
Maison >base de données >tutoriel mysql >Une compréhension approfondie de la synchronisation maître-esclave MySql dans un seul article
Une compréhension approfondie de la synchronisation maître-esclave MySql dans un seul article

- 藏色散人avant
- 2023-03-01 16:59:592189parcourir
Cet article vous apporte des connaissances pertinentes sur MySql. Il présente principalement la synchronisation maître-esclave de MySQL et son principe de fonctionnement, etc. Les amis intéressés peuvent y jeter un œil ensemble. Bienvenue pour collectionner et apprendre !
1 Introduction
Bonjour à tous, Mysql est la base de données la plus couramment utilisée par tout le monde. Ce qui suit est un partage de points de connaissances sur la synchronisation maître-esclave mysql afin de consolider les connaissances de base de mysql s'il y en a. erreurs, s'il vous plaît laissez-moi savoir Correction.
2 Présentation de la synchronisation maître-esclave MySql
La synchronisation maître-esclave MySQL, à savoir la réplication MySQL, peut synchroniser les données d'un serveur de base de données vers plusieurs serveurs de base de données. La base de données MySQL est livrée avec une fonction de synchronisation maître-esclave. Après configuration, elle peut réaliser une synchronisation maître-esclave selon divers schémas basés sur les structures de base de données et de tables.
Redis est une base de données en mémoire hautes performances, mais elle n'est pas le protagoniste aujourd'hui ; MySQL est une base de données relationnelle basée sur des fichiers disque. Par rapport à Redis, la vitesse de lecture sera plus lente, mais elle est puissante et peut être utilisée. pour le stockage Données persistantes. Dans le travail réel, nous utilisons souvent Redis comme cache en conjonction avec MySQL. Lorsqu'il y a une demande d'accès aux données, elle sera d'abord recherchée dans le cache. Si elle existe, elle sera directement supprimée. la base de données sera à nouveau consultée. Cela améliore les performances. L'efficacité de la lecture réduit également la pression d'accès sur la base de données back-end. L'utilisation d'une architecture de cache comme Redis est une partie très importante d'une architecture à haute concurrence.
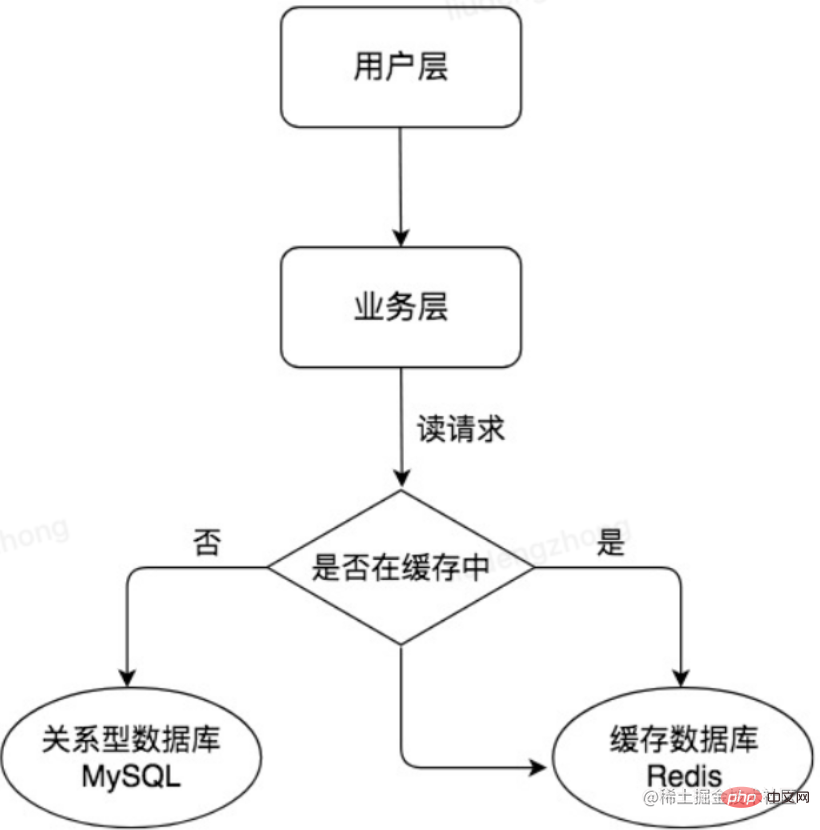
Avec la croissance continue du volume d'affaires, la pression sur la base de données continuera d'augmenter. Les changements fréquents dans le cache dépendent également fortement des résultats des requêtes de données, ce qui entraîne une faible efficacité des requêtes de données, une charge élevée. trop de connexions et autres problèmes. Pour les scénarios de commerce électronique, il existe souvent de nombreux scénarios typiques avec plus de lecture et moins d'écriture. Nous pouvons utiliser une architecture maître-esclave pour MySQL et séparer la lecture et l'écriture, de sorte que le serveur maître (Master) gère les demandes d'écriture et le serveur esclave. (Esclave) gère les demandes de lecture. Cela peut encore améliorer les capacités de traitement simultané de la base de données. Comme le montre l'image ci-dessous :
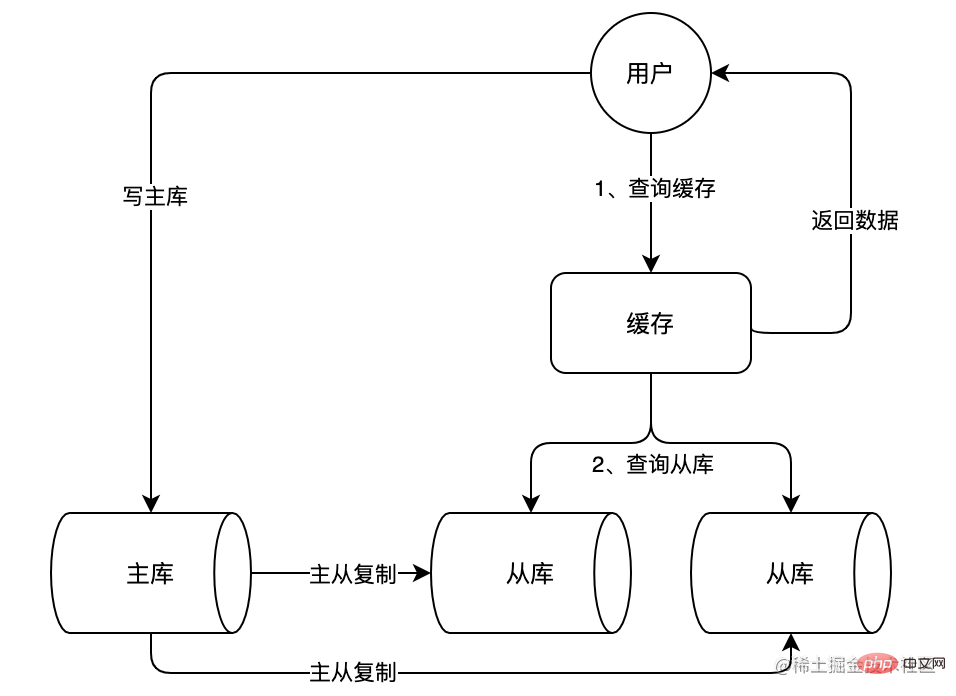
Dans l'image ci-dessus, vous pouvez voir que nous avons ajouté deux bibliothèques esclaves. Ces deux bibliothèques esclaves peuvent ensemble résister à un grand nombre de requêtes de lecture et partager la pression sur la bibliothèque principale. La base de données esclave synchronisera en permanence les données de la base de données maître via la réplication maître-esclave pour garantir que les données de la base de données esclave sont cohérentes avec les données de la base de données maître.
Ensuite, examinons les fonctions de synchronisation maître-esclave et comment la synchronisation maître-esclave est mise en œuvre.
3 Le rôle de la synchronisation maître-esclave
De manière générale, tous les systèmes n'ont pas besoin de concevoir une architecture maître-esclave pour la base de données, car l'architecture elle-même a un certain coût si notre objectif est d'améliorer les accès simultanés élevés. pour l'efficacité de la base de données, nous devons d'abord optimiser les instructions et les index SQL pour exploiter pleinement les performances maximales de la base de données, et deuxièmement, adopter des stratégies de mise en cache, telles que l'utilisation d'outils de mise en cache tels que Redis et MongoDB pour enregistrer les données dans des bases de données en mémoire ; grâce à leurs avantages de haute performance. Pour améliorer l'efficacité de la lecture, la dernière étape consiste à adopter une architecture maître-esclave pour la base de données et à séparer la lecture et l'écriture. Le coût d'utilisation et de maintenance du système augmente progressivement en fonction de l'évolution de l'architecture.
Pour en revenir au sujet, la synchronisation maître-esclave peut non seulement améliorer le débit de la base de données, mais présente également les trois aspects suivants :
3.1 Séparation en lecture et en écriture
Nous pouvons synchroniser les données via la réplication maître-esclave , puis lire et écrire. La séparation améliore les capacités de traitement simultané de la base de données. Pour faire simple, nos données sont placées dans plusieurs bases de données, dont l'une est la base de données principale et les autres sont des bases de données esclaves. Lorsque les données de la base de données principale changent, les données seront automatiquement synchronisées avec la base de données esclave et notre programme peut lire les données de la base de données esclave, c'est-à-dire en utilisant une méthode de séparation en lecture-écriture. Les applications de commerce électronique consistent souvent à « lire plus et écrire moins », et la séparation de la lecture et de l'écriture peut permettre d'obtenir un accès simultané plus élevé. À l'origine, toutes les pressions de lecture et d'écriture étaient supportées par un seul serveur. Désormais, plusieurs serveurs gèrent conjointement les demandes de lecture, réduisant ainsi la pression sur la base de données principale. De plus, l'équilibrage de charge peut être effectué sur les serveurs esclaves, de sorte que différentes demandes de lecture puissent être réparties uniformément sur différents serveurs esclaves selon les politiques, rendant la lecture plus fluide. Une autre raison pour une lecture fluide est de réduire l'impact des tables de verrouillage. Par exemple, si nous laissons la bibliothèque principale se charger de l'écriture, lorsqu'un verrou en écriture se produit dans la bibliothèque principale, cela n'affectera pas l'opération de requête de la bibliothèque esclave.
3.2 Sauvegarde des données
La synchronisation maître-esclave est également équivalente à un mécanisme de sauvegarde à chaud des données, qui est sauvegardée dans le cadre du fonctionnement normal de la base de données principale sans affecter la fourniture des services de données.
3.3 Haute disponibilité
La sauvegarde des données est en fait un mécanisme redondant. Grâce à cette méthode de redondance, la haute disponibilité de la base de données peut être échangée lorsque le serveur tombe en panne ou est indisponible, il peut être rapidement effectué un basculement et laisser l'esclave. La base de données fait office de base de données principale pour assurer le fonctionnement normal du service. Vous pouvez en apprendre davantage sur les indicateurs SLA de haute disponibilité de la base de données du système de commerce électronique.
4 Principe de synchronisation maître-esclave
En parlant du principe de la synchronisation maître-esclave, nous devons comprendre un fichier journal important dans la base de données, qui est le fichier binaire Binlog, qui enregistre les événements qui mettent à jour la base de données. En fait, le principe de la synchronisation maître-esclave est basé. sur la synchronisation des données basée sur Binlog de.
Dans le processus de réplication maître-esclave, les opérations seront basées sur trois threads. L'un est le thread de vidage du journal binaire, situé sur le nœud maître, les deux autres threads sont le thread d'E/S et le thread SQL, tous deux. sont situés sur le nœud esclave, comme indiqué ci-dessous :
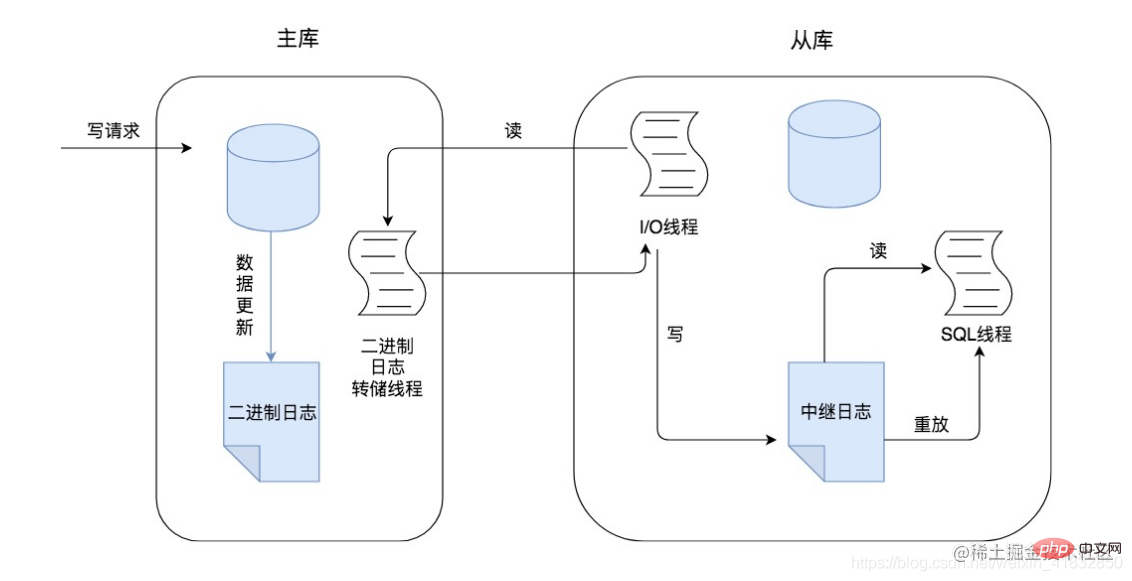
Combinés avec les images ci-dessus, comprenons le processus principal de la réplication maître-esclave :
Lorsque le nœud maître reçoit une demande d'écriture, la demande d'écriture. Il peut s'agir d'une opération d'ajout, de suppression ou de modification. À ce stade, il enregistrera toutes les opérations de mise à jour des demandes d'écriture dans le journal binlog.
Le nœud maître copiera les données sur le nœud esclave, comme le nœud esclave01 et le nœud esclave02 dans l'image. Dans ce processus, chaque nœud esclave doit d'abord être connecté au nœud maître lorsque le nœud esclave est connecté. au nœud maître, le nœud maître créera un thread de vidage binlog pour chaque nœud esclave afin d'envoyer les journaux binlog à chaque nœud esclave.
Le thread de vidage binlog lira le journal binlog sur le nœud maître, puis enverra le journal binlog au thread d'E/S sur le nœud esclave. Lorsque la bibliothèque principale lit les événements, elle verrouille le Binglog une fois la lecture terminée, le verrou est libéré.
Après avoir reçu le journal binlog, le thread d'E/S sur le nœud esclave écrira d'abord le journal binlog dans le relaylog local, et le journal binlog sera enregistré dans le relaylog.
Le thread SQL sur le nœud esclave lira le journal binlog dans le relaylog, l'analysera en opérations d'ajout, de suppression et de modification spécifiques, et refairea ces opérations effectuées sur le nœud maître sur le nœud esclave une fois, l'effet de. la restauration des données est obtenue, de telle sorte que la cohérence des données du nœud maître et du nœud esclave peut être garantie.
Le contenu des données de la synchronisation maître-esclave est en fait un journal binaire (Binlog). Bien qu'il soit appelé journal binaire, il stocke en réalité les événements les uns après les autres. Ces événements correspondent aux opérations de mise à jour de la base de données, telles que. INSÉRER, METTRE À JOUR, SUPPRIMER, etc.
De plus, nous devons également noter que toutes les versions de MySQL n'activent pas le journal binaire du serveur par défaut. Lors de la synchronisation maître-esclave, nous devons d'abord vérifier si le serveur a activé le journal binaire.
Le journal binaire est un fichier. Il y aura un certain retard lors de la transmission réseau, par exemple 200 ms. Cela peut faire en sorte que les données lues par l'utilisateur à partir de la bibliothèque esclave ne soient pas les dernières données, ce qui entraînera également une défaillance du maître. L'incohérence des données se produit lors de la synchronisation. Par exemple, si nous mettons à jour un enregistrement, cette opération est terminée sur la base de données principale, et dans un court laps de temps, par exemple 100 ms, le même enregistrement est relu. À ce moment, la base de données esclave n'a pas terminé la synchronisation des données. alors, les données que nous lisons dans la bibliothèque sont des données anciennes. Que faire dans cette situation ?
5 Comment résoudre le problème de cohérence des données de la synchronisation maître-esclave
Comme vous pouvez l'imaginer, si les données que nous voulons exploiter sont toutes stockées dans la même base de données, alors lors de la mise à jour des données, nous pouvons ajouter un verrouillage des enregistrements , afin qu'aucune incohérence des données ne se produise lors de la lecture. Mais à l'heure actuelle, le rôle de la bibliothèque esclave est de sauvegarder les données, sans séparation de la lecture et de l'écriture, afin de partager la pression de la bibliothèque principale.
Nous devons donc encore trouver un moyen de résoudre le problème de l'incohérence des données dans la synchronisation maître-esclave lors de la séparation de la lecture et de l'écriture, c'est-à-dire de résoudre le problème de la réplication des données entre le maître et l'esclave. faible à fort Pour diviser, il existe les trois méthodes de copie suivantes.
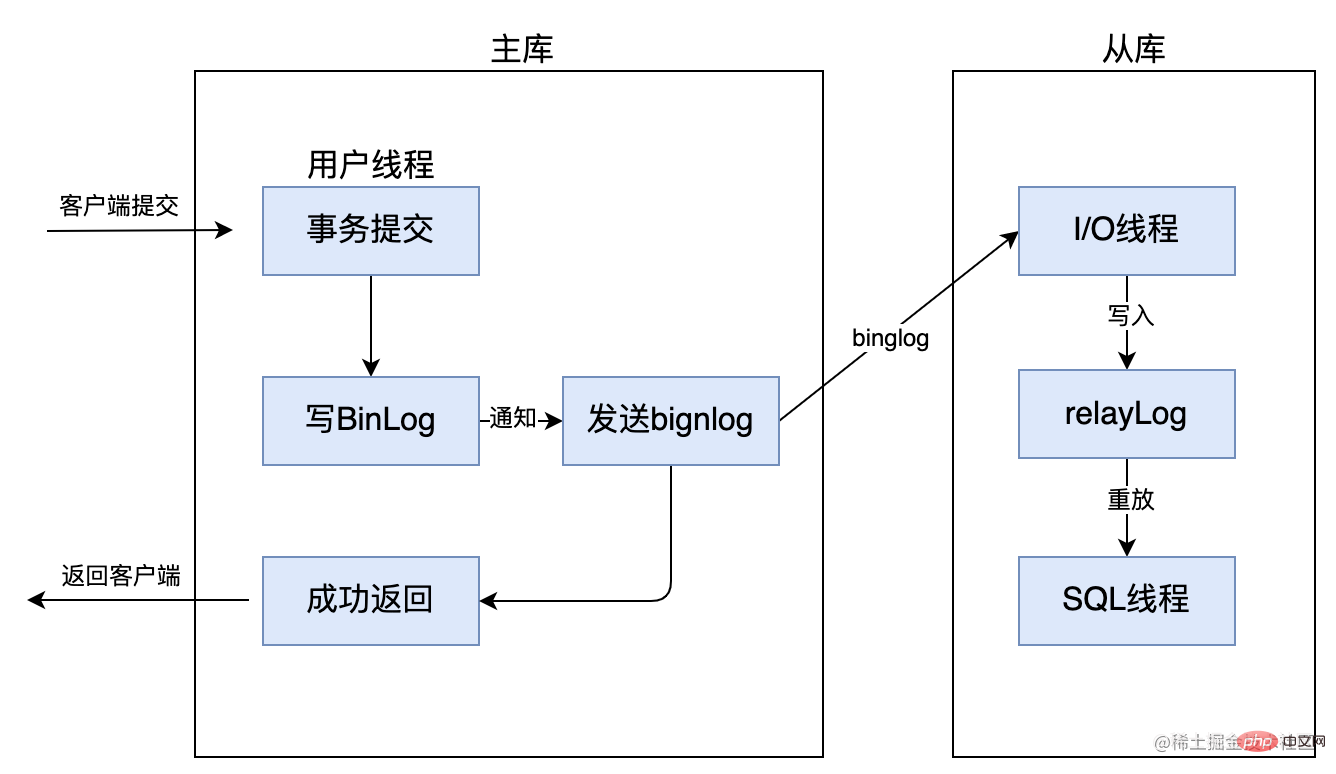
5.1 Réplication entièrement synchrone
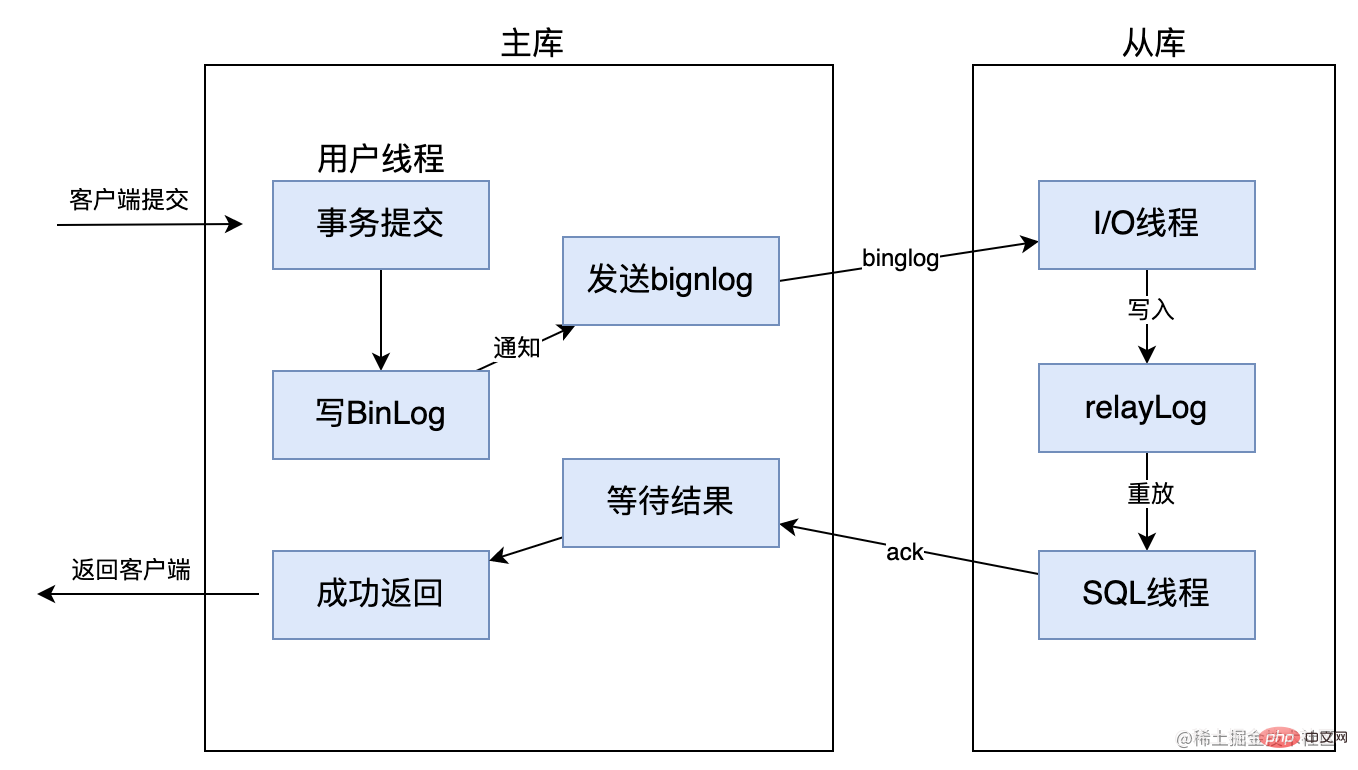
Tout d'abord, la réplication entièrement synchrone signifie qu'une fois que la bibliothèque principale a terminé une transaction, toutes les bibliothèques esclaves doivent également terminer la transaction avant que les résultats du traitement puissent être renvoyés au client, bien que entièrement ; la cohérence des données de réplication synchrone est garantie, mais la base de données maître doit attendre que toutes les bases de données esclaves terminent une transaction, les performances sont donc relativement faibles. Comme indiqué ci-dessous :
5.2 Réplication asynchrone
La réplication asynchrone signifie que lorsque la bibliothèque principale soumet des éléments, elle informera le thread de vidage du journal binaire d'envoyer le journal du journal binaire à la bibliothèque esclave une fois que le thread de vidage du journal binaire l'aura envoyé. le journal binlog à la bibliothèque esclave, il n'est pas nécessaire d'attendre que la bibliothèque esclave termine la transaction de manière synchrone, la bibliothèque maître renverra les résultats du traitement au client.
Étant donné que la bibliothèque principale n'a besoin d'exécuter la transaction que par elle-même, elle peut renvoyer les résultats du traitement au client sans se soucier de savoir si la bibliothèque esclave a terminé la transaction. Cela peut entraîner des problèmes d'incohérence des données maître-esclave à court terme, tels que. comme dans la bibliothèque principale. Si les nouvelles données insérées sont interrogées immédiatement à partir de la base de données, elles ne peuvent pas être interrogées.
De plus, une fois que la base de données maître a soumis les éléments, en cas de panne, le journal binaire n'aura peut-être pas le temps de se synchroniser avec la base de données esclave. À ce moment-là, si les nœuds maître et esclave sont basculés en cas d'échec de récupération, une perte de données se produira, donc. asynchrone Bien que la réplication ait des performances élevées, elle est la plus faible en termes de cohérence des données.
La réplication maître-esclave MySQL adopte la réplication asynchrone par défaut.
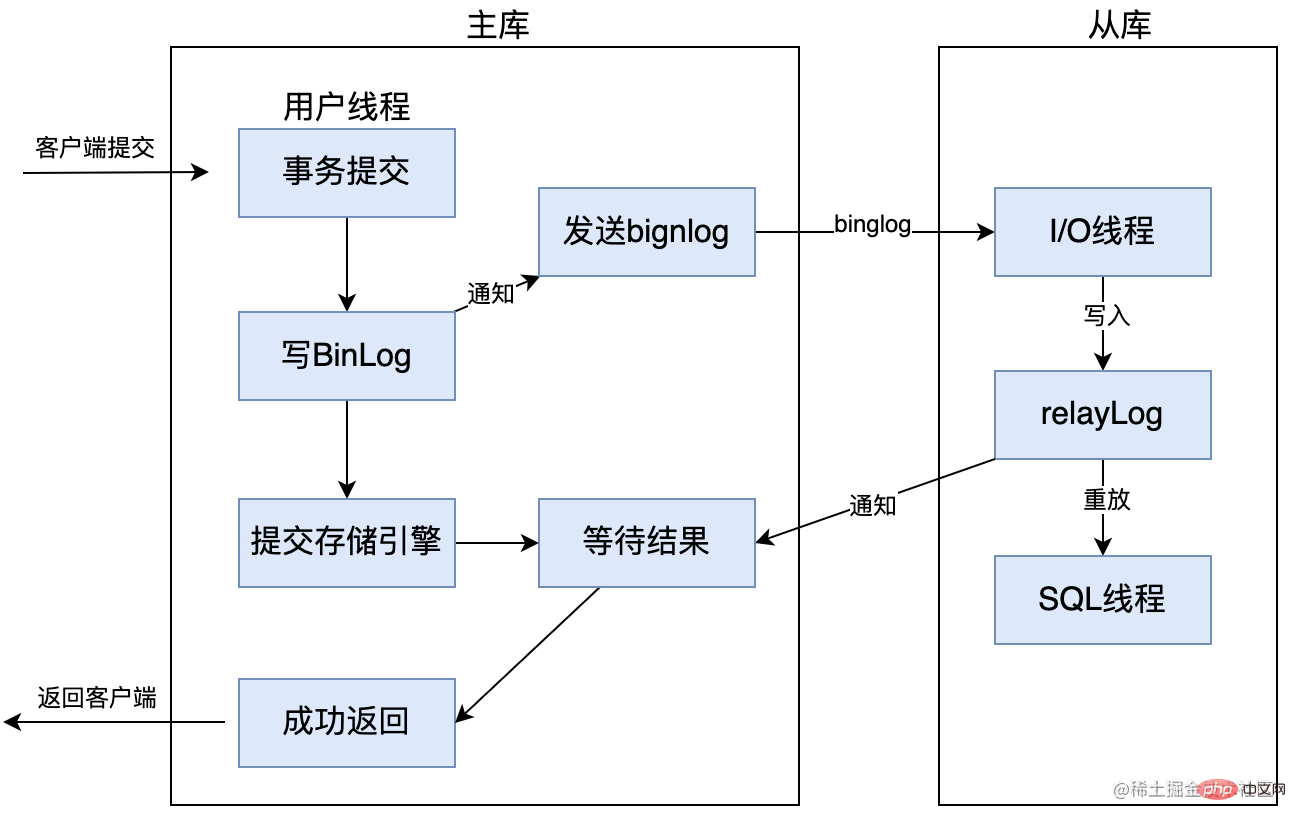
5.3 Réplication semi-synchrone
MySQL commence à prendre en charge la réplication semi-synchrone après la version 5.5. Le principe est qu'une fois que le client a soumis COMMIT, le résultat n'est pas renvoyé directement au client, mais attend plutôt qu'au moins une bibliothèque esclave reçoive le Binlog et l'écrive dans le journal du relais avant de le renvoyer au client. L'avantage est que cela améliore la cohérence des données. Bien entendu, par rapport à la réplication asynchrone, cela augmente le délai d'au moins une connexion réseau supplémentaire et réduit l'efficacité de l'écriture dans la base de données principale.
Dans la version MySQL 5.7, un paramètre rpl_semi_sync_master_wait_for_slave_count a également été ajouté. Nous pouvons définir le nombre de bibliothèques esclaves qui doivent répondre. La valeur par défaut est 1, ce qui signifie que tant qu'une bibliothèque esclave répond, elle peut être renvoyée. client. Si vous augmentez ce paramètre, vous pouvez améliorer la cohérence des données, mais cela augmentera également le temps pendant lequel la base de données maître attend que la base de données esclave réponde.
Cependant, la réplication semi-synchrone présente également les problèmes suivants :
- Les performances de la réplication semi-synchrone ont diminué par rapport à la réplication asynchrone. Par rapport à la réplication asynchrone, il n'est pas nécessaire d'attendre qu'une bibliothèque esclave le fasse. recevoir Pour répondre aux données, la réplication semi-synchrone doit attendre qu'au moins une base de données esclave confirme la réponse de réception du journal binlog, ce qui est plus coûteux en termes de performances.
- Le temps maximum pendant lequel la bibliothèque maître attend la réponse de la bibliothèque esclave est configurable. Si le temps configuré est dépassé, la réplication semi-synchrone deviendra une réplication asynchrone et le problème de la réplication asynchrone se posera également.
- Dans les versions antérieures à MySQL 5.7.2, la réplication semi-synchrone avait un problème de lecture fantôme.
Lorsque la bibliothèque principale soumet avec succès la transaction et est en train d'attendre la confirmation de la bibliothèque esclave, à ce moment-là, la bibliothèque esclave n'a pas eu le temps de renvoyer les résultats du traitement au client, mais parce que la bibliothèque principale le moteur de stockage a déjà soumis la transaction, d'autres clients Le client peut lire les données de la bibliothèque principale.
Cependant, si la bibliothèque principale raccroche soudainement dans la seconde suivante et que la requête suivante arrive à ce moment-là, parce que la bibliothèque principale raccroche, la requête ne peut être basculée que vers la bibliothèque esclave, car la bibliothèque esclave n'a pas n'a pas encore fini de synchroniser les données de la bibliothèque principale, donc, bien sûr, ces données ne peuvent pas être lues à partir de la bibliothèque. Par rapport au résultat de la lecture des données dans la seconde précédente, le phénomène de lecture fantôme est provoqué.
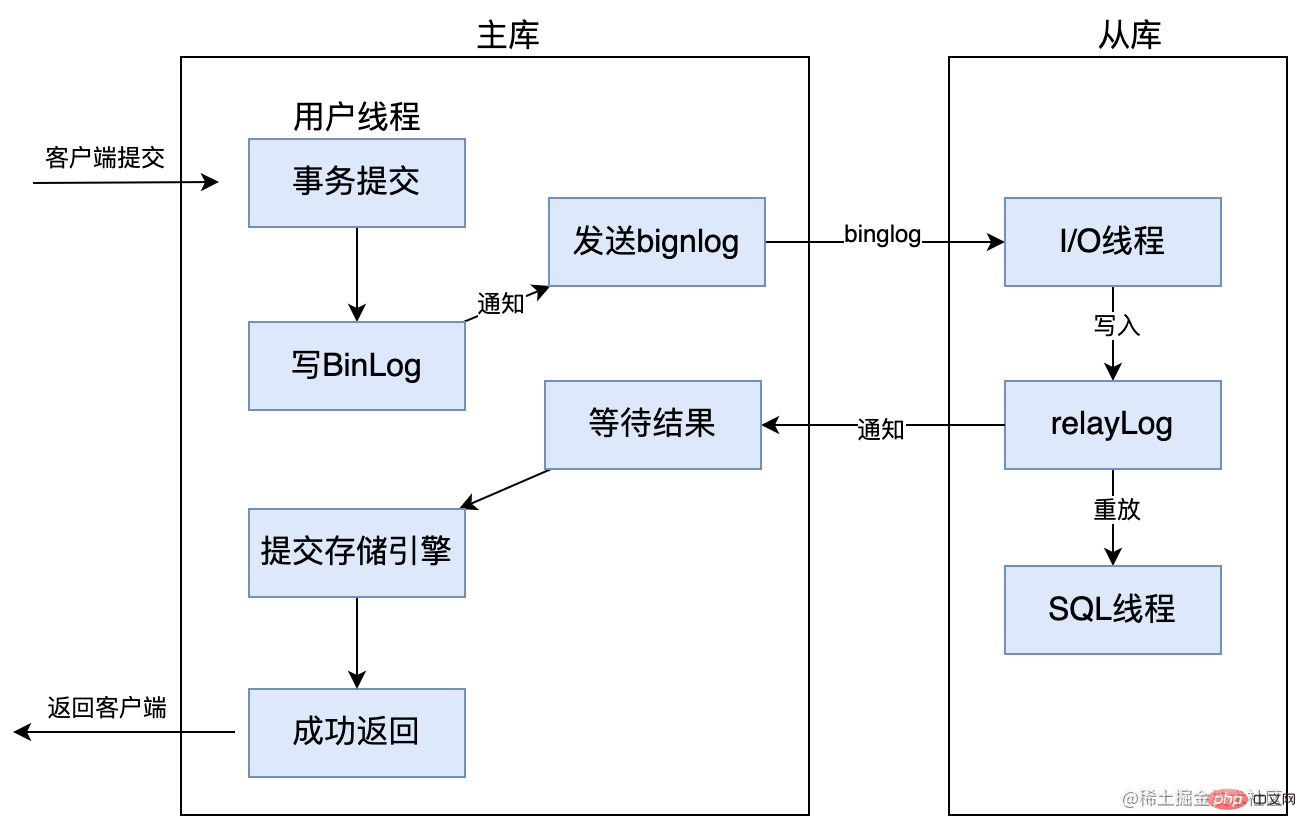
5.4 Réplication semi-synchrone améliorée
La réplication semi-synchrone améliorée est une amélioration apportée à la réplication semi-synchrone dans les versions postérieures à mysql 5.7.2. Le principe est presque le même, principalement pour résoudre le problème des lectures fantômes.
Une fois la bibliothèque maître configurée avec le paramètre rpl_semi_sync_master_wait_point = AFTER_SYNC, avant que le moteur de stockage ne valide la transaction, la bibliothèque maître doit recevoir la confirmation que la synchronisation des données est terminée de la bibliothèque esclave avant de soumettre la transaction, résolvant ainsi le problème de lecture fantôme. . Reportez-vous à l'image ci-dessous :
6 Résumé
Grâce au contenu ci-dessus, nous comprenons la synchronisation maître-esclave de la base de données Mysql. Si votre objectif est uniquement une concurrence élevée de la base de données, vous pouvez commencer par l'optimisation SQL. , indexation et Redis Envisagez l'optimisation d'aspects tels que la mise en cache des données, puis réfléchissez à l'opportunité d'adopter une architecture maître-esclave.
Dans la configuration de l'architecture maître-esclave, si nous souhaitons adopter une stratégie de séparation lecture-écriture, nous pouvons écrire notre propre programme ou l'implémenter via un middleware tiers.
L'avantage d'écrire votre propre programme est qu'il est plus indépendant. Nous pouvons juger quelles requêtes exécuter sur la base de données esclave. Pour des exigences élevées en temps réel, nous pouvons également considérer quelles requêtes peuvent être exécutées sur la base de données principale. Dans le même temps, le programme se connecte directement à la base de données, réduisant ainsi la couche middleware et réduisant certaines pertes de performances.
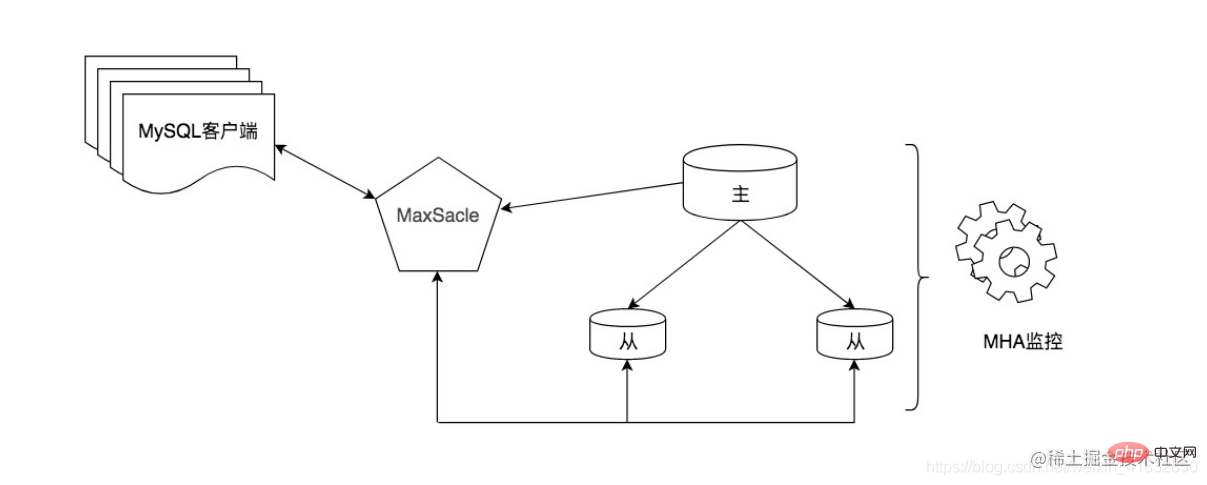
La méthode d'utilisation du middleware présente des avantages évidents, elle est puissante et facile à utiliser. Cependant, il y aura une certaine perte de performances en raison de l'ajout d'une couche middleware entre le client et la base de données. Dans le même temps, le prix du middleware commercial est relativement élevé et il existe un certain coût d'apprentissage. De plus, nous pouvons également envisager d’utiliser d’excellents outils open source, tels que MaxScale. Il s'agit d'un middleware de données MySQL développé par MariaDB. Par exemple, dans la figure ci-dessous, MaxScale est utilisé comme proxy de base de données et la séparation lecture-écriture est effectuée via le routage et le transfert. Dans le même temps, nous pouvons également utiliser l'outil MHA comme outil de commutation maître-esclave fortement cohérent pour compléter l'architecture haute disponibilité de MySQL.
Apprentissage recommandé : "Tutoriel vidéo MySQL"
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!