
Maison >Périphériques technologiques >IA >ViP3D : prédiction visuelle de trajectoire de bout en bout via une requête d'agent 3D
ViP3D : prédiction visuelle de trajectoire de bout en bout via une requête d'agent 3D

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-08 20:51:081534parcourir
Article arXiv "ViP3D : End-to-end Visual Trajectory Prediction via 3D Agent Queries", mis en ligne le 2 août 22, produit conjointement par l'Université Tsinghua, Shanghai (Yao) Qizhi Research Institute, CMU, Fudan, Li Auto et MIT, etc. Travail.

Le pipeline de conduite autonome existant sépare le module de perception du module de prédiction. Les deux modules communiquent via des fonctionnalités sélectionnées manuellement telles que des boîtes d'agents et des trajectoires comme interfaces. Du fait de cette séparation, le module de prédiction ne reçoit que des informations partielles du module de perception. Pire encore, les erreurs du module de perception peuvent se propager et s'accumuler, affectant négativement les résultats de prédiction.
Ce travail propose ViP3D, un pipeline de prédiction de trajectoire visuelle qui utilise les riches informations de la vidéo originale pour prédire la trajectoire future de l'agent dans la scène. ViP3D utilise une requête d'agent clairsemée tout au long du pipeline, ce qui la rend entièrement différenciable et interprétable. De plus, un nouvel indice d'évaluation pour la tâche de prédiction de trajectoire visuelle de bout en bout est proposé, End-to-end Prediction Accuracy (EPA, End-to-end Prediction Accuracy), qui prend en compte de manière globale la précision de la perception et de la prédiction. tout en améliorant la précision des prédictions, les trajectoires sont évaluées par rapport aux trajectoires de vérité terrain.
L'image montre la comparaison entre le pipeline en cascade multi-étapes traditionnel et ViP3D : le pipeline traditionnel implique plusieurs modules non différenciables, tels que la détection, le suivi et la prédiction. ViP3D prend la vidéo multi-vues en entrée et génère des trajectoires prédites dans un de bout en bout. Utilisation efficace des informations visuelles, telles que les clignotants des véhicules.
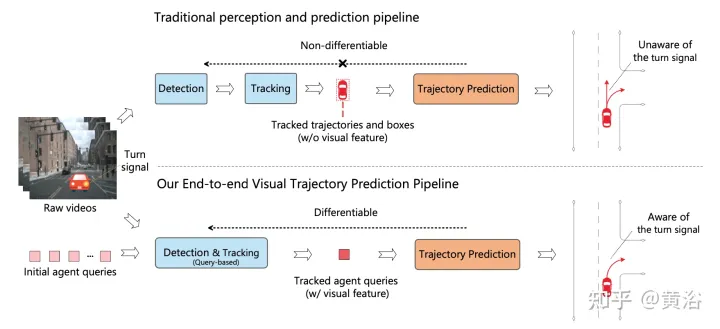
ViP3D vise à résoudre le problème de prédiction de trajectoire des vidéos originales de bout en bout. Plus précisément, grâce à des vidéos multi-vues et des cartes haute définition, ViP3D prédit les trajectoires futures de tous les agents de la scène.
Le processus global de ViP3D est illustré dans la figure : Tout d'abord, le tracker basé sur des requêtes traite les vidéos multi-vues des caméras environnantes pour obtenir la requête de l'agent suivi avec des fonctionnalités visuelles. Les fonctionnalités visuelles de la requête d'agent capturent la dynamique de mouvement et les caractéristiques visuelles des agents, ainsi que les relations entre les agents. Après cela, le prédicteur de trajectoire prend la requête de l'agent de suivi en entrée, l'associe aux caractéristiques de la carte HD et génère finalement la trajectoire prédite.
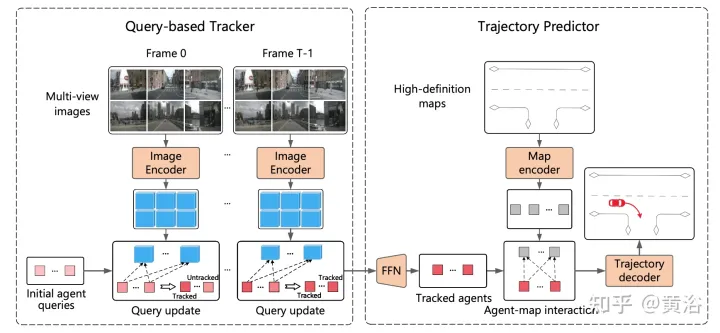
Le tracker basé sur des requêtes extrait les caractéristiques visuelles de la vidéo brute de la caméra surround. Plus précisément, pour chaque image, les caractéristiques de l'image sont extraites selon DETR3D. Pour l'agrégation des fonctionnalités du domaine temporel, un tracker basé sur des requêtes est conçu selon MOTR («Motr: End-to-end multiple-object tracking with transformer». arXiv 2105.03247, 2021), comprenant deux étapes clés : mise à jour des fonctionnalités de requête et supervision des requêtes. La requête de l'agent sera mise à jour au fil du temps pour modéliser la dynamique de mouvement de l'agent.
La plupart des méthodes de prédiction de trajectoire existantes peuvent être divisées en trois parties : l'encodage d'agent, l'encodage de carte et le décodage de trajectoire. Après un suivi basé sur des requêtes, la requête de l'agent suivi est obtenue, qui peut être considérée comme les caractéristiques de l'agent obtenues grâce au codage de l'agent. Par conséquent, les tâches restantes sont le codage de la carte et le décodage de la trajectoire.
Représentez les agents de prédiction et de vérité sous la forme d'ensembles non ordonnés Sˆ et S respectivement, où chaque agent est représenté par les coordonnées d'agent du pas de temps actuel et de K trajectoires futures possibles. Pour chaque type d'agent c, calculez la précision de la prédiction entre Scˆ et Sc. Le coût entre l'agent de prédiction et le véritable agent est défini comme :

L'EPA entre Scˆ et Sc est défini comme :

Les résultats expérimentaux sont les suivants :
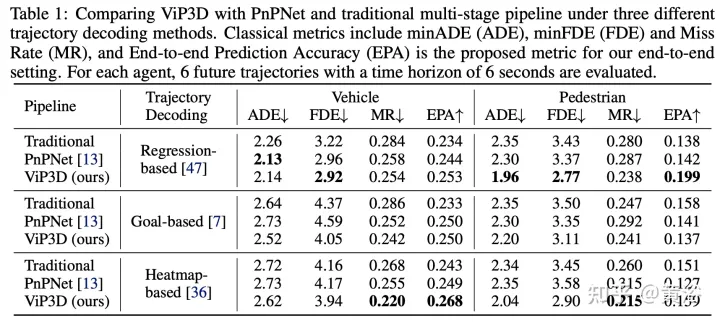
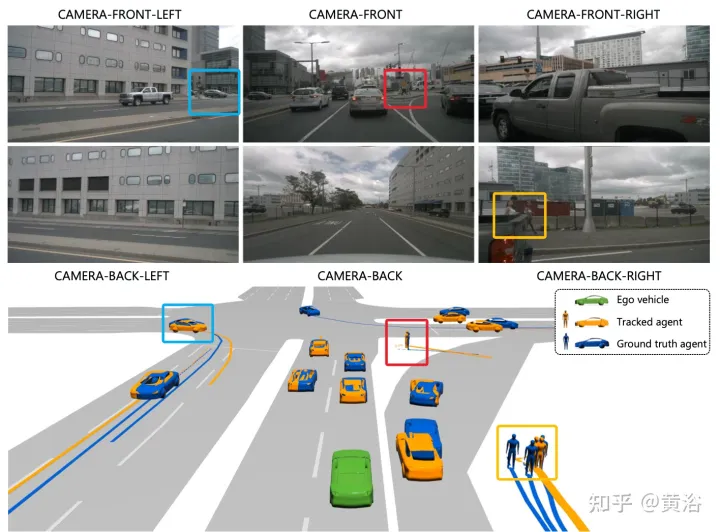
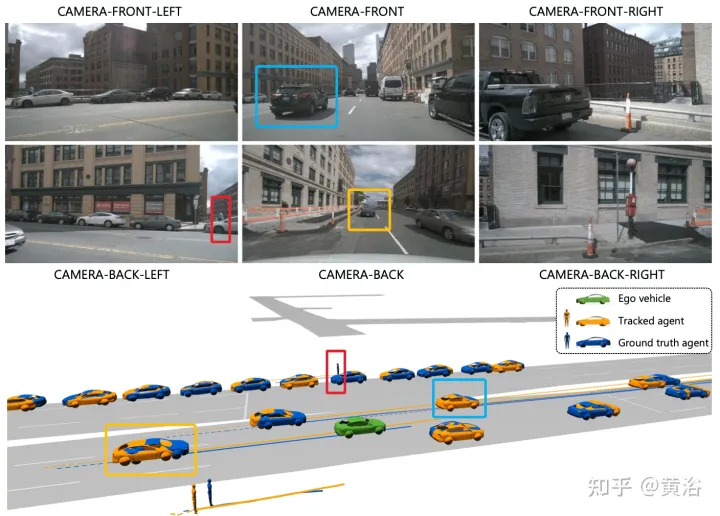
Remarque : Ce rendu cible est bien réalisé.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI