
Maison >Périphériques technologiques >IA >Ensembles de données et perception de conduite dans des conditions météorologiques répétitives et difficiles
Ensembles de données et perception de conduite dans des conditions météorologiques répétitives et difficiles

- 王林avant
- 2023-04-08 19:11:081470parcourir
Article arXiv « Ithaca365 : Dataset and Driving Perception under Repeated and Challenging Weather Conditions », mis en ligne le 1er 22 août, travaux des universités de Cornell et de l'État de l'Ohio.

Ces dernières années, les capacités de perception des véhicules autonomes se sont améliorées grâce à l'utilisation d'ensembles de données à grande échelle, qui sont souvent collectées dans des endroits spécifiques et dans de bonnes conditions météorologiques. Cependant, afin de répondre à des exigences de sécurité élevées, ces systèmes de détection doivent fonctionner de manière robuste dans diverses conditions météorologiques, notamment la neige et la pluie.
Cet article propose un ensemble de données pour parvenir à une conduite autonome robuste, en utilisant un nouveau processus de collecte de données, c'est-à-dire dans différents scénarios (ville, autoroute, zone rurale, campus), météo (neige, pluie, soleil), heure (jour /nuit) ) et les conditions de circulation (piétons, cyclistes et voitures), les données ont été enregistrées à plusieurs reprises tout au long d'un parcours de 15 km.
Cet ensemble de données comprend des images et des nuages de points provenant de caméras et de capteurs lidar, ainsi que des GPS/INS de haute précision pour établir une correspondance entre les itinéraires. L'ensemble de données comprend des annotations de routes et d'objets, des occlusions locales et des cadres de délimitation 3D capturés avec des masques amodaux.
Les chemins répétés ouvrent de nouvelles directions de recherche pour la découverte de cibles, l'apprentissage continu et la détection d'anomalies.
Lien Ithaca365 : Un nouvel ensemble de données pour permettre une conduite autonome robuste via un nouveau processus de collecte de données
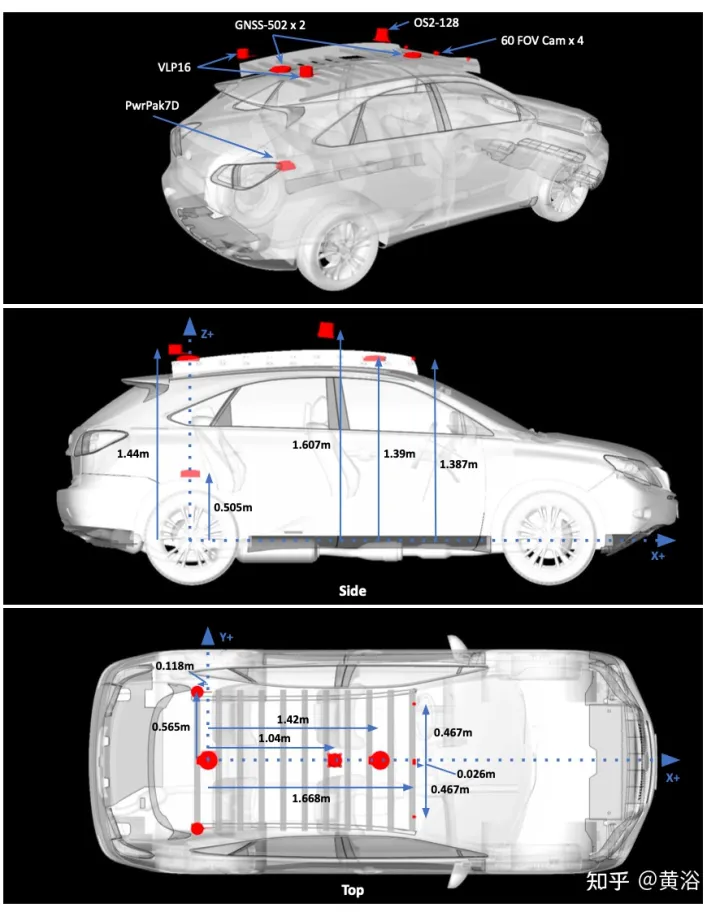
L'image est la configuration du capteur pour la collecte de données :
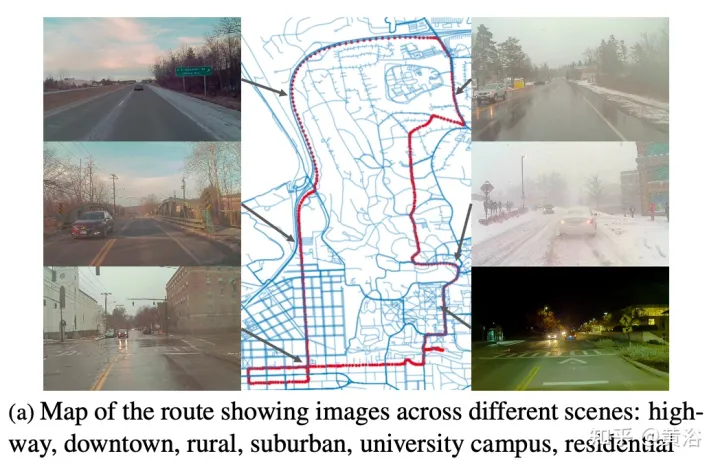
L'image a montre la feuille de route avec des captures à plusieurs endroits. Les déplacements étaient programmés pour collecter des données à différents moments de la journée, y compris la nuit. Enregistrez les fortes chutes de neige avant et après le déneigement de la route.
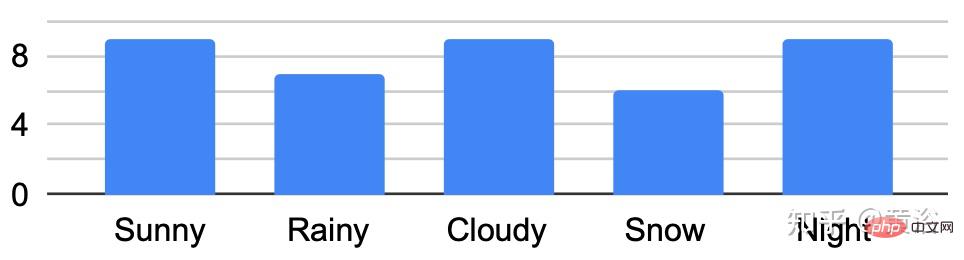
Une caractéristique clé de l'ensemble de données est que les mêmes emplacements peuvent être observés dans des conditions différentes ; un exemple est présenté dans la figure b.

La figure montre l'analyse transversale dans différentes conditions :
Développer un outil de marquage personnalisé pour obtenir des masques non modaux de routes et de cibles. Pour les étiquettes de route soumises à des conditions environnementales différentes, telles que des routes enneigées, utilisez des parcours répétés du même itinéraire. Plus précisément, la carte routière en nuage de points construite à partir des données d'attitude GPS et lidar convertit l'étiquette routière de « beau temps » en « mauvais temps ».
Les itinéraires/données sont divisés en 76 intervalles. Projetez le nuage de points dans BEV et étiquetez la route à l'aide de l'annotateur de polygone. Une fois la route marquée en BEV (générant une limite de route 2D), le polygone est décomposé en polygones plus petits de 150 m^2, en utilisant un seuil de 1,5 m de hauteur moyenne, et un ajustement plan est effectué sur les points du polygone. limite pour déterminer la hauteur de la route.
Ajustez un plan à ces points avec RANSAC et un régresseur ; puis calculez la hauteur de chaque point le long de la frontière en utilisant le plan de sol estimé. Projetez les points de la route dans l'image et créez un masque de profondeur pour obtenir l'étiquette non modale de la route. Faire correspondre les emplacements aux cartes marquées avec le GPS et optimiser les itinéraires avec ICP permet de projeter le plan de sol vers des emplacements spécifiques sur de nouveaux itinéraires de collecte.
Une vérification finale de la solution ICP en vérifiant que le masque de vérité terrain moyen projeté de l'étiquette routière est conforme à 80 % de mIOU avec tous les autres masques de vérité terrain au même endroit, sinon les données de localisation de la requête ne sont pas récupérées ;
Les cibles amodales sont étiquetées avec Scale AI pour six catégories de cibles de premier plan : voitures, bus, camions (y compris les marchandises, les camions de pompiers, les camionnettes, les ambulances), les piétons, les cyclistes et les motocyclistes.
Ce paradigme d'étiquetage comporte trois éléments principaux : d'abord identifier les instances visibles d'un objet, puis déduire des masques de segmentation d'instances occluses, et enfin étiqueter l'ordre d'occlusion de chaque objet. Le marquage est effectué sur la vue de la caméra avant la plus à gauche. Suit les mêmes normes que KINS ("Segmentation d'instance modale avec ensemble de données kins". CVPR, 2019).
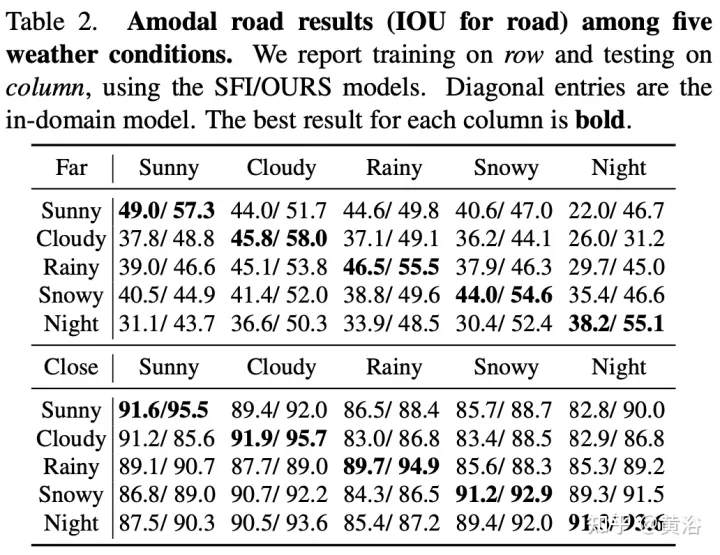
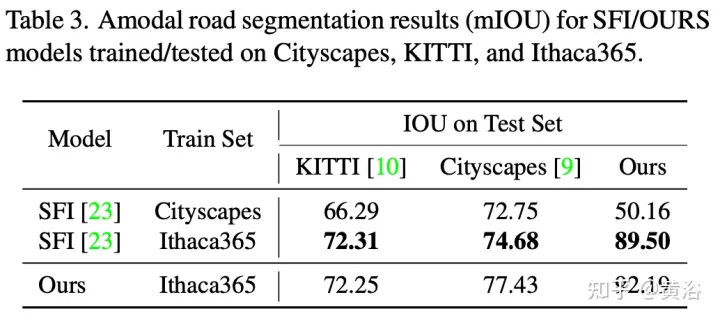
Pour démontrer la diversité environnementale et la qualité amodale de l'ensemble de données, deux réseaux de référence ont été formés et testés pour identifier les routes amodales au niveau du pixel, fonctionnant même lorsque les routes sont couvertes de neige ou de voitures. Le premier réseau de base est le Semantic Foreground Inpainting (SFI). La deuxième référence, comme le montre la figure, utilise les trois innovations suivantes pour améliorer SFI.
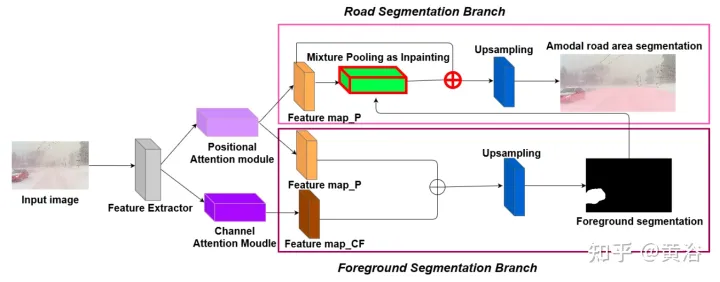
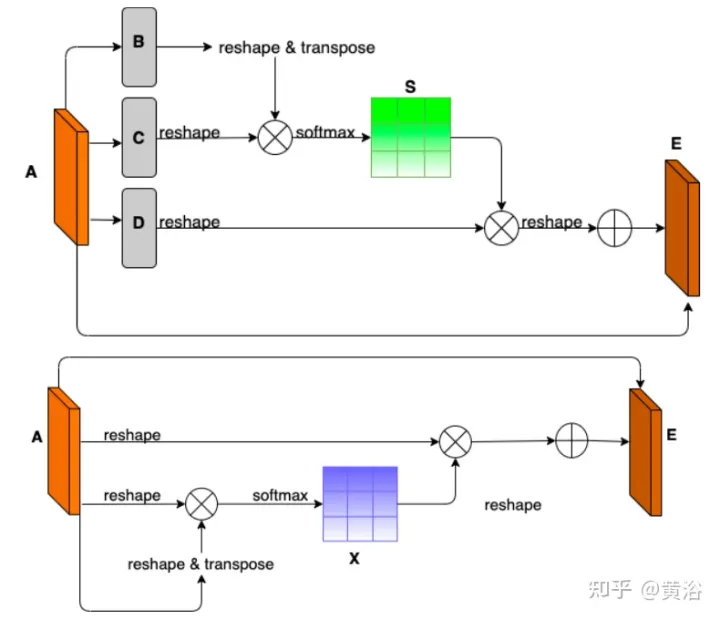
- Remarque sur la position et le canal : étant donné que la segmentation amodale déduit principalement ce qui est invisible, le contexte est un indice très important. DAN (« Dual attention network for scene segmentation », CVPR’2019) introduit deux innovations pour capturer deux arrière-plans différents. Le module d'attention de position (PAM) utilise les fonctionnalités des pixels pour se concentrer sur d'autres pixels de l'image, capturant ainsi le contexte d'autres parties de l'image. Le Channel Attention Module (CAM) utilise un mécanisme d'attention similaire pour regrouper efficacement les informations sur les canaux. Ici, ces deux modules sont appliqués sur l'extracteur de fonctionnalités du backbone. Combinaison de CAM et PAM pour une meilleure localisation des limites fines des masques. Le masque d'instance final de premier plan est obtenu grâce à une couche de suréchantillonnage.
- Regroupement hybride comme inpainting : le pooling maximum est utilisé comme opération d'inpainting pour remplacer les éléments de premier plan qui se chevauchent par des éléments d'arrière-plan à proximité afin de faciliter la restauration des éléments routiers non modaux. Cependant, comme les fonctionnalités d’arrière-plan sont généralement réparties de manière fluide, l’opération de pooling maximal est très sensible à tout bruit ajouté. En revanche, les opérations de mutualisation moyennes atténuent naturellement le bruit. À cette fin, le pooling moyen et le pooling maximum sont combinés pour l’application de correctifs, appelé Mixture Pooling.
- Opération Somme : avant la dernière couche de suréchantillonnage, les fonctionnalités du module de pooling hybride ne sont pas transmises directement, mais les liens résiduels de la sortie du module PAM sont inclus. En optimisant conjointement deux cartes de caractéristiques dans la branche de segmentation routière, le module PAM peut également apprendre les caractéristiques d'arrière-plan des zones occultées. Cela peut conduire à une récupération plus précise des fonctionnalités en arrière-plan.
L'image montre le schéma d'architecture de PAM et CAM :
Le pseudo-code de l'algorithme pour le patching par pooling hybride est le suivant :

Le code de formation et de test pour la segmentation routière non modale est le suivant suit : https://github.com/coolgrasshopper/amodal_road_segmentation
Les résultats expérimentaux sont les suivants :
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI