
Maison >Périphériques technologiques >IA >« Embedding de localisation » : le secret derrière le transformateur
« Embedding de localisation » : le secret derrière le transformateur

- 王林avant
- 2023-04-10 10:01:031096parcourir
Traducteur | Cui Hao
Réviseur | Sun Shujuan
Contenu
- Introduction
- Concept d'intégration en PNL
- Obligatoire pour l'intégration de positions dans Transformers
- Divers types d'expériences initiales d'essais et d'erreurs
- Intégration de position basée sur la fréquence
- Résumé
- Références
Introduction
L'introduction de l'architecture Transformer dans le domaine de l'apprentissage profond est sans aucun doute Le silencieux La révolution a ouvert la voie, notamment pour les branches de la PNL. La partie la plus indispensable de l'architecture Transformer est « l'intégration positionnelle », qui donne au réseau neuronal la capacité de comprendre l'ordre des mots dans les phrases longues et les dépendances entre eux.
Nous savons que RNN et LSTM, qui ont été introduits avant Transformer, ont la capacité de comprendre l'ordre des mots même sans utiliser d'intégrations positionnelles. Ensuite, vous vous demanderez évidemment pourquoi ce concept a été introduit dans Transformer et les avantages de ce concept sont si soulignés. Cet article vous expliquera ces causes et conséquences.
Concept d'intégration en PNLL'intégration est un processus de traitement du langage naturel qui est utilisé pour convertir du texte brut en vecteurs mathématiques. En effet, le modèle d'apprentissage automatique ne sera pas capable de gérer directement le format de texte et de l'utiliser pour divers processus informatiques internes.
Le processus d'intégration d'algorithmes tels que Word2vec et Glove est appelé intégration de mots ou intégration statique.
De cette manière, un corpus de texte contenant un grand nombre de mots peut être transmis au modèle pour l'entraînement. Le modèle attribuera une valeur mathématique correspondante à chaque mot, en supposant que les mots qui apparaissent le plus fréquemment sont similaires. Après ce processus, les valeurs mathématiques résultantes sont utilisées pour d'autres calculs.
Par exemple, considérons que notre corpus de texte comporte 3 phrases, comme suit :
- Le gouvernement britannique accorde chaque année d'importantes subventions au roi et à la reine de Palerme, revendiquant un certain contrôle sur l'administration.
- En plus du roi et de la reine, les membres de la famille royale comprennent également leur fille Marie-Thérèse Charlotte (Madame Royale), la sœur du roi Lady Elizabeth, le valet Clary et d'autres.
- Ceci est interrompu par la nouvelle de la trahison de Mordred, Lancelot n'a pas été impliqué dans le conflit final fatal, il a survécu à la fois au roi et à la reine, ainsi qu'à la chute de la Table ronde.
Ici, nous pouvons voir que les mots « King » et « Queen » apparaissent fréquemment. Par conséquent, le modèle supposera qu’il peut y avoir une certaine similitude entre ces mots. Lorsque ces mots sont convertis en valeurs mathématiques, ils sont placés à une petite distance lorsqu'ils sont représentés dans un espace multidimensionnel.
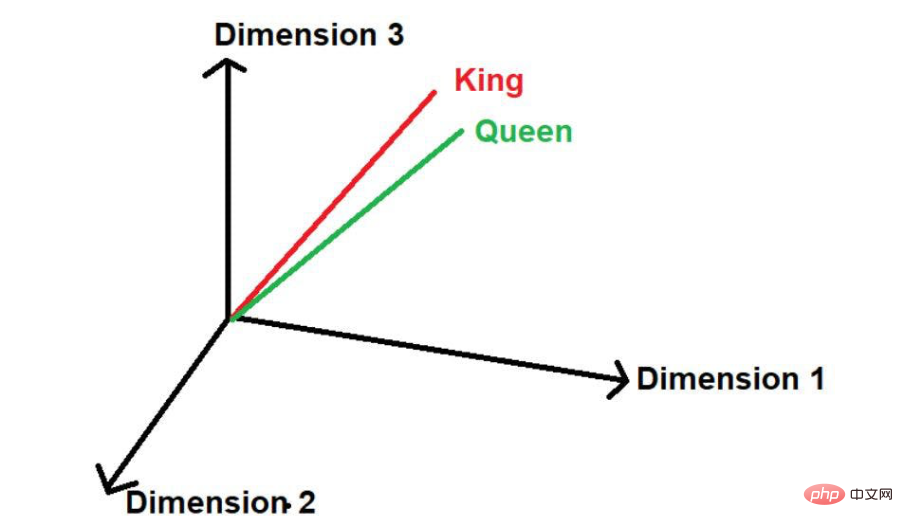
Source de l'image : Illustrations fournies par l'auteur
En supposant qu'il existe un autre mot "route", alors logiquement, il n'apparaîtra pas aussi souvent que "roi" et "reine" dans ce grand corpus de texte . Par conséquent, le mot serait loin de « Roi » et « Reine » et placé très loin ailleurs dans l’espace.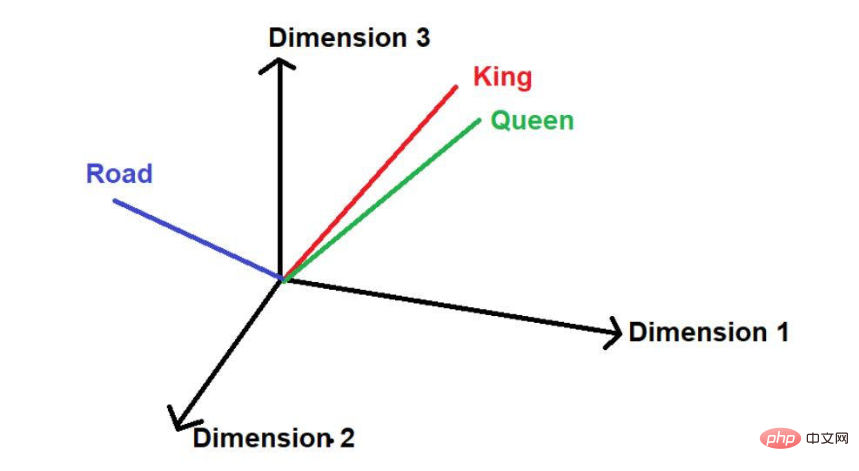
.
Par conséquent, dans les projets PNL, la compréhension des informations de localisation est très critique. Si un modèle utilise simplement des nombres dans un espace multidimensionnel et méconnaît le contexte, cela peut avoir de graves conséquences, notamment dans les modèles prédictifs.
Pour relever ce défi, des architectures de réseaux neuronaux telles que RNN (Recurrent Neural Network) et LSTM (Long Short-Term Memory) ont été introduites. Dans une certaine mesure, ces architectures réussissent très bien à comprendre les informations de localisation. Le principal secret de leur réussite est d’apprendre de longues phrases en préservant l’ordre des mots. En plus de cela, ils disposent également d'informations sur les mots proches du « mot d'intérêt » et les mots éloignés du « mot d'intérêt ».
Par exemple, considérons la phrase suivante :
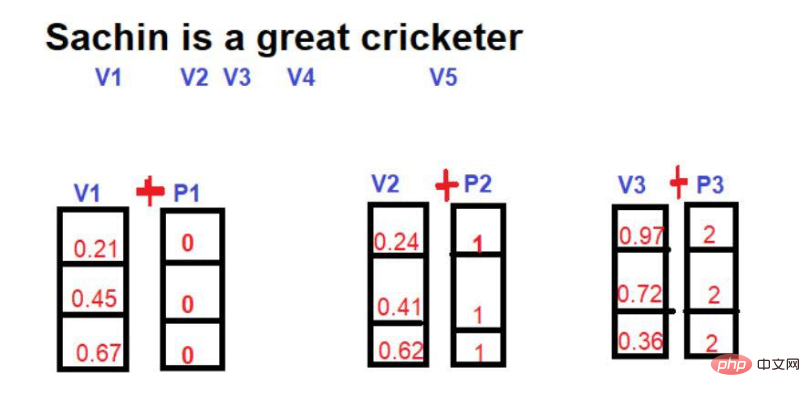
"Sachin est le plus grand joueur de cricket de tous les temps".

Source de l'image : Illustrations fournies par l'auteur
Les mots soulignés en rouge sont les suivants. Vous pouvez voir ici que les « mots d'intérêt » sont parcourus dans l'ordre du texte original.
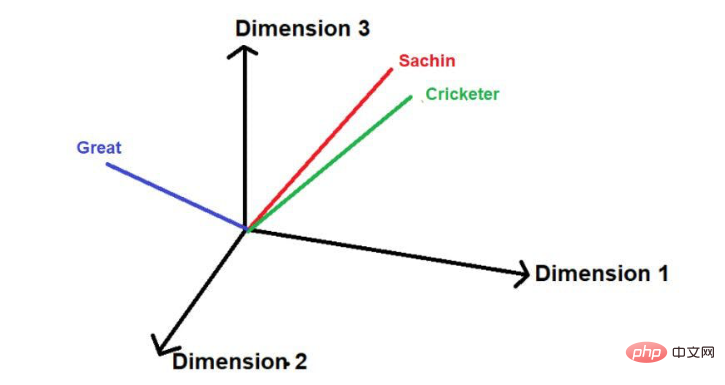
De plus, ils peuvent également comprendre les informations de localisation dans de grands corpus de textes en se souvenant

Source de l'image : Illustrations fournies par l'auteur
Cependant, grâce à ces techniques, RNN/LSTM peut comprendre les informations de localisation dans de grands corpus de textes. Cependant, le véritable problème consiste à effectuer un parcours séquentiel de mots dans un vaste corpus de texte. Imaginez que nous ayons un très grand corpus de texte contenant 1 million de mots, et qu'il faudrait très longtemps pour parcourir chaque mot dans l'ordre. Parfois, il n’est pas possible de consacrer autant de temps de calcul à la formation d’un modèle.
Pour relever ce défi, une nouvelle architecture avancée - "Transformer" est introduite.
Une caractéristique importante de l'architecture Transformer est qu'un corpus de texte peut être appris en traitant tous les mots en parallèle. Que le corpus de texte contienne 10 mots ou 1 million de mots, l'architecture Transformer s'en fiche.

Source de l'image : Illustration fournie par l'auteur

Source de l'image : Illustration fournie par l'auteur
Maintenant, nous devons relever le défi du traitement des mots en parallèle. Étant donné que tous les mots sont accessibles simultanément, les informations sur les dépendances entre les mots sont perdues. Par conséquent, le modèle ne peut pas mémoriser les informations associées à un mot spécifique et ne peut pas les enregistrer avec précision. Cette question nous amène à nouveau au défi initial de préserver les dépendances du contexte malgré une réduction considérable du temps de calcul/d'entraînement du modèle.
Alors, comment résoudre les problèmes ci-dessus ? La solution est
essais et erreurs continus
Au départ, lorsque ce concept a été introduit, les chercheurs étaient très désireux de proposer une méthode optimisée capable de préserver les informations de position dans la structure du transformateur. Dans le cadre d'une expérience d'essais et d'erreurs, la première méthode essayée a été
Ici, l'idée est d'introduire un nouveau vecteur mathématique en utilisant des vecteurs de mots, qui contiennent l'index du mot.
Source de l'image : Illustrations fournies par l'auteur
Supposons que l'image suivante soit la représentation de mots dans un espace multidimensionnel
Source de l'image : Illustrations fournies par l'auteur
Après avoir ajouté la position vecteur, sa taille et sa direction peuvent La position de chaque mot sera modifiée comme indiqué ci-dessous.
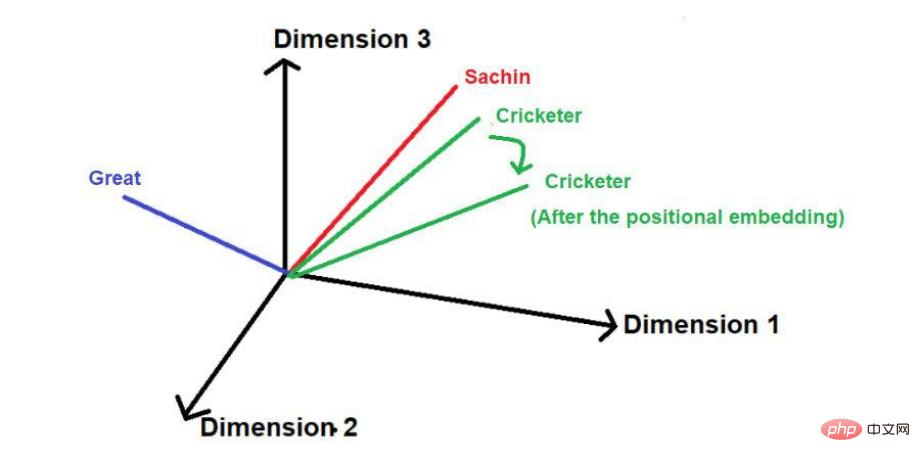
Source de l'image : Illustrations fournies par l'auteur
L'inconvénient de cette technique est que si la phrase est particulièrement longue, le vecteur position augmentera proportionnellement. Disons qu'une phrase contient 25 mots, alors le premier mot aura un vecteur de position de magnitude 0 ajouté, et le dernier mot aura un vecteur de position de magnitude 24 ajouté. Cette énorme incertitude peut poser des problèmes lorsque l’on projette ces valeurs dans des dimensions supérieures.
Une autre technique utilisée pour réduire les vecteurs de position est
Ici, la valeur fractionnaire de chaque mot par rapport à la longueur de la phrase est calculée comme l'ampleur du vecteur de position.
La formule de calcul de la valeur du score est
Valeur=1/N-1
où "N" est la position d'un mot spécifique.
Par exemple, considérons l'exemple ci-dessous -
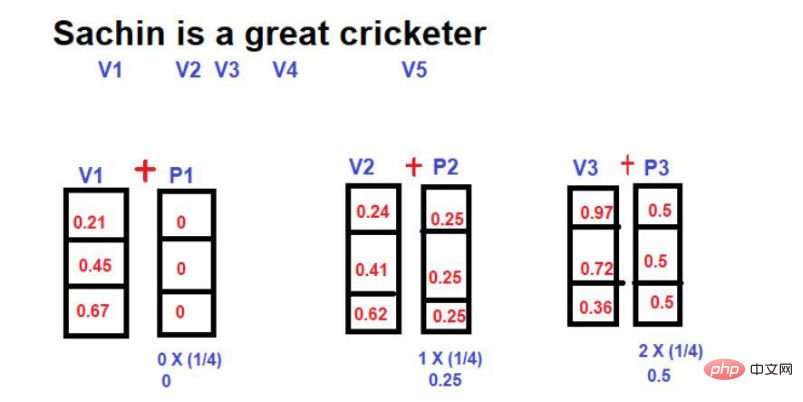
Source de l'image : Illustration fournie par l'auteur
Dans cette technique, l'amplitude maximale du vecteur position peut être limitée à 1 quelle que soit la longueur de la phrase . Il existe cependant une lacune importante. Si vous comparez deux phrases de longueurs différentes, la valeur d'intégration d'un mot à une position spécifique sera différente. Un mot spécifique ou sa position correspondante doit avoir la même valeur d'intégration dans tout le corpus de texte pour faciliter la compréhension de son contexte. Si le même mot dans différentes phrases a des valeurs d’incorporation différentes, représenter les informations d’un corpus de texte dans un espace multidimensionnel devient une tâche très complexe. Même si un espace aussi complexe est mis en œuvre, il est très probable que le modèle s'effondre à un moment donné en raison d'une distorsion excessive de l'information. Par conséquent, cette technique a été exclue du développement de l’intégration positionnelle du transformateur.
Enfin, les chercheurs ont proposé une architecture Transformer et l'ont mentionné dans le célèbre livre blanc : « L'attention est tout ce dont vous avez besoin ». ... " est la position ou la valeur d'index d'un mot spécifique dans une phrase.
« d » est la longueur/dimension maximale du vecteur représentant un mot spécifique dans la phrase.
"i" représente l'indice de la dimension d'intégration de chaque position. Cela signifie aussi la fréquence. Lorsque i=0, elle est considérée comme la fréquence la plus élevée, pour les valeurs suivantes, la fréquence est considérée comme étant d'ampleur décroissante.
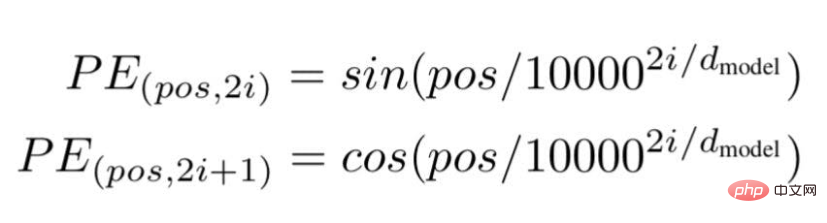
Source de l'image : Illustration fournie par l'auteur
Source de l'image : Illustration fournie par l'auteur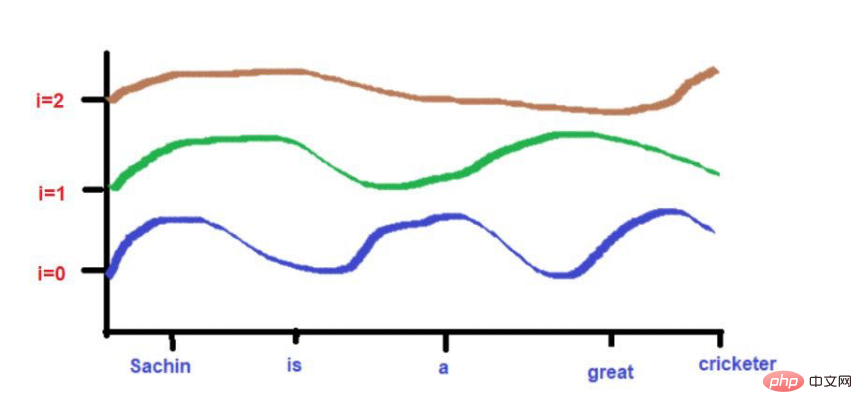
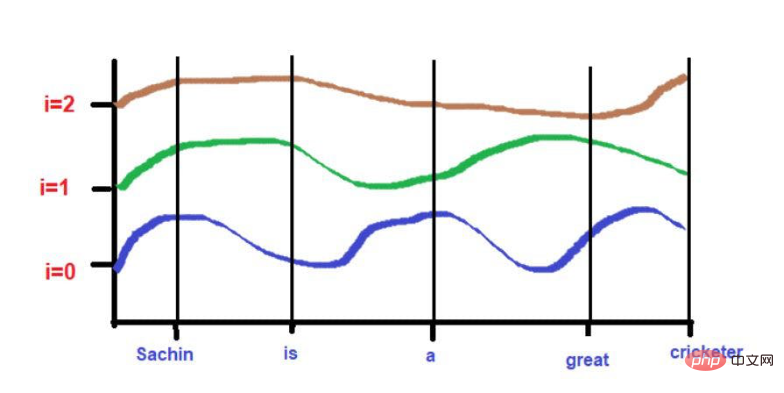 Basé sur notre exemple de texte : "Sachin est un grand joueur de cricket".
Basé sur notre exemple de texte : "Sachin est un grand joueur de cricket".
Pour
pos = 0 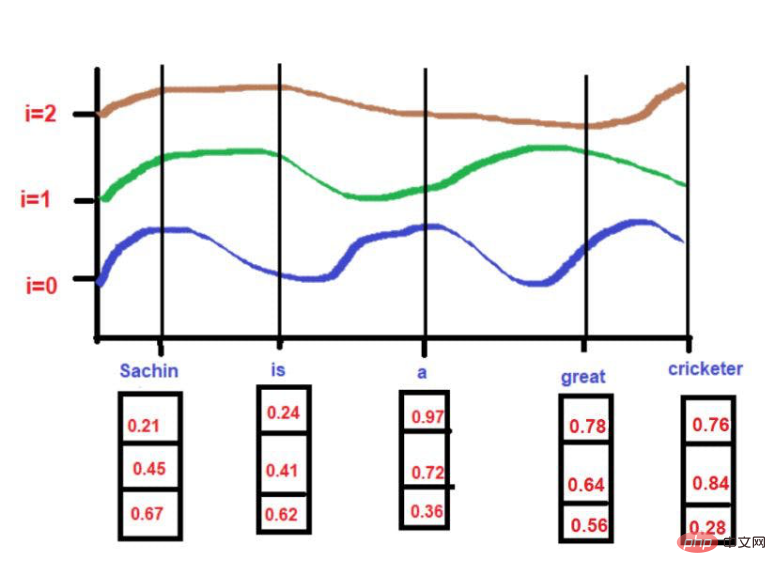
Source de l'image : Illustrations fournies par l'auteur
Quand i =0,
PE(0,0) = sin(0/10000^2(0)/3)
PE(0,0) = sin(0)
PE(0,0) = 0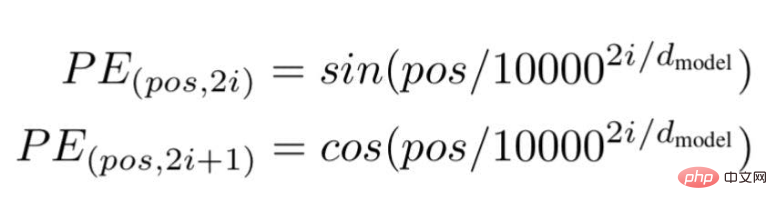
Source de l'image : Illustrations fournies par l'auteur
Quand i =0,
PE(3,0) = sin(3/10000^2(0)/3)
PE(3,0) = sin(3/1)
PE(3,0) = 0,05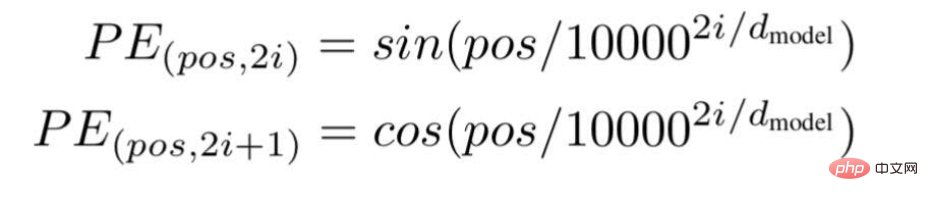
PE(3,2) = sin(3/1.4)PE(3,2) = 0.03
Source de l'image : Illustration fournie par l'auteur
Ici, la valeur maximale sera limitée à 1 (car nous utilisons la fonction sin/cos). Par conséquent, les vecteurs de position de grande ampleur ne posent aucun problème dans les techniques antérieures.
De plus, les mots très proches les uns des autres peuvent tomber à des hauteurs similaires aux fréquences basses, tandis que leurs hauteurs seront un peu différentes aux fréquences plus élevées.
Si la distance entre les mots est très proche, alors leur hauteur sera très différente même à des fréquences plus basses, et leur différence de hauteur augmentera avec la fréquence.
Par exemple, considérons cette phrase : "Le roi et la reine marchaient sur la route".
Les mots « King » et « Road » sont placés plus loin.
Considérez qu'après avoir appliqué la formule de fréquence d'onde, les deux mots ont à peu près la même hauteur. À mesure que nous atteignons des fréquences plus élevées (comme 0), leurs hauteurs deviendront plus différentes.
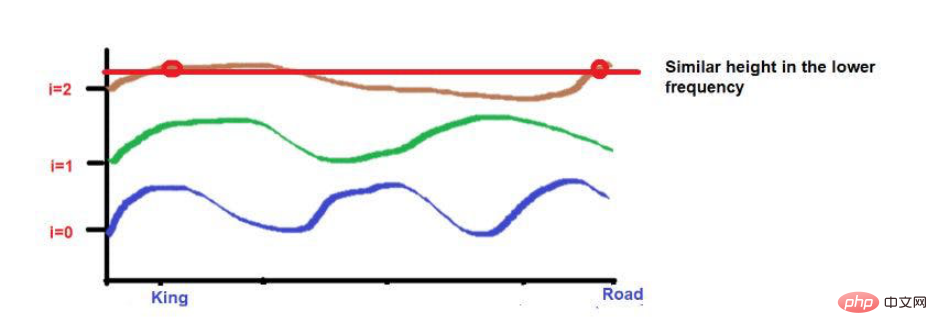
Source de l'image : Illustrations fournies par l'auteur
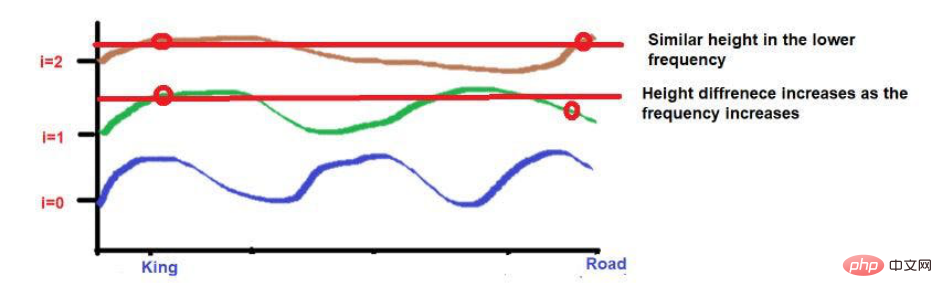
Source de l'image : Illustrations fournies par l'auteur
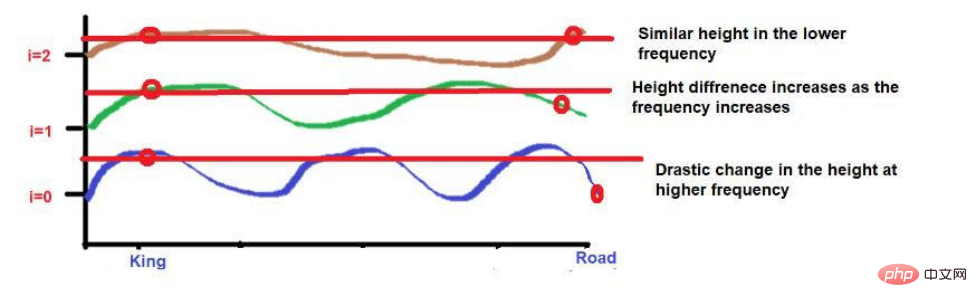
Source de l'image : Illustrations fournies par l'auteur
Et les deux mots "King" et " Reine" soit placée plus près.
Ces 2 mots seront placés à des hauteurs similaires à des fréquences plus basses (comme 2 ici). À mesure que nous atteignons des fréquences plus élevées (comme 0), leur différence de hauteur augmente un peu pour les rendre reconnaissables.
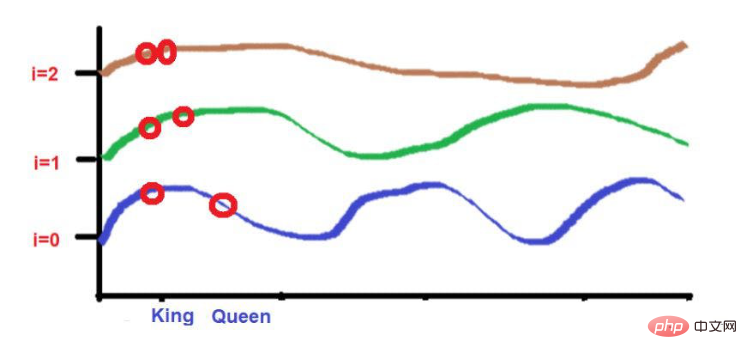
Source de l'image : Illustrations fournies par l'auteur
Mais ce qu'il faut noter, c'est que si la proximité de ces mots est faible, leur hauteur sera très différente en évoluant vers la haute fréquence. Si les mots sont très rapprochés, il n’y aura qu’une petite différence dans leur hauteur à mesure que vous vous déplacez vers des fréquences plus élevées.
Résumé
Grâce à cet article, j'espère que vous avez une compréhension intuitive des calculs mathématiques complexes derrière l'intégration de position dans l'apprentissage automatique. Bref, nous avons discuté de la nécessité d'atteindre certains objectifs.
Pour les passionnés de technologie qui s'intéressent au « traitement du langage naturel », je pense que ces contenus sont utiles pour comprendre des méthodes informatiques complexes. Pour des informations plus détaillées, vous pouvez vous référer au célèbre document de recherche « L’attention est tout ce dont vous avez besoin ».
Introduction du traducteur
Cui Hao, rédacteur de la communauté 51CTO, architecte senior, a 18 ans d'expérience en développement de logiciels et en architecture, et 10 ans d'expérience en architecture distribuée.
Titre original : Embedding positionnel : le secret derrière la précision des réseaux de neurones transformateurs, auteur : Sanjay Kumar
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI