
Maison >Opération et maintenance >exploitation et maintenance Linux >Où est le journal des crash Linux ?
Où est le journal des crash Linux ?

- 藏色散人original
- 2023-03-10 10:41:127974parcourir
Le journal des temps d'arrêt de Linux se trouve dans "/var/log/" ; le journal de "/var/log/" sous Linux comprend le message, le journal des erreurs du noyau, etc. ; l'enregistrement sa enregistre le fonctionnement du processeur, de la mémoire, etc. Fichier de performances ; utilisez le fichier sa pour afficher les conditions du processeur et de la mémoire pendant le crash.

L'environnement d'exploitation de ce tutoriel : système linux5.9.8, ordinateur Dell G3.
Où sont les journaux d'arrêt de Linux ?
Idées de dépannage en cas d'indisponibilité de l'hôte Linux
Analyse des causes
Classification des serveurs, serveur Web, serveur de base de données, serveur de fichiers, middleware, autres serveurs.
Analyse du serveur Web : applications Web courantes Apache, nginx, IIS, etc.
Il existe de nombreuses raisons de temps d'arrêt, telles que le processeur, la mémoire, le disque IO, le BUG de l'application, le BUG du noyau, le matériel, etc.
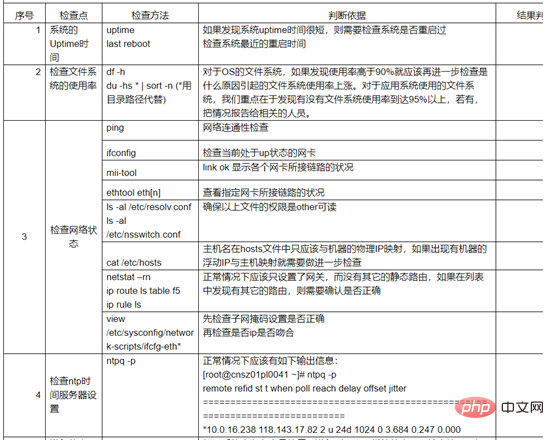
Version du système et du noyau
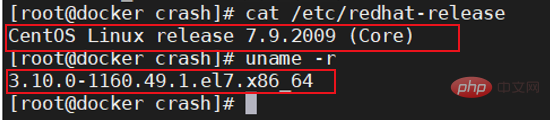
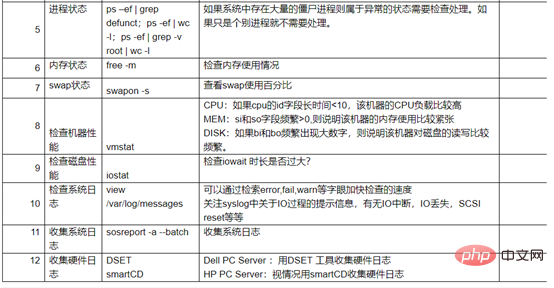
Processus
1. enregistrements de temps, historiques de connexions et de redémarrages Heure
dernier redémarrage

last -F | grep crash

Vérifiez l'historique de connexion pour tout utilisateur anormal
last

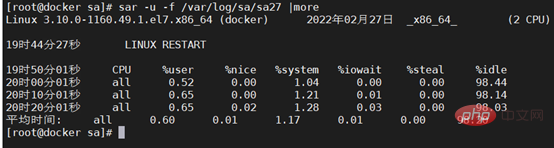
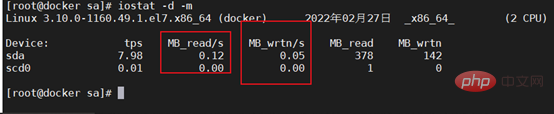
2. Vérifiez d'abord le système enregistrer. Par exemple, le journal sous /var/log/ sous Linux inclut les messages, le journal des erreurs du noyau demsg, etc. L'enregistrement sa est un fichier de performances qui enregistre le fonctionnement du processeur, de la mémoire, etc., et enregistre l'état d'exécution du CPU pendant le fonctionnement comme indiqué sur la figure Show.
Utilisez le fichier sa pour vérifier l'état du processeur pendant l'arrêt
Utilisez le fichier sa pour vérifier l'état de la mémoire pendant l'arrêt
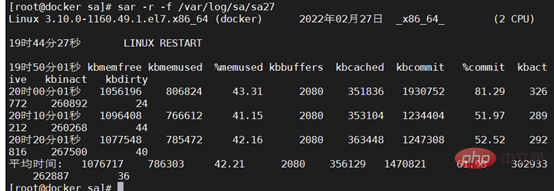
Le volume du journal est souvent important
Vous pouvez également effectuer des requêtes floues , tels que
Afficher les rapports d'erreur
tail -200 /var/log/messages |grep "Error" cat /var/log/dmesg |grep "Error"
Vérifiez le journal des crash du noyau
tail -200 /car/log/messages |grep "crash"
Vérifiez si le MOO se produit, généralement kill tue le processus
cat /var/log/messages |grep -i "kill"
Vous pouvez également consulter les journaux de la période d'arrêt, vérifier les journaux de 15h00 le 11 décembre
cat /vat/log/messages |grep "Feb 11 15*"
3. Afficher l'utilisation de la mémoire
free -m, vérifiez l'utilisation du swap, de la mémoire restante et du cache. Si le swap est utilisé et que la disponibilité n'est pas suffisante, vous devez également vérifier le paramètre cat /proc/sys/vm/swappiness. S'il est défini sur 0, cela signifie qu'il n'y a pas assez de mémoire.

4. Afficher l'utilisation de l'IO et du système de fichiers
Observez l'inactivité et l'iowait. Le cache est utilisé lors de la lecture et de l'écriture sur le disque, qui représente généralement 40 % de la mémoire système. Cependant, il y a un temps de tampon de 120 secondes au milieu. Lorsque le cache est sur le point d'être utilisé, il attendra. 120 secondes avant d'écrire sur le disque Lorsque la lecture et l'écriture sont fréquentes, il est parfois facile de provoquer un blocage.
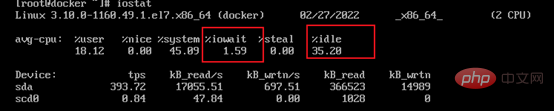
Vérifiez la vitesse de lecture et d'écriture des IO Si elle est très lente, cela signifie qu'il y a un goulot d'étranglement dans les performances du disque.
Utilisation du système de fichiers
5. Vérifiez le journal de sécurité
Le journal de sécurité est /var/log/secure, vérifiez l'historique pour voir si quelqu'un s'est connecté à l'hôte et a entrepris des actions malveillantes, comme la fermeture.
6. Utilisez les outils kdump et crash pour analyser le noyau
Vérifiez que le service kdump est activé sur le serveur et recherchez le fichier vmcore généré ce jour-là dans le répertoire /var/crash. Utilisez l'outil crash pour analyser le fichier vmcore.
Kdump est utilisé pour vider les images mémoire. Il peut non seulement vider l'image mémoire sur le disque dur local, mais également vers des appareils sur différentes machines via NFS, SSH et d'autres protocoles.
Kdump est divisé en deux composants : Kexec et Kdump.
Kexec est un outil de démarrage rapide pour le noyau qui permet de démarrer un nouveau noyau dans le contexte d'un noyau en cours d'exécution (noyau de production) sans passer par une détection fastidieuse du BIOS, ce qui permet aux développeurs de noyau de déboguer plus facilement le noyau.
Kdump est un outil de vidage de mémoire efficace. Après avoir activé Kdump, le noyau de production réservera une partie de l'espace mémoire pour démarrer rapidement sur un nouveau noyau via Kexec lorsque le noyau plante. Ce processus ne nécessite donc pas de redémarrer le système. peut vider une image mémoire du noyau de production en panne.
7. Vérifiez les journaux de service et le logiciel de surveillance
Si vous pouvez trouver l'occupation du processus pendant le temps d'arrêt, vous pouvez vérifier ses journaux en fonction des services avec une occupation anormale.
Les journaux de service incluent généralement les bases de données et les services Web, les middlewares, les frameworks, etc.
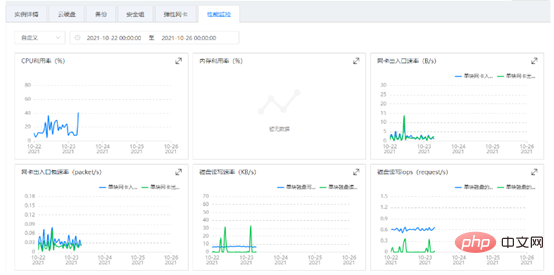
Vous pouvez également visualiser les images d'enregistrement historique du logiciel de surveillance et trouver l'analyse d'images des points de pointe et des points d'arrêt comme indiqué ci-dessous.
8. Résumé
Il existe de nombreuses raisons pour les temps d'arrêt du système, nous devons les analyser soigneusement en fonction du processus,
Recommandations associées : "Tutoriel vidéo Linux"
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!