
Maison >développement back-end >Golang >Explication détaillée de la façon d'utiliser Golang pour explorer les fonds d'écran Bing
Explication détaillée de la façon d'utiliser Golang pour explorer les fonds d'écran Bing

- 青灯夜游avant
- 2023-02-20 19:38:283151parcourir

Inutile de dire qu'il suffit d'utiliser Python pour créer un robot. Une seule requête peut prendre soin du monde. Cependant, j'ai entendu dire que le package http intégré à golang est très puissant. Même si je n'ai aucun travail à faire, je veux juste apprendre de nouvelles choses et revoir les points de connaissances liés à cela. la requête et la réponse du protocole http. Sans plus tarder, allons droit au butrequests包走天下。但是呢,听说golang中内置的http包非常牛逼,咱就是说不得整点活,也刚好学习学习新东西,复习下http协议的请求和响应相关的知识点。话不多说,咱直接开整
本文章爬下必应壁纸先小试牛刀。狗头保命 狗头保命 狗头保命
爬虫流程概述
graph TD 请求数据 --> 解析数据 --> 数据入库
上图的流程图大家可以看到,其实爬虫并不麻烦,整个流程就只有三步而已。接下来具体聊聊每一步需要做什么
请求数据:在这里我们需要使用golang中的内置包http包向目标地址发起请求,这一步就完成了
解析数据:这里我们需要对请求到的数据进行解析,因为不是整个请求到的数据我们都需要,我们只需要某些具体的关键的数据而已。这一步也叫数据清洗
数据入库:不难理解,这就是将解析好的数据进行入库操作
实战分析
先到必应壁纸官网上观察,做爬虫的话是需要对数据特别敏感的。这是首页信息,整个页面是非常简洁的
接下来,需要调出浏览器的开发者工具(这个大家应该都非常熟悉吧,不熟悉的话很难跟下去的喔)。直接按下F12
Découvrez cet articleBing Wallpaper
Essayons-le d'abord. La tête du chien lui sauve la vie. La tête du chien lui sauve la vie. gênant. L’ensemble du processus ne comporte que trois étapes. Parlons ensuite de ce qui doit être fait à chaque étape
Demande de données : ici, nous devons utiliser le package http intégré dans golang pour lancer une demande à l'adresse cible. Complétée en une seule étape
Analyse des données : Ici, nous devons analyser les données demandées, car nous n'avons pas besoin de l'intégralité des données demandées, nous n'avons besoin que de certaines données clés spécifiques. Cette étape est également appelée nettoyage des données
Stockage des données : ce n'est pas difficile à comprendre, il s'agit de stocker les données analysées dans la base de données
Analyse pratique
Allez d'abord sur le site officiel de Bing Wallpaper pour observer et faire un robot d'exploration. Si tel est le cas, vous devez être particulièrement sensible aux données. Ce sont les informations de la page d'accueil. La page entière est très concise
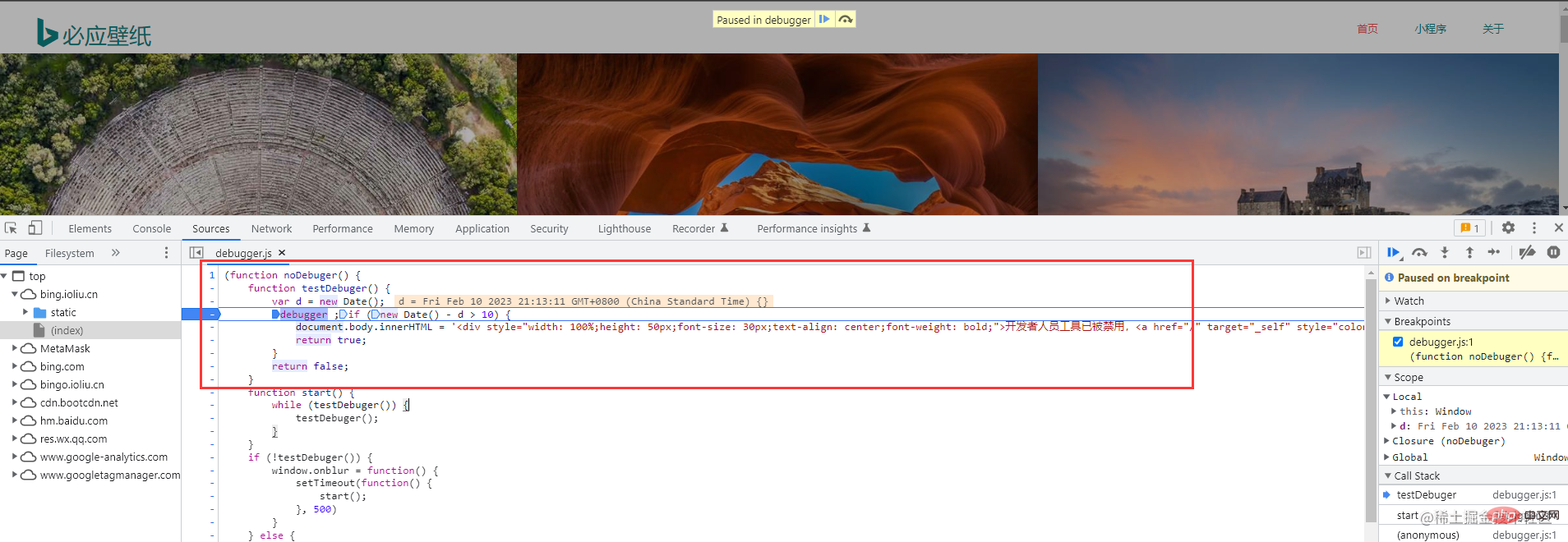
Ensuite, vous devez appeler les outils de développement du navigateur (vous devriez être très familier avec cela, si vous ne le connaissez pas, ce sera difficile à suivre). Appuyez simplement sur
F12ou faites un clic droit pour cocher Mais quoi ? Sur le fond d'écran Bing, un clic droit ne peut pas appeler la console et ne peut être appelé que manuellement. Ne vous inquiétez pas, suivez simplement la première image. Si le chrome d'un camarade de classe est en chinois, la même opération est effectuée. Sélectionnez plus d'outils et sélectionnez les outils de développementPas de surprise, tout le monde doit voir une page comme celle-ci
Ce n'est pas grave, c'est juste nécessaire. C'est juste un anti- erreurs d'exploration sur le site Web de papier peint. (Je n'ai pas eu cette erreur anti-crawling lors de mon exploration il y a longtemps) Cela n'affecte pas notre fonctionnement
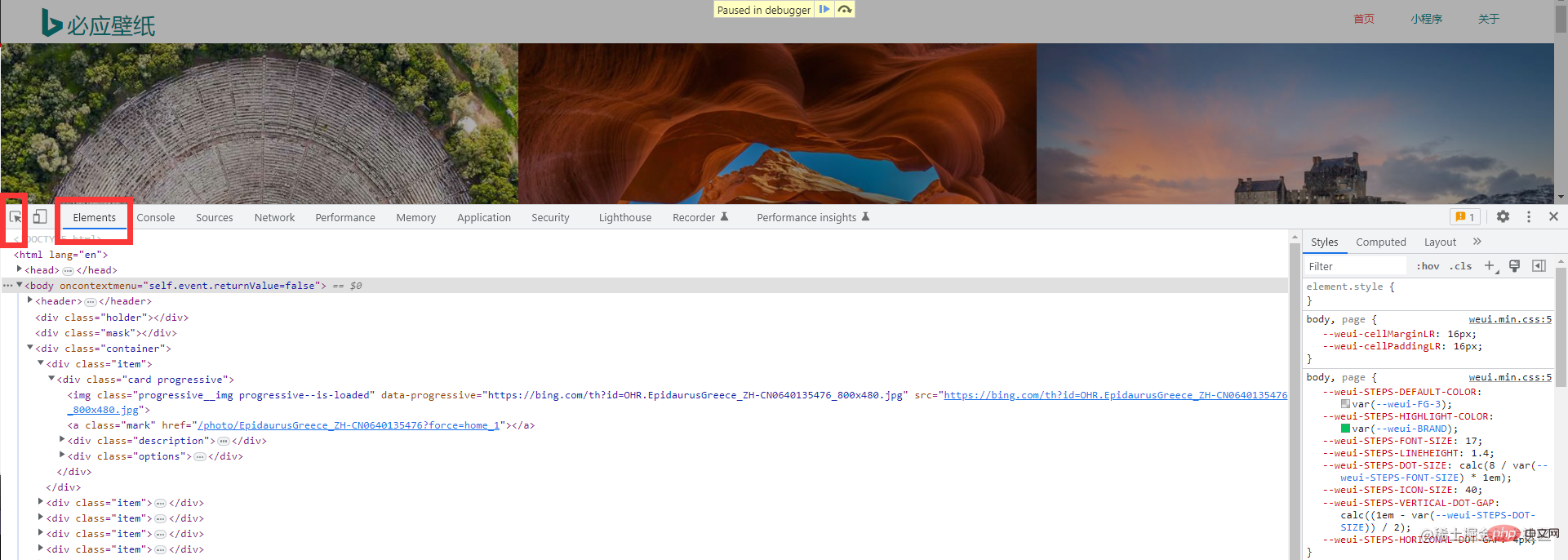
Ensuite, sélectionnez cet outil pour nous aider à localiser rapidement l'élément que nous voulons Nous pourrons ensuite trouver ce dont nous avons besoin Image information
- Pratique du code
- Ce qui suit sont les données pour explorer une page
package main import ( "fmt" "github.com/PuerkitoBio/goquery" "io" "io/ioutil" "log" "net/http" "os" "time" ) func Run(method, url string, body io.Reader, client *http.Client) { req, err := http.NewRequest(method, url, body) if err != nil { log.Println("获取请求对象失败") return } req.Header.Set("user-agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36") resp, err := client.Do(req) if err != nil { log.Println("发起请求失败") return } if resp.StatusCode != http.StatusOK { log.Printf("请求失败,状态码:%d", resp.StatusCode) return } defer resp.Body.Close() // 关闭响应对象中的body query, err := goquery.NewDocumentFromReader(resp.Body) if err != nil { log.Println("生成goQuery对象失败") return } query.Find(".container .item").Each(func(i int, s *goquery.Selection) { imgUrl, _ := s.Find("a.ctrl.download").Attr("href") imgName := s.Find(".description>h3").Text() fmt.Println(imgUrl) fmt.Println(imgName) DownloadImage(imgUrl, i, client) time.Sleep(time.Second) fmt.Println("-------------------------") }) } func DownloadImage(url string, index int, client *http.Client) { req, err := http.NewRequest("POST", url, nil) if err != nil { log.Println("获取请求对象失败") return } req.Header.Set("user-agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36") resp, err := client.Do(req) if err != nil { log.Println("发起请求失败") return } data, err := ioutil.ReadAll(resp.Body) if err != nil { log.Println("读取请求体失败") return } baseDir := "./image/image-%d.jpg" f, err := os.OpenFile(fmt.Sprintf(baseDir, index), os.O_CREATE|os.O_TRUNC|os.O_WRONLY, 0666) if err != nil { log.Println("打开文件失败", err.Error()) return } defer f.Close() _, err = f.Write(data) if err != nil { log.Println("写入数据失败") return } fmt.Println("下载图片成功") } func main() { client := &http.Client{} url := "https://bing.ioliu.cn/?p=%d" method := "GET" Run(method, url, nil, client) }- Ce qui suit sont les données pour explorer plusieurs pages
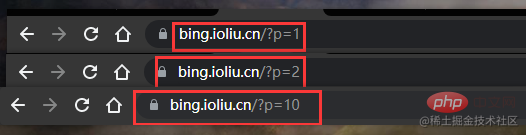
Le code pour explorer plusieurs pages n'a pas beaucoup changé, nous avons toujours devez d'abord observer les fonctionnalités du site WebAvez-vous trouvé quelque chose ? La première page p=1, la deuxième page p=2, la dixième page p=10
Nous commençons donc simplement une boucle for, puis réutilisons le code qui a exploré la page unique avant🎜// 爬取多页的main函数如下 func main() { client := &http.Client{} url := "https://bing.ioliu.cn/?p=%d" method := "GET" for i := 1; i < 5; i++ { // 实现分页操作 Run(method, fmt.Sprintf(url, i), nil, client) } }🎜🎜Résumé🎜🎜🎜Dans Dans notre exemple, nous utilisons un package d'outils tiers pour analyser les données d'une page Web, car il est vraiment trop compliqué d'utiliser des expressions régulières🎜🎜🎜Utilisez le sélecteur CSS : 🎜goQuery🎜🎜🎜Utilisez le sélecteur XPath : 🎜htmlquery🎜🎜🎜 Regular : Package intégré, non recommandé, les règles régulières sont difficiles à écrire🎜🎜🎜Apprentissage recommandé :🎜Tutoriel Golang🎜🎜
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Partager l'utilisation préliminaire de ChatGPT (exemples laravel et go)
- GO Goutil a sorti la version v0.6.4 ! Mise à jour en un coup d'œil !
- Comment déterminer si une méthode existe dans une structure en langage Go ? Deux façons de présenter
- Un article pour parler du problème de concurrence des ressources en langage Go
- Quel langage de programmation est le langage go ?
- Comment implémenter la surveillance des fichiers dans Golang