
Maison >Périphériques technologiques >IA >Graph-DETR3D : repenser les régions qui se chevauchent dans la détection d'objets 3D multi-vues
Graph-DETR3D : repenser les régions qui se chevauchent dans la détection d'objets 3D multi-vues

- PHPzavant
- 2023-04-09 18:51:13840parcourir
Article arXiv "Graph-DETR3D: Rethinking Overlapping Regions for Multi-View 3D Object Detection", 22 juin, travaux de l'Université des sciences et technologies de Chine, de l'Institut de technologie de Harbin et de SenseTime.

La détection d'objets 3D à partir de plusieurs vues d'images est une tâche fondamentale mais difficile dans la compréhension des scènes visuelles. En raison de son faible coût et de sa grande efficacité, la détection d’objets 3D multi-vues offre de larges perspectives d’application. Cependant, en raison du manque d’informations sur la profondeur, il est extrêmement difficile de détecter avec précision des objets par perspective dans un espace 3D. Récemment, DETR3D a introduit un nouveau paradigme de requête 3D-2D pour agréger des images multi-vues pour la détection d'objets 3D et a atteint des performances de pointe.
Grâce à des expériences guidées intensives, cet article quantifie les cibles situées dans différentes régions et constate que les « instances tronquées » (c'est-à-dire les régions limites de chaque image) sont le principal goulot d'étranglement entravant les performances de DETR3D. Malgré la fusion de plusieurs fonctionnalités de deux vues adjacentes dans des régions qui se chevauchent, DETR3D souffre toujours d'une agrégation de fonctionnalités insuffisante et manque donc l'opportunité d'améliorer pleinement les performances de détection.
Pour résoudre ce problème, Graph-DETR3D est proposé pour agréger automatiquement les informations d'image multi-vues grâce à l'apprentissage de la structure graphique (GSL). Une carte 3D dynamique est construite entre chaque requête cible et une carte de fonctionnalités 2D pour améliorer la représentation cible, en particulier dans les régions limites. De plus, Graph-DETR3D bénéficie d'une nouvelle stratégie de formation multi-échelle invariante en profondeur, qui maintient la cohérence de la profondeur visuelle en mettant simultanément à l'échelle la taille de l'image et la profondeur cible.
Graph-DETR3D diffère sur deux points, comme le montre la figure : (1) module d'agrégation de fonctionnalités de graphe dynamique (2) stratégie de formation multi-échelle invariante en profondeur ; Il suit la structure de base de DETR3D et se compose de trois composants : un encodeur d'image, un décodeur de transformateur et une tête de prédiction de cible. Étant donné un ensemble d'images I = {I1, I2,…, IK} (capturées par N caméras péri-vue), Graph-DETR3D vise à prédire l'emplacement et la catégorie de la boîte englobante d'intérêt. Tout d’abord, utilisez un encodeur d’image (comprenant ResNet et FPN) pour transformer ces images en un ensemble de fonctionnalités F relativement L au niveau de la carte. Ensuite, un graphique 3D dynamique est construit pour agréger de manière approfondie les informations 2D via le module d'agrégation de fonctionnalités de graphique dynamique (DGFA) afin d'optimiser la représentation de la requête cible. Enfin, la requête cible améliorée est utilisée pour générer la prédiction finale.
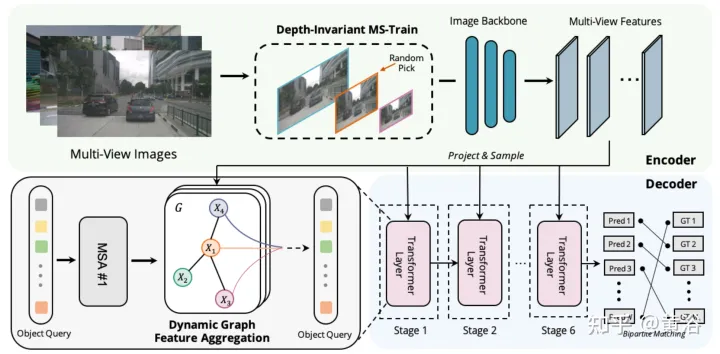
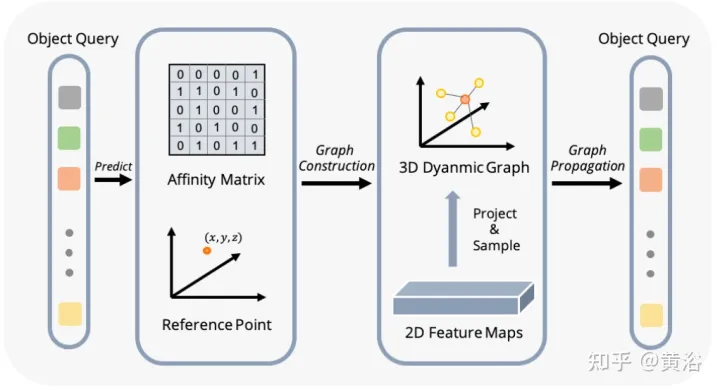
La figure montre le processus d'agrégation de caractéristiques de graphique dynamique (DFGA) : construisez d'abord un graphique 3D apprenable pour chaque requête cible, puis échantillonnez les caractéristiques du plan d'image 2D. Enfin, la représentation de la requête cible est améliorée grâce à des connexions graphiques. Ce schéma de propagation de messages interconnectés prend en charge le raffinement itératif de la construction de la structure graphique et l'amélioration des fonctionnalités.
La formation multi-échelle est une stratégie d'augmentation des données couramment utilisée dans les tâches de détection d'objets 2D et 3D, qui s'est avérée être une inférence efficace et peu coûteuse. Cependant, il apparaît rarement dans les méthodes d’inspection 3D basées sur la vision. La prise en compte de différentes tailles d'image d'entrée peut améliorer la robustesse du modèle, tout en ajustant la taille de l'image et en modifiant les paramètres internes de la caméra pour mettre en œuvre une stratégie de formation multi-échelle commune.
Un phénomène intéressant est que la performance finale chute fortement. En analysant soigneusement les données d'entrée, nous avons découvert que le simple redimensionnement de l'image conduit à un problème d'ambiguïté de perspective : lorsque la cible est redimensionnée à une échelle plus grande/plus petite, ses propriétés absolues (c'est-à-dire la taille de la cible, la distance à l'ego) point) ne changez pas.
À titre d'exemple concret, la figure montre ce problème ambigu : bien que la position 3D absolue de la zone sélectionnée en (a) et (b) soit la même, le nombre de pixels de l'image est différent. Les réseaux de prédiction de profondeur ont tendance à estimer la profondeur en fonction de la zone occupée de l'image. Par conséquent, ce modèle d'entraînement dans la figure peut confondre le modèle de prédiction de profondeur et détériorer davantage les performances finales.

Recalculez la profondeur du point de vue des pixels pour cela. Le pseudo code de l'algorithme est le suivant :

Voici l'opération de décodage :

La taille de pixel recalculée est :
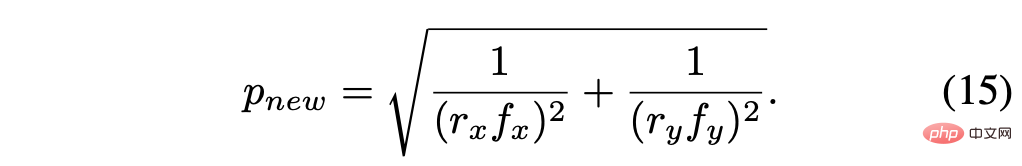
En supposant le facteur d'échelle r = rx = ry, alors le le résultat simplifié est :
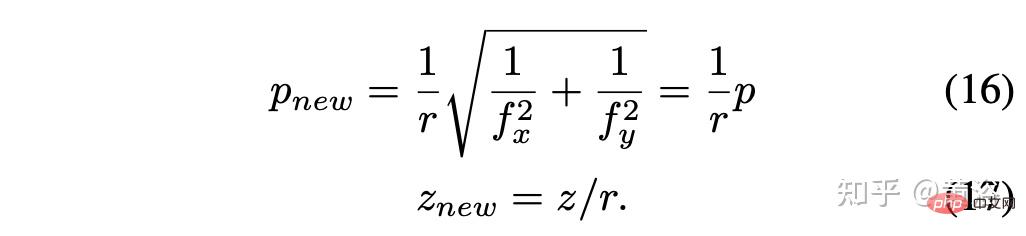
Les résultats expérimentaux sont les suivants :
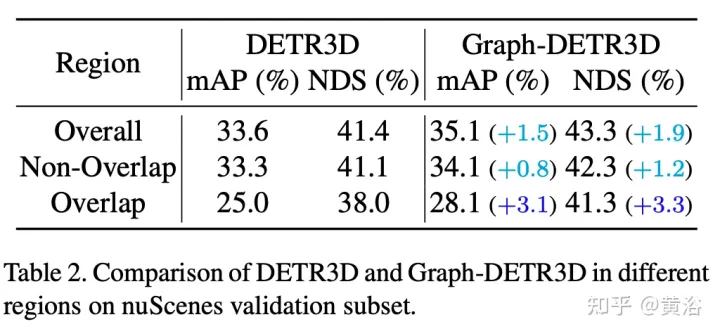
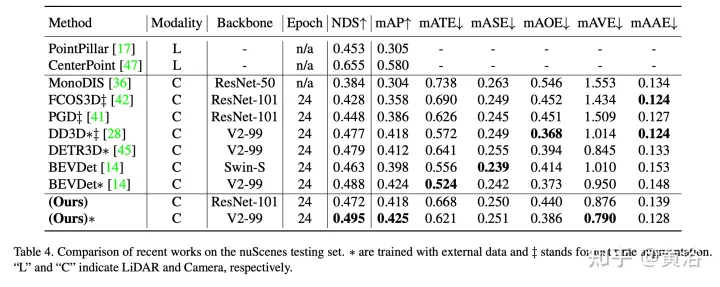
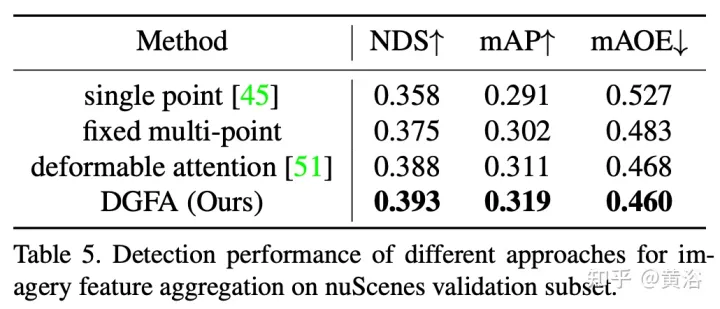
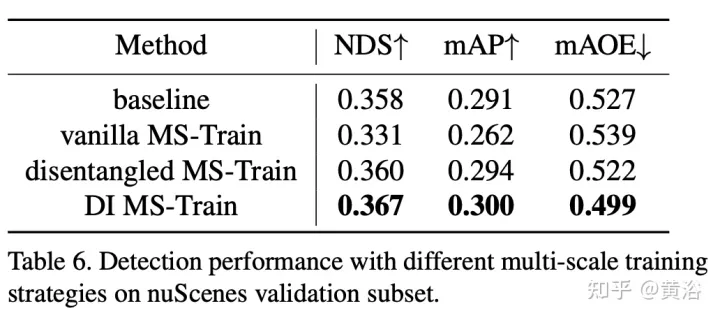
Remarque : DI = Depth-Invariant
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI