
Maison >Périphériques technologiques >IA >Intel aide à créer un moteur de formation/prédiction de modèles clairsemés open source à grande échelle DeepRec
Intel aide à créer un moteur de formation/prédiction de modèles clairsemés open source à grande échelle DeepRec

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-08 22:01:101564parcourir
DeepRec (PAI-TF) est le moteur de recommandation open source unifié du groupe Alibaba (https://github.com/alibaba/DeepRec). Il est principalement utilisé pour la formation et la prédiction de modèles clairsemés, et peut prendre en charge des centaines de milliards de fonctionnalités et). des milliards d'échantillons.La formation clairsemée à très grande échelle présente des avantages évidents en termes de performances et d'effet de formation ; actuellement DeepRec prend en charge la recherche, la recommandation, la publicité et d'autres scénarios Taobao, et est largement utilisé dans Taobao, Tmall, Alimama, Amap et d'autres entreprises. .
Intel travaille en étroite collaboration avec l'équipe Alibaba PAI depuis 2019 pour appliquer la technologie Intel d'intelligence artificielle (IA) à DeepRec, en ciblant les opérateurs, les sous-graphes, le temps d'exécution, les couches et modèles de framework, etc. Optimisez à tous les niveaux pour faire jouer pleinement Les avantages logiciels et matériels d'Intel et aident Alibaba à accélérer les performances des activités d'IA internes et externes.
Principaux avantages de DeepRec
Les moteurs open source grand public actuels ont encore certaines limites dans la prise en charge de scénarios de formation clairsemés à très grande échelle. Par exemple, ils ne prennent pas en charge la formation en ligne, les fonctionnalités ne peuvent pas être chargées dynamiquement et. l'itération du déploiement en ligne n'est pas pratique, etc. En particulier, le problème de la difficulté à répondre aux exigences de l'entreprise en termes de performances est particulièrement évident. Afin de résoudre les problèmes ci-dessus, DeepRec a été profondément personnalisé et optimisé pour les scénarios de modèles clairsemés basés sur TensorFlow1.15. Les principales mesures incluent les trois catégories suivantes :
Effet de modèle : Principalement en ajoutant l'EmbeddingVariable (EV). ) fonction de fonctionnalité élastique dynamique et amélioration d'Adagrad Optimizer pour réaliser l'optimisation. La fonction EV résout des problèmes tels que la difficulté d'estimation des conflits de taille de variable native et de fonctionnalités, et fournit une multitude de fonctionnalités avancées telles que des stratégies d'admission et d'élimination de fonctionnalités. En même temps, elle configure automatiquement les dimensions de fonctionnalités chaudes et froides en fonction de la fréquence. occurrences de fonctionnalités, ajoutant La puissance expressive des fonctionnalités haute fréquence atténue le surajustement et peut améliorer considérablement l'effet des modèles clairsemés
Performances de formation et d'inférence : Pour les scénarios clairsemés, DeepRec a été implémenté en termes de distribution, sous-graphiques, opérateurs, runtime, etc. Optimisation approfondie des performances, y compris l'optimisation de la stratégie distribuée, le pipeline automatique SmartStage, la fusion automatique des graphes, l'optimisation des graphes telles que l'intégration et l'attention, l'optimisation des opérateurs clairsemés communs et l'optimisation de la gestion de la mémoire, réduit considérablement l'utilisation de la mémoire et accélère considérablement la formation de bout en bout et les performances d'inférence ; exigences commerciales en matière de rapidité ; ciblage de la parcimonie. Les fonctionnalités du modèle ont des caractéristiques de répartition à chaud et à froid. DeepRec offre la capacité de stockage hybride à plusieurs niveaux (jusqu'à quatre niveaux de stockage hybride, à savoir HBM+DRAM+PMem+SSD), qui peut être utilisé. améliorer les performances des grands modèles tout en réduisant les coûts.
La technologie Intel aide DeepRec à atteindre des performances élevées L'étroite coopération entre Intel et l'équipe Alibaba PAI a joué un rôle important dans l'obtention des trois avantages uniques ci-dessus. Les trois avantages majeurs de DeepRec reflètent également pleinement la grande valeur de la technologie Intel. :
En termes d'optimisation des performances, l'équipe de logiciels cloud à très grande échelle d'Intel travaille en étroite collaboration avec Alibaba pour optimiser la plate-forme CPU à partir des opérateurs, des sous-graphiques, des frameworks, du runtime et d'autres niveaux afin de tirer pleinement parti d'Intel® Xeon ® Diverses nouvelles fonctionnalités des processeurs évolutifs peuvent tirer pleinement parti des avantages matériels
Afin d'améliorer la facilité d'utilisation de DeepRec sur la plate-forme CPU, modelzoo a également été conçu pour prendre en charge la plupart des modèles de recommandation courants et le fera. Les capacités EV uniques de DeepRec sont appliquées à ces modèles, permettant une expérience utilisateur prête à l'emploi.
Dans le même temps, en réponse aux besoins particuliers du modèle de formation clairsemé à très grande échelle EV pour les opérations de stockage et de recherche KV, l'équipe Intel Optane Innovation Center assure la gestion de la mémoire et la solution de stockage prend en charge et coopère avec le Solution de stockage hybride multi-niveaux DeepRec pour répondre aux besoins de grande mémoire et à faible coût ; L'équipe de la division Programmable Solutions utilise FPGA pour implémenter la fonction de recherche KV pour l'intégration, ce qui améliore considérablement la capacité de requête d'intégration. , davantage de ressources CPU peuvent être libérées. Combinés aux différentes caractéristiques matérielles du CPU, du PMem et du FPGA, du point de vue du système, les avantages logiciels et matériels d'Intel peuvent être pleinement utilisés pour différents besoins, ce qui peut accélérer la mise en œuvre de DeepRec dans l'activité IA d'Alibaba et fournir de meilleures solutions pour l'ensemble de l'activité clairsemée. écosystème commercial de scénario. Excellente solution.
Intel® DL Boost fournit une accélération clé des performances pour DeepRec
Intel® DL Boost (Intel® Deep Learning Acceleration) optimise DeepRec, principalement reflété dans l'optimisation du framework et de l'opérateur, l'optimisation des sous-graphes et optimisation du modèle Quatre niveaux. Depuis l'avènement des processeurs Intel® Xeon® Scalable, Intel a amélioré les capacités AVX en passant de l'AVX 256 à l'AVX-512 doublé, améliorant considérablement capacités de formation et d'inférence d'apprentissage profond ; et l'introduction de DL Boost_VNNI dans la deuxième génération d'Intel®. Après le processeur Strong® Scalable, Intel a lancé un jeu d'instructions qui prend en charge le type de données BFloat16 (BF16) pour améliorer encore les performances de formation et d'inférence d'apprentissage profond. Grâce à l'innovation et au développement continus de la technologie matérielle, Intel lancera une nouvelle technologie de traitement de l'IA dans la prochaine génération de processeurs Xeon® Scalable afin d'améliorer encore les capacités du VNNI et du BF16 du vecteur unidimensionnel à la matrice bidimensionnelle. Les technologies de jeu d'instructions matérielles mentionnées ci-dessus ont été appliquées à l'optimisation de DeepRec, permettant d'utiliser différentes fonctionnalités matérielles pour différents besoins informatiques. Il a également été vérifié que les Intel® AVX-512 et BF16 sont très adaptés à la formation et à l'accélération d'inférence en clairsemés. scénarios. Figure 1 Diagramme d'évolution des capacités d'IA de la plate-forme Intel x86 DeepRec intègre l'open source cross- profondeur de la plateforme Bibliothèque d'accélération des performances d'apprentissage oneDNN (oneAPI Deep Neural Network Library), et modifiez le pool de threads d'origine de oneDNN et unifiez-le dans le pool de threads propre de DeepRec, ce qui réduit le coût de changement de pool de threads et évite la dégradation des performances causée par la concurrence entre différents pools de threads. oneDNN a mis en œuvre une optimisation des performances pour un grand nombre d'opérateurs grand public, notamment MatMul, BiasAdd, LeakyReLU et d'autres opérateurs courants dans des scénarios clairsemés, qui peuvent fournir un solide support de performances pour les modèles de recherche et de promotion, et les opérateurs de oneDNN prennent également en charge le type de données BF16, utilisé avec le processeur Intel® Xeon® Scalable de troisième génération équipé du jeu d'instructions BF16, peut améliorer considérablement les performances d'entraînement et d'inférence des modèles. Dans les options de compilation DeepRec, ajoutez simplement "--config=mkl_threadpool" pour activer facilement l'optimisation oneDNN. Bien que oneDNN puisse être utilisé pour améliorer considérablement les performances des opérateurs à forte intensité de calcul, il existe un grand nombre d'opérateurs clairsemés dans le modèle de recommandation de publicité sur les recherches, tels que Select, DynamicStitch, Transpose, Tile , SparseSegmentMean, etc. La plupart des implémentations natives de ces opérateurs disposent d'un certain espace pour l'optimisation de l'accès à la mémoire, et des solutions ciblées peuvent être utilisées pour obtenir une optimisation supplémentaire. Cette optimisation appelle les instructions AVX-512 et peut être activée en ajoutant "--copt=-march=skylake-avx512" à la commande de compilation. Voici deux des cas d’optimisation. Cas 1 : Le principe de mise en œuvre de l'opérateur Select est de sélectionner des éléments en fonction des conditions. À ce stade, la méthode de chargement de masque d'Intel® AVX-512 peut être utilisée, comme le montre l'image de gauche de la figure 2, pour réduire la condition if d'origine. Pour réduire le temps nécessaire à un grand nombre de jugements, puis améliorer l'efficacité de la lecture et de l'écriture des données grâce à la sélection par lots, le test final en ligne montre que les performances sont considérablement améliorées ; Cas 2 : De même, vous pouvez utiliser les instructions de décompression et de lecture aléatoire d'Intel® AVX-512 pour optimiser l'opérateur de transposition, c'est-à-dire transposer la matrice à travers de petits blocs, comme le montre l'image de droite de la figure 2, la chaîne finale. Le test ci-dessus montre que l'amélioration des performances est également très significative. Optimisation des sous-graphes Basée sur la plate-forme CPU, Intel a construit des recommandations uniques dans DeepRec couvrant plusieurs modèles grand public tels que WDL, DeepFM, DLRM, DIEN, DIN, DSSM, BST, MMoE, DBMTL, ESMM , etc. Collecte de modèles, impliquant divers scénarios courants tels que le rappel, le tri, le multi-objectif, etc. et l'optimisation des performances pour les plates-formes matérielles, ces modèles offrent d'excellentes performances sur les plates-formes CPU basées sur des ensembles de données open source tels que. comme le promeut Criteo. La performance la plus remarquable est sans aucun doute la mise en œuvre optimisée de la précision mixte BF16 et Float32. En ajoutant la fonction de personnalisation du type de données de la couche DNN dans DeepRec, nous pouvons répondre aux exigences de haute performance et de haute précision des scènes clairsemées. La manière d'activer l'optimisation est celle illustrée à la figure 3. Le type de données de la variable actuelle est. conservé comme Float32 via keep_weights. Empêchez la baisse de précision causée par l'accumulation de gradient, puis utilisez deux opérations de conversion pour convertir l'opération DNN en BF16 pour le calcul en s'appuyant sur l'unité de calcul matérielle BF16 du processeur Intel® Xeon® Scalable de troisième génération. Les performances du calcul DNN sont considérablement améliorées, tout en améliorant encore les performances grâce aux opérations de fusion de graphes. Figure 3 Comment activer l'optimisation de précision mixte Afin de pouvoir montrer l'impact de BF16 sur la précision du modèle AUC (Area Under Curve) et les performances Gsteps/ s, pour le modelzoo existant. Les modèles appliquent tous la méthode d'optimisation de précision mixte ci-dessus. L'évaluation de l'équipe Alibaba PAI utilisant DeepRec sur la plateforme Alibaba Cloud montre que [1], sur la base de l'ensemble de données Criteo, après optimisation à l'aide de BF16, la précision du modèle WDL ou AUC peut s'approcher du FP32, et les performances d'entraînement du modèle BF16 sont améliorées de 1,4 fois, ce qui est un effet remarquable. À l'avenir, afin de maximiser les avantages du matériel de la plate-forme CPU, en particulier pour maximiser l'effet des nouvelles fonctionnalités matérielles, DeepRec mettra davantage en œuvre l'optimisation sous différents angles, y compris les opérateurs d'optimisation, les sous-graphiques d'attention et l'ajout d'objectifs multiples. modèles, etc., afin de créer des solutions CPU plus performantes pour les scènes clairsemées. Utilisez PMem pour implémenter le stockage intégré Pour les moteurs de formation et de prédiction de modèles clairsemés à très grande échelle (centaines de milliards de fonctionnalités, des milliards d'échantillons, niveau de modèle de 10 To), si tous sont aléatoires et dynamiques les mémoires d'accès sont utilisées (Dynamic Random Access Memory, DRAM) pour le stockage augmentera considérablement le coût total de possession (Total Cost of Ownership, TCO), et en même temps exercera une pression énorme sur l'exploitation et la gestion informatique de l'entreprise, rendant la mise en œuvre des solutions d’IA rencontrent des défis. PMem présente les avantages d'une densité de stockage et d'une persistance des données plus élevées, ses performances d'E/S sont proches de la DRAM et son coût est plus abordable. Il peut répondre pleinement aux besoins de haute performance et de grande capacité des ultra-grandes capacités. -formation et prédiction clairsemées à grande échelle. PMem prend en charge deux modes de fonctionnement, à savoir le mode mémoire et le mode App Direct. En mode mémoire, il est identique au stockage système volatile (non persistant) ordinaire, mais à un coût inférieur, permettant une capacité plus élevée tout en conservant les budgets système et en fournissant des téraoctets de mémoire sur un seul serveur. Capacité totale par rapport au mode mémoire, application ; le mode d’accès direct peut profiter de la fonctionnalité de persistance de PMem. En mode d'accès direct à l'application, PMem et sa mémoire DRAM adjacente seront reconnues comme mémoire adressable par octets. Le système d'exploitation peut utiliser le matériel PMem comme deux périphériques différents. L'un est le mode FSDAX, PMem est configuré comme un périphérique de bloc et les utilisateurs peuvent le faire. formatez-le dans un système de fichiers pour l'utiliser ; l'autre est le mode DEVDAX, PMem est piloté comme un périphérique à un seul caractère, s'appuie sur la fonctionnalité KMEM DAX fournie par le noyau (5.1 ou supérieur) et traite PMem comme volatile. Il utilise une mémoire flexible et est connecté au système de gestion de la mémoire. En tant que nœud NUMA de mémoire plus lent et plus grand, similaire à la DRAM, l'application peut y accéder de manière transparente. Dans la formation de fonctionnalités à très grande échelle, l'intégration du stockage variable occupe plus de 90 % de la mémoire, et la capacité de la mémoire deviendra l'un de ses goulots d'étranglement. L'enregistrement d'EV sur PMem peut briser ce goulot d'étranglement et créer plusieurs valeurs, telles que l'amélioration de la capacité de stockage de mémoire de la formation distribuée à grande échelle, la prise en charge de la formation et de la prédiction de modèles plus grands, la réduction de la communication entre plusieurs machines et l'amélioration des performances de formation des modèles. réduisant le coût total de possession. Dans l'intégration du stockage hybride multi-niveaux, PMem est également un excellent choix pour briser le goulot d'étranglement de la DRAM. Actuellement, il existe trois façons de stocker les véhicules électriques dans PMem, et lors de l'exécution d'un micro-benchmark, d'un modèle WDL et d'un modèle proxy WDL des trois manières suivantes, les performances sont très proches de celles du stockage des véhicules électriques dans la DRAM, ce qui représente sans aucun doute son TCO. mieux. Gros avantages : Par conséquent, le prochain plan d'optimisation utilisera PMem pour enregistrer le modèle et stocker le fichier de point de contrôle du modèle clairsemé dans la mémoire persistante. Obtenez des améliorations de performances de plusieurs ordres de grandeur et débarrassez-vous du dilemme actuel lié à l'utilisation du SSD pour sauvegarder et restaurer de très grands modèles, ce qui prend beaucoup de temps et les prédictions d'entraînement seront interrompues pendant cette période.
FPGA accélère la recherche d'intégrationLa formation et la prédiction clairsemées à grande échelle couvrent une variété de scénarios, tels que la formation distribuée, la prédiction distribuée et sur une seule machine, et la formation informatique hétérogène. Par rapport aux réseaux de neurones convolutifs (CNN) ou aux réseaux de neurones récurrents (RNN) traditionnels, ils présentent une différence clé, à savoir le traitement de la table d'intégration, et les exigences de traitement de la table d'intégration dans ces scénarios sont confrontées à de nouveaux défis : Le moteur KV implémenté par logiciel via multi-threading est devenu le goulot d'étranglement de la circulation série I prenant en charge CXL (Compute Express Link) a été introduit dans l'optimisation. Le chemin de mise en œuvre est illustré à la figure 5. : TM série I Résumé L'article précédent a présenté le schéma de mise en œuvre d'optimisation de DeepRec sur différents matériels de CPU, PMem et FPGA, et l'a déployé avec succès dans plusieurs scénarios commerciaux internes et externes d'Alibaba, et a également réalisé un bout en bout évident résultats dans l'activité réelle. L'accélération des performances de bout en bout résout les problèmes et les défis rencontrés par les scénarios clairsemés à très grande échelle sous différents angles. Comme nous le savons tous, Intel propose des options matérielles diversifiées pour les applications d'IA, permettant aux clients de choisir des solutions d'IA plus rentables. En même temps, Intel, Alibaba et ses clients travaillent ensemble pour mettre en œuvre une innovation logicielle et matérielle basée sur ; matériel diversifié. Collaborez et optimisez pour mieux exploiter la valeur des technologies et des plates-formes Intel. Intel espère également continuer à travailler avec des partenaires industriels pour développer une coopération plus approfondie et continuer à contribuer au déploiement de la technologie de l'IA. Intel ne contrôle ni n'audite les données de tiers. Veuillez examiner ce contenu, consulter d'autres sources et confirmer que les données mentionnées sont exactes. Les scénarios de réduction des coûts décrits visent à illustrer l'impact de produits Intel spécifiques sur les coûts futurs et à générer des économies dans des situations et des configurations spécifiques. Chaque situation est différente. Intel ne garantit aucun coût ni réduction de coût. Les fonctionnalités et avantages de la technologie Intel dépendent de la configuration du système et peuvent nécessiter l'activation de matériel, de logiciels ou de services activés. Les performances du produit peuvent varier en fonction de la configuration du système. Aucun produit ou composant n’est totalement sûr. Plus d’informations sont disponibles auprès du fabricant ou du détaillant d’équipement d’origine, ou consultez intel.com. Intel, le logo Intel et les autres marques Intel sont des marques commerciales d'Intel Corporation ou de ses filiales aux États-Unis et/ou dans d'autres pays. © Copyright Intel Corporation [1] https://github.com/alibaba/DeepRec/tree/ main/modelzoo/ WDL[2] https://help.aliyun.com/document_detail/25378.html?spm=5176.2020520101 .0.0.787c4df5FgibRE#re7p 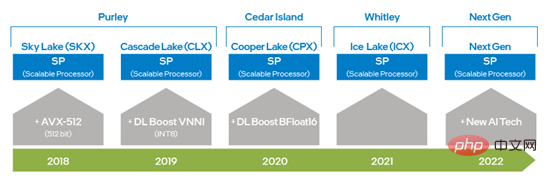
 Figure 2 Sélectionnez le cas d'optimisation de l'opérateur
Figure 2 Sélectionnez le cas d'optimisation de l'opérateur
En définissant do_fusion sur True dans l'API tf.feature_column.embedding_column(..., do_fusion=True), vous pouvez activer la fonction d'optimisation de sous-graphe d'intégration. 

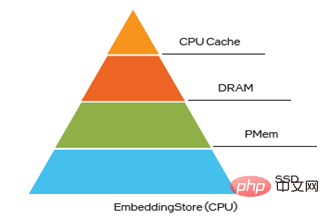 Figure 4 Intégration du stockage hybride multi-niveaux
Figure 4 Intégration du stockage hybride multi-niveaux
TM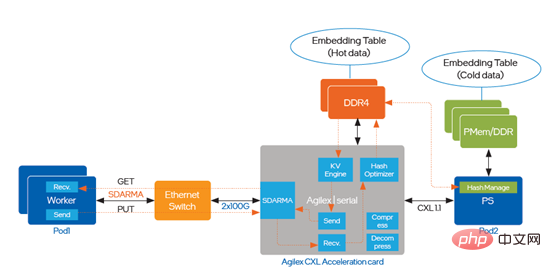
Mentions légales
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI