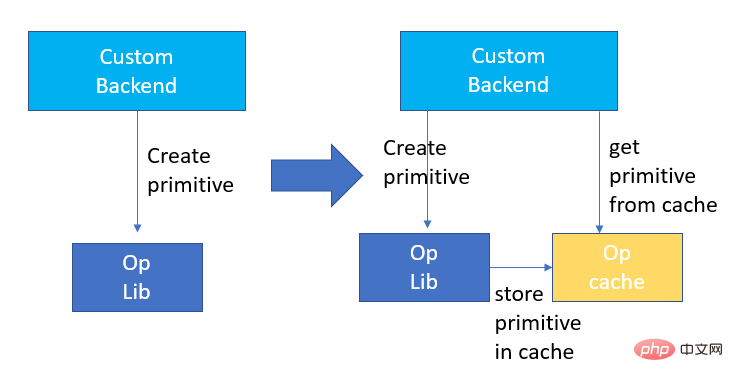
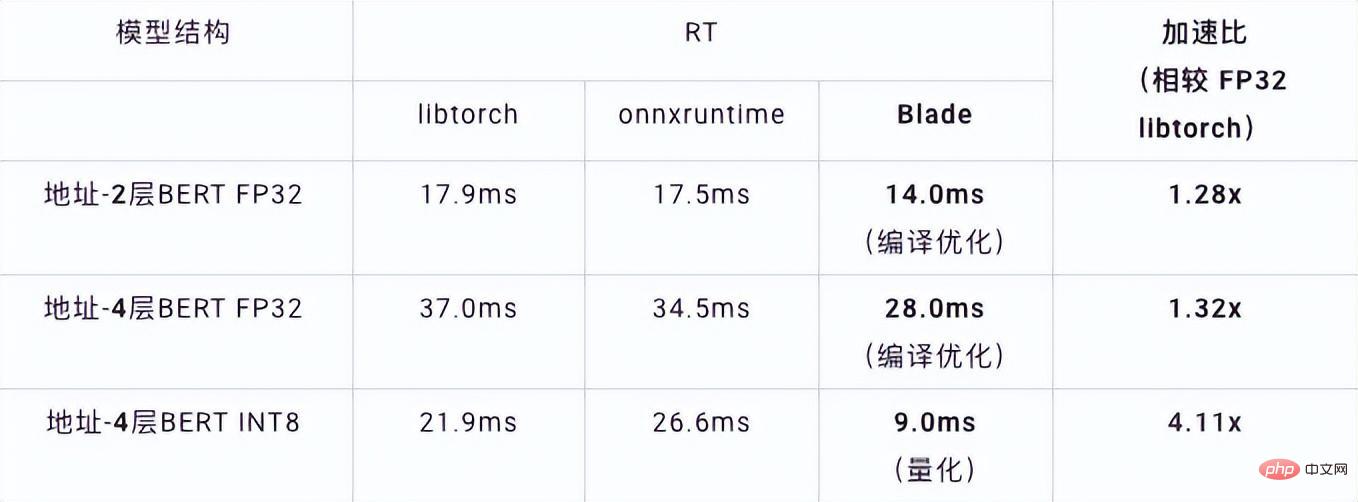
La quantification du modèle fait référence au processus consistant à rapprocher les valeurs ou poids d'activation en virgule flottante (généralement représentés par des nombres à virgule flottante de 32 bits) avec des entiers de faible taille (16 bits ou 8 bits), puis à terminer le calcul. dans une représentation à bits faibles. De manière générale, la quantification du modèle peut compresser les paramètres du modèle, réduisant ainsi la surcharge de stockage du modèle ; et en réduisant l'accès à la mémoire et en utilisant efficacement les instructions informatiques à faible bit (telles que les instructions de réseau neuronal vectoriel Intel® Deep Learning Boost, VNNI) pour réaliser inférence. vitesse Amélioration. Étant donné une valeur à virgule flottante, nous pouvons la mapper à une valeur de bit faible grâce à la formule suivante : où la somme est obtenue grâce à l'algorithme de quantification. Sur cette base, en prenant l'opération Gemm comme exemple, en supposant qu'il existe un processus de calcul en virgule flottante : Nous pouvons compléter le processus de calcul correspondant dans le domaine des bits faibles : Opérateurs hautes performances dans le cadre du deep learning Afin de maintenir la polyvalence et de prendre en compte divers processus (comme la formation), il existe une redondance dans la surcharge d'inférence de l'opérateur. Lorsque la structure du modèle est déterminée, le processus de raisonnement de l'opérateur n'est qu'un sous-ensemble du processus complet d'origine. Par conséquent, lorsque la structure du modèle est déterminée, nous pouvons implémenter des opérateurs d'inférence hautes performances et remplacer les opérateurs généraux du modèle d'origine pour améliorer la vitesse d'inférence. La clé pour implémenter des opérateurs hautes performances sur le CPU est de réduire les accès à la mémoire et d'utiliser un jeu d'instructions plus efficace. Dans le processus de calcul de l'opérateur d'origine, d'une part, il existe un grand nombre de variables intermédiaires, et ces variables effectueront un grand nombre d'opérations de lecture et d'écriture sur la mémoire, ralentissant ainsi la vitesse de raisonnement. En réponse à cette situation, on peut modifier sa logique de calcul pour réduire le coût des variables intermédiaires ; d'autre part, on peut appeler directement le jeu d'instructions vectorisées pour accélérer certaines étapes de calcul au sein de l'opérateur, comme le traitement Intel® Xeon® Efficace Jeu d'instructions AVX512 sur le processeur. AI Compiler Optimization Avec le développement du domaine de l'apprentissage profond, la structure du modèle et le matériel déployé ont montré une tendance d'évolution diversifiée. Lors du déploiement du modèle sur diverses plates-formes matérielles, nous appelons généralement le runtime lancé par chaque fabricant de matériel. Dans les scénarios commerciaux réels, cela peut rencontrer certains défis, tels que : Le compilateur AI a été proposé pour résoudre les problèmes ci-dessus. Il fait abstraction de plusieurs niveaux pour résoudre certains des problèmes ci-dessus. Premièrement, il accepte le graphique de calcul du modèle de chaque framework frontal en entrée et génère une représentation intermédiaire unifiée via divers convertisseurs. Par la suite, des passes d'optimisation de graphes telles que la fusion d'opérateurs et l'expansion de boucles seront appliquées à la représentation intermédiaire pour améliorer les performances de raisonnement. Enfin, le compilateur IA effectuera une génération de code pour des plates-formes matérielles spécifiques sur la base du graphique de calcul optimisé pour générer du code exécutable. Dans ce processus, des stratégies d'optimisation telles que les contraintes de point et de forme seront introduites. Les compilateurs d'IA sont très robustes, adaptables, faciles à utiliser et peuvent générer des avantages d'optimisation significatifs. Dans cet article, l'équipe PAI de la plateforme d'apprentissage automatique Alibaba Cloud s'est associée à l'équipe des logiciels de centre de données Intel, à l'équipe d'intelligence artificielle et d'analyse d'Intel et à l'équipe de normalisation des adresses NLP de la DAMO Academy pour résoudre le défi des performances d'inférence de la normalisation des adresses. service et collaborer pour obtenir un schéma d’optimisation d’inférence haute performance. La sécurité publique et les affaires gouvernementales, la logistique du commerce électronique, l'énergie (eau, électricité et gaz), les opérateurs, la nouvelle vente au détail, la finance, la médecine et d'autres industries impliquent souvent une grande quantité d'adresses. données dans le processus de développement commercial, et ces données Il n'existe souvent pas de spécification de structure standard et des problèmes tels que des adresses manquantes et des noms multiples au même endroit surviennent. Avec la numérisation, le problème des adresses urbaines non standard est devenu de plus en plus important. Avantages de la normalisation des adressesCe service d'algorithme d'adresse peut automatiquement normaliser les données d'adresse, ce qui peut résoudre efficacement le problème de plusieurs noms en un seul endroit, l'identification de l'adresse, l'identification de l'authenticité de l'adresse et d'autres irrégularités et délais des données d'adresse. consommation de gestion manuelle Il résout les problèmes de consommation de main-d'œuvre et de duplication de la construction de bases de données d'adresses, et fournit des capacités de nettoyage des données d'adresse et de normalisation des adresses aux entreprises, aux agences gouvernementales et aux développeurs, afin que les données d'adresse puissent mieux soutenir les entreprises. Les produits de normalisation d'adresses ont les caractéristiques suivantes : Super performance : accumulation Avec. riche expérience dans la construction de projets, il peut transporter de manière stable d'énormes quantités de données Schéma schématique du système de recherche de services d'adressesPlus précisément, le modèle optimisé cette fois est basé sur la Base de modèle de langage de pré-formation géographique multitâche Modèle de rappel vectoriel multitâche . Base de modèle linguistique de pré-formation géographique multitâcheBasé sur la tâche Masked Language Model (MLM), il combine la classification des points d'intérêt associés et l'identification des éléments d'adresse (province, ville, district, POI, etc.), et grâce à la méthode de méta-apprentissage (Meta Learning), la probabilité d'échantillonnage de plusieurs tâches est ajustée de manière adaptative et les connaissances générales en matière d'adresse sont intégrées dans le modèle linguistique. Diagramme schématique de la base du modèle de pré-entraînement d'adresse multitâcheLe modèle de rappel vectoriel multitâche Diagramme schématique du modèle de rappel vectoriel multitâcheEn tant que module de base pour le calcul de la correspondance de similarité d'adresse, le Modèle de classement fin Affichage des performances Diagramme schématique d'un modèle affiné Le produit Blade lancé par l'équipe PAI de la plateforme d'apprentissage automatique Alibaba Cloud prend en charge toutes les solutions d'optimisation mentionnées ci-dessus, fournit une interface utilisateur unifiée et dispose de plusieurs Backends logiciels, tels que les opérateurs hautes performances, Intel Custom Backend, BladeDISC, etc. Schéma d'architecture d'optimisation d'inférence de modèle Blade 3.1 Blade Blade est un outil général d'optimisation d'inférence lancé par l'équipe PAI (Plateforme d'intelligence artificielle) d'apprentissage automatique d'Alibaba Cloud, qui peut être conjointement optimisé via le système de modèle , afin que le modèle puisse atteindre des performances de raisonnement optimales. Il intègre de manière organique l'optimisation des graphiques informatiques, les bibliothèques d'optimisation des fournisseurs telles qu'Intel® oneDNN, l'optimisation de la compilation BladeDISC, la bibliothèque d'opérateurs hautes performances Blade, le backend Costom, la précision mixte Blade et d'autres méthodes d'optimisation. Dans le même temps, la simplicité d’utilisation abaisse le seuil d’optimisation du modèle et améliore l’expérience utilisateur et l’efficacité de la production. PAI-Blade prend en charge plusieurs formats d'entrée, notamment Tensorflow pb, PyTorch torchscript, etc. Pour que le modèle soit optimisé, PAI-Blade l'analysera, puis appliquera diverses méthodes d'optimisation possibles et sélectionnera celle ayant l'effet d'accélération le plus évident parmi divers résultats d'optimisation comme résultat d'optimisation final. Schéma d'optimisation de Blade Afin d'obtenir l'effet d'optimisation maximum tout en assurant le taux de réussite du déploiement, PAI-Blade adopte une méthode d'optimisation de type "diagramme circulaire", c'est-à-dire : Diagramme du cercle Blade Blade Compression est une boîte à outils pour la compression de modèles lancée par Blade, conçue pour aider les développeurs dans un travail efficace d'optimisation de la compression des modèles. Il contient une variété de fonctions de compression de modèle, notamment la quantification, l'élagage, la sparsification, etc. Le modèle compressé peut être facilement optimisé via Blade pour obtenir l’optimisation ultime de la combinaison de systèmes de modèles. En termes de quantification, Blade Compression : Dans le même temps, nous fournissons une API riche en capacités atomiques pour faciliter le développement personnalisé pour des situations spécifiques. Blade Compression Schematic BladeDISC est un compilateur d'apprentissage profond de forme dynamique pour les scénarios d'apprentissage automatique lancé par l'équipe PAI de la plateforme d'apprentissage automatique Alibaba Cloud, et est l'un des backends de Blade. Il prend en charge les frameworks front-end traditionnels (TensorFlow, PyTorch) et le matériel back-end (CPU, GPU), et prend également en charge l'optimisation de l'inférence et de la formation. Schéma d'architecture BladeDISC 3.2 Opérateur hautes performances basé sur Intel® Il s'agit du module de base pour la construction de modèles et est responsable de fonctions spécifiques. Différents modèles peuvent être obtenus grâce à différentes combinaisons de ces modules, et ces modules sont également la clé. objectifs d'optimisation du compilateur AI. En conséquence, afin d'obtenir les modules de base les plus performants et ainsi d'obtenir le modèle le plus performant, Intel a procédé à une optimisation à plusieurs niveaux de ces modules de base pour l'architecture X86, notamment en permettant des instructions AVX512 efficaces, une planification des calculs internes de l'opérateur, une Fusion, optimisation du cache, optimisation parallèle, etc. Dans les services de normalisation d'adresses, le modèle de réseau neuronal récurrent (RNN) apparaît souvent, et les modules qui affectent le plus les performances dans le modèle RNN sont des modules tels que LSTM ou GRU. Ce chapitre prend LSTM comme exemple, qui est présenté. dans un format de longueur variable et multidimensionnel Comment obtenir l'optimisation ultime des performances de LSTM lors de la saisie de lots. Habituellement, afin de répondre aux besoins et aux demandes des différents utilisateurs, les services cloud qui recherchent des performances élevées et un faible coût regrouperont différentes demandes d'utilisateurs pour maximiser l'utilisation des ressources informatiques. Comme le montre la figure ci-dessous, il existe un total de trois phrases intégrées, et le contenu et la longueur d'entrée sont différents. Données d'entrée originales Données d'entrée originales Étapes de calcul de LSTM pour l'entrée LSTM computing fusion[8] Intel custom backend[9], en tant que backend logiciel de Blade, accélère puissamment la quantification du modèle et les performances d'inférence clairsemées, comprenant principalement trois niveaux d’optimisation. Premièrement, la stratégie Primitive Cache est utilisée pour optimiser la mémoire. Deuxièmement, une optimisation de la fusion de graphes est effectuée. Enfin, au niveau des opérateurs, une bibliothèque d'opérateurs efficace comprenant des opérateurs clairsemés et quantifiés est implémentée. Diagramme d'architecture backend personnalisé Intel Quantisation de faible précision Les opérateurs à grande vitesse tels que la clairseance et la quantification bénéficient du jeu d'instructions d'accélération Intel® DL Boost, tel que le jeu d'instructions VNNI.
Introduction à l'instruction VNNI L'image ci-dessus montre l'instruction VNNI. 8 bits peuvent être accélérés à l'aide de trois instructions AVX512 BW qui multiplient d'abord et ajoutent 2 paires de tableaux composés de 8 bits pour obtenir des données de 16 bits. obtenez des données 32 bits, et enfin ajoutez une constante à VPADDD. Ces trois fonctions peuvent former un AVX512_VNNI. Cette instruction peut être utilisée pour accélérer la multiplication matricielle en inférence. Fusion de graphiques De plus, Custom Backend fournit également une fusion de graphiques, par exemple, après la multiplication matricielle, le Tensor temporaire intermédiaire n'est pas généré, mais les instructions suivantes sont directement exécutées, c'est-à-dire la publication. de ce dernier terme. L'opération est fusionnée avec l'opérateur précédent, réduisant ainsi le mouvement des données et réduisant ainsi le temps d'exécution. Une fois l'opérateur dans la case rouge fusionné, le mouvement des données supplémentaires peut être éliminé et il devient. un nouvel opérateur. Fusion de graphiques Optimisation de la mémoire L'allocation et la libération de la mémoire communiqueront avec le système d'exploitation, ce qui entraînera un délai d'exécution accru. Afin de réduire cette partie de la surcharge, un backend personnalisé est ajouté. La conception du Primitive Cache est modifiée. Primitive Cache est utilisé pour mettre en cache les primitives qui ont été créées afin que les primitives ne puissent pas être recyclées par le système, réduisant ainsi la surcharge de création du prochain appel. Dans le même temps, un mécanisme de cache a été mis en place pour les opérateurs chronophages afin d'accélérer le fonctionnement des opérateurs, comme le montre la figure ci-dessous : Cache primitif Comme mentionné précédemment , la taille du modèle Après la réduction, les frais de calcul et d'accès sont considérablement réduits, ce qui entraîne une énorme amélioration des performances. Nous avons sélectionné deux structures de modèle typiques dans le service de recherche d'adresses pour vérifier l'effet de la solution d'optimisation ci-dessus. L'environnement de test est le suivant : 4.1 ESIM ESIM[6 ] Il s'agit d'une version améliorée de LSTM conçue pour l'inférence en langage naturel. Sa surcharge d'inférence provient principalement de la structure LSTM du modèle. Blade utilise l'opérateur LSTM polyvalent hautes performances développé par l'équipe logicielle du centre de données Intel pour l'accélérer, remplaçant le LSTM par défaut (Baseline) dans le module PyTorch. L'ESIM testé cette fois contient deux structures LSTM. Les performances avant et après l'optimisation par un seul opérateur sont indiquées dans le tableau :
.
RT optimisé Accélération LSTM - A 7x200 0,199 ms 0,066 ms +3.02x 202x200 0.914ms 0,307ms +2,98x LSTM - B 70x50 0.266ms 0.098ms +2.71x 202x50 0.804ms 0,209ms +3,85x Performances d'inférence à opérateur unique LSTM avant et après optimisation Avant et après optimisation, la vitesse d'inférence de bout en bout ESIM est celle indiquée dans le tableau, tandis que la précision du modèle avant et après optimisation reste inchangé. Structure du modèle ESIM[6] ESIM[6]+Opérateur lame Optim ize speedup RT 6,3ms 3,4ms +1,85x Performances d'inférence du modèle ESIM avant et après optimisation 4.2 BERT BERT [7] a été largement adopté dans le traitement du langage naturel (NLP), la vision par ordinateur (CV) et d'autres domaines ces dernières années. Blade dispose de diverses méthodes telles que l'optimisation de la compilation (FP32) et la quantification (INT8) pour cette structure. Dans le test de vitesse, la forme des données de test est fixée à 10x53. Les performances de vitesse des différents backends et des différentes méthodes d'optimisation sont indiquées dans le tableau ci-dessous. On peut voir que la vitesse d'inférence du modèle après la compilation et l'optimisation de la lame ou après la quantification INT8 est meilleure que libtorch et onnxruntime, et le backend de l'inférence est Intel Custom Backend & BladeDisc. Il convient de noter que la vitesse du BERT à 4 couches après une accélération quantitative est 1,5 fois supérieure à celle du BERT à 2 couches, ce qui signifie qu'en accélérant, l'entreprise peut utiliser un modèle plus grand et obtenir une meilleure précision commerciale. Affichage des performances d'inférence BERT d'adresse En termes de précision, nous démontrons les performances du modèle associé basées sur la tâche de corrélation d'adresses PNL chinoise CCKS2021 [5], comme indiqué dans le tableau ci-dessous. La précision de la macro BERT F1 à 4 couches auto-développée par l'équipe d'adressage de la DAMO Academy est supérieure à celle de la base BERT standard à 12 couches. L'optimisation de la compilation Blade peut atteindre une précision sans perte, et la précision du modèle quantifié réel après l'entraînement à la quantification Blade Compression est légèrement supérieure à celle du modèle à virgule flottante d'origine. Structure du modèle macro F1 (le plus haut sera le mieux) 12 couches Base BERT 77.24 BERT d'adresse à 4 couches 78.72(+1.48) BERT d'adresse à 4 couches + optimisation de la compilation Blade 78.72( +1.48) Adresse - BERT 4 couches + quantification de lame 78.85 (+1.61) Résultats de précision liés au BERT
2. Introduction à la normalisation des adresses
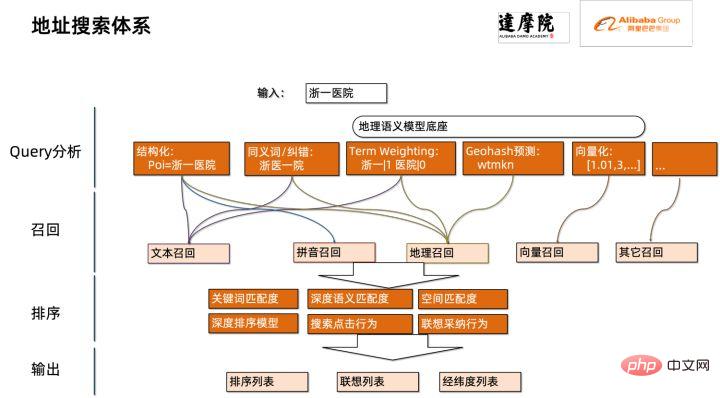 et
et 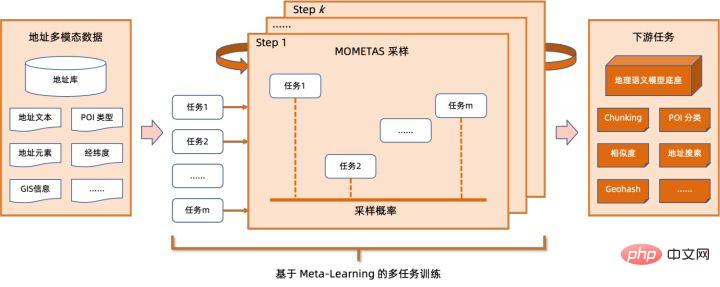
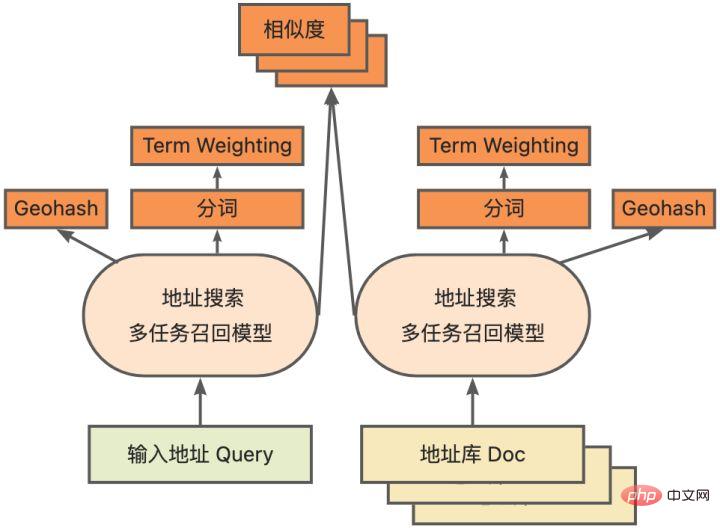 pour plus de détails).
pour plus de détails). 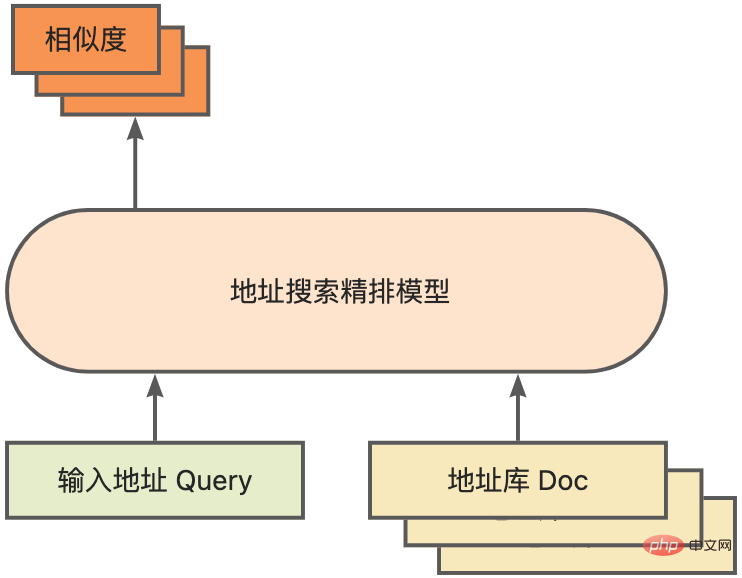
3. Solution d'optimisation d'inférence de modèle




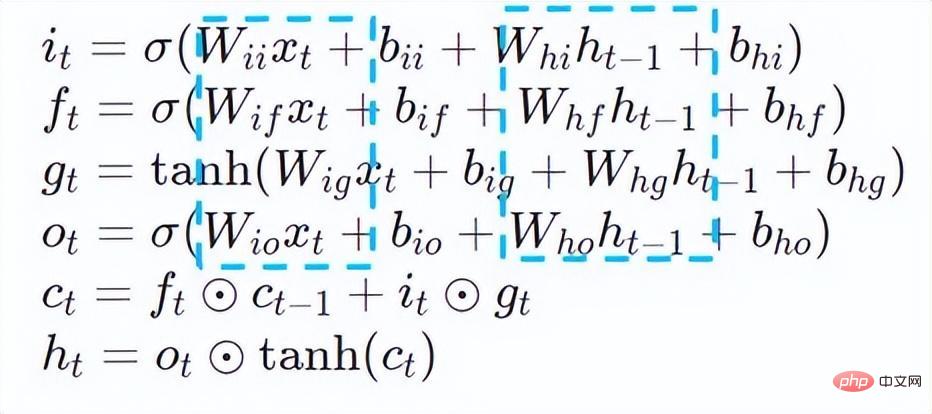
4. Affichage des performances globales
Structure LSTM
Forme d'entrée
RT avant optimisation
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI