
Maison >Périphériques technologiques >IA >Rapport détaillé : L'IA basée sur des modèles à grande échelle accélère à tous les niveaux ! La décennie dorée commence
Rapport détaillé : L'IA basée sur des modèles à grande échelle accélère à tous les niveaux ! La décennie dorée commence

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-09 21:31:06950parcourir
Après les « trois hauts et deux bas » des 70 dernières années, avec l'amélioration et le progrès des puces sous-jacentes, de la puissance de calcul, des données et d'autres infrastructures, l'industrie mondiale de l'IA passe progressivement de l'intelligence informatique à l'intelligence perceptuelle et à l'intelligence cognitive. et a formé en conséquence une division industrielle du travail et un système de collaboration « puces, installations de puissance de calcul, cadres d'IA et modèles d'algorithmes, scénarios d'application ». Depuis 2019, les grands modèles d'IA ont considérablement amélioré la capacité à généraliser la résolution de problèmes, et les « grands modèles + petits modèles » sont progressivement devenus la voie technologique dominante dans l'industrie, entraînant l'accélération globale du développement de l'industrie mondiale de l'IA et formant un « Puce + infrastructure de puissance de calcul + IA » La structure stable de la chaîne de valeur industrielle de « bibliothèque de cadres et d'algorithmes + scénarios d'application ».
Pour la référence interne intelligente de ce numéro, nous recommandons le rapport de CITIC Securities « Large Models Drive AI to Accelerate Comprehensively, and the Industry's Golden Ten-Year Investment Cycle Begins » pour interpréter l'état actuel de l'industrie de l'intelligence artificielle et les principaux problèmes de l'industrie. développement. Source : CITIC Securities
1. Les « trois hauts et les trois bas » de l'intelligence artificielle
Depuis que le concept et la théorie de « l'intelligence artificielle » ont été proposés pour la première fois en 1956, le développement de l'industrie et de la technologie de l'IA a principalement traversé trois grandes étapes. étapes de développement.
1) 20century50era~20century70era: sous réserve des performances de la puissance de calcul, du volume de données, etc., plus Restez en théorie niveau. La Conférence de Dartmouth en 1956 a favorisé l'émergence de la première vague mondiale d'intelligence artificielle. À cette époque, une atmosphère optimiste imprégnait l'ensemble du monde universitaire et de nombreuses inventions de classe mondiale ont émergé en termes d'algorithmes, dont un prototype appelé apprentissage par renforcement. L'apprentissage par renforcement est l'idée centrale de l'algorithme AlphaGo de Google. Au début des années 1970, l’IA s’est heurtée à un goulot d’étranglement : les gens ont découvert que les démonstrateurs logiques, les perceptrons, l’apprentissage par renforcement, etc. ne pouvaient effectuer que des tâches très simples et à objectif restreint, et ne pouvaient pas gérer des tâches qui dépassaient légèrement leur portée. La mémoire limitée et la vitesse de traitement des ordinateurs à l’époque n’étaient pas suffisantes pour résoudre les problèmes pratiques d’IA. La complexité de ces calculs augmente de façon exponentielle, ce qui en fait une tâche informatique impossible. Le système expert est la première tentative de commercialisation de l'intelligence artificielle, élevée
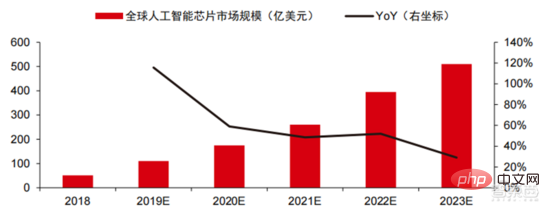
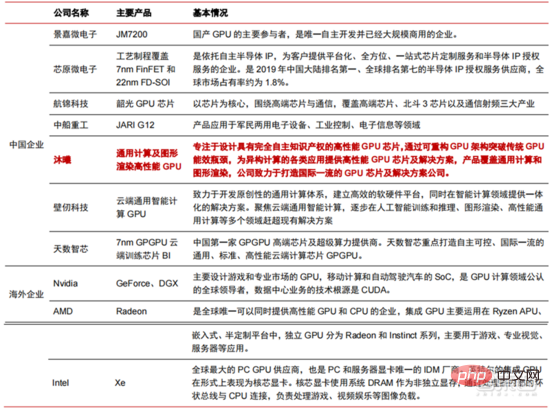
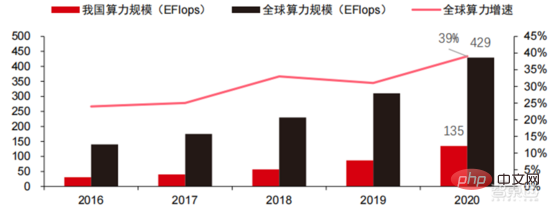
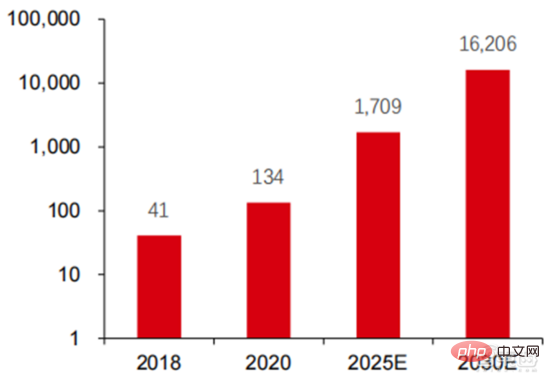
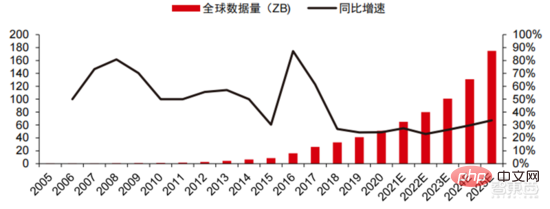
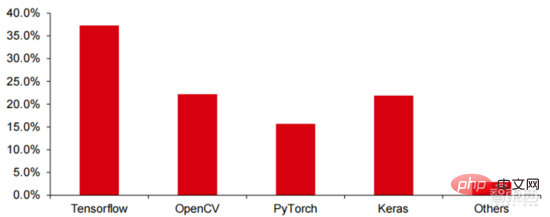
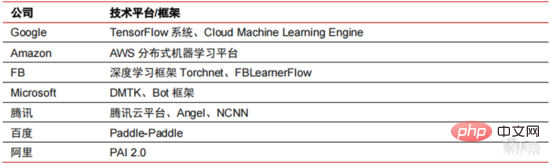
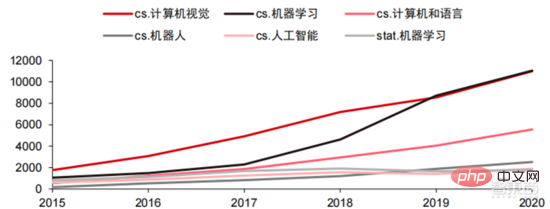
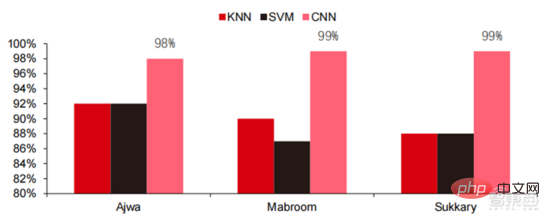
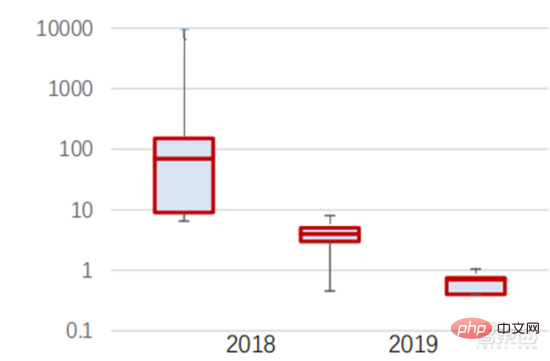
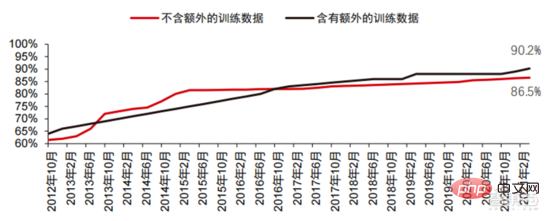
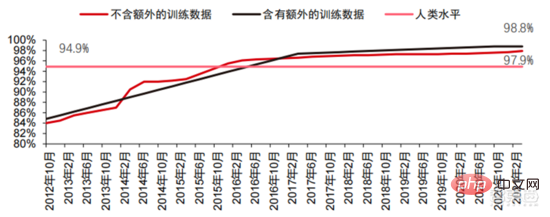
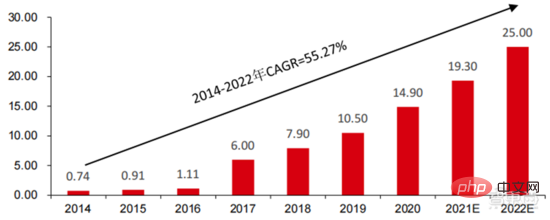
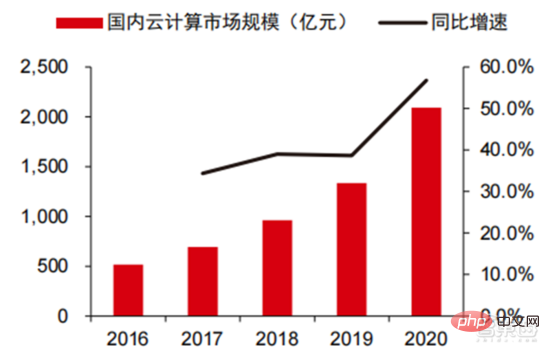
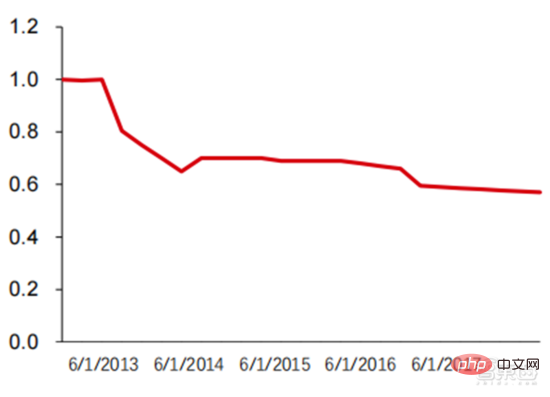
Ang Le coût élevé du matériel et les scénarios applicables limités limitent le développement ultérieur du marché. Dans les années 1980, les programmes d'IA par systèmes experts ont commencé à être adoptés par les entreprises du monde entier, et le « traitement des connaissances » est devenu le centre de la recherche traditionnelle en IA. Les capacités des systèmes experts proviennent des connaissances professionnelles qu’ils stockent, et les systèmes de base de connaissances et l’ingénierie des connaissances sont devenus les principales orientations de la recherche sur l’IA dans les années 1980. Cependant, l'utilité pratique des systèmes experts est limitée à certaines situations, et l'enthousiasme des gens pour les systèmes experts s'est vite transformé en une grande déception. D’un autre côté, l’avènement des PC modernes entre 1987 et 1993 était bien moins coûteux que les machines comme Symbolics et Lisp utilisées par les systèmes experts. Comparés aux PC modernes, les systèmes experts sont considérés comme archaïques et très difficiles à maintenir. En conséquence, le financement gouvernemental a commencé à diminuer et l’hiver est revenu. 3) 2015Année à présenter : Formation progressive d'une chaîne industrielle complète de division du travail et d'un système de collaboration. Le troisième événement marquant dans le domaine de l'intelligence artificielle a eu lieu en mars 2016. AlphaGo développé par Google DeepMind a battu le joueur professionnel coréen neuf dan Lee Sedol dans une bataille de Go homme-machine. Par la suite, le public s’est familiarisé avec l’intelligence artificielle et l’enthousiasme s’est mobilisé dans divers domaines. Cet incident a établi un modèle d'apprentissage profond de classification statistique basé sur l'algorithme de réseau neuronal DNN. Ce type de modèle est plus général que par le passé et peut être appliqué à différents scénarios d'application grâce à différentes extractions de valeurs de caractéristiques. Dans le même temps, la popularité de l’Internet mobile entre 2010 et 2015 a également apporté un apport de données sans précédent aux algorithmes d’apprentissage profond. Grâce à l’augmentation du volume de données, à l’amélioration de la puissance de calcul et à l’émergence de nouveaux algorithmes d’apprentissage automatique, l’intelligence artificielle a commencé à subir des ajustements majeurs. Le domaine de recherche sur l'intelligence artificielle est également en expansion, incluant les systèmes experts, l'apprentissage automatique, l'informatique évolutive, la logique floue, la vision par ordinateur, le traitement du langage naturel, les systèmes de recommandation, etc. Le développement de l’apprentissage profond a amené l’intelligence artificielle à un nouveau point culminant de développement. ▲ La troisième vague de développement de l'intelligence artificielleLa troisième vague de l'intelligence artificielle nous a apporté un certain nombre de scénarios pouvant être commercialisés. Les performances exceptionnelles de l'algorithme DNN ont permis à la reconnaissance vocale et à la reconnaissance d'images de contribuer dans les domaines. de sécurité et d'éducation. Le premier lot de business cases réussis. Ces dernières années, le développement d'algorithmes tels que Transformer basés sur des algorithmes de réseaux neuronaux a mis la commercialisation du NLP (traitement du langage naturel) à l'ordre du jour, et on s'attend à voir des scénarios de commercialisation matures dans les 3 à 5 prochaines années. ▲ Nombre d'années nécessaires à l'industrialisation de la technologie de l'intelligence artificielle Après le développement des 5 à 6 dernières années, le monde L'industrie de l'IA forme progressivement une division du travail et de la collaboration, ainsi qu'une structure de chaîne industrielle complète, et a commencé à former des scénarios d'application typiques dans certains domaines. Chip est le AI les sommets de l'industrie. La prospérité de ce cycle de l'industrie de l'intelligence artificielle est due à la puissance de calcul considérablement améliorée de l'IA, qui rend possible l'apprentissage en profondeur et les algorithmes de réseaux neuronaux multicouches. 人 L'intelligence artificielle pénètre rapidement dans diverses industries et les données augmentent massivement. Cela se traduit par des modèles d'algorithmes extrêmement complexes, des objets de traitement hétérogènes et des exigences de performances informatiques élevées. Par conséquent, l'apprentissage profond de l'intelligence artificielle nécessite des capacités de traitement parallèle extrêmement puissantes. Par rapport aux processeurs, les puces d'IA disposent de davantage d'unités d'opération logiques (ALU) pour le traitement des données et sont adaptées au traitement parallèle de données intensives. Les principaux types incluent les processeurs graphiques (GPU). réseau prédiffusé programmable sur site (FPGA), circuit intégré spécifique à une application (ASIC), etc. Du point de vue des scénarios d'utilisation, le matériel pertinent comprend : les puces d'inférence côté cloud, les puces de test côté cloud, les puces de traitement de terminal, les cœurs IP, etc. Dans la partie « formation » ou « apprentissage » du cloud, le GPU NVIDIA dispose d'un fort avantage concurrentiel, et Google TPU développe également activement son marché et ses applications. Les FPGA et les ASIC peuvent présenter un avantage dans les applications « d'inférence » d'utilisation finale. Les États-Unis disposent de solides avantages dans les domaines des GPU et des FPGA, avec des sociétés avantageuses telles que NVIDIA, Xilinx et AMD, Google et Amazon qui développent également activement des puces IA. ▲ Application de puces dans différents liens d'IA ▲ Complexité du modèle d'algorithme de réseau neuronal d'intelligence artificielle ▲ Disposition du fabricant de puces Sur le marché du calcul haute performance, avec l'aide de calcul parallèle des puces d'IA La capacité à résoudre des problèmes complexes est actuellement la solution dominante. Selon les données de Tractica, la taille du marché mondial du HPC IA était d'environ 1,36 milliard de dollars américains en 2019, et la taille du marché devrait atteindre 11,19 milliards de dollars américains d'ici 2025, avec un TCAC sur sept ans de 35,1 %. La part de marché de l’IA HPC passera de 13,2 % en 2019 à 35,5 % en 2025. Dans le même temps, les données de Tractica montrent que la taille du marché mondial des puces d’IA s’élevait à 6,4 milliards de dollars américains en 2019, et que la taille du marché devrait atteindre 51 milliards de dollars américains d’ici 2023, l’espace de marché étant multiplié par près de 10. ▲ Expéditions de puces Edge computing (en millions, par équipement terminal) ▲ Taille du marché mondial des puces d'intelligence artificielle (milliards de dollars américains) Au cours des deux dernières années, un grand nombre de puces auto-développées Des sociétés chinoises ont vu le jour, représentées par Moore Thread, qui développe des GPU auto-développés, et Cambrian, qui développe des puces de conduite autonomes auto-développées. Moore Thread a publié l'architecture système unifiée MUSA et la puce de première génération « Sudi » en mars 2022. La nouvelle architecture de Moore Thread prend en charge l'architecture CUDA de NVIDIA. Selon les données d'IDC, parmi les puces d'intelligence artificielle chinoises au premier semestre 2021, le GPU a été le premier choix sur le marché, représentant plus de 90 % de la part de marché. Cependant, avec le développement constant d'autres puces, c'est le cas. On s'attend à ce que la proportion de GPU diminue progressivement jusqu'à 80 % d'ici 2025. . ▲ Principaux acteurs et feuille de route technique des puces GPU Dans le passé, le développement de la puissance de calcul a effectivement atténué le problème. goulet d’étranglement du développement de l’intelligence artificielle. En tant que concept ancien, l'intelligence artificielle a été limitée dans son développement passé par une puissance de calcul insuffisante. Ses besoins en puissance de calcul proviennent principalement de deux aspects : 1) L'un des plus grands défis de l'intelligence artificielle est la faible reconnaissance et la faible précision. il est nécessaire d'augmenter l'échelle et la précision du modèle, ce qui nécessite une puissance de calcul plus importante. 2) À mesure que les scénarios d'application de l'intelligence artificielle sont progressivement mis en œuvre, les données dans les domaines de l'image, de la voix, de la vision industrielle et des jeux ont connu une croissance explosive, ce qui a également mis en avant des exigences plus élevées en matière de puissance de calcul, faisant entrer la technologie informatique dans un nouveau cycle de période d'innovation à grande vitesse. Le développement de la puissance de calcul au cours de la dernière décennie a effectivement atténué le goulot d'étranglement du développement de l'intelligence artificielle. À l'avenir, l'informatique intelligente présentera les caractéristiques d'une demande accrue, d'exigences de performances plus élevées et de besoins diversifiés à tout moment et en tout lieu. À mesure qu'elle approche de la limite physique, la loi de Moore sur la croissance de la puissance de calcul expire progressivement et l'industrie de la puissance de calcul est au stade d'une innovation globale de plusieurs éléments. Dans le passé, l'amélioration de l'alimentation électrique des ordinateurs résultait principalement du rétrécissement des processus, c'est-à-dire de l'augmentation du nombre de piles de transistors dans la même puce pour améliorer les performances informatiques. Cependant, à mesure que les processus approchent des limites physiques et que les coûts continuent d'augmenter, la loi de Moore devient progressivement inefficace. L'industrie de l'énergie de calcul entre dans l'ère post-Moore et l'alimentation en énergie de calcul doit être améliorée grâce à une innovation complète de plusieurs facteurs. Il existe actuellement quatre niveaux d'alimentation en énergie de calcul : puissance de calcul monopuce, puissance de calcul de machine complète, puissance de calcul de centre de données et puissance de calcul en réseau, qui évoluent et se mettent à niveau en permanence grâce à différentes technologies pour répondre aux besoins d'approvisionnement en puissance de calcul diversifiée dans l’ère intelligente. En outre, l'amélioration des performances globales des systèmes informatiques grâce à une intégration approfondie des systèmes logiciels et matériels et à l'optimisation des algorithmes constitue également une direction importante pour l'évolution de l'industrie de la puissance de calcul. Échelle de puissance de calcul : Selon le « Livre blanc sur l'indice de développement de la puissance de calcul de la Chine » publié par l'Académie chinoise des technologies de l'information et des communications en 2021, l'échelle totale de la puissance de calcul mondiale maintiendra toujours une tendance à la croissance en 2020, avec une échelle totale de 429EFlops, soit une augmentation d'une année sur l'autre de 39%, dont l'échelle de puissance de calcul de base est de 313EFlops, l'échelle de puissance de calcul intelligente est de 107EFlops et l'échelle de puissance de calcul est de 9EFlops. de puissance de calcul intelligente a augmenté. Le rythme de développement de la puissance de calcul de mon pays est similaire à celui du monde.En 2020, l'échelle totale de la puissance de calcul de mon pays a atteint 135EFlops, représentant 39 % de l'échelle de la puissance de calcul mondiale, atteignant une forte croissance de 55 %, et atteignant un taux de croissance de plus de 40% pendant trois années consécutives. ▲ Changements dans l'échelle de la puissance de calcul mondiale Structure de la puissance de calcul : la situation de développement de mon pays est similaire à celle du monde. La puissance de calcul intelligente croît rapidement, sa proportion passant de 3 % en 2016. à 41% en 2020. La proportion de puissance de calcul de base est passée de 95 % en 2016 à 57 % en 2020. Poussée par la demande en aval, l'infrastructure de puissance de calcul de l'intelligence artificielle représentée par les centres de calcul intelligents s'est développée rapidement. Dans le même temps, en termes de demande future, selon le rapport « Ubiquitous Computing Power : Cornerstone of an Intelligent Society » publié par Huawei en 2020, avec la vulgarisation de l'intelligence artificielle, on s'attend à ce que d'ici 2030, la demande d'intelligence artificielle La puissance de calcul de l'intelligence sera équivalente à 160 milliards de puces Qualcomm. Le Snapdragon 855 possède une puce IA intégrée, ce qui équivaut à environ 390 fois celle de 2018 et environ 120 fois celle de 2020. ▲ Estimation de la demande en puissance de calcul de l'intelligence artificielle (EFlops) en 2030 Stockage de données : les bases de données non relationnelles et les lacs de données utilisés pour stocker et gérer des données non structurées connaissent une explosion de la demande. Ces dernières années, la quantité de données mondiales a connu une croissance explosive. Selon les statistiques d'IDC, la quantité de données générées à l'échelle mondiale en 2019 était de 41 ZB. Le TCAC au cours des dix dernières années était proche de 50 %. le volume de données pourrait atteindre 175 ZB d'ici 2025, et atteindra encore 175 ZB en 2019-2025. Il maintiendra un taux de croissance composé de près de 30 %, et plus de 80 % des données seront des données non structurées telles que du texte et des images. , audio et vidéo, ce qui est difficile à traiter. L'augmentation du volume de données (en particulier les données non structurées) a rendu les faiblesses des bases de données relationnelles de plus en plus évidentes. Face à la croissance exponentielle géométrique des données, le modèle d'extension de données par superposition verticale des bases de données relationnelles traditionnellement conçues pour les données structurées est difficile à satisfaire. Les bases de données non relationnelles et les lacs de données utilisés pour stocker et gérer des données non structurées occupent progressivement une part croissante du marché en raison de leur flexibilité et de leur évolutivité facile. Selon IDC, la taille du marché mondial des bases de données Nosql était de 5,6 milliards de dollars en 2020 et devrait atteindre 19 milliards de dollars en 2025, avec un taux de croissance composé de 27,6 % de 2020 à 2025. Dans le même temps, selon IDC, la taille du marché mondial des lacs de données était de 6,2 milliards de dollars en 2020, et le taux de croissance de la taille du marché en 2020 était de 34,4 %. ▲ Volume mondial de données et taux de croissance d'une année sur l'autre (ZB, %) Tensorflow (industrie), PyTorch (université ) Atteindre progressivement la domination. Tensorflow lancé par Google est le courant dominant et, avec d'autres modules open source tels que Keras (Tensorflow2 intègre le module Keras), le PyTorch open source de Facebook, etc., ils forment le cadre courant actuel pour l'apprentissage de l'IA. Depuis sa création en 2011, Google Brain a mené des recherches sur les applications d'apprentissage profond à grande échelle pour la recherche scientifique et le développement de produits Google. Ses premiers travaux étaient DistBelief, le prédécesseur de TensorFlow. DistBelief est affiné et largement utilisé dans le développement de produits chez Google et d'autres sociétés appartenant à Alphabet. En novembre 2015, sur la base de DistBelief, Google Brain a achevé le développement de TensorFlow, le « système d'apprentissage automatique de deuxième génération » et a rendu le code open source. Par rapport à son prédécesseur, TensorFlow présente des améliorations significatives en termes de performances, de flexibilité architecturale et de portabilité. Bien que Tensorflow et Pytorch soient des modules open source, en raison de l'énorme modèle et de la complexité du cadre d'apprentissage en profondeur, leurs modifications et mises à jour sont essentiellement effectuées par Google. En conséquence, Google et Facebook dominent également directement la direction de mise à jour de Tensorflow et. PyTorch. Le modèle de développement de l’intelligence artificielle de l’industrie. ▲ Structure mondiale des parts de marché du cadre d'intelligence artificielle commerciale (2021) Microsoft a investi 1 milliard de dollars dans OpenAI en 2020 et a obtenu une licence exclusive pour le modèle de langage GPT-3. GPT-3 est actuellement l'application la plus performante en matière de génération de langage naturel. Elle peut non seulement être utilisée pour rédiger des « articles », mais peut également être utilisée pour « générer automatiquement du code ». Depuis sa sortie en juillet de cette année, elle a également été utilisée. considéré par l'industrie comme le modèle de langage d'intelligence artificielle le plus puissant. Facebook a fondé l'AI Research Institute dès 2013. FAIR lui-même n'a pas de modèles et d'applications aussi célèbres qu'AlphaGo et GPT-3, mais son équipe a publié des articles universitaires dans des domaines qui intéressent Facebook lui-même, notamment la vision par ordinateur, Traitement du langage naturel et IA conversationnelle, etc. En 2021, Google avait 177 articles acceptés et publiés par NeurIPS (actuellement la plus haute revue sur les algorithmes d'intelligence artificielle), Microsoft avait 116 articles, DeepMind avait 81 articles, Facebook avait 78 articles, IBM avait 36 articles et Amazon n'avait que 35 articles. L'apprentissage profond est en transition vers un réseau neuronal profond. L'apprentissage automatique est un algorithme informatique qui prédit les images, les sons et d'autres données grâce à l'apprentissage de caractéristiques non linéaires multicouches et à l'extraction de caractéristiques hiérarchiques. Le deep learning est un apprentissage automatique avancé, également connu sous le nom de réseau de neurones profonds (DNN : Deep Neural Networks). Différents réseaux neuronaux et méthodes de formation sont établis pour la formation et l'inférence dans différents scénarios (informations), et la formation est le processus d'optimisation du poids et de la direction de transmission de chaque neurone grâce à une déduction massive de données. Le réseau neuronal convolutif peut prendre en compte des pixels uniques et les variables environnementales environnantes, et simplifier la quantité d'extraction de données, améliorant ainsi encore l'efficacité de l'algorithme du réseau neuronal. L'algorithme de réseau neuronal est devenu le cœur du traitement du Big Data. L'IA effectue un apprentissage en profondeur grâce à des données étiquetées massives, optimise les réseaux et modèles de neurones et introduit le lien d'application du raisonnement et de la prise de décision. Les années 1990 ont été une période de développement rapide des algorithmes d’apprentissage automatique et de réseaux neuronaux, et ces algorithmes ont été utilisés commercialement avec le soutien de la puissance de calcul. Après les années 1990, les domaines d'application pratique de la technologie de l'IA comprennent l'exploration de données, les robots industriels, la logistique, la reconnaissance vocale, les logiciels bancaires, le diagnostic médical et les moteurs de recherche, etc. Le cadre des algorithmes associés est devenu le centre d’intérêt des géants de la technologie. ▲ Cadre de plate-forme algorithmique des grands géants de la technologie En termes d'orientation technologique, la vision par ordinateur et l'apprentissage automatique sont les principales orientations de recherche et développement technologique. Selon les données ARXIV, d'un point de vue théorique, les deux domaines de la vision par ordinateur et de l'apprentissage automatique se sont développés rapidement de 2015 à 2020, suivis par le domaine de la robotique. En 2020, parmi les publications liées à l'IA sur ARXIV, le nombre de publications dans le domaine de la vision par ordinateur a dépassé 11 000, se classant au premier rang en nombre de publications liées à l'IA. ▲Nombre de publications liées à l'IA sur ARXIV de 2015 à 2020 Au cours des cinq dernières années, nous avons observé que les algorithmes de réseaux neuronaux, principalement CNN et DNN, sont les algorithmes d'apprentissage automatique qui connaissent la croissance la plus rapide ces dernières années. En raison de leurs excellentes performances en vision par ordinateur, en traitement du langage naturel et dans d'autres domaines, ils ont grandement progressé. accéléré la vitesse de l’intelligence artificielle. La rapidité de mise en œuvre des applications intelligentes est un facteur clé de la maturité rapide de la vision par ordinateur et de l’intelligence décisionnelle. Comme le montre la vue latérale, la méthode DNN standard présente des avantages évidents par rapport aux méthodes traditionnelles KNN, SVM et forêt aléatoire dans les tâches de reconnaissance vocale. ▲ L'algorithme de convolution brise le goulot d'étranglement en matière de précision du traitement d'image traditionnel et est disponible industriellement pour la première fois En termes de coûts de formation, le coût de formation de l'intelligence artificielle avec des algorithmes de réseaux neuronaux est considérablement réduit. ImageNet est un ensemble de données de plus de 14 millions d'images utilisées pour entraîner des algorithmes d'intelligence artificielle. Selon les tests effectués par l'équipe DAWNBench de Stanford, la formation d'un système de reconnaissance d'images moderne en 2020 ne coûte qu'environ 7,5 dollars américains, soit une baisse de plus de 99 % par rapport aux 1 100 dollars américains de 2017. Cela est principalement dû à l'optimisation de la conception des algorithmes, à la réduction des les coûts de puissance de calcul et les progrès de l’infrastructure de formation en IA à grande échelle. Plus le système peut être formé rapidement, plus il peut être évalué et mis à jour rapidement avec de nouvelles données, ce qui accélérera encore la formation du système ImageNet et augmentera la productivité du développement et du déploiement de systèmes d'intelligence artificielle. En ce qui concerne la répartition du temps de formation, le temps requis pour la formation des algorithmes de réseau neuronal a été réduit dans tous les domaines. En analysant la répartition du temps de formation dans chaque période, on constate qu'au cours des dernières années, le temps de formation a été considérablement raccourci et la répartition du temps de formation est devenue plus concentrée, ce qui profite principalement de l'utilisation généralisée des puces accélératrices. . ▲ Répartition du temps de formation ImageNet (minutes) Poussés par les réseaux de neurones convolutifs, les résultats des tests de précision de vision par ordinateur se sont considérablement améliorés et sont en phase d'industrialisation. La précision de la vision par ordinateur a fait d'énormes progrès au cours de la dernière décennie, principalement grâce à l'application de la technologie d'apprentissage automatique. Test de précision Top-1 Plus un système d'IA est efficace pour attribuer l'étiquette correcte à une image, plus ses prédictions (parmi toutes les étiquettes possibles) sont identiques à l'étiquette cible. Avec des données d'entraînement supplémentaires (telles que des photos des réseaux sociaux), il y a eu 1 erreur pour 10 tentatives au test de précision Top-1 en janvier 2021, contre 1 erreur pour 10 tentatives en décembre 2012. 4 erreurs se produiront. Un autre test de précision, Top-5, demande à l'ordinateur de déterminer si l'étiquette cible fait partie des cinq premières prédictions du classificateur. Sa précision est passée de 85 % en 2013 à 99 % en 2021, dépassant le niveau humain de 94,9 %. ▲ Changements dans la précision TOP-1 ▲ Changements dans la précision TOP-5 Dans le processus de développement d'algorithmes de réseaux neuronaux, le modèle Transformer est devenu courant dans le cinq dernières années, intégrant divers petits modèles dispersés dans le passé. Le modèle Transformer est un modèle PNL classique lancé par Google en 2017 (Bert utilise Transformer). La partie centrale du modèle se compose généralement de deux parties, à savoir l'encodeur et le décodeur. L'encodeur/décodeur est principalement composé de deux modules : le réseau neuronal feedforward (la partie bleue sur l'image) et le mécanisme d'attention (la partie rose-rouge sur l'image). Le décodeur a généralement une attention supplémentaire (cross-over). mécanisme. L'encodeur et le décodeur classent et recentrent les données en imitant le réseau neuronal. Les performances du modèle dépassent RNN et CNN dans les tâches de traduction automatique. Seul l'encodeur/décodeur est nécessaire pour obtenir de bons résultats et peut être efficacement parallélisé. IALa modélisation à grande échelle est une nouvelle tendance qui a émergé au cours des deux dernières années. L'apprentissage auto-supervisé+les solutions de réglage fin et d'adaptation de modèles pré-entraînés sont progressivement devenues courantes, et IA les modèles évoluent vers le support du big data. La généralisation est possible. Les petits modèles traditionnels sont formés avec des données étiquetées dans des domaines spécifiques et ont une faible polyvalence. Ils ne sont souvent pas applicables à un autre scénario d'application et doivent être recyclés. Les grands modèles d'IA sont généralement formés sur des données non étiquetées à grande échelle, et les grands modèles peuvent être ajustés pour répondre aux besoins d'une variété de tâches d'application. Représenté par OpenAI, Google, Microsoft, Facebook, NVIDIA et d'autres institutions, le déploiement de modèles intelligents à grande échelle est devenu une tendance mondiale majeure et a donné naissance à des modèles de base avec de grandes quantités de paramètres tels que GPT-3 et Switch Transformer. Le Megatron-LM développé conjointement par NVIDIA et Microsoft fin 2021 compte 8,3 milliards de paramètres, tandis que le Megatron développé par Facebook compte 11 milliards de paramètres. La plupart de ces paramètres proviennent de Reddit, Wikipédia, de sites d’information, etc. Les outils tels que les lacs de données nécessaires au stockage et à l’analyse de grandes quantités de données seront l’un des axes de recherche et de développement futurs. 5. Scénarios d'application : progressivement mis en œuvre dans les domaines de la sécurité, de l'Internet, du commerce de détail et autres Dans le domaine de la reconnaissance vocale, les sociétés cotées relativement matures incluent iFlytek et Nuance, précédemment acquise par Microsoft pour 29 milliards de dollars. Soins médicaux intelligents : Les soins médicaux sont principalement utilisés dans des scénarios d'assistance médicale. Les produits d'IA dans le domaine médical et de la santé impliquent de multiples scénarios d'application tels que la consultation intelligente, la collecte d'antécédents médicaux, les dossiers médicaux électroniques vocaux, la saisie vocale médicale, le diagnostic d'imagerie médicale, le suivi intelligent et les plateformes cloud médicales. Du point de vue du processus de traitement médical hospitalier, les produits de pré-diagnostic sont principalement des produits d'assistance vocale, tels que les conseils médicaux, la collecte d'antécédents médicaux, etc. ; les produits de diagnostic sont principalement des cas électroniques vocaux et des diagnostics et post-diagnostics assistés par imagerie ; les produits sont principalement des produits de suivi. Compte tenu des différents produits présents dans l'ensemble du processus de traitement médical, les principaux domaines d'application actuels des soins médicaux AI+ restent des scénarios auxiliaires, remplaçant le travail physique et répétitif des médecins. Nuance est la principale entreprise étrangère de soins médicaux IA+. 50 % de ses activités proviennent de solutions médicales intelligentes, et les solutions de transcription de documents médicaux cliniques, tels que les dossiers médicaux, constituent la principale source de revenus du secteur médical. Villes intelligentes : les maladies des grandes villes et la nouvelle urbanisation posent de nouveaux défis à la gouvernance urbaine, stimulant la demande de gouvernance urbaine. Avec l'augmentation de la population et du nombre de véhicules à moteur dans les grandes et moyennes villes, les problèmes tels que la congestion urbaine deviennent plus importants. Avec l’avancée de la nouvelle urbanisation, les villes intelligentes deviendront le principal modèle de développement des villes chinoises. Les technologies IA+sécurité et IA+gestion du trafic impliquées dans les villes intelligentes deviendront les principales solutions de mise en œuvre du côté G. En 2016, Hangzhou a procédé à sa première transformation cérébrale des données urbaines, et l'indice de congestion maximale est tombé en dessous de 1,7. À l'heure actuelle, le cerveau des données urbaines représenté par Alibaba a investi plus de 1,5 milliard de yuans, principalement dans les domaines de la sécurité intelligente et des transports intelligents. L'ampleur de l'industrie des villes intelligentes en Chine continue de croître. L'Institut de recherche prospective sur l'industrie prévoit qu'elle atteindra 25 000 milliards de yuans en 2022, avec un taux de croissance annuel composé moyen de 55,27 % entre 2014 et 2022. Dans le contexte de coûts élevés et de transformation numérique dans le secteur de la logistique, la logistique d'entreposage et la fabrication de produits sont confrontées au besoin urgent d'automatisation, de numérisation et de transformation intelligente pour améliorer l'efficacité de la fabrication et de la circulation. Selon les données de la Fédération chinoise de la logistique et des achats, le marché chinois de la logistique intelligente atteindra 571 milliards de yuans en 2020, avec un taux de croissance annuel composé moyen de 21,61 % entre 2013 et 2020. Les technologies de l'information de nouvelle génération telles que l'Internet des objets, le big data, le cloud computing et l'intelligence artificielle ont non seulement favorisé le développement du secteur de la logistique intelligente, mais ont également mis en avant des exigences de service plus élevées pour le secteur de la logistique intelligente. le marché de la logistique devrait continuer à se développer. Selon les estimations du GGII, la taille du marché chinois de l'entreposage intelligent s'élevait à près de 90 milliards de yuans en 2019, et le Forward Research Institute prévoit que ce chiffre atteindra plus de 150 milliards de yuans en 2025. ▲ Taille et taux de croissance du marché chinois de la logistique intelligente de 2013 à 2020 Nouveau commerce de détail : l'intelligence artificielle réduira les coûts de main-d'œuvre et améliorera l'efficacité opérationnelle. Amazon Go est le concept de magasin sans personnel proposé par Amazon. Le magasin sans personnel a officiellement ouvert ses portes à Seattle, aux États-Unis, le 22 janvier 2018. AmazonGo combine le cloud computing et l'apprentissage automatique, en appliquant la technologie Just Walk Out et Amazon Rekognition. Les caméras en magasin, les moniteurs à capteurs et les algorithmes des machines qui les sous-tendent identifieront les articles que les consommateurs emportent et les vérifieront automatiquement lorsque les clients quitteront le magasin. Il s'agit d'une toute nouvelle révolution dans le domaine du commerce de détail. Les composants des modules d'intelligence artificielle basés sur le cloud sont actuellement la principale direction de commercialisation de l'intelligence artificielle par les grands géants de l'Internet Intégrer la technologie de l'intelligence artificielle dans les services de cloud public à vendre. La technologie d'IA de Google Cloud Platform a toujours été à la pointe du secteur et s'engage à intégrer une technologie d'IA avancée dans les centres de services de cloud computing. Ces dernières années, Google a acquis un certain nombre de sociétés d'IA et lancé des produits tels que des puces TPU spécifiques à l'IA et le service cloud Cloud AutoML pour compléter sa mise en page. À l'heure actuelle, les capacités d'IA de Google couvrent les services cognitifs, l'apprentissage automatique, la robotique, l'analyse et la collaboration de données, ainsi que d'autres domaines. Différent des produits relativement dispersés de certains fournisseurs de cloud dans le domaine de l'IA, Google est plus complet et systématique dans le fonctionnement des produits d'IA. Il intègre les applications verticales dans les composants d'IA de base et intègre l'informatique Tensorflow et TPU dans l'infrastructure, formant ainsi une infrastructure. services complets de plateforme d’IA. Baidu est le fournisseur de cloud public le plus performant en Chine AI La stratégie principale de Baidu AI est l'autonomisation ouverte. Baidu a construit une plateforme d'IA représentée par DuerOS et Apollo pour ouvrir l'écosystème et former une itération positive de données et de scénarios. Sur la base des données de recherche Internet Baidu, les technologies de traitement du langage naturel, de graphes de connaissances et de portraits d'utilisateurs ont progressivement mûri. Au niveau plateforme et écologique, Baidu Cloud est une grande plateforme informatique ouverte à tous les partenaires et devient une plateforme de support de base avec diverses capacités de Baidu Brain. Il existe également des solutions verticales, comme un système d'exploitation de nouvelle génération basé sur une interaction homme-machine basée sur le langage naturel, et Apollo lié à la conduite intelligente. Les constructeurs automobiles peuvent faire appel aux capacités dont ils ont besoin, et les fabricants d'électronique automobile peuvent également faire appel aux capacités correspondantes dont ils ont besoin pour construire conjointement l'ensemble de la plate-forme et de l'écosystème. Ces dernières années, l'évolution technologique de l'industrie de l'IA a principalement montré les caractéristiques suivantes : l'amélioration des performances des modules sous-jacents et l'accent mis sur la capacité de généralisation du modèle, contribuant ainsi à optimiser la polyvalence des algorithmes d'IA et à remonter la collecte de données. Le développement durable de la technologie de l’IA repose sur des percées dans les algorithmes sous-jacents, ce qui nécessite également la construction de capacités de base centrées sur la puissance de calcul et un environnement soutenu par le Big Data pour l’apprentissage des connaissances et de l’expérience. La popularité rapide des grands modèles dans l'industrie, le mode de fonctionnement des grands modèles + petits modèles et l'amélioration continue des capacités des liens sous-jacents tels que les puces et l'infrastructure de puissance de calcul, ainsi que l'amélioration continue qui en résulte dans les catégories de scénarios d'application et la profondeur des scénarios et, en fin de compte, cela entraînera une promotion mutuelle continue entre les capacités industrielles de base et les scénarios d'application, et conduira le développement de l'industrie mondiale de l'IA à continuer de s'accélérer dans la logique d'un cycle positif. Les grands modèles apportent de fortes capacités générales de résolution de problèmes. Actuellement, la plupart des intelligences artificielles sont dans un « style d'atelier manuel ». Face aux applications en aval dans diverses industries, l'IA a progressivement montré des caractéristiques de fragmentation et de diversification, et la polyvalence des modèles n'est pas élevée. Afin d'améliorer les capacités générales de résolution, les grands modèles offrent une solution réalisable, à savoir « pré-formation de grands modèles + réglage fin des tâches en aval ». Cette solution consiste à capturer des connaissances à partir d'une grande quantité de données étiquetées et non étiquetées, à améliorer les capacités de généralisation du modèle en stockant les connaissances dans un grand nombre de paramètres et en affinant des tâches spécifiques. Le grand modèle devrait encore dépasser les limites de précision de la structure de modèle existante et, combiné à la formation de petits modèles imbriqués, améliore encore l'efficacité du modèle dans des scénarios spécifiques. Au cours des dix dernières années, l'amélioration de la précision du modèle reposait principalement sur les changements structurels du réseau. Cependant, à mesure que la technologie de conception de la structure du réseau neuronal mûrit progressivement et tend à converger, l'amélioration de la précision a atteint un goulot d'étranglement et son application. les grands modèles devraient briser ce goulot d'étranglement. En prenant comme exemple le modèle de transfert visuel Big Transfer, BiT de Google, deux ensembles de données, ILSVRC-2012 (1,28 million d'images, 1 000 catégories) et JFT-300M (300 millions d'images, 18 291 catégories), sont utilisés pour entraîner ResNet50 à la précision. Ils sont respectivement de 77 % et 79 %. L'utilisation de grands modèles améliore encore la précision des goulots d'étranglement. De plus, en utilisant JFT-300M pour entraîner ResNet152x4, la précision peut augmenter jusqu'à 87,5 %, soit 10,5 % de plus que la structure ILSVRC-2012+ResNet50. Grand modèle+Petit modèle : La promotion de l'intelligence artificielle grand modèle généralisée et combinée à l'optimisation des données dans des scénarios spécifiques deviendra la clé de la commercialisation de l'industrie de l'intelligence artificielle à moyen terme. Le modèle original de réextraction de données pour des scénarios spécifiques s'est avéré difficile à rentabiliser. Le coût de recyclage du modèle est trop élevé et le modèle obtenu est peu polyvalent et difficile à réutiliser. Dans le contexte de l'amélioration continue des performances du calcul sur puce, la tentative d'imbriquer les grands modèles dans les petits modèles offre aux fabricants une autre idée. En analysant des données massives, ils peuvent obtenir des modèles à usage général, puis imbriquer des petits modèles spécifiques pour fournir des solutions. différents scénarios. Optimisé et économisé beaucoup de coûts. Les fournisseurs de cloud public tels qu'Alibaba Cloud, Huawei Cloud et Tencent Cloud développent activement des plates-formes de grands modèles auto-développées pour améliorer la généralité des modèles. Les géants des puces AI représentés par NVIDIA ont spécialement conçu de nouveaux moteurs pour les modèles AI couramment utilisés dans l'industrie dans la nouvelle génération de puces afin d'améliorer considérablement les capacités informatiques. Comme vous pouvez le voir sur la figure, le prix du produit m1.large avec 2 vCPU, 2 ECU et 7,5 Go a continué de baisser, passant d'environ 0,4 $/heure en 2008 à environ 0,18 $/heure en 2022. Le prix d'utilisation à la demande du produit n1-standard-8 de Google Cloud avec 8 vCPU et 30 Go de mémoire a également chuté, passant de 0,5 USD/heure en 2014 à 0,38 USD/heure en 2022. On peut constater que les prix du cloud computing sont en hausse. une tendance globale à la baisse. Au cours des 3 à 5 prochaines années, nous verrons davantage d’offres d’IA en tant que service (AIaaS). La tendance à grande échelle mentionnée précédemment, en particulier la naissance de GPT-3, a déclenché cette tendance. En raison du grand nombre de paramètres de GPT-3, il doit être exécuté sur une énorme puissance de calcul dans le cloud public, telle que des installations informatiques à l'échelle d'Azure. donc Microsoft En faire un service accessible via une API Web favorisera également l'émergence de modèles plus volumineux. ▲ Prix standardisé historique AWS EC2 (USD/heure) Avec la prise en charge des conditions actuelles de puissance de calcul et des capacités techniques prévisibles, le côté application continuera à réaliser l'itération et l'optimisation des algorithmes grâce à l'acquisition de données, et à améliorer la compréhension actuelle. Il existe encore des carences en matière d'intelligence (sens reconnaissance d'images), et tenter d'évoluer vers une intelligence décisionnelle. Selon les capacités techniques actuelles et la puissance de calcul du matériel, il faudra encore beaucoup de temps pour parvenir à une intelligence décisionnelle complète ; la création d'une intelligence locale basée sur l'approfondissement continu des scénarios existants sera la principale orientation d'ici 3 à 5 ans. Le niveau actuel d'application de l'IA est encore trop concentré, et l'achèvement de la connexion en série locale deviendra la première étape pour parvenir à une intelligence décisionnelle. Les applications logicielles d'intelligence artificielle incluront du pilote inférieur au cadre d'applications et d'algorithmes supérieur, depuis les applications commerciales (fabrication, finance, logistique, vente au détail, immobilier, etc.) jusqu'aux personnes (métaverse, médical, robots humanoïdes, etc.) ), la conduite autonome et d'autres domaines. Zhixixi estime qu'avec l'amélioration continue des éléments de base tels que les puces d'IA, les installations de puissance de calcul et les données, ainsi que l'amélioration substantielle des capacités généralisées de résolution de problèmes apportées par les grands modèles, l'industrie de l'IA forme une « puce » + infrastructure de puissance de calcul + IA" Avec la structure stable de la chaîne de valeur industrielle de "Bibliothèque de cadres et d'algorithmes + scénario d'application", fabricants de puces IA, fabricants de cloud computing (installations de puissance de calcul + cadre d'algorithme), fabricants de scénarios d'IA + d'application, cadre d'algorithme de plate-forme les fabricants, etc. devraient continuer à devenir les principaux bénéficiaires de l’industrie. 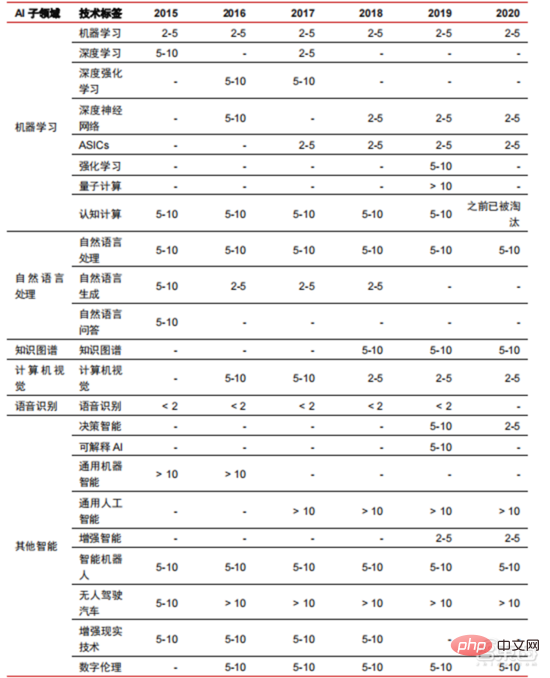
2. La division du travail s'achève progressivement et les scénarios de mise en œuvre s'élargissent constamment
1. Puces AI : Du GPU au FPGA, ASIC, etc., les performances s'améliorent constamment
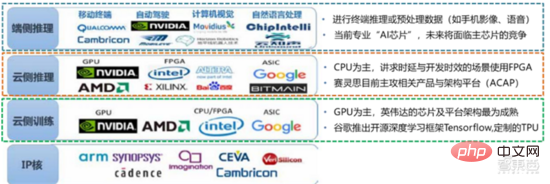
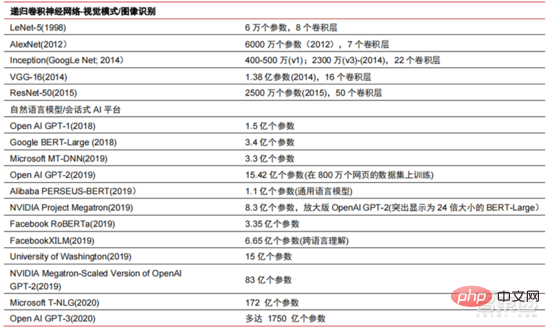
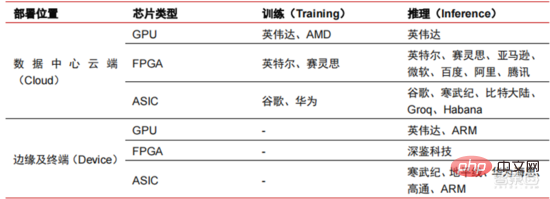
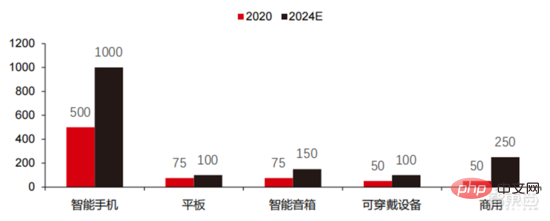
2. Installations de puissance de calcul : grâce au cloud computing, à l'auto-construction et à d'autres méthodes, des indicateurs tels que l'échelle de puissance de calcul et le coût unitaire ont été continuellement améliorés
3. Framework d'IA : relativement mature, dominé par quelques géants
4. Modèle d'algorithme : l'algorithme de réseau neuronal est la principale base théorique
3. Changements industriels : les grands modèles d'IA deviennent progressivement courants et le développement industriel devrait s'accélérer dans tous les domaines
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI