
Maison >Périphériques technologiques >IA >Google a créé un système de traduction automatique pour plus de 1 000 langues de « longue traîne » et prend déjà en charge certaines langues de niche
Google a créé un système de traduction automatique pour plus de 1 000 langues de « longue traîne » et prend déjà en charge certaines langues de niche

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-08 15:21:131757parcourir
La qualité des systèmes de traduction automatique (TA) académiques et commerciaux s'est considérablement améliorée au cours de la dernière décennie. Ces améliorations sont en grande partie dues aux progrès de l’apprentissage automatique et à la disponibilité d’ensembles de données d’exploration du Web à grande échelle. Dans le même temps, l'émergence de modèles d'apprentissage profond (DL) et d'E2E, d'ensembles de données monolingues parallèles à grande échelle obtenus à partir de l'exploration du Web, de méthodes d'amélioration des données telles que la rétro-traduction et l'auto-formation, ainsi que de méthodes multi-apprentissage à grande échelle. la modélisation linguistique a permis de prendre en charge plus de 100 systèmes de traduction automatique de haute qualité pour les langues.
Cependant, malgré les énormes progrès de la traduction automatique à faibles ressources, les langues pour lesquelles des systèmes de traduction automatique largement disponibles et généraux ont été construits sont limitées à environ 100, qui ne sont évidemment que parmi les plus de 7000 langues parlé dans le monde aujourd’hui. Outre le nombre limité de langues, la répartition des langues prises en charge par les systèmes de traduction automatique actuels est également fortement orientée vers les langues européennes.
On constate que malgré leurs populations importantes, il existe moins de services liés aux langues parlées en Afrique, en Asie du Sud et du Sud-Est, et aux langues amérindiennes. Par exemple, Google Translate prend en charge le frison, le maltais, l'islandais et le corse, qui comptent tous moins d'un million de locuteurs natifs. À titre de comparaison, la population dialectale du Bihar non desservie par Google Translate est d'environ 51 millions, la population oromo est d'environ 24 millions, la population quechua est d'environ 9 millions et la population tigrinya est d'environ 9 millions (2022). Ces langages sont connus sous le nom de langages « à longue traîne », et le manque de données nécessite l'application de techniques d'apprentissage automatique qui peuvent se généraliser au-delà des langages disposant de données de formation suffisantes.
La création de systèmes de traduction automatique pour ces langues à longue traîne est largement limitée par le manque d'ensembles de données numérisées disponibles et d'outils PNL tels que les modèles d'identification de langue (LangID). Ceux-ci sont omniprésents pour les langues à ressources élevées.
Dans un récent article de Google intitulé « Construire des systèmes de traduction automatique pour les mille prochaines langues », plus de deux douzaines de chercheurs ont démontré les résultats de leurs efforts pour créer des systèmes de traduction automatique pratiques prenant en charge plus de 1 000 langues.

Adresse papier : https://arxiv.org/pdf/2205.03983.pdf
Plus précisément, les chercheurs ont décrit leurs résultats dans les trois domaines de recherche suivants.
Tout d'abord, créez des ensembles de données propres et extraits du Web pour plus de 1 500 langues grâce à une pré-formation semi-supervisée à la reconnaissance des langues et aux techniques de filtrage basées sur les données.
Deuxièmement, créez de nouveaux modèles pour les langues mal desservies avec des modèles multilingues à grande échelle formés sur des données parallèles supervisées pour plus de 100 langues à ressources élevées, ainsi que des ensembles de données monolingues pour plus de 1000 autres langues. Une machine pratique et efficace modèle de traduction.
Troisièmement, étudiez les limites des métriques d'évaluation pour ces langages et effectuez une analyse qualitative de la sortie des modèles de traduction automatique, en vous concentrant sur plusieurs modèles d'erreur courants de ces modèles.
Nous espérons que ce travail pourra fournir des informations utiles aux praticiens travaillant sur la création de systèmes de traduction automatique pour des langues actuellement sous-étudiées. En outre, les chercheurs espèrent que ces travaux pourront conduire à des orientations de recherche qui remédieront aux faiblesses des modèles multilingues à grande échelle dans des contextes de données clairsemées.
Lors de la conférence I/O du 12 mai, Google a annoncé que son système de traduction avait ajouté 24 nouvelles langues, dont certaines langues amérindiennes de niche, comme les dialectes du Bihar mentionnés ci-dessus, l'oromo, le quechua et le tigrinya.

Aperçu de l'article
Cet ouvrage est principalement divisé en quatre grands chapitres. Voici seulement une brève introduction au contenu de chaque chapitre.
Créer un ensemble de données de texte Web en 1 000 langues
Ce chapitre détaille les méthodes utilisées par les chercheurs pour explorer des ensembles de données de texte en une seule langue pour plus de 1 500 langues. Ces méthodes se concentrent sur la récupération de données de haute précision (c'est-à-dire une forte proportion de texte propre et dans la langue), donc une grande partie repose sur diverses méthodes de filtrage.
En général, les méthodes utilisées par les chercheurs sont les suivantes :
- Supprimez les langues avec une mauvaise qualité des données de formation et de mauvaises performances LangID du modèle LangID, et entraînez un modèle LangID CLD3 de 1629 langues et un modèle LangID semi-supervisé (SSLID)
- Taux d'erreur dans le modèle CLD3 ; par langue Effectuer une opération de clustering ;
- Effectuer le premier tour d'exploration du Web en utilisant le modèle CLD3 ;
- Filtrer les phrases en utilisant la cohérence du document ;
- Filtrer tous les corpus en utilisant une liste de mots à seuil de pourcentage ; Utilisez un LangID semi-supervisé (SSLID) pour filtrer tous les corpus ;
- Utilisez le rappel relatif pour détecter les langues aberrantes et filtrez à l'aide de Term-Frequency-Inverse-Internet-Frequency (TF-IIF) ; Scores d'anomalies de fréquence pour détecter les langues aberrantes et concevoir manuellement des filtres pour elles
- Dédupliquer tous les corpus au niveau de la phrase ;
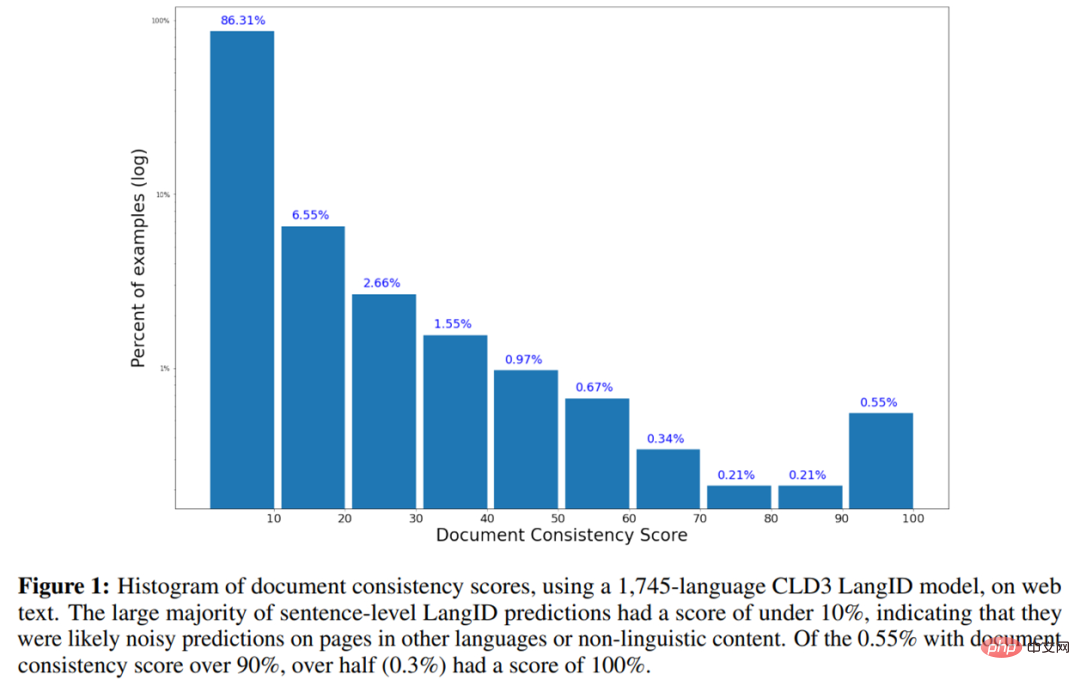
- Ce qui suit est l'histogramme du score de cohérence du document utilisant le modèle LangID CLD3 en 1745 langues sur le texte Web.
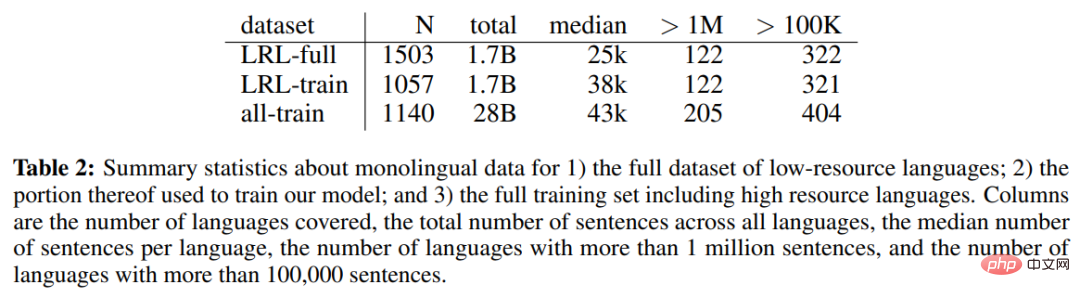
Le tableau 2 ci-dessous montre les données monolingues de l'ensemble de données complet des langues à faibles ressources (LRL), une partie des données monolingues utilisées pour entraîner le modèle et l'ensemble monolingue statistiques de données de l'ensemble complet de formation, y compris les langues à hautes ressources.
Le répertoire des chapitres est le suivant :
Créer des modèles de traduction automatique pour les langues à longue traîne
 Pour les données monolingues extraites du Web, le prochain défi est de former à partir d'un nombre limité de monolingues Créez des modèles de traduction automatique polyvalents et de haute qualité à partir de données. À cette fin, les chercheurs ont adopté une approche pragmatique consistant à exploiter toutes les données parallèles disponibles pour les langues à ressources plus élevées afin d'améliorer la qualité des langues à longue traîne où seules des données monolingues sont disponibles. Ils appellent cette configuration « zéro ressource » car il n'y a pas de surveillance directe des langues à longue traîne.
Pour les données monolingues extraites du Web, le prochain défi est de former à partir d'un nombre limité de monolingues Créez des modèles de traduction automatique polyvalents et de haute qualité à partir de données. À cette fin, les chercheurs ont adopté une approche pragmatique consistant à exploiter toutes les données parallèles disponibles pour les langues à ressources plus élevées afin d'améliorer la qualité des langues à longue traîne où seules des données monolingues sont disponibles. Ils appellent cette configuration « zéro ressource » car il n'y a pas de surveillance directe des langues à longue traîne.
Les chercheurs utilisent plusieurs technologies développées pour la traduction automatique au cours des dernières années afin d'améliorer la qualité de la traduction sans ressources des langues à longue traîne. Ces techniques comprennent l'apprentissage auto-supervisé à partir de données monolingues, l'apprentissage supervisé multilingue à grande échelle, la rétro-traduction et l'auto-formation à grande échelle, ainsi que des modèles à haute capacité. Ils ont exploité ces outils pour créer des modèles de traduction automatique capables de traduire plus de 1 000 langues, en exploitant des corpus parallèles existants couvrant environ 100 langues et un ensemble de données monolingues de 1 000 langues construit à partir du Web.
Plus précisément, les chercheurs ont d'abord souligné l'importance de la capacité du modèle dans les modèles hautement multilingues en comparant les performances de 1,5 milliard et 6 milliards de transformateurs de paramètres sur une traduction sans ressource (3.2), puis le nombre de langues auto-supervisées en augmentation à 1000 démontre que les performances s'améliorent pour la plupart des langues à longue traîne à mesure que davantage de données monolingues provenant de langues similaires deviennent disponibles (3.3). Bien que le modèle en 1 000 langues des chercheurs ait démontré des performances raisonnables, ils ont incorporé une augmentation des données à grande échelle pour comprendre les forces et les limites de leur approche.
De plus, les chercheurs ont affiné le modèle génératif sur un sous-ensemble de 30 langues contenant de grandes quantités de données synthétiques grâce à l'auto-formation et à la rétro-traduction (3.4). Ils décrivent en outre des méthodes pratiques de filtrage des données synthétiques afin d'améliorer la robustesse de ces modèles affinés face aux hallucinations et à la traduction incorrecte du langage (3.5).
Les chercheurs ont également utilisé la distillation au niveau de la séquence pour affiner ces modèles en architectures plus petites et plus faciles à raisonner et ont mis en évidence l'écart de performance entre les modèles d'enseignant et d'étudiant (3.6).
La table des matières du chapitre est la suivante :
Évaluation
 Pour évaluer leur modèle de traduction automatique, les chercheurs ont d'abord traduit des phrases anglaises dans ces langues et ont construit un modèle pour le 38 Langues à longue traîne sélectionnées. Un ensemble d’évaluation (4.1). Ils mettent en évidence les limites de BLEU dans les contextes longue traîne et évaluent ces langages à l'aide de CHRF (4.2).
Pour évaluer leur modèle de traduction automatique, les chercheurs ont d'abord traduit des phrases anglaises dans ces langues et ont construit un modèle pour le 38 Langues à longue traîne sélectionnées. Un ensemble d’évaluation (4.1). Ils mettent en évidence les limites de BLEU dans les contextes longue traîne et évaluent ces langages à l'aide de CHRF (4.2).
Les chercheurs ont également proposé une métrique approximative sans référence basée sur une traduction aller-retour pour comprendre la qualité du modèle sur les langues où l'ensemble de référence n'est pas disponible, et ont rapporté la qualité du modèle mesurée par cette métrique (. 4.3). Ils ont effectué une évaluation humaine du modèle sur un sous-ensemble de 28 langues et ont rapporté les résultats, confirmant qu'il est possible de construire des systèmes de traduction automatique utiles en suivant l'approche décrite dans l'article (4.4).
Afin de comprendre les faiblesses des modèles multilingues sans ressources à grande échelle, les chercheurs ont mené une analyse qualitative des erreurs sur plusieurs langues. Il a été constaté que le modèle confondait souvent des mots et des concepts dont la distribution était similaire, tels que « tigre » devenu « petit crocodile » (4.5). Et avec des paramètres de ressources inférieurs (4.6), la capacité du modèle à traduire les jetons diminue sur les jetons qui apparaissent moins fréquemment.
Les chercheurs ont également constaté que ces modèles ne peuvent souvent pas traduire avec précision une saisie courte ou d'un seul mot (4.7). La recherche sur des modèles raffinés montre que tous les modèles sont plus susceptibles d'amplifier les biais ou le bruit présents dans les données d'entraînement (4.8).
La table des matières du chapitre est la suivante :

Expériences et notes supplémentaires
Les chercheurs ont mené des expériences supplémentaires sur les modèles ci-dessus, montrant qu'ils fonctionnent généralement mieux lors de la traduction directe entre des langues similaires. , sans utiliser l'anglais comme pivot (5.1), et ils peuvent être utilisés pour une translittération zéro entre différents scripts (5.2).
Ils décrivent une astuce pratique pour ajouter une ponctuation terminale à n'importe quelle entrée, appelée "astuce du point", qui peut être utilisée pour améliorer la qualité de la traduction (5.3).
De plus, nous démontrons que ces modèles sont robustes à l'utilisation de glyphes Unicode non standard dans certaines langues, mais pas dans toutes (5.4), et explorons plusieurs polices non Unicode (5.5).
La table des matières du chapitre est la suivante :

Pour plus de détails sur la recherche, veuillez vous référer à l'article original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI