
Maison >Périphériques technologiques >IA >Explication détaillée de ChatGPT/InstructGPT
Explication détaillée de ChatGPT/InstructGPT

- 王林avant
- 2023-04-10 10:01:142559parcourir
Avant-propos
La série GPT est une série d'articles de pré-formation d'OpenAI. Le nom complet de GPT est Generative Pre-Trained Transformer. Comme son nom l'indique, le but de GPT est d'utiliser Transformer comme modèle de base et d'utiliser pré-entraîné. -technologie de formation pour obtenir un modèle de texte universel. Les articles publiés jusqu'à présent incluent la pré-formation de texte GPT-1, GPT-2, GPT-3 et la pré-formation d'images iGPT. GPT-4, qui n'a pas encore été publié, serait un modèle multimodal. Les très populaires ChatGPT et [1] annoncés au début de cette année sont une paire de modèles frères. Ce sont des modèles de préchauffage sortis avant GPT-4, parfois également appelés GPT3.5. ChatGPT et InstructGPT sont complètement cohérents en termes de structure du modèle et de méthodes de formation, c'est-à-dire qu'ils utilisent tous deux l'apprentissage des instructions (Instruction Learning) et l'apprentissage par renforcement à partir de la rétroaction humaine (RLHF) pour guider la formation du modèle. Il existe des différences dans la manière dont les données sont collectées. Donc, pour comprendre ChatGPT, nous devons d'abord comprendre InstructGPT.
1. Connaissances de base
Avant de présenter ChatGPT/InstructGPT, nous présentons d'abord les algorithmes de base sur lesquels ils s'appuient.
Série 1.1 GPT
Les modèles de trois générations de GPT-1[2], GPT-2[3] et GPT-3[4] basés sur la pré-formation textuelle utilisent tous des modèles avec Transformer comme structure de base ( Figure 1). La différence réside dans le nombre de couches du modèle et la longueur des vecteurs de mots et autres hyperparamètres. Leur contenu spécifique est présenté dans le tableau 1.
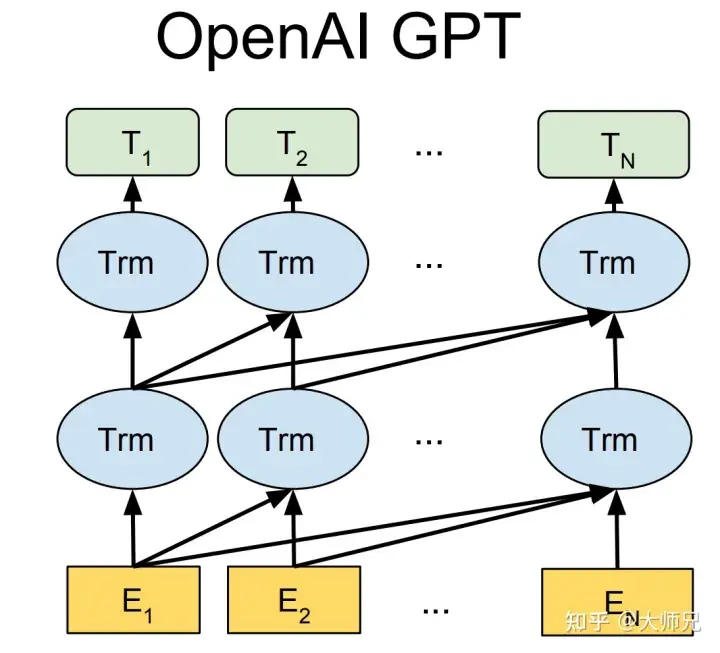
Figure 1 : Structure du modèle de la série GPT (où Trm est une structure de transformateur)
Tableau 1 : Temps de libération, quantité de paramètres et quantité d'entraînement des générations précédentes de GPT
Modèle |
Durée de sortie |
Nombre de couches |
Nombre de têtes |
Longueur du vecteur de mot |
Montant du paramètre |
Quantité de données pré-entraînement |
GPT- 1 |
Juin 2018 |
12 |
12 |
768 |
117 millions |
Environ 5 Go |
GPT-2 |
Février 2019 |
48 |
- |
1600 | 1,5 milliard |
40 Go |
GPT-3 |
Mai 2020 |
96 |
96 |
12888 |
175 milliards |
45 To |
GPT-1 est né quelques mois plus tôt que BERT. Ils utilisent tous Transformer comme structure de base. La différence est que GPT-1 construit les tâches de pré-formation de manière générative de gauche à droite, puis obtient un modèle de pré-formation général qui peut être utilisé pour des tâches en aval comme BERT. . GPT-1 a obtenu des résultats SOTA sur 9 tâches NLP à cette époque, mais la taille du modèle et le volume de données utilisés par GPT-1 étaient relativement petits, ce qui a conduit à la naissance de GPT-2.
Par rapport à GPT-1, GPT-2 n'a pas fait beaucoup de bruit sur la structure du modèle, mais a uniquement utilisé un modèle avec plus de paramètres et plus de données d'entraînement (Tableau 1). L'idée la plus importante de GPT-2 est l'idée selon laquelle « tout apprentissage supervisé est un sous-ensemble de modèles de langage non supervisés ». Cette idée est également le prédécesseur de l'apprentissage rapide. GPT-2 a également fait beaucoup de sensation lors de sa première naissance. Les nouvelles qu'il a générées étaient suffisantes pour tromper la plupart des humains et avoir pour effet de confondre les fausses nouvelles avec les vraies nouvelles. Elle était même qualifiée à l'époque d'"arme la plus dangereuse du monde de l'IA", et de nombreux portails ont ordonné d'interdire l'utilisation des informations générées par GPT-2.
Lorsque GPT-3 a été proposé, en plus de son effet dépassant de loin GPT-2, ce qui a suscité davantage de discussions a été son nombre de 175 milliards de paramètres. En plus du fait que GPT-3 soit capable d'accomplir des tâches courantes de PNL, les chercheurs ont découvert de manière inattendue que GPT-3 avait également de bonnes performances dans l'écriture de codes dans des langages tels que SQL et JavaScript et dans l'exécution d'opérations mathématiques simples. La formation de GPT-3 utilise l'apprentissage en contexte, qui est un type de méta-apprentissage. L'idée centrale du méta-apprentissage est de trouver une plage d'initialisation appropriée à travers une petite quantité de données, afin que le modèle puisse être rapide. s'adapter à des ensembles de données limités et à de bons résultats.
Grâce à l'analyse ci-dessus, nous pouvons voir que du point de vue des performances, GPT a deux objectifs :
- Améliorer les performances du modèle sur les tâches PNL courantes
- Améliorer les performances du modèle sur d'autres tâches PNL atypiques (telles que le code ; écriture), capacité de généralisation sur des opérations mathématiques).
De plus, depuis la naissance du modèle pré-entraîné, un problème qui a été critiqué est le biais du modèle pré-entraîné. Étant donné que les modèles pré-entraînés sont formés sur des modèles avec des niveaux de paramètres extrêmement importants grâce à des données massives, par rapport aux systèmes experts entièrement contrôlés par des règles artificielles, les modèles pré-entraînés sont comme une boîte noire. Personne ne peut garantir que le modèle pré-entraîné ne générera pas de contenu dangereux contenant de la discrimination raciale, du sexisme, etc., car ses dizaines de gigaoctets, voire ses dizaines de téraoctets de données d'entraînement contiennent presque certainement des échantillons d'entraînement similaires. C'est la motivation d'InstructGPT et ChatGPT. Le journal utilise 3H pour résumer leurs objectifs d'optimisation :
- Utile (Utile)
- Trusted (Honnête) ;
- Les modèles de la série GPT d'OpenAI ne sont pas open source, mais ils fournissent un site Web d'essai pour le modèle, et les étudiants qualifiés peuvent l'essayer par eux-mêmes.
1.2 Instruct Learning (Instruct Learning) et Prompt Learning (Prompt Learning) Learning
Instruction Learning est un article intitulé "Les modèles de langage affinés sont des apprenants zéro-shot" par l'équipe Quoc V.Le de Google Deepmind en 2021 [5] idées présentées dans l'article. Le but de l’apprentissage pédagogique et de l’apprentissage rapide est d’exploiter la connaissance du modèle linguistique lui-même. La différence est que Prompt stimule la capacité de complétion du modèle de langage, comme la génération de la seconde moitié de la phrase basée sur la première moitié de la phrase, ou le remplissage cloze, etc. Instruct stimule la capacité de compréhension du modèle de langage. Il permet au modèle de prendre des mesures correctes en donnant des instructions plus évidentes. Nous pouvons comprendre ces deux méthodes d'apprentissage différentes à travers les exemples suivants :
Conseils pour apprendre : J'ai acheté ce collier pour ma copine, elle l'aime beaucoup, ce collier est tellement ____.- Instructions pour l'apprentissage : Déterminez l'émotion de cette phrase : J'ai acheté ce collier pour ma copine et elle l'aime beaucoup. Options : A=bon ; B=moyen ; C=médiocre.
- L'avantage de l'apprentissage des repères est qu'après un réglage précis pour plusieurs tâches, il peut également effectuer un tir nul sur d'autres tâches, tandis que l'apprentissage des repères est entièrement destiné à une seule tâche. La capacité de généralisation est inférieure à l’apprentissage instruit. Nous pouvons comprendre le réglage fin, l’apprentissage indicé et l’apprentissage instruit grâce à la figure 2.
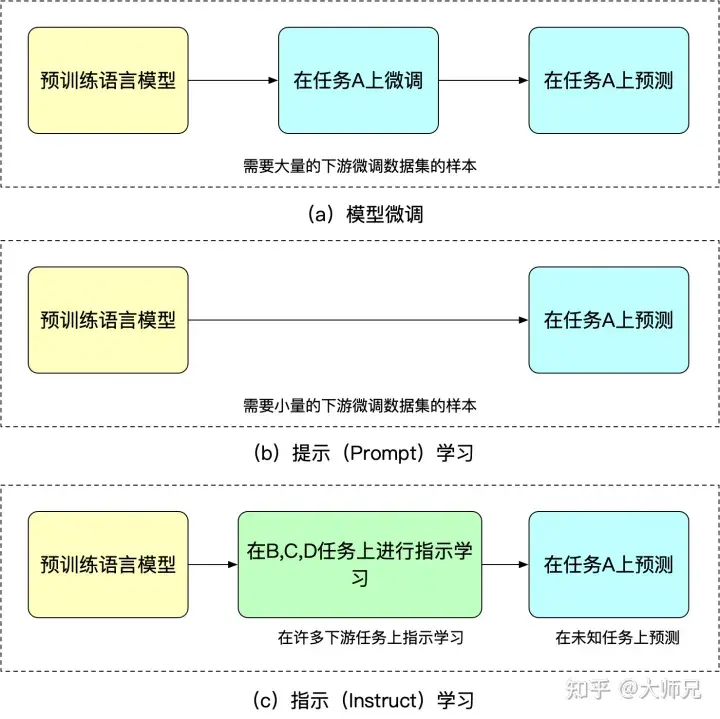 Figure 2 : Similitudes et différences entre le réglage fin du modèle, l'apprentissage rapide et l'apprentissage instruit
Figure 2 : Similitudes et différences entre le réglage fin du modèle, l'apprentissage rapide et l'apprentissage instruit
1.3 Apprentissage par renforcement avec feedback artificiel
Le modèle entraîné n'étant pas très contrôlable, le modèle peut être considéré comme un ajustement de la distribution de l'ensemble d'entraînement. Ensuite, lorsqu'elle est réinjectée dans le modèle génératif, la distribution des données de formation est le facteur le plus important affectant la qualité du contenu généré. Parfois, nous espérons que le modèle sera non seulement affecté par les données d'entraînement, mais également artificiellement contrôlable, afin de garantir l'utilité, l'authenticité et l'innocuité des données générées. La question de l'alignement est mentionnée à plusieurs reprises dans l'article. Nous pouvons la comprendre comme l'alignement du contenu de sortie du modèle et du contenu de sortie que les humains aiment n'inclut pas seulement la fluidité et l'exactitude grammaticale du contenu généré. mais aussi la qualité du contenu généré, l'utilité, l'authenticité et l'innocuité.
Nous savons que l'apprentissage par renforcement guide la formation du modèle via un mécanisme de récompense (Reward). Le mécanisme de récompense peut être considéré comme la fonction de perte du mécanisme traditionnel de formation du modèle. Le calcul des récompenses est plus flexible et diversifié que la fonction de perte (la récompense d'AlphaGO est le résultat du jeu). Le prix est que le calcul des récompenses n'est pas différentiable, il ne peut donc pas être utilisé directement pour la rétropropagation. L'idée de l'apprentissage par renforcement est d'adapter la fonction de perte à travers un grand nombre d'échantillons de récompenses pour réaliser une formation sur modèle. De même, la rétroaction humaine n'est pas non plus dérivable, nous pouvons donc également utiliser la rétroaction artificielle comme récompense pour l'apprentissage par renforcement, et l'apprentissage par renforcement basé sur la rétroaction artificielle est apparu au fur et à mesure que les temps l'exigent.
RLHF remonte à « Deep Reinforcement Learning from Human Preferences » [6] publié par Google en 2017. Il utilise l'annotation manuelle comme retour d'information pour améliorer les performances de l'apprentissage par renforcement sur des robots simulés et des jeux Atari.
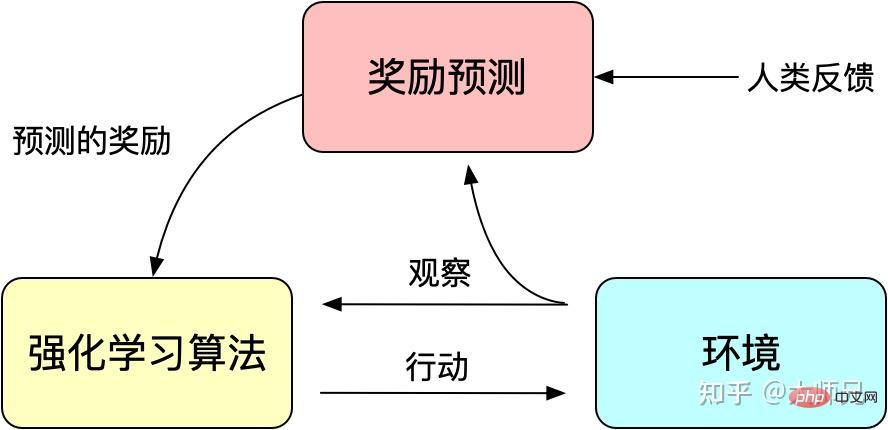
Figure 3 : Le principe de base de l'apprentissage par renforcement avec feedback artificiel
InstructGPT/ChatGPT utilise également un algorithme classique en apprentissage par renforcement : le récent Proximal Policy Optimization (PPO) proposé par OpenAI [7]. L'algorithme PPO est un nouveau type d'algorithme de gradient de politique. L'algorithme de gradient de politique est très sensible à la taille du pas, mais il est difficile de choisir une taille de pas appropriée pendant le processus de formation, si la différence entre l'ancienne et la nouvelle politique est modifiée. est trop grand, cela nuira à l’apprentissage. PPO a proposé une nouvelle fonction d'objectif qui peut réaliser des mises à jour par petits lots en plusieurs étapes de formation, résolvant ainsi le problème selon lequel la taille de l'étape dans l'algorithme Policy Gradient est difficile à déterminer. En fait, TRPO est également conçu pour résoudre cette idée, mais comparé à l'algorithme TRPO, l'algorithme PPO est plus facile à résoudre.
2. Interprétation des principes InstructGPT/ChatGPT
Avec les connaissances de base ci-dessus, il nous sera beaucoup plus facile de comprendre InstructGPT et ChatGPT. Pour faire simple, InstructGPT/ChatGPT adoptent tous deux la structure de réseau de GPT-3 et construisent des échantillons de formation grâce à l'apprentissage d'instructions pour former un modèle de récompense (RM) qui reflète l'effet du contenu prédit. Enfin, le score de ce modèle de récompense est. utilisé pour guider le modèle d’apprentissage par renforcement. Le processus de formation d’InstructGPT/ChatGPT est illustré à la figure 4.
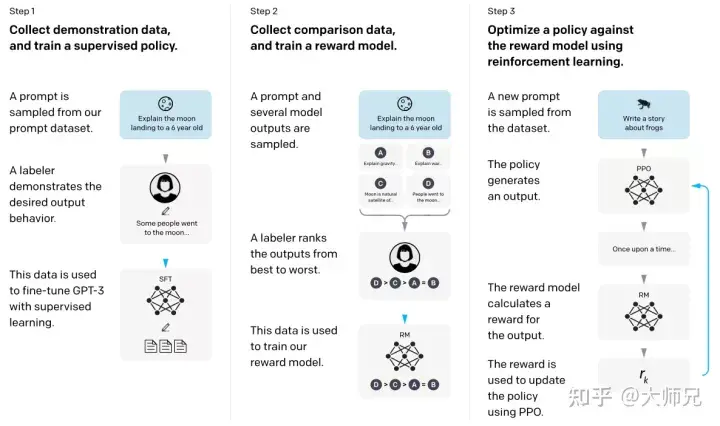
Figure 4 : Processus de calcul InstructGPT : (1) Affinement supervisé (SFT) ; (2) Formation sur le modèle de récompense (RM) ; (3) Apprentissage par renforcement basé sur le modèle de récompense via PPO.
À partir de la figure 4, nous pouvons voir que la formation d'InstructGPT/ChatGPT peut être divisée en 3 étapes, dont les étapes 2 et 3 sont le modèle de récompense et le modèle d'apprentissage par renforcement SFT qui peuvent être optimisés de manière itérative.
- Effectuer un réglage fin supervisé (Supervised FineTune, SFT) de GPT-3 sur la base de l'ensemble de données SFT collectées
- Collecter des données de comparaison étiquetées manuellement et entraîner le modèle de récompense (Reword Model, RM) ; renforcement Objectifs d'optimisation de l'apprentissage, en utilisant l'algorithme PPO pour affiner le modèle SFT.
- Selon la figure 4, nous présenterons respectivement les deux aspects de la collecte d'ensembles de données et de la formation de modèles d'InstructGPT/ChatGPT.
2.1 Collecte d'ensembles de données
Comme le montre la figure 4, la formation d'InstructGPT/ChatGPT est divisée en 3 étapes, et les données requises pour chaque étape sont également légèrement différentes. Nous les présenterons séparément ci-dessous.
2.1.1 Ensemble de données SFT
L'ensemble de données SFT est utilisé pour entraîner le modèle supervisé dans la première étape, c'est-à-dire en utilisant les nouvelles données collectées pour affiner GPT-3 selon la méthode d'entraînement de GPT-3. Étant donné que GPT-3 est un modèle génératif basé sur un apprentissage rapide, l'ensemble de données SFT est également un échantillon composé de paires invite-réponse. Une partie des données SFT provient des utilisateurs de PlayGround d’OpenAI, et l’autre partie provient des 40 étiqueteurs employés par OpenAI. Et ils ont formé l’étiqueteur. Dans cet ensemble de données, le travail de l'annotateur consiste à rédiger des instructions basées sur le contenu, et les instructions doivent répondre aux trois points suivants :
- Tâche simple : l'étiqueteur donne n'importe quelle tâche simple, tout en garantissant la diversité des tâches ;
- Tâche en quelques étapes : l'étiqueteur donne une instruction et plusieurs paires d'instructions correspondant à une requête
- Connexes à l'utilisateur : obtenez des cas d'utilisation ; depuis l'interface, puis laissez l'étiqueteur écrire des instructions basées sur ces cas d'utilisation.
2.1.2 Ensemble de données RM
L'ensemble de données RM est utilisé pour entraîner le modèle de récompense à l'étape 2. Nous devons également définir un objectif de récompense pour la formation d'InstructGPT/ChatGPT. Cet objectif de récompense ne doit pas nécessairement être différenciable, mais il doit s'aligner de manière aussi complète et réaliste que possible sur ce que le modèle doit générer. Naturellement, nous pouvons fournir cette récompense via une annotation manuelle. Grâce à un couplage artificiel, nous pouvons attribuer des scores plus faibles au contenu généré impliquant des biais pour encourager le modèle à ne pas générer de contenu que les humains n'aiment pas. L'approche d'InstructGPT/ChatGPT consiste d'abord à laisser le modèle générer un lot de textes candidats, puis à utiliser l'étiqueteur pour trier le contenu généré en fonction de la qualité des données générées.
2.1.3 Ensemble de données PPO
Les données PPO d'InstructGPT ne sont pas annotées, elles proviennent des utilisateurs de l'API GPT-3. Il existe différents types de tâches de génération fournies par différents utilisateurs, la proportion la plus élevée comprenant les tâches de génération (45,6 %), l'assurance qualité (12,4 %), le brainstorming (11,2 %), le dialogue (8,4 %), etc.
2.1.4 Analyse des données
Étant donné qu'InstructGPT/ChatGPT est affiné sur la base de GPT-3 et qu'il implique une annotation manuelle, leur volume total de données n'est pas important. Le tableau 2 montre les sources des trois données et. leur volume de données.
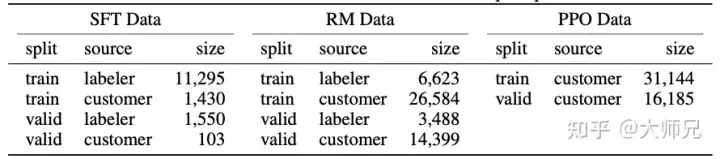
Tableau 2 : Distribution des données d'InstructGPT
L'annexe A du document traite de la distribution des données plus en détail. J'énumère ici quelques éléments qui peuvent affecter l'effet du modèle :
- 96 % des données. ci-dessus est l'anglais, et les 20 autres langues telles que le chinois, le français, l'espagnol, etc. totalisent moins de 4 %. Cela peut permettre à InstructGPT/ChatGPT de générer d'autres langues, mais l'effet devrait être bien moindre. que l'anglais ;
- Il existe 9 types d'invites, et la grande majorité d'entre elles sont des tâches de génération, ce qui peut donner lieu à des types de tâches qui ne sont pas couverts par le modèle
- 40 employés externalisés viennent des États-Unis et d'Asie du Sud-Est ; , avec une distribution relativement concentrée et un petit nombre de personnes. L'objectif d'InstructGPT/ChatGPT est de former une valeur. Pour le bon modèle pré-entraîné, ses valeurs sont composées des valeurs de ces 40 employés externalisés. Et cette répartition relativement étroite peut générer des problèmes de discrimination et de préjugés qui préoccupent davantage d’autres régions.
De plus, le blog ChatGPT a mentionné que les méthodes de formation de ChatGPT et InstructGPT sont les mêmes. La seule différence est qu'ils collectent des données, mais il n'y a pas plus d'informations sur les détails de la collecte des données. Étant donné que ChatGPT n'est utilisé que dans le domaine du dialogue, je suppose que ChatGPT présente ici deux différences dans la collecte de données : 1. Il augmente la proportion de tâches de dialogue ; 2. Il convertit la méthode d'invite en une méthode de questions-réponses. Bien sûr, ce ne sont que des spéculations. Une description plus précise ne sera pas connue tant que des informations plus détaillées telles que les documents et le code source de ChatGPT ne seront pas publiées.
2.2 Tâche de formation
Nous venons d'introduire qu'InstructGPT/ChatGPT dispose d'une méthode de formation en trois étapes. Ces trois étapes de formation feront intervenir trois modèles : SFT, RM et PPO Nous les présenterons en détail ci-dessous.
2.2.1 Réglage fin supervisé (SFT)
La formation dans cette étape est cohérente avec GPT-3, et l'auteur a constaté que permettre au modèle de surajuster de manière appropriée facilitera la formation dans les deux étapes suivantes.
2.2.2 Modèle de récompense (RM)
Étant donné que les données pour la formation RM se présentent sous la forme d'un étiqueteur trié en fonction des résultats générés, elles peuvent être considérées comme un modèle de régression. La structure RM est un modèle qui supprime la couche d'intégration finale du modèle formé par SFT. Ses entrées sont l'invite et la réponse, et sa sortie est la valeur de la récompense. Plus précisément, pour chaque invite, InstructGPT/ChatGPT générera de manière aléatoire K sorties (4≤K≤9), puis affichera les résultats de sortie par paires pour chaque étiqueteur, c'est-à-dire que chaque invite affichera ensuite un total de résultats CK2 à l'utilisateur. sélectionne le meilleur résultat parmi eux. Pendant la formation, InstructGPT/ChatGPT traite les paires de réponses CK2 de chaque invite comme un lot. Cette méthode de formation de regroupement par invite est moins susceptible de surajuster que la méthode traditionnelle de regroupement par échantillon, car cette méthode Chaque invite sera saisie dans le modèle. une seule fois.
La fonction de perte du modèle de récompense est exprimée par l'équation (1). Le but de cette fonction de perte est de maximiser la différence entre la réponse que l’étiqueteur préfère et la réponse qu’il n’aime pas.
(1)loss(θ)=−1(K2)E(x,yw,yl)∼D[log(σ(rθ(x,yw)−rθ(x,yl)))]
où rθ(x,y) est la valeur de récompense de l'invite x et de la réponse y sous le modèle de récompense avec le paramètre θ, yw est le résultat de réponse que l'étiqueteur préfère et yl est le résultat de réponse que l'étiqueteur n'aime pas. D est l'ensemble des données d'entraînement.
2.2.3 Modèle d'apprentissage par renforcement (PPO)
Les modèles d'apprentissage par renforcement et de pré-entraînement sont deux des directions les plus en vogue de l'IA au cours des deux dernières années. De nombreux chercheurs scientifiques ont déjà déclaré que l'apprentissage par renforcement n'est pas une application très appropriée pour le pré-apprentissage. -modèles de formation, car il est difficile d'établir un mécanisme de récompense à travers le contenu de sortie du modèle. InstructGPT/ChatGPT y parvient de manière contre-intuitive. Il introduit l'apprentissage par renforcement dans le modèle de langage pré-entraîné en combinant l'annotation manuelle, ce qui constitue la plus grande innovation de cet algorithme.
Comme le montre le tableau 2, l'ensemble de formation du PPO provient entièrement de l'API. Il utilise le modèle de récompense obtenu à l'étape 2 pour guider la formation continue du modèle SFT. Souvent, l'apprentissage par renforcement est très difficile à entraîner. InstructGPT/ChatGPT a rencontré deux problèmes pendant le processus de formation :
- Problème 1 : à mesure que le modèle est mis à jour, la différence entre les données générées par le modèle d'apprentissage par renforcement et les données utilisées pour l'entraînement. le modèle de récompense Il deviendra de plus en plus grand. La solution de l'auteur consiste à ajouter le terme de pénalité KL βlog(πϕRL(y∣x)/πSFT(y∣x)) à la fonction de perte pour garantir que la sortie du modèle PPO et la sortie de SFT ne sont pas très différentes.
- Problème 2 : utiliser uniquement le modèle PPO pour la formation entraînera une baisse significative des performances du modèle sur les tâches générales de PNL. La solution de l'auteur consiste à ajouter une cible de modèle de langage général γEx∼Dpretrain [log(πϕRL) à la formation. target (x))], cette variable est appelée PPO-ptx dans l'article.
Pour résumer, l'objectif d'entraînement du PPO est la formule (2). (2) objectif (ϕ)=E(x,y)∼DπϕRL[rθ(x,y)−βlog(πϕRL(y∣x)/πSFT(y∣x))]+γEx∼Dpretrain [log( πϕRL(x))]
3. Analyse des performances d'InstructGPT/ChatGPT
Il est indéniable que l'effet d'InstructGPT/ChatGPT est très bon, surtout après l'introduction de l'annotation manuelle, les "valeurs" du modèle sont correctes. Le niveau et « l’authenticité » des modèles de comportement humain ont été considérablement améliorés. Ainsi, simplement sur la base des solutions techniques et des méthodes de formation d’InstructGPT/ChatGPT, nous pouvons analyser quels effets les améliorations peuvent apporter ?
3.1 Avantages
- L'effet d'InstructGPT/ChatGPT est plus réaliste que celui de GPT-3 : ceci est facile à comprendre, car GPT-3 lui-même a de très fortes capacités de généralisation et de génération, et InstructGPT/ChatGPT introduit différentes invites et tris de Labeler. résultats générés et est affiné au-dessus de GPT-3, ce qui nous permet d'avoir des récompenses plus élevées pour des données plus réalistes lors de la formation du modèle de récompense. L'auteur a également comparé leurs performances avec GPT-3 sur l'ensemble de données TruthfulQA. Les résultats expérimentaux montrent que même le PPO-ptx de petite taille de 1,3 milliard fonctionne mieux que GPT-3.
- InstructGPT/ChatGPT est légèrement plus inoffensif que GPT-3 en termes d'innocuité du modèle : le principe est le même que ci-dessus. Cependant, l’auteur a constaté qu’InstructGPT n’améliorait pas de manière significative la discrimination, les préjugés et d’autres ensembles de données. En effet, GPT-3 lui-même est un modèle très efficace et la probabilité de générer des échantillons problématiques avec des conditions nuisibles, discriminatoires, biaisées, etc. est très faible. La simple collecte et l'étiquetage des données via 40 étiqueteurs ne permettront probablement pas d'optimiser pleinement le modèle dans ces aspects, de sorte que l'amélioration des performances du modèle sera faible, voire imperceptible.
- InstructGPT/ChatGPT a de fortes capacités de codage : tout d'abord, GPT-3 possède de fortes capacités de codage, et les API basées sur GPT-3 ont également accumulé une grande quantité de code de codage. Et certains employés internes d'OpenAI ont également participé au travail de collecte de données. Grâce à la grande quantité de données liées au codage et à l'annotation manuelle, il n'est pas surprenant que l'InstructGPT/ChatGPT formé possède de très fortes capacités de codage.
3.2 Inconvénients
- InstructGPT/ChatGPT réduira l'effet du modèle sur les tâches générales de PNL : Nous en avons discuté lors de la formation de PPO Bien que la modification de la fonction de perte puisse l'atténuer, ce problème n'a pas été complètement résolu.
- Parfois, InstructGPT/ChatGPT donnera un résultat ridicule : bien qu'InstructGPT/ChatGPT utilise les commentaires humains, il est limité par des ressources humaines limitées. Ce qui affecte le plus le modèle, c'est la tâche de modèle de langage supervisé, dans laquelle les humains ne jouent qu'un rôle correcteur. Par conséquent, il est très probable qu'il soit limité par le nombre limité de données de correction ou par le caractère trompeur de la tâche supervisée (en considérant uniquement le résultat du modèle, et non ce que veulent les humains), ce qui entraîne le contenu irréaliste qu'il génère. Tout comme un élève, bien qu'il y ait un professeur pour le guider, il n'est pas certain que l'élève puisse apprendre tous les points de connaissance.
- Le modèle est très sensible aux instructions : cela peut également être attribué à la quantité insuffisante de données annotées par l'étiqueteur, car les instructions sont le seul indice permettant au modèle de produire une sortie si le nombre et le type d'instructions ne sont pas correctement formés. , le modèle peut avoir ce problème.
- La surinterprétation par le modèle de concepts simples : cela peut être dû au fait que l'étiqueteur a tendance à accorder des récompenses plus élevées au contenu de sortie plus long lorsqu'il compare le contenu généré.
- Des instructions nuisibles peuvent produire des réponses nuisibles : par exemple, InstructGPT/ChatGPT donnera également un plan d'action pour le "Plan de destruction de l'humanité par l'IA" proposé par l'utilisateur (Figure 5). En effet, InstructGPT/ChatGPT suppose que les instructions écrites par l'étiqueteur sont raisonnables et ont des valeurs correctes, et ne porte pas de jugement plus détaillé sur les instructions données par l'utilisateur, ce qui amènera le modèle à répondre à toute entrée. Bien que le modèle de récompense ultérieur puisse donner une valeur de récompense inférieure à ce type de sortie, lorsque le modèle génère du texte, il doit non seulement prendre en compte les valeurs du modèle, mais également prendre en compte la correspondance du contenu et des instructions générés. Parfois, des problèmes surviennent lors de la génération de certaines valeurs. La sortie est également possible.

Figure 5 : Plan pour détruire l'humanité rédigé par ChatGPT.
3.3 Travaux futurs
Nous avons analysé la solution technique d'InstrcutGPT/ChatGPT et ses problèmes, puis nous pouvons également voir les angles d'optimisation d'InstrcutGPT/ChatGPT.
- Réduction des coûts et augmentation de l'efficacité de l'annotation manuelle : InstrcutGPT/ChatGPT emploie une équipe d'annotation de 40 personnes, mais à en juger par les performances du modèle, cette équipe de 40 personnes n'est pas suffisante. Il est très important de savoir comment permettre aux humains de fournir des méthodes de rétroaction plus efficaces et de combiner de manière organique et habile les performances humaines et les performances des modèles.
- La capacité du modèle à généraliser/corriger les instructions : en tant que seul indice permettant au modèle de produire un résultat, le modèle en dépend fortement. Comment améliorer la capacité du modèle à généraliser les instructions et à corriger les instructions d'erreur est une tâche très importante ? améliorer l'expérience du modèle. Cela permet non seulement au modèle d'avoir une plus large gamme de scénarios d'application, mais rend également le modèle plus « intelligent ».
- Éviter la dégradation générale des performances des tâches : il peut être nécessaire de concevoir une utilisation plus raisonnable du feedback humain ou une structure de modèle plus avancée. Parce que nous avons discuté du fait que de nombreux problèmes d'InstrcutGPT/ChatGPT peuvent être résolus en fournissant davantage de données étiquetées par l'étiqueteur, mais cela entraînera une dégradation plus grave des performances des tâches générales de PNL, des solutions sont donc nécessaires pour améliorer les performances des tâches 3H et générales de PNL qui générer des résultats.
3.4 Réponses aux sujets d'actualité InstrcutGPT/ChatGPT
- L'émergence de ChatGPT fera-t-elle perdre leur emploi aux programmeurs de bas niveau ? À en juger par les principes de ChatGPT et le contenu généré divulgué sur Internet, de nombreux codes générés par ChatGPT peuvent fonctionner correctement. Mais le travail d’un programmeur ne consiste pas seulement à écrire du code, mais surtout à trouver des solutions aux problèmes. Par conséquent, ChatGPT ne remplacera pas les programmeurs, notamment les programmeurs de haut niveau. Au contraire, il deviendra un outil très utile pour les programmeurs pour écrire du code, comme de nombreux outils de génération de code aujourd'hui.
- Stack Overflow annonce une règle temporaire : Interdire ChatGPT. ChatGPT est essentiellement un modèle de génération de texte Par rapport à la génération de code, il est plus efficace pour générer du faux texte. De plus, il n'est pas garanti que le code ou la solution généré par le modèle de génération de texte soit exécutable et puisse résoudre le problème, mais cela déroutera de nombreuses personnes qui se renseigneront sur ce problème en prétendant être du vrai texte. Afin de maintenir la qualité du forum, Stack Overflow a banni ChatGPT et fait également le ménage.
- Le chatbot ChatGPT a été incité à rédiger un « plan pour détruire l'humanité » et à fournir le code. À quels problèmes doivent prêter attention dans le développement de l'IA ? Le « Plan pour détruire l'humanité » de ChatGPT est un contenu généré qu'il a ajusté de force sur la base de données massives selon des instructions imprévues. Bien que le contenu semble très réel et que l'expression soit très fluide, cela montre seulement que ChatGPT a un effet génératif très fort, et cela ne signifie pas que ChatGPT a l'idée de détruire l'humanité. Parce qu'il ne s'agit que d'un modèle de génération de texte, pas d'un modèle de prise de décision.
4. Résumé
Tout comme les algorithmes de nombreuses personnes à leur naissance, ChatGPT a attiré une large attention dans l'industrie et la réflexion humaine sur l'IA en raison de son utilité, de son authenticité et de ses effets inoffensifs. Mais après avoir examiné les principes de son algorithme, nous avons constaté qu’il n’est pas aussi effrayant qu’annoncé dans l’industrie. Au contraire, nous pouvons apprendre beaucoup de choses précieuses de ses solutions techniques. La contribution la plus importante d'InstrcutGPT/ChatGPT dans le monde de l'IA est la combinaison intelligente de modèles d'apprentissage par renforcement et de pré-formation. De plus, le feedback artificiel améliore l’utilité, l’authenticité et l’innocuité du modèle. ChatGPT a également augmenté le coût des grands modèles. Auparavant, il s'agissait simplement d'une compétition entre le volume de données et l'échelle du modèle. Aujourd'hui, il introduit même les coûts d'embauche en sous-traitance, ce qui rend les travailleurs individuels encore plus prohibitifs.
Référence
- ^Ouyang, Long, et al. "Formation de modèles de langage pour suivre les instructions avec des commentaires humains." *Préimpression arXiv arXiv:2203.02155* (2022).
- ^Radford, A., Narasimhan, K., Salimans, T. et Sutskever, I., 2018. Améliorer la compréhension du langage grâce à la pré-formation générative https://www.cs.ubc.ca/~amuham01/LING530. /papers/radford2018improving.pdf
- ^Radford, A., Wu, J., Child, R., Luan, D., Amodei, D. et Sutskever, I., 2019. Les modèles de langage sont des apprenants multitâches non supervisés *OpenAI. blog*, *1*(8), p.9. 9D%E6%8E%A2/langage-models.pdf
- ^Brown, Tom B., Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan et al. « Les modèles linguistiques sont des apprenants rares. ." *Préimpression arXiv arXiv:2005.14165* (2020). https://proceedings.neurips.cc/paper/2020/file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf
- ^Wei, Jason et al. "Les modèles de langage affinés sont nuls -shot learners." *Préimpression arXiv arXiv:2109.01652* (2021). https://arxiv.org/pdf/2109.01652.pdf
- ^Christiano, Paul F., et al. "Apprentissage par renforcement profond à partir des préférences humaines." *Avances dans les systèmes de traitement de l'information neuronale* 30 (2017). https://arxiv.org/pdf/1706.03741.pdf
- ^Schulman, John, et al. "Algorithmes d'optimisation de politique proximale." (2017). https://arxiv.org/pdf/1707.06347.pdf
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI