
Maison >Périphériques technologiques >IA >Créez des modèles d'apprentissage automatique avec PySpark ML
Créez des modèles d'apprentissage automatique avec PySpark ML

- PHPzavant
- 2023-04-09 13:51:081230parcourir
Spark est un framework open source conçu pour les requêtes interactives, l'apprentissage automatique et les charges de travail en temps réel, et PySpark est une bibliothèque pour Python utilisant Spark.
PySpark est un excellent langage pour effectuer une analyse exploratoire des données à grande échelle, créer des pipelines d'apprentissage automatique et créer des ETL pour les plates-formes de données. Si vous êtes déjà familier avec des bibliothèques comme Python et Pandas, PySpark est un excellent langage pour apprendre et créer des analyses et des pipelines plus évolutifs.
Le but de cet article est de montrer comment créer un modèle d'apprentissage automatique à l'aide de PySpark.
Conda crée un environnement virtuel python
conda gère presque tous les outils et packages tiers en tant que packages, même python et conda eux-mêmes. Anaconda est une collection packagée, préinstallée avec conda, une certaine version de python, divers packages, etc.
1. Installez Anaconda.
Ouvrez la ligne de commande et entrez conda -V pour vérifier s'il est installé et la version actuelle de conda.
Installez la version par défaut de Python via Anaconda 3.6 correspond à Anaconda3-5.2, et python 3.7 après 5.3.
(https://repo.anaconda.com/archive/)
2.Commandes couramment utilisées dans conda
1) Vérifiez quels packages sont installés
conda list
2) Vérifiez quels environnements virtuels existent actuellement
conda env list <br>conda info -e
3) Cochez Mettre à jour le conda
conda update conda
3 actuel. Python crée un environnement virtuel
conda create -n your_env_name python=x.x
La commande anaconda crée un environnement virtuel avec la version python x.x et nomme your_env_name. Votre fichier_env_name se trouve sous le fichier envs dans le répertoire d'installation d'Anaconda.
4. Activez ou changez d'environnement virtuel
Ouvrez la ligne de commande et entrez python --version pour vérifier la version actuelle de Python.
Linux:source activate your_env_nam<br>Windows: activate your_env_name
5. Installez des packages supplémentaires dans l'environnement virtuel
conda install -n your_env_name [package]
6 Fermez l'environnement virtuel
(c'est-à-dire quittez l'environnement actuel et revenez à la version python par défaut dans l'environnement PATH)
deactivate env_name<br># 或者`activate root`切回root环境<br>Linux下:source deactivate
7. environnement
conda remove -n your_env_name --all
8. Supprimer un certain package dans l'horloge de l'environnement
conda remove --name $your_env_name$package_name
9. Configurer un miroir domestique
Le serveur de http://Anaconda.org est à l'étranger Lors de l'installation de plusieurs packages, la vitesse de téléchargement de conda est souvent. très lent. La source miroir Tsinghua TUNA a le miroir de l'entrepôt Anaconda, ajoutez-le simplement à la configuration conda :
# 添加Anaconda的TUNA镜像<br>conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/<br><br># 设置搜索时显示通道地址<br>conda config --set show_channel_urls yes
10 Restaurer le miroir par défaut
conda config --remove-key channels
Installer PySpark
Le processus d'installation de PySpark est aussi simple que les autres packages python ( comme Pandas, Numpy, scikit-learn).
Une chose importante est de vous assurer d’abord que Java est installé sur votre machine. Vous pouvez ensuite exécuter PySpark sur votre notebook jupyter.

Exploration des données
Nous utilisons l'ensemble de données sur le diabète, qui est associé à l'Institut national du diabète et des maladies digestives et rénales. L'objectif de la classification est de prédire si un patient est diabétique (oui/non).
from pyspark.sql import SparkSession<br>spark = SparkSession.builder.appName('ml-diabetes').getOrCreate()<br>df = spark.read.csv('diabetes.csv', header = True, inferSchema = True)<br>df.printSchema()
L'ensemble de données se compose de plusieurs variables prédictives médicales et d'une variable cible Résultat. Les variables prédictives incluent le nombre de grossesses de la patiente, l'IMC, les niveaux d'insuline, l'âge, etc.
- Grossesses : nombre de grossesses
- Glucose : concentration de glucose dans le sang obtenue lors du test oral de tolérance au glucose dans les 2 heures
- Pression artérielle : tension artérielle diastolique (mm Hg)
- Épaisseur de la peau : épaisseur du pli cutané du triceps (mm)
- Insuline : 2 heures Insuline sérique (mu U/ml)
- IMC : indice de masse corporelle (unité de poids kg/(unité de taille m)²)
- diabespedigreefonction : fonction du spectre du diabète
- Âge : âge (année)
- Résultat : variable de classe ( 0 ou 1)
- Variables d'entrée : glucose, tension artérielle, IMC, âge, grossesse, insuline, épaisseur de la peau, fonction du spectre du diabète.
- Variable de sortie : Résultat.
Regardez les cinq premières observations. Les dataframes Pandas sont plus jolies que Spark DataFrame.show().
import pandas as pd<br>pd.DataFrame(df.take(5), <br> columns=df.columns).transpose()
Dans PySpark, vous pouvez afficher des données à l'aide du DataFrame toPandas() de Pandas.
df.toPandas()

Vérifiez que la classe est complètement équilibrée !
df.groupby('Outcome').count().toPandas()

Statistiques descriptives
numeric_features = [t[0] for t in df.dtypes if t[1] == 'int']<br>df.select(numeric_features)<br>.describe()<br>.toPandas()<br>.transpose()
Corrélation entre les variables indépendantes
from pandas.plotting import scatter_matrix<br>numeric_data = df.select(numeric_features).toPandas()<br><br>axs = scatter_matrix(numeric_data, figsize=(8, 8));<br><br># Rotate axis labels and remove axis ticks<br>n = len(numeric_data.columns)<br>for i in range(n):<br>v = axs[i, 0]<br>v.yaxis.label.set_rotation(0)<br>v.yaxis.label.set_ha('right')<br>v.set_yticks(())<br>h = axs[n-1, i]<br>h.xaxis.label.set_rotation(90)<br>h.set_xticks(())

Préparation des données et ingénierie des fonctionnalités
Dans cette partie, nous supprimerons les colonnes inutiles et remplirons les valeurs manquantes. Enfin, les fonctionnalités sont sélectionnées pour le modèle d'apprentissage automatique. Ces fonctions seront divisées en deux parties : la formation et les tests.
Gestion des données manquantes
from pyspark.sql.functions import isnull, when, count, col<br>df.select([count(when(isnull(c), c)).alias(c)<br> for c in df.columns]).show()
Cet ensemble de données est génial, il n'y a aucune valeur manquante.
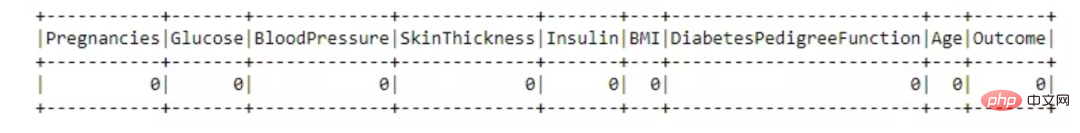
不必要的列丢弃
dataset = dataset.drop('SkinThickness')<br>dataset = dataset.drop('Insulin')<br>dataset = dataset.drop('DiabetesPedigreeFunction')<br>dataset = dataset.drop('Pregnancies')<br><br>dataset.show()

特征转换为向量
VectorAssembler —— 将多列合并为向量列的特征转换器。
# 用VectorAssembler合并所有特性<br>required_features = ['Glucose',<br>'BloodPressure',<br>'BMI',<br>'Age']<br><br>from pyspark.ml.feature import VectorAssembler<br><br>assembler = VectorAssembler(<br>inputCols=required_features, <br>outputCol='features')<br><br>transformed_data = assembler.transform(dataset)<br>transformed_data.show()
现在特征转换为向量已完成。
训练和测试拆分
将数据随机分成训练集和测试集,并设置可重复性的种子。
(training_data, test_data) = transformed_data.randomSplit([0.8,0.2], seed =2020)<br>print("训练数据集总数: " + str(training_data.count()))<br>print("测试数据集总数: " + str(test_data.count()))
训练数据集总数:620<br>测试数据集数量:148
机器学习模型构建
随机森林分类器
随机森林是一种监督学习算法,用于分类和回归。但是,它主要用于分类问题。众所周知,森林是由树木组成的,树木越多,森林越茂盛。类似地,随机森林算法在数据样本上创建决策树,然后从每个样本中获取预测,最后通过投票选择最佳解决方案。这是一种比单个决策树更好的集成方法,因为它通过对结果进行平均来减少过拟合。
from pyspark.ml.classification import RandomForestClassifier<br><br>rf = RandomForestClassifier(labelCol='Outcome', <br>featuresCol='features',<br>maxDepth=5)<br>model = rf.fit(training_data)<br>rf_predictions = model.transform(test_data)
评估随机森林分类器模型
from pyspark.ml.evaluation import MulticlassClassificationEvaluator<br><br>multi_evaluator = MulticlassClassificationEvaluator(<br>labelCol = 'Outcome', metricName = 'accuracy')<br>print('Random Forest classifier Accuracy:', multi_evaluator.evaluate(rf_predictions))
Random Forest classifier Accuracy:0.79452
决策树分类器
决策树被广泛使用,因为它们易于解释、处理分类特征、扩展到多类分类设置、不需要特征缩放,并且能够捕获非线性和特征交互。
from pyspark.ml.classification import DecisionTreeClassifier<br><br>dt = DecisionTreeClassifier(featuresCol = 'features',<br>labelCol = 'Outcome',<br>maxDepth = 3)<br>dtModel = dt.fit(training_data)<br>dt_predictions = dtModel.transform(test_data)<br>dt_predictions.select('Glucose', 'BloodPressure', <br>'BMI', 'Age', 'Outcome').show(10)
评估决策树模型
from pyspark.ml.evaluation import MulticlassClassificationEvaluator<br><br>multi_evaluator = MulticlassClassificationEvaluator(<br>labelCol = 'Outcome', <br>metricName = 'accuracy')<br>print('Decision Tree Accuracy:', <br>multi_evaluator.evaluate(dt_predictions))
Decision Tree Accuracy: 0.78767
逻辑回归模型
逻辑回归是在因变量是二分(二元)时进行的适当回归分析。与所有回归分析一样,逻辑回归是一种预测分析。逻辑回归用于描述数据并解释一个因二元变量与一个或多个名义、序数、区间或比率水平自变量之间的关系。当因变量(目标)是分类时,使用逻辑回归。
from pyspark.ml.classification import LogisticRegression<br><br>lr = LogisticRegression(featuresCol = 'features', <br>labelCol = 'Outcome', <br>maxIter=10)<br>lrModel = lr.fit(training_data)<br>lr_predictions = lrModel.transform(test_data)
评估我们的逻辑回归模型。
from pyspark.ml.evaluation import MulticlassClassificationEvaluator<br><br>multi_evaluator = MulticlassClassificationEvaluator(<br>labelCol = 'Outcome',<br>metricName = 'accuracy')<br>print('Logistic Regression Accuracy:', <br>multi_evaluator.evaluate(lr_predictions))
Logistic Regression Accuracy:0.78767
梯度提升树分类器模型
梯度提升是一种用于回归和分类问题的机器学习技术,它以弱预测模型(通常是决策树)的集合形式生成预测模型。
from pyspark.ml.classification import GBTClassifier<br>gb = GBTClassifier(<br>labelCol = 'Outcome', <br>featuresCol = 'features')<br>gbModel = gb.fit(training_data)<br>gb_predictions = gbModel.transform(test_data)
评估我们的梯度提升树分类器。
from pyspark.ml.evaluation import MulticlassClassificationEvaluator<br>multi_evaluator = MulticlassClassificationEvaluator(<br>labelCol = 'Outcome',<br>metricName = 'accuracy')<br>print('Gradient-boosted Trees Accuracy:',<br>multi_evaluator.evaluate(gb_predictions))
Gradient-boosted Trees Accuracy:0.80137
结论
PySpark 是一种非常适合数据科学家学习的语言,因为它支持可扩展的分析和 ML 管道。如果您已经熟悉 Python 和 Pandas,那么您的大部分知识都可以应用于 Spark。总而言之,我们已经学习了如何使用 PySpark 构建机器学习应用程序。我们尝试了三种算法,梯度提升在我们的数据集上表现最好。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI