
Maison >Périphériques technologiques >IA >En utilisant une seule ligne de code pour améliorer considérablement l'effet des méthodes d'apprentissage sans tir, l'Université de technologie de Nanjing et Oxford proposent un module de classification plug-and-play.
En utilisant une seule ligne de code pour améliorer considérablement l'effet des méthodes d'apprentissage sans tir, l'Université de technologie de Nanjing et Oxford proposent un module de classification plug-and-play.

- 王林avant
- 2023-04-09 21:51:201204parcourir
Zero-Shot Learning se concentre sur la classification des catégories qui ne sont pas apparues au cours du processus de formation. L'apprentissage Zero-shot basé sur la description sémantique réalise la classification à partir de classes visibles (transfert de connaissances d'une classe vue à une classe invisible). L'apprentissage zéro-shot traditionnel doit uniquement identifier les classes invisibles lors de la phase de test, tandis que l'apprentissage zéro-shot généralisé (GZSL) doit identifier à la fois les classes visibles et invisibles. Ses indicateurs d'évaluation sont la précision moyenne des classes visibles et la précision moyenne des classes invisibles. classes. Moyenne harmonique de précision.
Une stratégie générale d'apprentissage sans tir consiste à utiliser des échantillons de classe visibles et la sémantique pour former un modèle de génération conditionnelle de l'espace sémantique à l'espace d'échantillon visuel, puis à utiliser la sémantique de classe invisible pour générer des pseudo-échantillons de classes invisibles, et enfin à utiliser des classes invisibles. classes Des échantillons et pseudo-échantillons de classes invisibles sont utilisés pour entraîner le réseau de classification. Cependant, l'apprentissage d'une bonne relation de cartographie entre deux modalités (modalité sémantique et modalité visuelle) nécessite généralement un grand nombre d'échantillons (voir CLIP), ce qui ne peut pas être obtenu dans les environnements d'apprentissage zéro-shot traditionnels. Par conséquent, la distribution d'échantillons visuels générée à l'aide d'une sémantique de classe invisible s'écarte généralement de la distribution d'échantillons réelle, ce qui signifie les deux points suivants : 1. La précision de classe invisible obtenue par cette méthode est limitée. 2. Lorsque le nombre moyen de pseudo-échantillons générés par classe pour les classes invisibles est équivalent au nombre moyen d'échantillons pour chaque classe pour les classes visibles, il existe une grande différence entre l'exactitude des classes invisibles et l'exactitude des classes visibles, comme indiqué dans le tableau 1 ci-dessous.

Nous avons constaté que même si nous apprenons uniquement le mappage de la sémantique aux points centraux de catégorie et copions le point d'échantillonnage unique sur lequel la sémantique de classe invisible est mappée plusieurs fois, puis participons à la formation du classificateur, nous pouvons nous rapprocher de l’utilisation de l’effet de modèle génératif. Cela signifie que les caractéristiques invisibles du pseudo-échantillon générées par le modèle génératif sont relativement homogènes pour le classificateur.
Les méthodes précédentes répondent généralement à la métrique d'évaluation GZSL en générant un grand nombre de pseudo-échantillons de classe invisibles (bien qu'un grand nombre d'échantillons ne soit pas utile pour la discrimination inter-classes invisible). Cependant, il a été prouvé que cette stratégie de rééchantillonnage dans le domaine de l'apprentissage à longue traîne entraînait un surajustement du classificateur sur certaines caractéristiques, ce qui est pseudo-invisible et s'écarte des caractéristiques réelles de la classe. Cette situation n’est pas propice à l’identification d’échantillons réels de classes visibles et invisibles. Alors, pouvons-nous abandonner cette stratégie de rééchantillonnage et utiliser à la place le décalage et l'homogénéité de la génération de pseudo-échantillons de classes invisibles (ou le déséquilibre de classes entre les classes vues et les classes invisibles) comme biais inductif ?
Sur cette base, nous avons proposé un module de classificateur plug-and-play qui peut améliorer l'effet de la méthode d'apprentissage génératif zéro-shot en modifiant simplement une ligne de code. Seuls 10 pseudo-échantillons sont générés par classe invisible pour atteindre le niveau SOTA. Par rapport à d'autres méthodes génératives à échantillon nul, la nouvelle méthode présente un énorme avantage en termes de complexité de calcul. Les membres de recherche viennent de l’Université des sciences et technologies de Nanjing et de l’Université d’Oxford.

- Papier : https://arxiv.org/abs/2204.11822
- Code : https://github.com/cdb342/IJCAI-2022-Z LA
Cet article utilise les objectifs cohérents de formation et de test comme guide pour dériver la limite inférieure variationnelle de l'indice d'évaluation de l'apprentissage zéro-shot généralisé. Le classificateur modélisé de cette manière peut éviter d'utiliser la stratégie de réadoption et empêcher le classificateur de surajuster les pseudo-échantillons générés et d'affecter négativement la reconnaissance des échantillons réels. La méthode proposée peut rendre le classificateur basé sur l'intégration efficace dans le cadre de la méthode générative et réduire la dépendance du classificateur à l'égard de la qualité des pseudo-échantillons générés.
Méthode
1. Présentation du prior paramétré
Nous avons décidé de commencer par la fonction de perte du classificateur. En supposant que l'espace des classes a été complété par des pseudo-échantillons générés de classes invisibles, le classificateur précédent est optimisé dans le but de maximiser la précision globale :
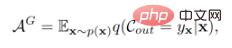

où  est la précision globale,
est la précision globale,  représente la sortie du classificateur,
représente la sortie du classificateur,  représente la distribution de l'échantillon,
représente la distribution de l'échantillon,  est l'étiquette correspondante de l'échantillon X. Les indicateurs d'évaluation de GZSL sont :
est l'étiquette correspondante de l'échantillon X. Les indicateurs d'évaluation de GZSL sont :
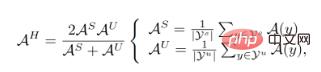

où  et
et  représentent respectivement l'ensemble des classes visibles et invisibles. L'incohérence entre les objectifs de formation et les objectifs de test signifie que les stratégies de formation précédentes des classificateurs ne prenaient pas en compte les différences entre les classes visibles et invisibles. Naturellement, nous essayons d'obtenir des résultats cohérents avec les objectifs d'entraînement et de tests en dérivant
représentent respectivement l'ensemble des classes visibles et invisibles. L'incohérence entre les objectifs de formation et les objectifs de test signifie que les stratégies de formation précédentes des classificateurs ne prenaient pas en compte les différences entre les classes visibles et invisibles. Naturellement, nous essayons d'obtenir des résultats cohérents avec les objectifs d'entraînement et de tests en dérivant  . Après dérivation, nous avons obtenu sa borne inférieure :
. Après dérivation, nous avons obtenu sa borne inférieure :

où  représente la classe visible - la classe invisible a priori, qui est indépendante des données et est ajustée comme un hyperparamètre dans l'expérience,
représente la classe visible - la classe invisible a priori, qui est indépendante des données et est ajustée comme un hyperparamètre dans l'expérience,  représente la classe visible ou l'antériorité interne de classe invisible est remplacée par la fréquence d'échantillonnage de classe vue ou une distribution uniforme pendant le processus de mise en œuvre. En maximisant la limite inférieure de
représente la classe visible ou l'antériorité interne de classe invisible est remplacée par la fréquence d'échantillonnage de classe vue ou une distribution uniforme pendant le processus de mise en œuvre. En maximisant la limite inférieure de  , nous obtenons l'objectif d'optimisation final :
, nous obtenons l'objectif d'optimisation final :

En conséquence, notre objectif de modélisation de classification présente les changements suivants par rapport au précédent :

Par l'utilisation de l'entropie croisée correspond à la probabilité postérieure  , et nous obtenons la perte du classificateur comme :
, et nous obtenons la perte du classificateur comme :

Ceci est similaire à l'ajustement logit dans l'apprentissage à longue traîne, nous l'appelons donc ajustement logit à échantillon nul (ZLA). Jusqu'à présent, nous avons implémenté l'introduction de priorités paramétrées pour implanter le déséquilibre des catégories entre les classes vues et les classes invisibles en tant que biais inductif dans la formation du classificateur, et il suffit d'ajouter des termes de biais supplémentaires aux logits d'origine dans l'implémentation du code pour obtenir ce qui précède. effets.

2. Présentation du prior sémantique
Jusqu'à présent, le noyau du transfert zéro-shot, c'est-à-dire le prior sémantique (prior sémantique), ne joue qu'un rôle dans la formation du générateur et la génération de pseudo-échantillons. entièrement sur la qualité des pseudo-échantillons générés de classes invisibles. Évidemment, si des a priori sémantiques peuvent être introduits lors de la phase de formation du classificateur, cela aidera à identifier les classes invisibles. Dans le domaine de l’apprentissage zéro-shot, il existe une classe de méthodes basées sur l’intégration qui peuvent réaliser cette fonction. Cependant, ce type de méthode est similaire aux connaissances apprises par le modèle génératif, c'est-à-dire le lien entre sémantique et vision (lien sémantique-visuel), qui a conduit à l'introduction directe du cadre génératif précédent (se référer à l'article f -CLSWGAN) basé sur le classificateur intégré ne peut pas obtenir de meilleurs résultats que l'original (à moins que le classificateur lui-même n'ait de meilleures performances de tir nul). Grâce à la stratégie ZLA proposée dans cet article, nous sommes en mesure de modifier le rôle que jouent les pseudo-échantillons de classe invisibles générés dans la formation du classificateur. De la fourniture initiale d'informations sur les classes invisibles à l'ajustement actuel de la frontière de décision entre les classes invisibles et les classes visibles, nous pouvons introduire des priorités sémantiques dans la phase de formation du classificateur. Plus précisément, nous utilisons une méthode d'apprentissage de prototype pour mapper la sémantique de chaque catégorie dans un prototype visuel (c'est-à-dire le poids du classificateur), puis modélisons la probabilité a posteriori ajustée comme la similarité cosinusoïdale entre l'échantillon et le prototype visuel Degré (similitude cosinusoïdale). , c'est-à-dire

où  est le coefficient de température. Dans la phase de test, il est prévu que les échantillons correspondent à la catégorie du prototype visuel présentant la plus grande similarité cosinusoïdale.
est le coefficient de température. Dans la phase de test, il est prévu que les échantillons correspondent à la catégorie du prototype visuel présentant la plus grande similarité cosinusoïdale.

Expériences
Nous avons combiné le classificateur proposé avec le WGAN de base et obtenu des résultats comparables aux SoTA en générant 10 échantillons par classe invisible. De plus, nous l'avons inséré dans la méthode CE-GZSL plus avancée, améliorant l'effet initial sans modifier d'autres paramètres (y compris le nombre d'échantillons générés).

Dans des expériences d'ablation, nous avons comparé un apprenant prototype basé sur une génération avec un apprenant prototype pur. Nous avons constaté que la dernière couche ReLU est essentielle au succès d'un apprenant pur prototype, car la suppression des nombres négatifs augmente la similitude du prototype de catégorie avec les fonctionnalités de classe invisibles (les fonctionnalités de classe invisibles sont également activées par ReLU). Cependant, fixer certaines valeurs à zéro limite également l'expression du prototype, ce qui n'est pas propice à des performances de reconnaissance ultérieures. L'utilisation d'échantillons de classe pseudo-invisibles pour compenser les informations de classe invisibles peut non seulement obtenir des performances plus élevées lors de l'utilisation de RuLU, mais également atteindre une transcendance supplémentaire des performances sans couche ReLU.

Dans une autre étude d'ablation, nous avons comparé un prototype d'apprenant avec un classificateur initial. Les résultats montrent que le prototype d’apprenant n’a aucun avantage sur le classificateur initial lorsqu’il génère un grand nombre d’échantillons de classe invisibles. En utilisant la technologie ZLA proposée dans cet article, le prototype d’apprenant montre sa supériorité. Comme mentionné précédemment, cela est dû au fait que le prototype d'apprenant et le modèle génératif apprennent des connexions sémantiques-visuelles, de sorte que les informations sémantiques sont difficiles à utiliser pleinement. ZLA permet aux échantillons de classe invisibles générés d'ajuster la limite de décision au lieu de simplement fournir des informations de classe invisibles, activant ainsi le prototype d'apprenant.

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI