
Maison >Périphériques technologiques >IA >Huang Hongbo, expert technique en IA de Xishanju : Intégration pratique de l'apprentissage par renforcement et des arbres de comportement dans les jeux
Huang Hongbo, expert technique en IA de Xishanju : Intégration pratique de l'apprentissage par renforcement et des arbres de comportement dans les jeux

- 王林avant
- 2023-04-09 14:31:091925parcourir
Les 6 et 7 août 2022,La conférence mondiale sur les technologies d'intelligence artificielle AISummitse tiendra comme prévu. Lors du sous-forum « Exploration des frontières de l'intelligence artificielle » tenu dans l'après-midi du 7, Huang Hongbo, un expert technique en IA de Xishanju, a partagé le thème « Combinaison pratique de l'apprentissage par renforcement et des arbres de comportement dans les jeux » et a partagé en détail le impact de l’apprentissage par renforcement dans le domaine du jeu.
Huang Hongbo a déclaré que la mise en œuvre de la technologie d'apprentissage par renforcement ne réside pas dans l'amélioration de l'algorithme, mais dans la combinaison de la technologie d'apprentissage par renforcement avec l'apprentissage en profondeur et la planification de jeux pour former une solution complète et la mettre en œuvre.
L'apprentissage par renforcement rend les jeux plus intelligents
La mise en œuvre de l'apprentissage par renforcement dans les jeux peut rendre les jeux plus intelligents et plus jouables. C'est l'objectif principal de l'utilisation de l'apprentissage par renforcement dans les jeux.
"L'apprentissage par renforcement est un paradigme d'apprentissage automatique qui entraîne la stratégie de l'agent afin qu'une série de décisions puisse être prise." Huang Hongbo a déclaré que le but de l'agent est de produire des actions basées sur des observations de l'environnement. Ces actions mèneront à plus d’observations et de récompenses. La formation implique de nombreux essais et erreurs à mesure que l'agent interagit avec l'environnement, et la politique peut être améliorée à chaque itération.
Dans un jeu, l'agent qui agit ou exécute un comportement est l'agent de jeu. Considérons un personnage ou un robot dans un jeu, il doit comprendre l'état du jeu, où se trouve le joueur, puis sur la base de cette observation, une décision doit être prise en fonction de la situation du jeu. Dans l'apprentissage par renforcement, les décisions sont motivées par des récompenses, qui peuvent être fournies dans le jeu sous forme de scores élevés ou pour atteindre de nouveaux niveaux afin d'atteindre des objectifs spécifiques.
Huang Hongbo a déclaré que la chose la plus cool dans la situation de jeu est que la stratégie de l'agent est entraînée sous la pression du jeu. Par exemple, il pourrait apprendre comment gérer une attaque ou comment se comporter pour atteindre un objectif spécifique.
Le rôle de l'arbre de comportement dans le jeu
Un arbre de comportement est une structure arborescente contenant des nœuds logiques et des nœuds de comportement. Habituellement, vous pouvez résumer chaque situation en un type de nœud, écrire les nœuds selon les spécifications, puis connecter ces nœuds dans un arbre. Chaque fois que l'utilisateur recherche un comportement, il partira du nœud racine de l'arborescence et trouvera un comportement cohérent avec les données actuelles de chaque nœud.
Pour faire simple, lorsque le degré de couplage et la granularité de chaque module d'IA sont élevés, un changement implique souvent un grand nombre de modifications, et il est facile qu'une grande quantité de code en double apparaisse. L'émergence des arbres de comportement a fourni un « cahier carré » pour la majorité des développeurs de jeux, permettant aux développeurs d'IA de créer plus facilement un ensemble de cadres d'IA réutilisables, faciles à développer et à maintenir. On peut dire que l'apprentissage par renforcement s'obtient grâce à la formation et que l'arbre comportemental est une combinaison de plusieurs autres déclarations et si.
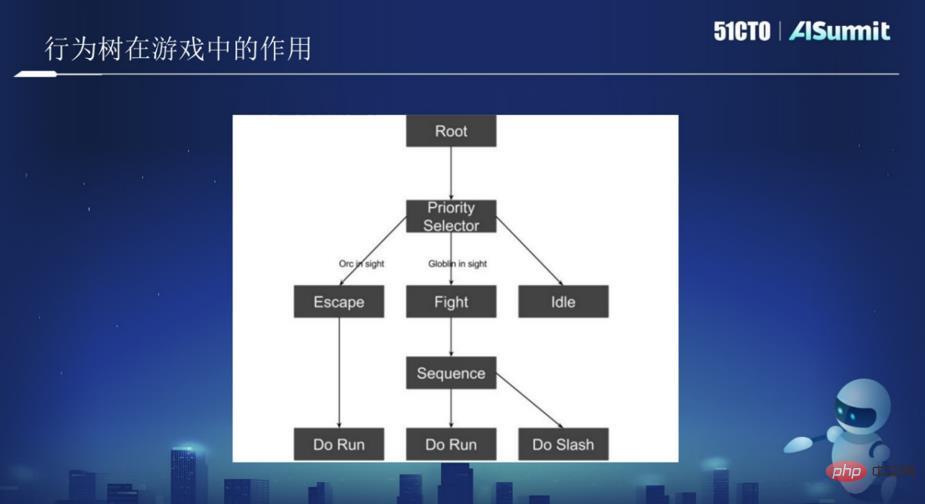
Comme le montre l'image ci-dessus, il y a un nœud racine dans l'image, et en dessous se trouve un nœud d'arbre. Le nœud d'arbre comprend l'évasion, l'attaque, l'errance, etc. Considérez l'image ci-dessus comme une IA ou un robot et laissez-la patrouiller dans la jungle. Lorsque l'IA voit un orc ORC et détermine qu'elle ne peut pas vaincre l'ORC, lorsque cette condition est déclenchée, l'IA s'enfuit et exécute l'action Exécuter en s'échappant. Lorsqu’il sera jugé plus facile de combattre, l’opération Combat sera effectuée.
Dans l'image ci-dessus, il y a deux nœuds, l'un est Root, qui est le nœud racine ; l'autre est le nœud Selector, qui est le nœud logique. Tous les nœuds sont exécutés dans un certain ordre de gauche à droite. Il s'agit d'un arbre de comportement. Par conséquent, il vous suffit d'écrire la logique correspondante dans chaque nœud pour permettre à l'IA d'effectuer certaines actions associées. Plusieurs arbres de comportement forment finalement un jeu.
La combinaison de l'apprentissage par renforcement et des arbres de comportement rend le jeu plus riche
Comment utiliser la combinaison de l'apprentissage par renforcement et des arbres de comportement pour rendre le jeu plus riche ? Il s'agit d'une application difficile qui doit être discutée dans de nombreux jeux.
Avant cela, discutons du moment où il est préférable d'utiliser l'apprentissage par renforcement et dans quelles circonstances il est préférable d'utiliser des arbres de comportement. Huang Hongbo a déclaré que s'il n'y a aucun moyen d'atteindre l'objectif en utilisant des arbres de comportement, l'apprentissage par renforcement peut être utilisé. Par exemple, dans les FPS (jeu de tir à la première personne), quelle puissance de feu doit être utilisée, sur qui tirer, de quel type. des armes doivent être utilisées, etc. Il est plus difficile de prendre des décisions à travers des arbres de comportement. De manière générale, il est préférable d'utiliser l'apprentissage par renforcement.
Quand utiliser les arbres de comportement ? Par exemple, si vous rencontrez un obstacle dans le jeu et devez le franchir, vous pouvez choisir d'utiliser l'apprentissage par renforcement pour le faire, ou vous pouvez choisir d'utiliser un arbre de comportement pour le faire. Mais si nous utilisons l’apprentissage par renforcement pour y parvenir, la formation sera très problématique. Puisqu’il n’y a qu’une seule option dans cette situation, qui est de sauter, il est plus simple d’utiliser un arbre de comportement.
Il n'est pas difficile de constater que si l'apprentissage par renforcement et les arbres comportementaux sont combinés et utilisés dans les jeux, c'est une meilleure solution. Huang Hongbo a déclaré qu'il existe deux manières principales de combiner l'apprentissage par renforcement avec des arbres comportementaux : l'une est basée sur l'apprentissage par renforcement et complétée par des arbres comportementaux ; l'autre est basée sur des arbres comportementaux et complétée par l'apprentissage par renforcement ;
Côté arbre de comportement : Avec l'arbre de comportement comme principale méthode de mouvement de l'IA, l'arbre de comportement reçoit les entrées des obs du client du jeu et écrit les comportements d'arbre de comportement correspondants pour les obs en fonction de sa propre situation cible dans chaque comportement de l'arbre de comportement. , certains nœuds qui nécessitent un apprentissage par renforcement pour prendre des décisions sont confiés à l'apprentissage par renforcement. Ensuite, ici, un apprentissage par renforcement est nécessaire pour effectuer la formation correspondante pour certains scénarios spécifiques.
Côté apprentissage par renforcement : La stratégie globale consiste à former plusieurs modèles, chaque modèle exécute une stratégie, puis l'intègre dans l'arbre de comportement.
Huang Hongbo a déclaré que parmi ces deux méthodes de mise en œuvre différentes, laquelle est la meilleure nécessite différentes considérations basées sur différentes situations, différentes applications et différents jeux, elle ne peut donc pas être généralisée.
Dans la période suivante, Huang Hongbo a présenté en détail le cadre technique adopté par Xishanju dans l'apprentissage par renforcement et les arbres comportementaux, et combiné avec un grand nombre de cas de jeu, a présenté en détail comment les arbres comportementaux et l'apprentissage par renforcement sont utilisés dans jeux. Combinez-les pour rendre le jeu plus riche. Les utilisateurs intéressés par la pratique de cas souhaiteront peut-être prêter attention aux merveilleuses vidéos de partage de la conférence mondiale sur les technologies d'intelligence artificielle AISummit. (https://www.php.cn/link/53253027fef2ab5162a602f2acfed431)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI