
Maison >Périphériques technologiques >IA >Prendre des décisions efficaces et exploitables pour optimiser les KPI de l'entreprise en utilisant l'apprentissage automatique causal
Prendre des décisions efficaces et exploitables pour optimiser les KPI de l'entreprise en utilisant l'apprentissage automatique causal

- 王林avant
- 2023-04-04 11:40:06900parcourir
L'analyse causale dans la plateforme d'apprentissage automatique Azure Machine Learning Studio peut répondre aux questions causales grâce à un cadre d'automatisation de bout en bout.
Traducteur | Li Rui
Réviseur | Sun Shujuan
Dans différents scénarios, les techniques de modélisation d'apprentissage automatique couramment utilisées peuvent mal comprendre les véritables relations entre les données. Ici, nous cherchons à changer ce paradigme pour trouver des informations exploitables au-delà des fausses corrélations basées sur l'estimation des relations causales et la mesure des effets du traitement sur les résultats des indicateurs clés de performance (KPI) cibles.

La motivation de l'apprentissage automatique causal
Supposons que nous obtenions les données historiques ou les données d'observation d'un certain produit d'une certaine entreprise au cours de l'année écoulée. Face à la perte de 5 % de clients pour ce produit, alors l'objectif de cette entreprise est de réduire le taux de désabonnement grâce à des campagnes ciblées. Généralement, un modèle classique de propension à prédire le désabonnement (score de propension - probabilité de désabonnement covariable du comportement du client) est construit et prescrit des remises ou des ventes incitatives/ventes croisées aux clients en sélectionnant des seuils.
Maintenant, les chefs d'entreprise veulent prédire l'efficacité de l'attrition des clients, par exemple si les clients de l'entreprise sont retenus grâce à des promotions ou des activités de marketing, ou l'inverse ? Cela nécessite des expériences standards de tests AB traditionnels, et les expériences nécessitent un certain temps, et dans certains cas également irréalisable et coûteux.
Nous devons donc réfléchir à des questions au-delà du modèle de propension. La prédiction du taux de désabonnement avec supervision est utile, mais pas à chaque fois, car elle manque de recommandations pour recommander la meilleure action suivante dans des situations hypothétiques. Le problème du ciblage des clients personnalisés qui sont capables de répondre positivement à la proposition marketing d'une entreprise sans gaspiller d'argent dans des cas d'échec, prenant ainsi la meilleure action/intervention suivante et modifiant les résultats futurs (par exemple en maximisant la rétention) est la modélisation de l'inférence causale Lift dans .
Pour comprendre certaines questions contrefactuelles dans le monde de la consommation, telles que : comment le comportement des consommateurs changerait-il si les prix de détail étaient augmentés ou abaissés (quel est l'impact du prix sur les modèles de comportement) ? Si une entreprise diffuse des publicités auprès des clients, achèteront-ils le produit (impact de la publicité sur l'achat) ? Cela inclut une prise de décision basée sur les données grâce à la modélisation causale.
En général, les questions de prédiction ou de prévision se concentrent sur le nombre de personnes qui s'abonneront au cours du mois prochain, tandis que les questions causales portent sur ce qui se passera si certaines politiques changent (par exemple, combien de personnes s'abonneront si une campagne est lancée) .
L’analyse causale ira encore plus loin. Il est conçu pour déduire divers aspects du processus de génération de données. À l’aide de ces aspects, on peut déduire non seulement la probabilité d’événements dans des conditions statiques, mais également la dynamique des événements dans des conditions changeantes. Cette capacité comprend la prévision des effets des actions (par exemple, un traitement ou des décisions politiques), la détermination des causes des événements signalés et l'évaluation de la responsabilité et de l'attribution (par exemple, si l'événement x était nécessaire ou suffisant pour que l'événement y se produise).
Lorsque l'on utilise l'apprentissage automatique supervisé pour prédire des modèles à l'aide de modèles de pseudo-corrélation, il existe une hypothèse implicite selon laquelle les choses continueront comme elles ont été dans le passé. Dans le même temps, l’environnement est activement modifié d’une manière qui brise souvent ces schémas, à la suite de décisions ou d’actions prises sur la base de résultats prévus.
De la prédiction à la prise de décision
Pour la prise de décision, vous devez trouver les caractéristiques qui mènent au résultat et estimer comment le résultat changera si les caractéristiques changent. De nombreux problèmes liés à la science des données sont des problèmes causals, et l’estimation de scénarios contrefactuels est courante dans les scénarios de prise de décision.
- Expérience A/B : Si vous changez la couleur des boutons de votre site Web, cela entraînera-t-il un engagement plus élevé ?
- Décision politique : si ce traitement/politique est adopté, comment cela entraînera-t-il un changement dans les résultats ? Cela entraînera-t-il des patients en meilleure santé/plus de revenus
- Évaluation de la politique : changements apportés par l'entreprise dans le passé Ou quoi ? est connu jusqu'à présent, et la manière dont les résultats ont changé, les politiques en place ont-elles aidé ou entravé les produits qu'ils essayaient de modifier ?
- Attribution du crédit : les gens ont-ils acheté l'article parce qu'ils ont vu l'annonce ? ?
Que sont les relations causales et les effets causals ?
Si une action ou un traitement (T) provoque un résultat (Y), si et seulement si l'action (T) provoque un changement dans le résultat (Y), garder tout le reste constant. La causalité signifie qu’en modifiant un facteur, un autre facteur peut être modifié.
Par exemple : Si l’aspirine peut soulager un mal de tête, elle ne fera que modifier l’état du mal de tête.
Si le marketing peut entraîner une augmentation des ventes, si et seulement si les activités marketing peuvent entraîner un changement dans les ventes, alors tout le reste peut rester pareil.
L'effet causal est l'ampleur du changement de Y avec un changement unitaire de T, et non l'inverse :
Effet causal = E [Y | do(T=1)] - E [Y | do (T = 0)] (Do-Calculus de Judea Pearl)
L'inférence causale nécessite des connaissances, des hypothèses et une expertise dans le domaine. L'équipe de recherche ALICE de Microsoft a développé les bibliothèques open source Do Why et EconML pour faciliter le travail et la vie des utilisateurs. La première étape de toute analyse causale consiste à poser une question claire :
- Quel traitement/action vous intéresse
- Quels résultats souhaitez-vous prendre en compte
- Quels facteurs de confusion pourraient être liés au résultat ? et traitement ?
Pipeline d'analyse causale : inférence causale de bout en bout (DECI) basée sur l'apprentissage profond (brevet Microsoft).
Découverte causale-identification causale-estimation causale-vérification causale.
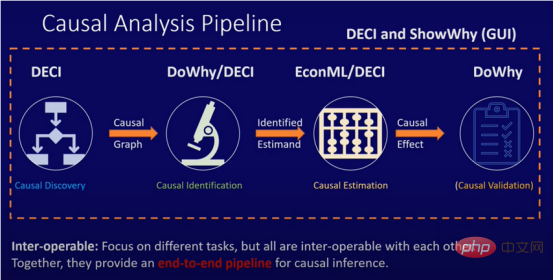
Tableau de bord IA responsable (Azure Machine Learning Studio) : analyse des causes
Cette fonctionnalité est basée sur l'interprétation du modèle ajusté dans le registre de modèles, qui peut être obtenue s'il existe une compréhension causale de celui-ci. variables Explorez ce qui pourrait arriver. Les effets causals de différentes caractéristiques peuvent être observés et comparés aux effets idiosyncratiques, et différents groupes peuvent être observés et quelles caractéristiques ou politiques fonctionnent le mieux pour eux.
- DECI : Fournit un cadre pour l'inférence causale de bout en bout, qui peut également être utilisé seul pour la découverte ou l'estimation.
- EconML : fournit plusieurs méthodes d'estimation de causalité.
- DoWhy : fournit plusieurs méthodes d'identification et de vérification.
- ShowPourquoi : fournit une analyse causale de bout en bout sans code pour la prise de décision causale dans une interface utilisateur graphique (GUI) conviviale.
Résumé
Les algorithmes modernes d'apprentissage automatique et d'apprentissage profond peuvent trouver des modèles complexes dans les données qui interprètent les algorithmes de la boîte noire, et leurs interprétations peuvent signifier ce que l'algorithme d'apprentissage automatique a appris du monde.
Lorsque ces algorithmes d’apprentissage automatique sont appliqués à la société pour prendre des décisions politiques telles que l’approbation de prêts et les polices d’assurance maladie, le monde qu’elle apprend ne reflète pas nécessairement bien ce qui se passe dans le monde.
Cependant, les modèles prédictifs basés sur les données sont transparents mais ne peuvent pas véritablement expliquer. L'interprétabilité nécessite un modèle causal (comme en témoigne l'erreur du tableau 2). Les modèles causals représentent de manière fiable certains processus dans le monde. L’IA explicable devrait être capable de raisonner pour prendre des décisions efficaces et impartiales.
Titre original : Analyse causale dans Azure Machine Learning Studio pour répondre à vos questions causales via un cadre automatisé de bout en bout, auteur : Hari Hara
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI