
Maison >Périphériques technologiques >IA >Utiliser l'apprentissage automatique pour reconstruire des visages dans des vidéos
Utiliser l'apprentissage automatique pour reconstruire des visages dans des vidéos

- 王林avant
- 2023-04-08 19:21:061105parcourir
Traducteur | Cui Hao
Critique | Sun Shujuan
Ouverture
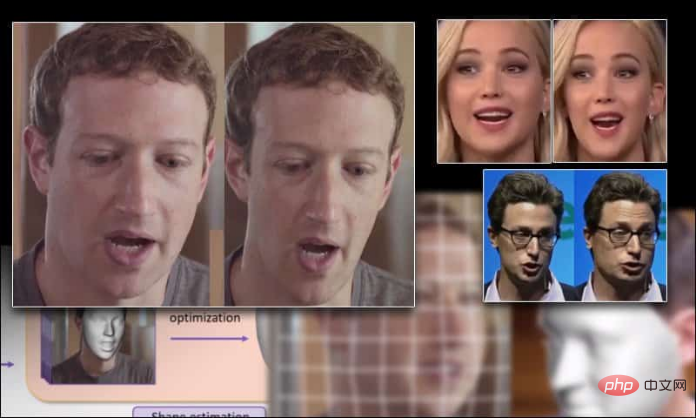
Une recherche collaborative en Chine et au Royaume-Uni a mis au point une nouvelle méthode pour remodeler les visages dans les vidéos. Cette technologie peut agrandir et réduire la structure du visage avec une grande cohérence et sans aucune trace de coupe artificielle.
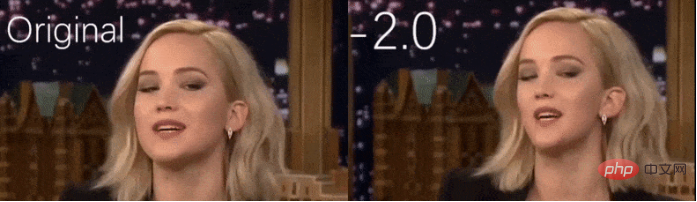
En général, cette transformation de la structure du visage est obtenue grâce à des méthodes CGI traditionnelles, qui reposent sur des procédures détaillées et coûteuses de capping de mouvement, de gréage et de texturation pour reconstruire complètement le visage.
Différent des méthodes traditionnelles, le CGI de la nouvelle technologie est intégré dans le pipeline neuronal en tant que paramètre pour les informations faciales 3D et sert de base au flux de travail d'apprentissage automatique.
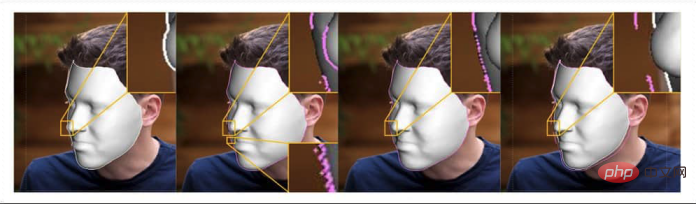
L'auteur souligne :
« Notre objectif est d'utiliser des visages naturels du monde réel comme base pour déformer et modifier les contours de leur visage afin de générer des vidéos de reconstruction de portrait de haute qualité [résultats]. utilisé pour les applications d'effets visuels telles que l'embellissement du visage et l'exagération du visage
Bien que les techniques de distorsion faciale 2D soient disponibles pour les consommateurs depuis l'avènement de Photoshop (et ont donné naissance à une sous-culture de distorsions faciales et de dysmorphie corporelle pour la vidéo sans utilisation). CGI est encore une technologie difficile

La taille du visage de Mark Zuckerberg s'est agrandie et réduite en raison des nouvelles technologies
Actuellement, le remodelage du corps est un sujet brûlant dans le domaine de la vision, principalement en raison de son potentiel dans la mode. le commerce électronique, comme faire paraître les gens plus grands et avec une ossature plus diversifiée, mais il reste encore quelques défis
Encore une fois, de manière convaincante, changer la forme des visages dans la vidéo a été au cœur du travail des chercheurs, bien que. la mise en œuvre de la technologie a été entravée par le traitement humain et d'autres limitations. Le nouveau produit migre ainsi les capacités précédemment étudiées des extensions statiques vers la sortie vidéo dynamique.
Le nouveau système est formé sur un ordinateur de bureau équipé d'AMD Ryzen 9 3950X et de 32 Go de mémoire. , et utilise l'algorithme de flux optique d'OpenCV pour générer des cartes de mouvement et les lisser via le framework StructureFlow (FAN) pour le composant d'estimation des caractéristiques, également utilisé dans le package de composants deepfakes populaire travaillant avec Ceres Solver pour résoudre les problèmes d'optimisation du visage
; 
Exemple d'utilisation du nouveau système pour agrandir les visages
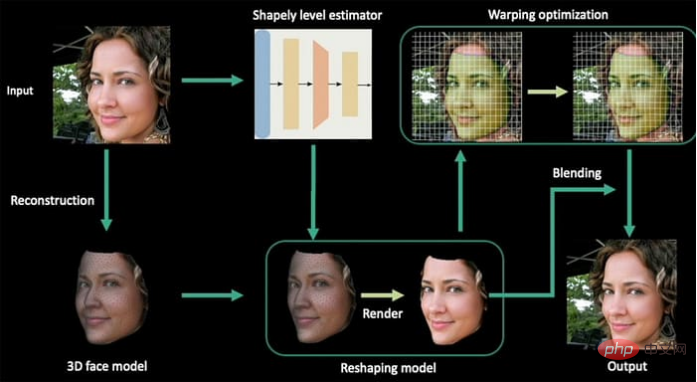
Le titre de cet article est Remodelage paramétrique des portraits dans les vidéos, et son auteur est trois chercheurs de l'Université du Zhejiang et un de l'Université de Bath. Dans le nouveau système, les vidéos sont extraites en séquences d'images, en construisant d'abord un modèle de base pour le visage, puis en concaténant les images suivantes représentatives, construisant ainsi des paramètres de personnalité cohérents dans toute la direction de l'image (c'est-à-dire la direction de l'image vidéo).
Processus architectural du système de déformation du visage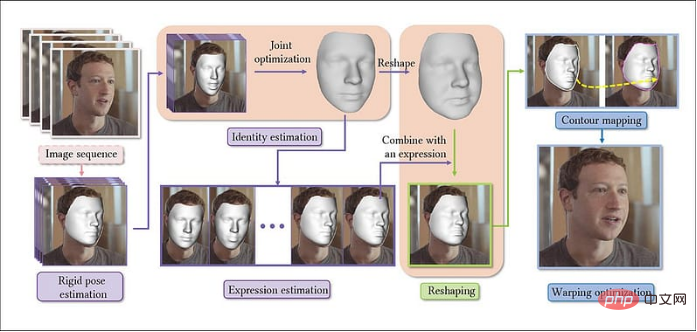 Ensuite, selon l'expression de calcul, les paramètres de mise en forme mis en œuvre par régression linéaire sont générés. Ensuite, une cartographie 2D des contours du visage est construite grâce à la fonction de distance signée (SDF. ) avant et après le remodelage du visage. Enfin, la vidéo de sortie est soumise à une optimisation de la déformation pour la reconnaissance du contenu.
Ensuite, selon l'expression de calcul, les paramètres de mise en forme mis en œuvre par régression linéaire sont générés. Ensuite, une cartographie 2D des contours du visage est construite grâce à la fonction de distance signée (SDF. ) avant et après le remodelage du visage. Enfin, la vidéo de sortie est soumise à une optimisation de la déformation pour la reconnaissance du contenu.
Ce processus utilise le modèle de visage 3D morphable (3DMM) est un outil auxiliaire de synthèse de visage neuronal et basé sur GAN qui convient également. systèmes de détection de deepfake
Exemples du modèle de visage morphable 3D (3DMM) — — Surfaces prototypes paramétriques utilisées dans de nouveaux projets. En haut à gauche, application iconique sur surface 3DMM. En haut à droite, sommets du maillage 3D de l'isomap. Le coin inférieur gauche montre l'ajustement des caractéristiques ; l'image inférieure du milieu, l'isomap de la texture du visage extraite et le coin inférieur droit, l'ajustement et la forme finaux;
Le flux de travail du nouveau système prendra en compte les situations d'occlusion, par exemple lorsqu'un objet s'éloigne de la vue. C’est également l’un des plus grands défis des logiciels deepfake, car les repères FAN peuvent à peine rendre compte de ces situations et leur qualité de traduction a tendance à se dégrader à mesure que les visages sont évités ou masqués.
Le nouveau système évite les problèmes ci-dessus en définissant une « énergie de contour » qui correspond aux limites des faces 3D (3DMM) et des faces 2D (définies par les repères FAN).
Optimisation
Le scénario d'application de ce système est la déformation en temps réel, telle que les changements de forme du visage en temps réel dans les filtres des chats vidéo. Actuellement, les frameworks ne peuvent pas y parvenir, donc fournir les ressources informatiques nécessaires pour permettre une déformation « en temps réel » devient un défi important.
Selon l'hypothèse de l'article, la latence de chaque opération d'image d'une vidéo à 24 ips dans le pipeline par rapport au matériau par seconde est de 16,344 secondes. Dans le même temps, pour l'estimation des caractéristiques et la déformation faciale 3D, elle est également accompagnée de. un coup (321 millisecondes et 160 millisecondes respectivement) milliseconde).
En conséquence, l’optimisation a réalisé des progrès clés dans la réduction de la latence. Étant donné qu'une optimisation conjointe sur toutes les trames augmenterait considérablement la surcharge du système et que l'optimisation du style d'initialisation (en supposant des caractéristiques de locuteur cohérentes dans l'ensemble) pourrait conduire à des anomalies, les auteurs ont adopté un mode clairsemé pour calculer les coefficients à des intervalles réalistes des trames échantillonnées.
Ensuite, une optimisation conjointe est effectuée sur ce sous-ensemble de cadres, ce qui entraîne un processus de reconstruction plus simple.
Surfaces faciales
La technologie de morphing utilisée dans ce projet est une adaptation de l'ouvrage de l'auteur de 2020 Deep Shapely Portraits (DSP).
Deep Shapely Portraits, soumission 2020 à ACM Multimedia. L'article a été dirigé par des chercheurs du laboratoire commun Tencent et Game and Intelligent Graphics Innovation Technology de l'Université du Zhejiang. Les auteurs ont observé que « nous avons étendu cette méthode du remodelage d'une seule image au remodelage d'une séquence d'images entière
Test
Le. Le document note qu’il n’existe pas de données historiques comparables pour évaluer la nouvelle approche. Par conséquent, les auteurs ont comparé leurs images de sortie vidéo incurvées avec une sortie DSP statique.
 Test du nouveau système contre des images statiques de Deep Shapely Portraits
Test du nouveau système contre des images statiques de Deep Shapely Portraits
Les auteurs soulignent que la méthode DSP souffre d'artefacts dus à l'utilisation d'un mappage clairsemé - le nouveau framework résout ce problème grâce à un mappage dense. En outre, l'article affirme que les vidéos produites par DSP manquent de fluidité et de cohérence visuelle.
L'auteur souligne :
« Les résultats montrent que notre méthode peut générer de manière stable et cohérente des vidéos de portraits remodelées, tandis que les méthodes basées sur l'image peuvent facilement conduire à des artefacts de scintillement évidents (traces de modifications artificielles). »
Introduction de l'auteur traduit
Cui Hao, rédacteur de la communauté 51CTO, architecte senior, a 18 ans d'expérience en développement logiciel et en architecture, et 10 ans d'expérience en architecture distribuée. Anciennement expert technique chez HP. Il est prêt à partager et a écrit de nombreux articles techniques populaires avec plus de 600 000 lectures. Auteur de "Principes et pratique de l'architecture distribuée".
Titre original :Restructuring Faces in Videos With Machine Learning, auteur : Martin Anderson
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI