
Maison >Périphériques technologiques >IA >Pour améliorer l'expérience de recherche Alipay, Ant et l'Université de Pékin utilisent un cadre de génération de texte d'apprentissage comparatif hiérarchique
Pour améliorer l'expérience de recherche Alipay, Ant et l'Université de Pékin utilisent un cadre de génération de texte d'apprentissage comparatif hiérarchique

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-09 15:41:111018parcourir
Les tâches de génération de texte sont généralement entraînées à l'aide du forçage de l'enseignant. Cette méthode de formation permet au modèle de ne voir que les échantillons positifs pendant le processus de formation. Cependant, il existe généralement certaines contraintes entre la cible de génération et l'entrée. Ces contraintes sont généralement reflétées par des éléments clés dans la phrase. Par exemple, dans la tâche de réécriture de requête, « commander McDonald's » ne peut pas être remplacé par « commander KFC Ceci ». joue un rôle dans L'élément clé de la retenue réside dans les mots-clés de la marque. En introduisant un apprentissage contrastif et en ajoutant des modèles d'échantillons négatifs au processus de génération, le modèle peut apprendre efficacement ces contraintes.
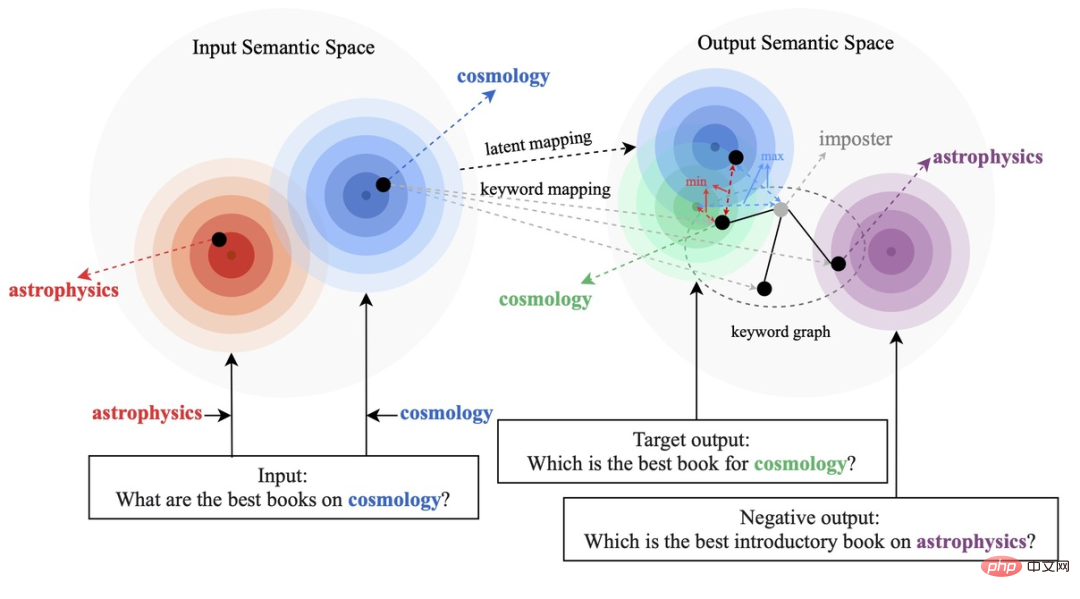
Les méthodes d'apprentissage contrastives existantes se concentrent principalement sur le niveau de la phrase entière [1][2], tout en ignorant les informations sur les entités granulaires des mots dans la phrase. L'exemple de la figure ci-dessous montre les mots clés de la phrase. Le sens important des mots. Pour une phrase d'entrée, si ses mots-clés sont remplacés (par exemple cosmologie->astrophysique), le sens de la phrase changera, et donc la position dans l'espace sémantique (représentée par la distribution) changera également. En tant qu'information la plus importante dans une phrase, les mots-clés correspondent à un point de la distribution sémantique, qui détermine dans une large mesure la position de la distribution de la phrase. Dans le même temps, dans certains cas, les objectifs d'apprentissage contrastés existants sont trop simples pour le modèle, ce qui fait que le modèle est incapable de véritablement apprendre les informations clés entre les exemples positifs et négatifs.
Sur cette base, des chercheurs de Ant Group, de l'Université de Pékin et d'autres institutions ont proposé une méthode de génération de contraste multi-granularité, conçu une structure de contraste hiérarchique, amélioré les informations à différents niveaux et amélioré l'apprentissage au niveau de la granularité des phrases. la sémantique globale améliore les informations locales importantes au niveau de la granularité des mots. Le document de recherche a été accepté pour l’ACL 2022.

Adresse papier : https://aclanthology.org/2022.acl-long.304.pdf
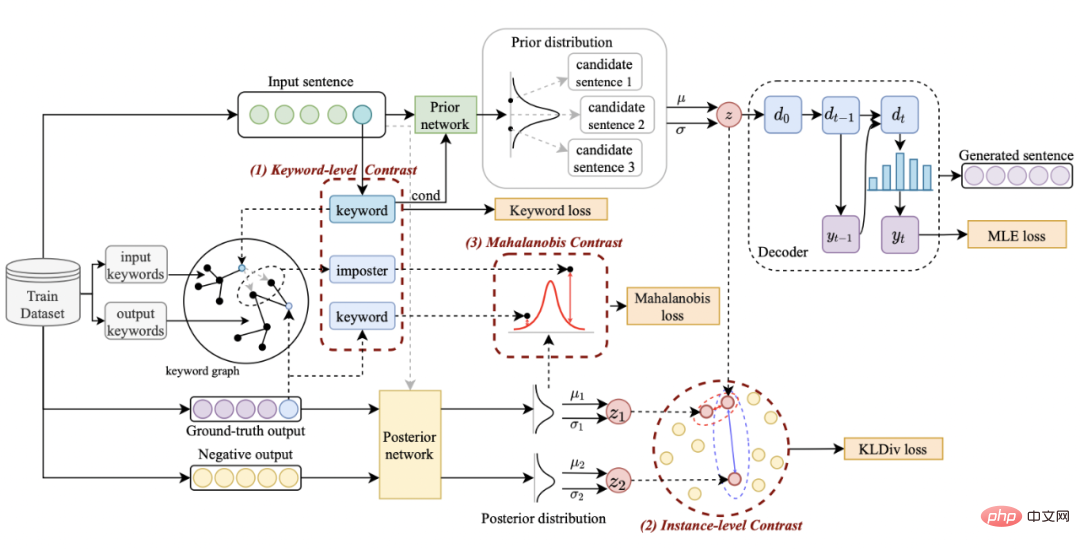
Méthode
Notre approche s'appuie sur classique Dans le cadre de génération de texte CVAE [3][4], chaque phrase peut être mappée à une distribution dans l'espace vectoriel, et les mots-clés de la phrase peuvent être considérés comme un point échantillonné à partir de cette distribution. D'une part, nous améliorons l'expression de la distribution des vecteurs spatiaux latents grâce à la comparaison de la granularité des phrases. D'autre part, nous améliorons l'expression de la granularité des points-clés grâce au graphe global des mots-clés construit. distribution des points-clés et des phrases. Contraste entre les niveaux de construction pour améliorer l'expression de l'information à deux granularités. La fonction de perte finale est obtenue en ajoutant trois pertes d'apprentissage contrastives différentes. Sensence Granular Comparative Learning
. Nous utilisons un réseau antérieur pour apprendre la distribution antérieure

, enregistrée comme
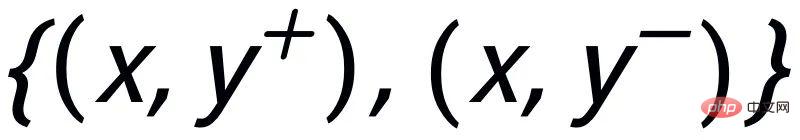
et apprendre la distribution postérieure approximative
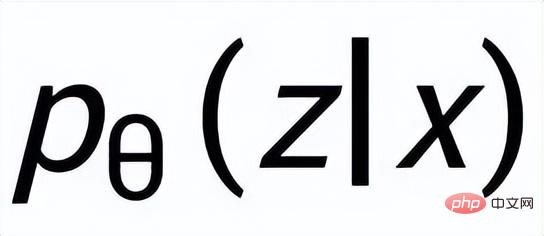 ;
;
et
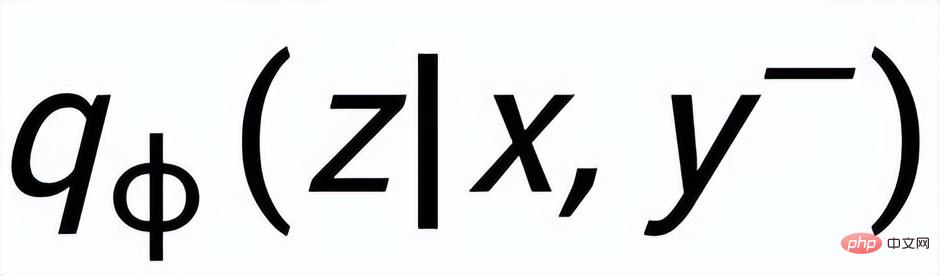
sont notés
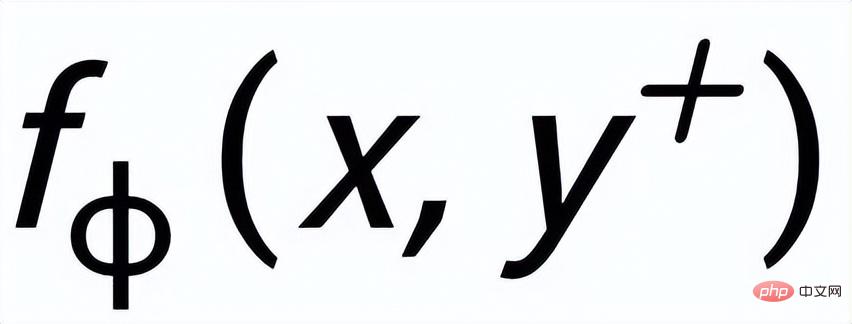
et respectivement . L'objectif de l'apprentissage comparatif granulaire des phrases est de réduire autant que possible la distance entre la distribution antérieure et la distribution postérieure positive, et en même temps, de maximiser la distance entre la distribution antérieure et la distribution postérieure négative. La fonction de perte correspondante est. comme suit :
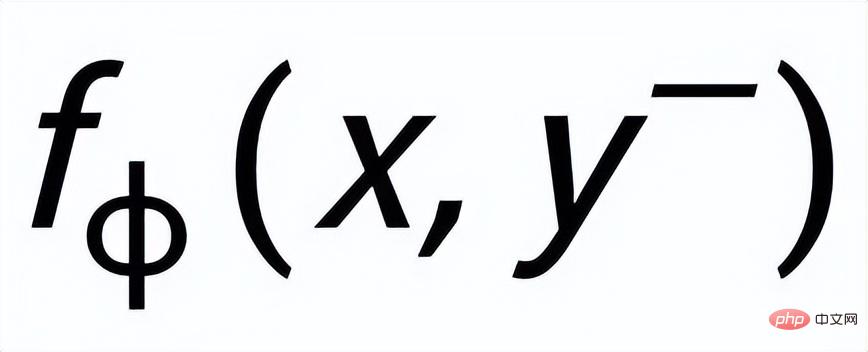
où est un échantillon positif ou un échantillon négatif, et est le coefficient de température, qui est utilisé pour représenter la mesure de distance. Ici, nous utilisons la divergence KL (divergence Kullback – Leibler) [5. ] pour mesurer la distance directe entre deux distributions.
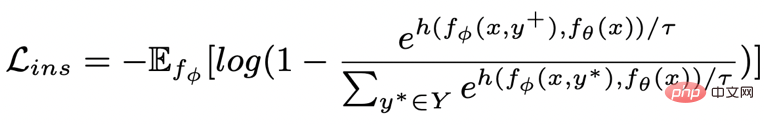
Apprentissage comparatif granulaire des mots clés
Réseau de mots clés
- L'apprentissage comparatif de la granularité des mots clés est utilisé pour que le modèle accorde plus d'attention aux mots clés dans la phrase Informations , nous atteignons cet objectif en construisant un graphe de mots-clés utilisant les relations positives et négatives correspondant au texte d'entrée et de sortie. Concrètement, en fonction d'une paire de phrases donnée
, on peut respectivement déterminer un mot-clé

et

( Pour la méthode d'extraction de mots clés, J'utilise l'algorithme TextRank classique [6]); pour une phrase

, il peut y avoir d'autres phrases avec les mêmes mots-clés

Ensemble, elles forment un ensemble
. 
, où chaque phrase
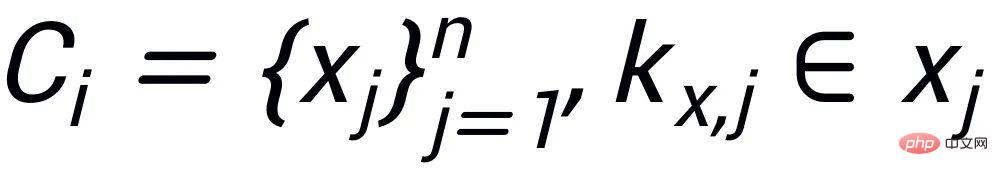
a une paire d'exemples de phrases de sortie positives et négatives

, ils ont différents A mot-clé positif
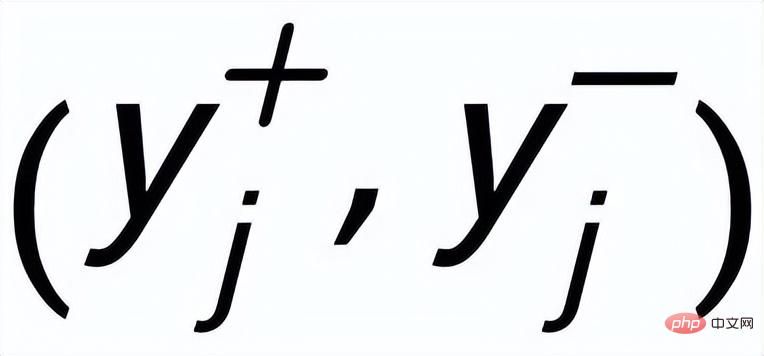
et exemples de mots clés à exclure . De cette façon, dans l'ensemble de la collection, pour toute phrase de sortie , on peut considérer que son mot-clé correspondant et chaque environnement (associé par des relations positives et négatives entre les phrases) , et il y a un avantage positif entre chaque environnement Côté négatif . Sur la base de ces nœuds de mots-clés et de leurs bords directs, nous pouvons construire un graphique de mots-clés Nous utilisons l'intégration BERT[7] pour chaque nœud Initialisez et utilisez une couche MLP pour apprendre la représentation de chaque arête . Nous mettons à jour de manière itérative les nœuds et les arêtes du réseau de mots-clés via une couche d'attention graphique (GAT) et une couche MLP. À chaque itération, nous mettons d'abord à jour la représentation des arêtes de la manière suivante : Ici . peut être ou . Puis en fonction des bords mis à jour , nous mettons à jour la représentation de chaque nœud via une couche d'attention graphique : Ici sont tous des paramètres apprenables, est le poids de l'attention. Afin d'éviter le problème du gradient de disparition, nous ajoutons une connexion résiduelle à pour obtenir la représentation des nœuds dans cette itération . Nous utilisons la représentation nodale de la dernière itération comme représentation du mot-clé, noté u. La comparaison de la granularité des mots-clés provient des mots-clés de la phrase d'entrée et un Node imposteur . Nous enregistrons le mot-clé extrait de l'échantillon positif de sortie de la phrase d'entrée comme , et son nœud voisin négatif dans le réseau de mots-clés ci-dessus est enregistré comme , puis , la perte d'apprentissage comparative de la granularité des mots clés est calculée comme suit : ici est utilisé pour désigner ou , h(·) est utilisé pour représenter la mesure de distance. Dans l'apprentissage comparatif de la granularité des mots clés, nous choisissons la similarité cosinus pour calculer la distance entre deux points. On peut noter que l'apprentissage contrastif ci-dessus de la granularité des phrases et de la granularité des mots-clés est mis en œuvre respectivement au niveau de la distribution et du point, de sorte qu'une comparaison indépendante des deux granularités sont possibles. L'effet d'amélioration est affaibli en raison de différences plus petites. À cet égard, nous construisons des associations comparatives entre différentes granularités basées sur la distance de Mahalanobis [8] entre points et distributions, de sorte que la distance entre le mot-clé de sortie cible et la distribution de la phrase soit aussi petite que possible, de sorte que la distance entre l'imposteur et la distribution est aussi petite que possible. Cela compense le défaut selon lequel le contraste peut disparaître en raison de la comparaison indépendante de chaque taille de particule. Plus précisément, l'apprentissage contrastif à distance Mahalanobis à granularité croisée espère réduire autant que possible la distance entre la distribution sémantique postérieure des phrases et , tout en augmentant la distance entre eux autant que possible. La distance entre lui et est la suivante :
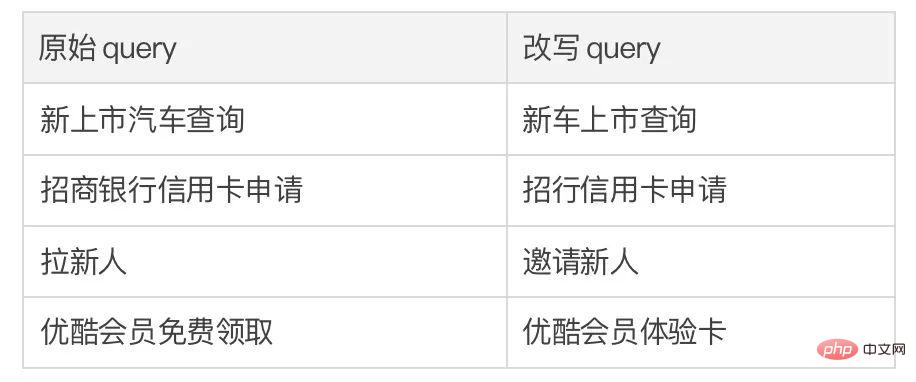
est également utilisé Référez-vous à ou , et h(·) est la distance de Mahalanobis. Nous avons effectué des analyses sur trois ensembles de données publics Douban (Dialogue) [9], QQP (Paraphrase) [10][11] et expériences de théories ont été menés sur (Storytelling) [12], et tous deux ont obtenu des résultats SOTA. Les références que nous comparons incluent des modèles génératifs traditionnels (par exemple CVAE[13], Seq2Seq[14], Transformer[15]), des méthodes basées sur des modèles pré-entraînés (par exemple Seq2Seq-DU[16], DialoGPT[17], BERT-GEN [7], T5[18]) et des méthodes basées sur l'apprentissage contrastif (par exemple Group-wise[9], T5-CLAPS[19]). Nous calculons le score BLEU[20] et la distance d'intégration BOW (extrema/moyenne/gourmande)[21] entre les paires de phrases comme indicateurs d'évaluation automatisés. Les résultats sont présentés dans la figure ci-dessous : Nous. L'évaluation manuelle est également utilisée sur l'ensemble de données QQP. Trois annotateurs ont respectivement annoté T5-CLAPS, DialoGPT, Seq2Seq-DU et les résultats générés par notre modèle. Les résultats sont présentés dans la figure ci-dessous : Nous avons mené des expériences d'analyse d'ablation pour savoir s'il fallait utiliser des mots-clés, s'il fallait utiliser des réseaux de mots-clés et s'il fallait utiliser la distribution de comparaison de distance de Mahalanobis. résultats finaux. rôle important, les résultats expérimentaux sont présentés dans la figure ci-dessous. Afin d'étudier le rôle de l'apprentissage contrastif à différents niveaux, nous avons visualisé les cas échantillonnés au hasard et effectué une réduction de dimensionnalité via t-sne[22] pour obtenir le photo suivante. On peut voir sur la figure que la représentation de la phrase d'entrée est proche de la représentation des mots-clés extraits, ce qui montre que les mots-clés, en tant qu'informations les plus importantes dans la phrase, déterminent généralement la position de la distribution sémantique. De plus, dans l’apprentissage contrastif, nous pouvons voir qu’après l’entraînement, la distribution des phrases d’entrée est plus proche des échantillons positifs et plus éloignée des échantillons négatifs, ce qui montre que l’apprentissage contrastif peut aider à corriger la distribution sémantique. Enfin, nous explorons l'impact de l'échantillonnage de différents mots-clés. Comme le montre le tableau ci-dessous, pour une question d'entrée, nous fournissons des mots-clés comme conditions pour contrôler la distribution sémantique via les méthodes d'extraction TextRank et de sélection aléatoire respectivement, et vérifions la qualité du texte généré. Les mots-clés constituent l'unité d'information la plus importante dans une phrase. Différents mots-clés conduiront à différentes distributions sémantiques et produiront différents tests. Plus il y a de mots-clés sélectionnés, plus les phrases générées sont précises. Parallèlement, les résultats générés par d'autres modèles sont également présentés dans le tableau ci-dessous. Dans cet article, nous proposons un mécanisme d'apprentissage contrastif hiérarchique multi-granularité, qui est plus que compétitif sur plusieurs ensembles de données générés par du texte. Le modèle de réécriture de requêtes basé sur ce travail a été mis en œuvre avec succès dans le scénario commercial réel de la recherche Alipay et a obtenu des résultats remarquables. Les services de recherche d'Alipay couvrent un large éventail de domaines et présentent des caractéristiques de domaine significatives. Il existe une énorme différence littérale entre l'expression de la requête de recherche de l'utilisateur et l'expression du service, ce qui rend difficile l'obtention de résultats idéaux en faisant correspondre directement des mots-clés (par exemple). Par exemple, l'utilisateur saisit la requête "Requête de voiture nouvellement lancée" ", incapable de rappeler le service "Requête de lancement de nouvelle voiture"), le but de la réécriture de la requête est de réécrire la requête saisie par l'utilisateur d'une manière plus proche de la expression de service tout en gardant l'intention de la requête inchangée, afin de mieux correspondre au service cible. Voici quelques exemples de reformulation : 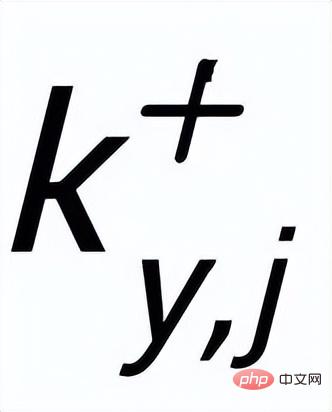



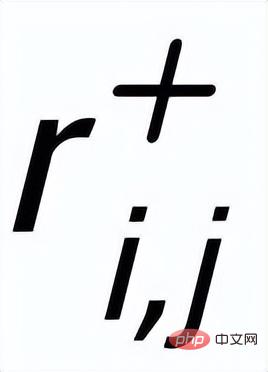




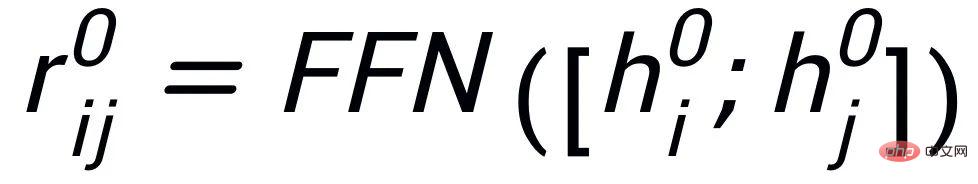
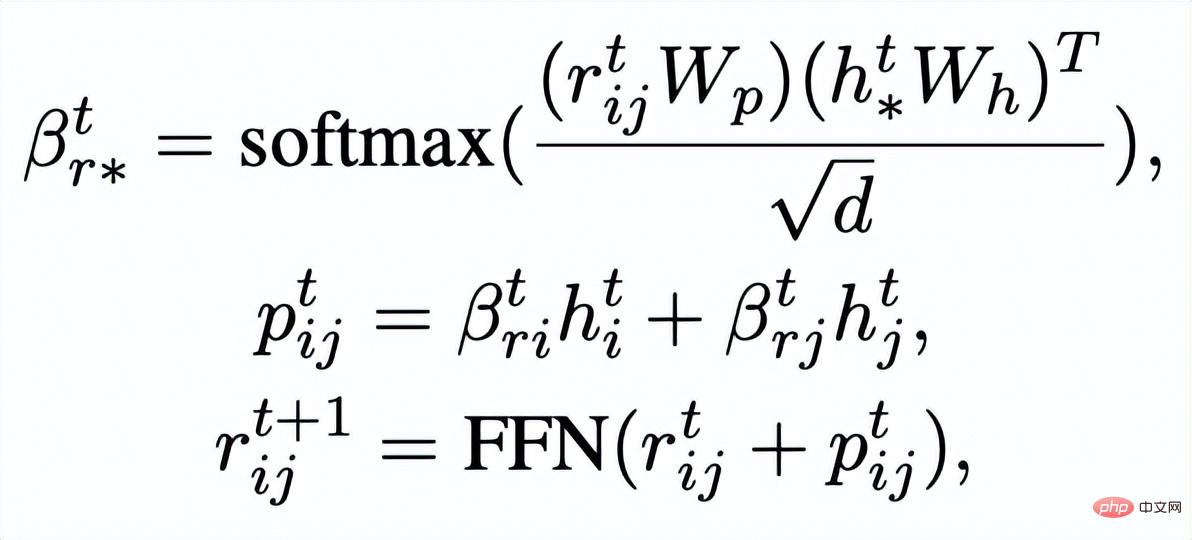




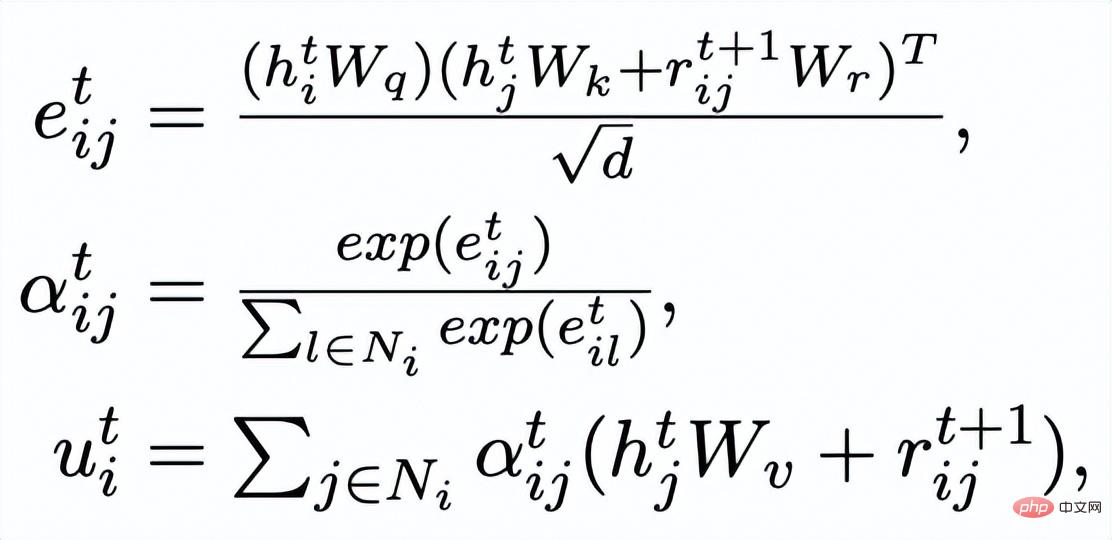
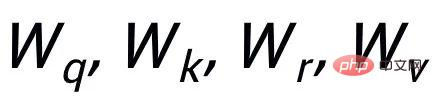







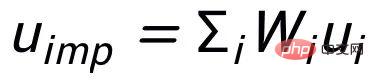
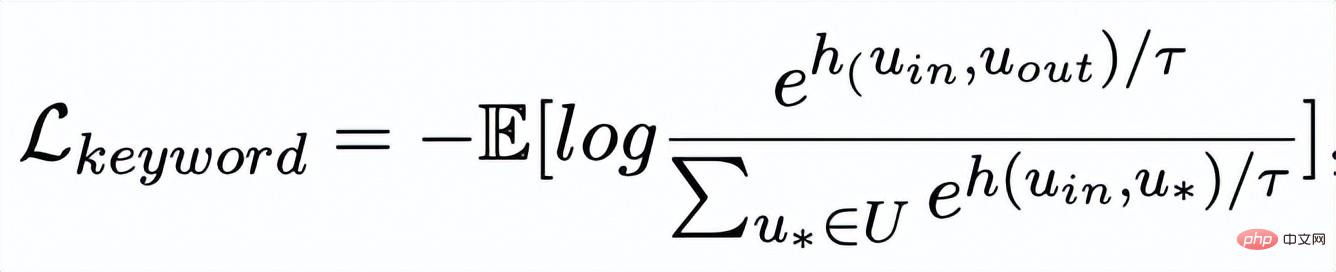



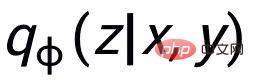


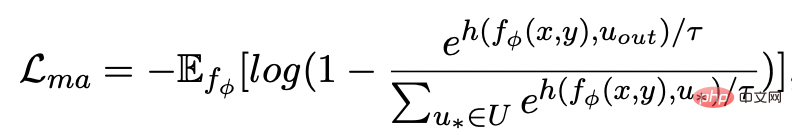



Expérimentation et analyse
Résultats expérimentaux
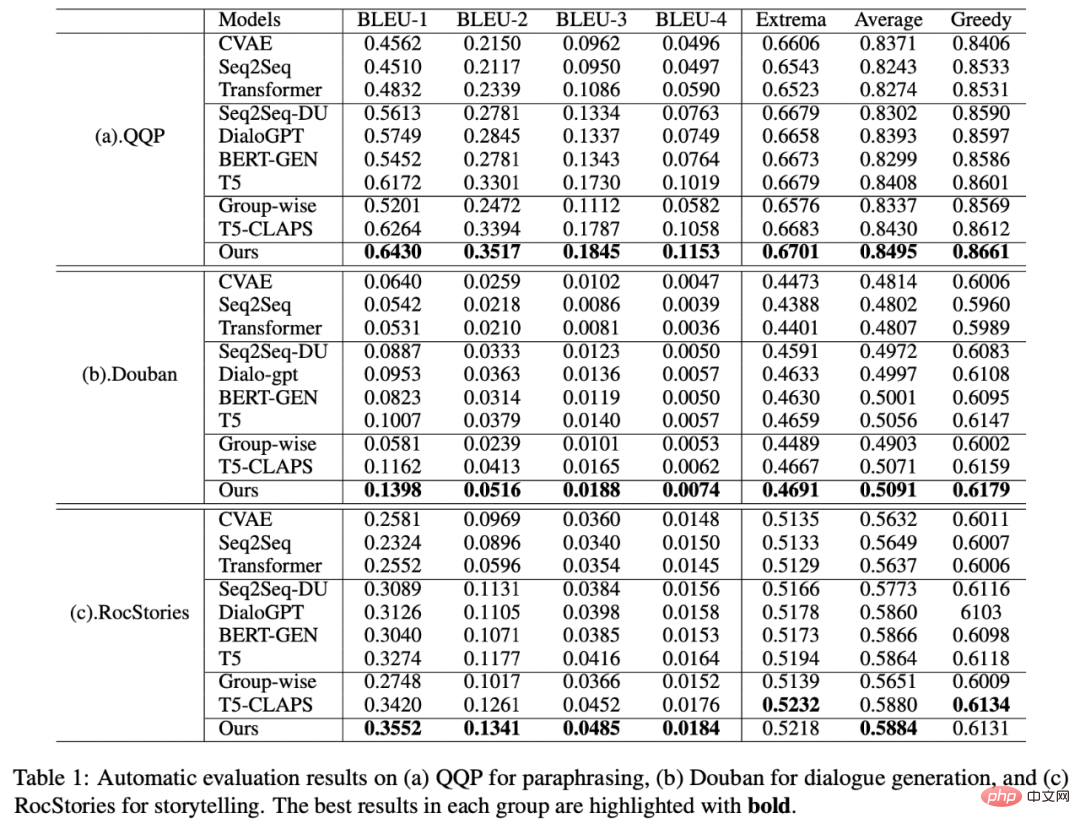
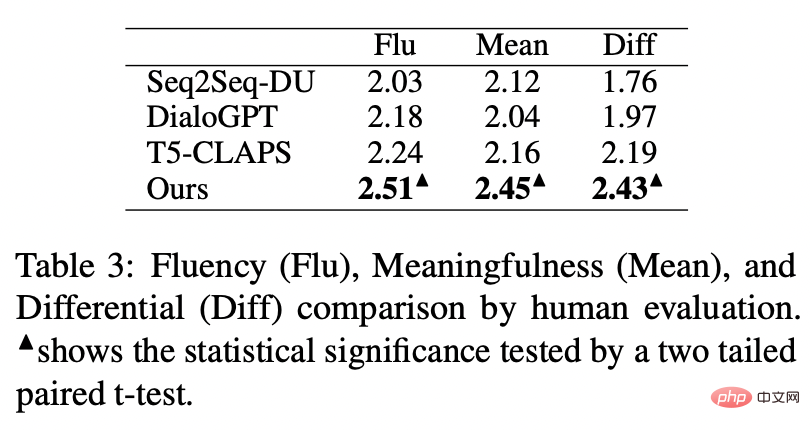
Analyse d'ablation
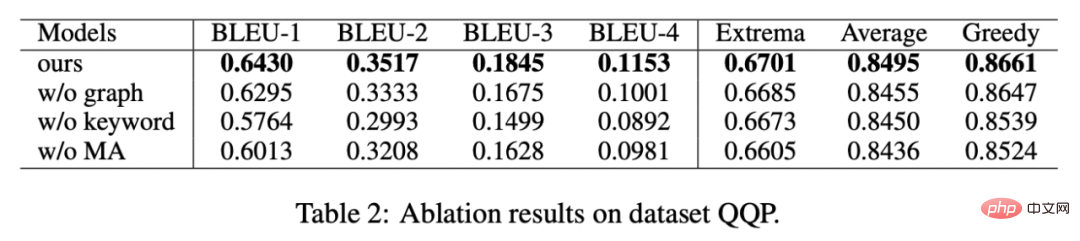
Analyse visuelle
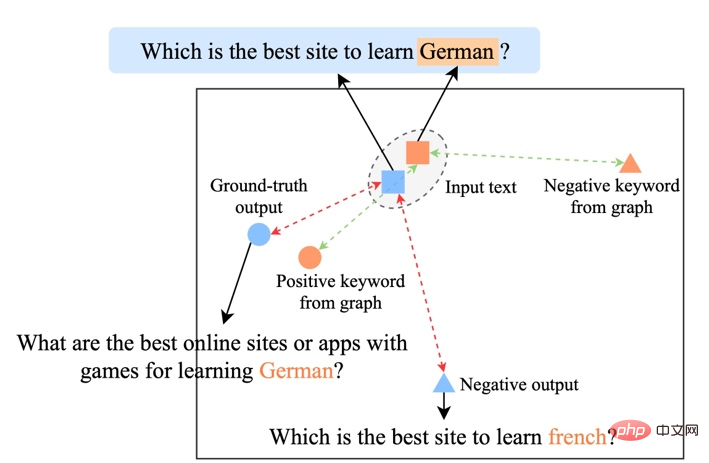
Analyse de l'importance des mots clés

Applications métiers
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI