
Maison >Périphériques technologiques >IA >Si vous souhaitez apprendre l'intelligence artificielle, vous devez maîtriser cet ensemble de données Introduction et utilisation pratique du MNIST.
Si vous souhaitez apprendre l'intelligence artificielle, vous devez maîtriser cet ensemble de données Introduction et utilisation pratique du MNIST.

- 王林avant
- 2023-04-08 11:11:062150parcourir
L'apprentissage de l'intelligence artificielle nécessite inévitablement certains ensembles de données. Par exemple, l'intelligence artificielle pour identifier la pornographie nécessite des images similaires. L'intelligence artificielle pour la reconnaissance vocale et les corpus sont indispensables. Les étudiants qui débutent dans l’intelligence artificielle s’inquiètent souvent des ensembles de données. Aujourd'hui, nous allons présenter un ensemble de données très simple mais très utile, qui est le MNIST. Cet ensemble de données nous permet d’apprendre et de pratiquer des algorithmes liés à l’intelligence artificielle.
L'ensemble de données MNIST est un ensemble de données très simple produit par le National Institute of Standards and Technology (NIST). Alors, de quoi parle cet ensemble de données ? Il s'agit en fait de chiffres arabes manuscrits (dix chiffres de 0 à 9).
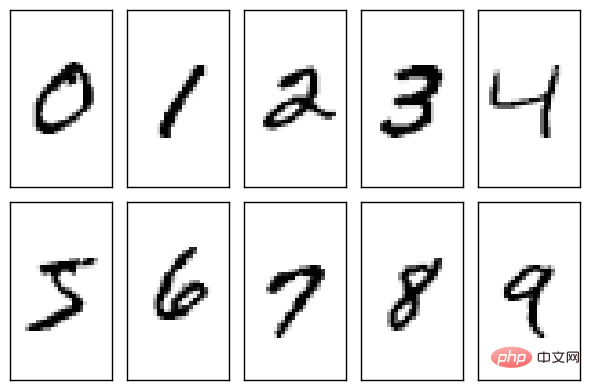
Le NIST est toujours très sérieux lors de la production de l'ensemble de données. L'ensemble de formation dans l'ensemble de données se compose de chiffres manuscrits provenant de 250 personnes différentes, dont 50 % sont des étudiants du secondaire et 50 % sont des membres du personnel du Bureau du recensement. L'ensemble de test contient également la même proportion de données numériques manuscrites.
Comment télécharger l'ensemble de données MNIST
L'ensemble de données MNIST peut être téléchargé à partir de son site officiel (http://yann.lecun.com/exdb/mnist/) Puisqu'il s'agit d'un site Web étranger, le téléchargement peut être effectué. lent. Il contient quatre parties :
- Images de l'ensemble de formation : train-images-idx3-ubyte.gz (9,9 Mo, 47 Mo après décompression, contient 60 000 échantillons)
- Étiquettes de l'ensemble de formation : train-labels-idx1-ubyte . gz (29 Ko, 60 Ko après décompression, contient 60 000 balises)
- Image de l'ensemble de test : t10k-images-idx3-ubyte.gz (1,6 Mo, 7,8 Mo après décompression, contient 10 000 échantillons)
- Balises de l'ensemble de test :t10k- labels-idx1-ubyte.gz (5 Ko, 10 Ko après décompression, contient 10 000 étiquettes)
Ce qui précède contient deux types de contenu, l'un est constitué d'images, l'autre est constitué d'étiquettes, les images et les étiquettes correspondent une à une. Mais l’image ici n’est pas le fichier image que nous voyons habituellement, mais un fichier binaire. Cet ensemble de données stocke 60 000 images au format binaire. L'étiquette est le numéro réel correspondant à l'image.
Comme le montre la figure ci-dessous, cet article télécharge l'ensemble de données localement et décompresse le résultat. Pour faciliter la comparaison, le package compressé d'origine et les fichiers décompressés sont inclus.
Une brève analyse du format de l'ensemble de données
Tout le monde a découvert qu'après décompression, le package compressé n'est pas une image, mais chaque package compressé correspond à un problème indépendant. Dans ce fichier, des informations sur des dizaines de milliers d'images ou de tags sont stockées. Alors, comment ces informations sont-elles stockées dans ce fichier ?
En fait, le site officiel du MNIST donne une description détaillée. En prenant le fichier image de l'ensemble de formation comme exemple, la description du format de fichier donnée par le site officiel est la suivante :
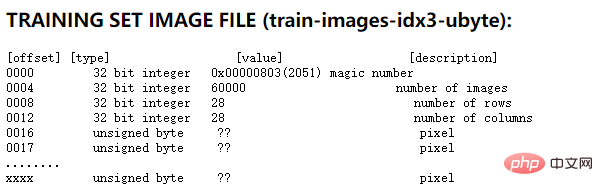
Comme le montre l'image ci-dessus, les quatre premiers nombres à 32 chiffres sont les informations de description. de l’ensemble de formation. Le premier est le nombre magique, qui est une valeur fixe de 0x0803 ; le deuxième est le nombre d'images, 0xea60, qui est 60 000 ; les troisième et quatrième sont la taille de l'image, c'est-à-dire que l'image est de 28* ; 28 pixels. Ce qui suit décrit chaque pixel dans un octet. Puisqu'un octet est utilisé pour décrire un pixel dans ce fichier, vous pouvez savoir que la valeur d'un pixel peut être comprise entre 0 et 255. Où 0 signifie blanc et 255 signifie noir.

Le format des fichiers d'étiquettes est similaire à celui des fichiers image. Il y a deux nombres à 32 chiffres devant, dont le premier est le nombre magique, valeur fixe 0x0801 ; le second est utilisé pour décrire le nombre de balises. Les données suivantes sont la valeur de chaque balise, représentée par un octet. La plage de valeurs représentée ici est

Les données correspondant au fichier d'étiquettes de l'ensemble d'entraînement réel sont les suivantes. On voit qu'il est cohérent avec la description du format ci-dessus. De plus, nous pouvons voir que correspondant à cet ensemble d'étiquettes, les nombres représentés par les images précédentes doivent être respectivement 5, 0, 4, 1, etc. N'oubliez pas cela ici, il sera utilisé plus tard.

Nous connaissons le format de fichier de l'ensemble de données, faisons-le en pratique.
Traitement visuel des ensembles de données
Après avoir connu le format de stockage des données ci-dessus, nous pouvons analyser les données. Par exemple, l'article suivant implémente un petit programme pour analyser une image dans la collection d'images et obtenir des résultats visuels. Bien sûr, nous pouvons réellement savoir quelle est l'image en fonction de la valeur de l'ensemble d'étiquettes. Ce n'est qu'une expérience. Le résultat final est stocké dans un fichier texte, en utilisant le caractère « Y » pour représenter l'écriture manuscrite et le caractère « 0 » pour représenter la couleur de fond. Le code spécifique du programme est très simple et ne sera pas décrit en détail dans cet article.
# -*- coding: UTF-8 -*-
def trans_to_txt(train_file, txt_file, index):
with open(train_file, 'rb') as sf:
with open(txt_file, "w") as wf:
offset = 16 + (28*28*index)
cur_pos = offset
count = 28*28
strlen = 1
out_count = 1
while cur_pos < offset+count:
sf.seek(cur_pos)
data = sf.read(strlen)
res = int(data[0])
#虽然在数据集中像素是1-255表示颜色,这里简化为Y
if res > 0 :
wf.write(" Y ")
else:
wf.write(" 0 ")
#由于图片是28列,因此在此进行换行
if out_count % 28 == 0 :
wf.write("n")
cur_pos += strlen
out_count += 1
trans_to_txt("../data/train-images.idx3-ubyte", "image.txt", 0)Lorsque nous exécutons le code ci-dessus, nous pouvons obtenir un fichier nommé image.txt. Vous pouvez voir le contenu du fichier comme suit. Les notes rouges ont été ajoutées plus tard, principalement pour une meilleure visibilité. Comme vous pouvez le voir sur la photo, il s’agit en fait d’un « 5 » manuscrit.

Auparavant, nous analysions visuellement l'ensemble de données via l'interface Python native. Python possède de nombreuses fonctions de bibliothèque déjà implémentées, nous pouvons donc simplifier les fonctions ci-dessus grâce à une fonction de bibliothèque.
Analyse des données basées sur des bibliothèques tierces
C'est un peu compliqué à implémenter en utilisant l'interface Python native. Nous savons que Python possède de nombreuses bibliothèques tierces, nous pouvons donc utiliser des bibliothèques tierces pour analyser et afficher l'ensemble de données. Le code spécifique est le suivant.
# -*- coding: utf-8 -*-
import os
import struct
import numpy as np
# 读取数据集,以二维数组的方式返回图片信息和标签信息
def load_mnist(path, kind='train'):
# 从指定目录加载数据集
labels_path = os.path.join(path,
'%s-labels.idx1-ubyte'
% kind)
images_path = os.path.join(path,
'%s-images.idx3-ubyte'
% kind)
with open(labels_path, 'rb') as lbpath:
magic, n = struct.unpack('>II',
lbpath.read(8))
labels = np.fromfile(lbpath,
dtype=np.uint8)
with open(images_path, 'rb') as imgpath:
#解析图片信息,存储在images中
magic, num, rows, cols = struct.unpack('>IIII',
imgpath.read(16))
images = np.fromfile(imgpath,
dtype=np.uint8).reshape(len(labels), 784)
return images, labels
# 在终端打印某个图片的数据信息
def print_image(data, index):
idx = 0;
count = 0;
for item in data[index]:
if count % 28 == 0:
print("")
if item > 0:
print("33[7;31mY 33[0m", end="")
else:
print("0 ", end="")
count += 1
def main():
cur_path = os.getcwd()
cur_path = os.path.join(cur_path, "..data")
imgs, labels = load_mnist(cur_path)
print_image(imgs, 0)
if __name__ == "__main__":
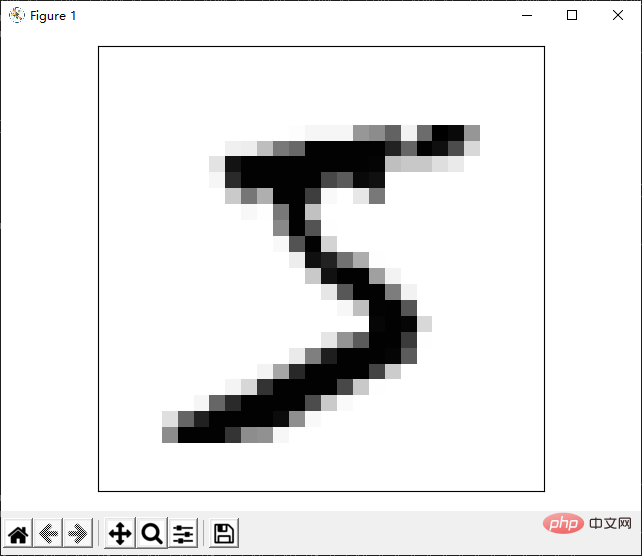
main()Le code ci-dessus est divisé en deux étapes. La première étape consiste à analyser l'ensemble de données dans un tableau et la deuxième étape consiste à afficher une certaine image dans le tableau. L'affichage ici se fait également via un programme texte, mais il n'est pas stocké dans un fichier, mais imprimé sur le terminal. Par exemple, si nous imprimons toujours la première image, l'effet est le suivant :

La présentation des résultats ci-dessus ne simule l'image qu'à travers des caractères. En fait, nous pouvons utiliser des bibliothèques tierces pour obtenir une présentation d’image plus parfaite. Ensuite, nous expliquons comment présenter des images via la bibliothèque matplotlib. Cette bibliothèque est très utile et j'entrerai en contact avec cette bibliothèque plus tard.
Nous implémentons un
def show_image(data, index): fig, ax = plt.subplots(nrows=1, ncols=1, sharex=True, sharey=True, ) img = data[0].reshape(28, 28) ax.imshow(img, cmap='Greys', interpolation='nearest') ax.set_xticks([]) ax.set_yticks([]) plt.tight_layout() plt.show()
Vous pouvez voir à ce stade que
peut manquer de certaines bibliothèques tierces, telles que matplotlib, etc. lors de l'implémentation des fonctions ci-dessus. Pour le moment, nous devons l'installer manuellement. La méthode spécifique est la suivante :
pip install matplotlib -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
L'analyse des données basée sur TensorFlow
MNIST est si célèbre que TensorFlow la prend déjà en charge. Par conséquent, nous pouvons le charger et l'analyser via TensorFlow. Ci-dessous nous donnons le code implémenté avec TensorFlow.
# -*- coding: utf-8 -*-
from tensorflow.examples.tutorials.mnist import input_data
import pylab
def show_mnist():
# 通过TensorFlow库解析数据
mnist = input_data.read_data_sets("../data", one_hot=True)
im = mnist.train.images[0]
im = im.reshape(28 ,28)
# 进行绘图
pylab.imshow(im, cmap='Greys', interpolation='nearest')
pylab.show()
if __name__ == "__main__":
show_mnist()L'effet final obtenu par ce code est cohérent avec l'exemple précédent, je n'entrerai donc pas dans les détails ici.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI