
Maison >base de données >tutoriel mysql >Vous faire comprendre le pool de tampons de base de données (Buffer Pool) dans MySQL
Vous faire comprendre le pool de tampons de base de données (Buffer Pool) dans MySQL

- 青灯夜游avant
- 2023-02-09 20:11:072479parcourir

Pour les tables utilisant le moteur de stockage InnoDB, l'espace de stockage est géré en unités de pages, comme granularité de base pour les échanges entrants et sortants entre la mémoire et le disque. Lorsque nous chargeons une page du disque dans la mémoire, des E/S sur le disque seront effectuées. La surcharge des E/S disque affecte grandement les performances globales. Si nous lisons la page correspondante directement à partir de la mémoire, cela ne réduirait-il pas la perte de performances causée par les E/S disque et l'efficacité serait considérablement améliorée. Sur cette base, Buffer Pool (
Buffer Pool) est apparu, alors parlons ensuite de Buffer Pool dans InnoDB.Buffer Pool) 出现了,那么接下来,我们就来谈谈InnoDB中的Buffer Pool。
缓冲池(Buffer Pool)
有人会想,既然缓冲池这么好,那我们将所有数据都存储到缓冲池中不就好了,不不不,缓冲池是操作系统分配的一片连续的内存。而内存相比于磁盘的容量小得多,并且价格昂贵。那么操作系统会给缓冲池分配多少内存呢?
- 默认情况下,缓冲池的大小为128MB;
当然,如果你的机器的内存容量非常大,可以在配置文件中配置启动选项参数innodb_buffer_pool_size单位是字节,最小不能小于5MB。
缓冲池的内部结构
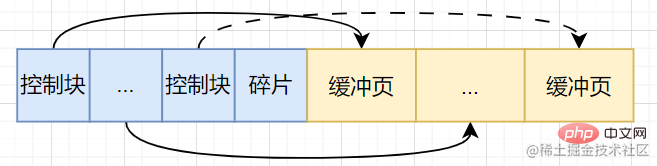
缓冲池将操作系统分配的这一片连续的内存,划分成若干个大小默认为16KB的页(缓冲页)【此时还没有真正的磁盘页被缓存到Buffer Pool中】,当我们从磁盘中换入一个页到缓冲池中,如何分配位置呢?因此就需要一些控制信息来标识这些缓冲池中的缓冲页,这些控制信息都存放在一个叫控制块的内存区域中,与缓冲页一一对应。控制块的大小也是固定的。因此在这片连续的内存空间中,难免会产生内存碎片。综上,缓冲池的内部结构如下:
- 缓冲页
- 控制块:页号、缓冲页在缓冲池中的地址、链表节点信息等。
- 内存碎片【若内存分配得当,内存碎片可有可无】
缓冲池的管理
上面在控制块中提到了链表节点信息,那么链表节点是用来做什么的呢?是为了更好的管理缓冲池中的页。而链表就是用来链接控制块的,因为控制块与缓冲页是一一对应的。
1)空闲链表
将所有空闲的缓冲页对应的控制块链接起来,形成的链表。
解决的问题:从磁盘中换入一个页到缓冲池中,如何区分缓冲池中的哪个页是空闲的呢?而有了空闲链表之后,换入一个磁盘页到缓冲池中时,就直接从空闲链表中获取一个空闲的缓冲页,并将磁盘页中对应的信息填到缓冲页对应的控制块中,然后将该控制块从空闲链表中删除即可。
2)更新链表
若修改了缓冲池中的缓冲页的数据,导致其与磁盘中数据不一致,该页称为脏页。将所有脏页对应的控制块链接起来形成更新链表,在将来的某个时间根据该链表将对应缓存页的数据刷新到磁盘中。
3)LRU链表
缓冲池的大小是有限的,如果缓存的页超出了缓冲池的大小,即没有空闲的缓冲页了,当有新的页要添加到缓冲池中时,采取LRU的策略将旧的缓冲页从缓冲池中移除,然后将新的页添加进来。由于LRU链表涉及的内容较多,我们接下来单独介绍。
LRU链表所蕴含的“哲理”
先提一下预读机制
在I/O上的优化机制,预读顾名思义,会异步地把某些页面加载到缓冲池中,预计很快就会需要这些页面,这些请求在一个范围内引入所有页面,就是所谓的 局部性原理,目的是减少磁盘I/O。
了解预读机制之前,先回顾一下InnoDB逻辑存储单元:表空间(tablespace)→段(segment )→区(extent)→页(page)。其中特意提一下区,后面会用到:一个区就是物理位置上连续的64个页
Buffer Pool
Certaines personnes peuvent penser que puisque le pool de tampons est si bon, pourquoi ne stockons-nous pas toutes les données dans le pool de tampons ? C'est très bien, non non non,Le pool de mémoire tampon est une mémoire contiguë allouée par le système d'exploitation. La mémoire a une capacité bien inférieure à celle du disque et coûte cher. Alors, quelle quantité de mémoire le système d’exploitation allouera-t-il au pool de mémoire tampon ? 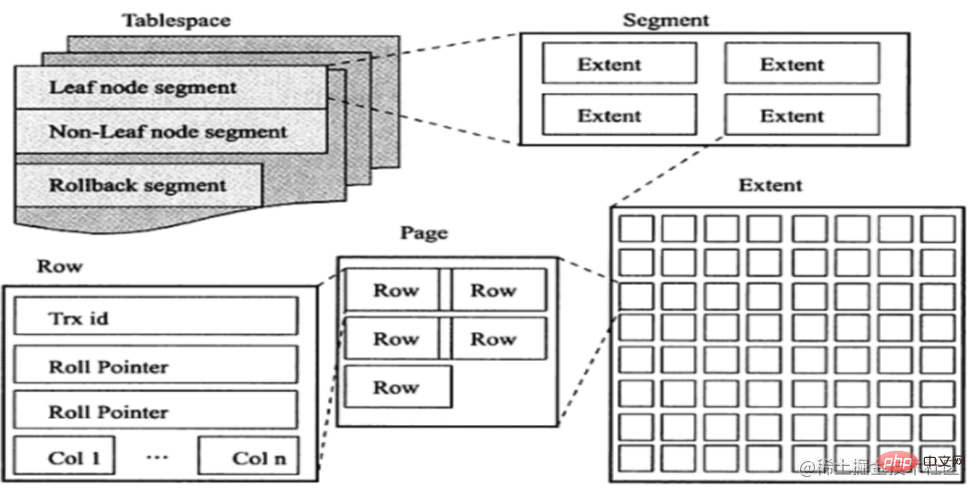
- Par défaut, la taille du pool de mémoire tampon est de 128 Mo
innodb_buffer_pool_sizeL'unité est de octets, et le minimum ne peut pas être inférieur à 5 Mo.
Structure interne du pool de mémoire tampon
🎜Le pool de mémoire tampon divise la mémoire continue allouée par le système d'exploitation en plusieurs pages (pages tampon) avec une taille par défaut de 16 Ko [ À l'heure actuelle, aucune page de disque réelle n'a été mise en cache dans le pool de tampons.] Lorsque nous échangeons une page du disque vers le pool de tampons, comment allouons-nous l'emplacement ? Par conséquent, certaines informations de contrôle sont nécessaires pour identifier les pages tampon dans ces pools de tampons. Ces informations de contrôle sont stockées dans une zone mémoire appelée bloc de contrôle et correspondent une à une à la page tampon. La taille du bloc de contrôle est également fixe. Par conséquent, dans cet espace mémoire continu, une fragmentation de la mémoire se produira inévitablement. En résumé, la structure interne du pool de tampons est la suivante : 🎜- Page tampon
- Bloc de contrôle : numéro de page, adresse de la page tampon dans le pool de tampons, informations sur le nœud de liste chaînée , etc.
- Fragmentation de la mémoire [Si la mémoire est allouée correctement, la fragmentation de la mémoire est superflue]
 🎜
🎜Gestion du pool de tampons
🎜 Le lien les informations sur les nœuds de liste sont mentionnées ci-dessus dans le bloc de contrôle, alors à quoi servent les nœuds de liste chaînés ? Il s'agit de mieux gérer les pages dans le pool tampon. La liste chaînée est utilisée pour lier les blocs de contrôle, car il existe une correspondance biunivoque entre les blocs de contrôle et les pages tampon. 🎜1) Liste chaînée gratuite
🎜 Liez les blocs de contrôle correspondant à toutes les pages tampon libres pour former une liste chaînée. 🎜🎜🎜Problème résolu : lors de l'échange d'une page du disque vers le pool de tampons, comment distinguer quelle page du pool de tampons est libre ? Avec la liste chaînée libre, lorsqu'une page disque est permutée dans le pool de tampons, une page tampon libre est obtenue directement à partir de la liste chaînée libre, et les informations correspondantes dans la page disque sont remplies dans le bloc de contrôle correspondant à la page tampon, puis supprimez simplement le bloc de contrôle de la liste chaînée gratuite. 🎜2) Mettre à jour la liste chaînée
🎜Si les données de la page tampon dans le pool de tampons sont modifiées, ce qui les rend incohérentes avec les données sur le disque, le la page est appelée une page sale. Liez les blocs de contrôle correspondant à toutes les pages sales pour former une liste chaînée de mise à jour et actualisez les données de la page de cache correspondante sur le disque à un certain moment dans le futur en fonction de cette liste chaînée. 🎜3) Liste chaînée LRU
🎜La taille du pool de tampons est limitée Si les pages mises en cache dépassent la taille du pool de tampons, il n'y aura pas de tampon libre. pages Quand Lorsqu'une nouvelle page doit être ajoutée au pool de mémoire tampon, la stratégie LRU est adoptée pour supprimer l'ancienne page tampon du pool de mémoire tampon, puis ajouter la nouvelle page. Étant donné que la liste chaînée LRU implique beaucoup de contenu, nous la présenterons séparément ensuite. 🎜La "philosophie" contenue dans la liste chaînée LRU
Permettez-moi d'abord de mentionner le mécanisme de pré-lecture h2>🎜In I Le mécanisme d'optimisation sur /O, en lecture anticipée, comme son nom l'indique, chargera de manière asynchrone certaines pages dans le pool de tampons. On s'attend à ce que ces pages soient bientôt nécessaires. Ces requêtes introduisent toutes les pages d'une plage. , ce qu'on appelle le 🎜Principe de localité Le but est de réduire les E/S disque. 🎜🎜Avant de comprendre le mécanisme de lecture anticipée, passons en revue l'unité de stockage logique InnoDB : tablespace → segment → étendue → page. Les zones sont spécifiquement mentionnées, qui seront utilisées plus tard : une zone est un 64 pages continu dans un emplacement physique, c'est-à-dire que la taille d'une zone est de 1 Mo.🎜🎜🎜🎜🎜La pré-lecture Le mécanisme peut être subdivisé en Les deux types suivants : 🎜
-
Lecture anticipée linéaire : une technique qui prédit quelles pages pourraient être bientôt nécessaires en fonction d'un accès séquentiel aux pages du pool de mémoire tampon. En configurant le paramètre innodb_read_ahead_threshold, si les pages d'une certaine zone accédées séquentiellement dépassent la valeur de ce paramètre, une demande de lecture asynchrone sera déclenchée pour lire toutes les pages de la zone suivante dans le pool de mémoire tampon.
-
Lecture anticipée aléatoire : peut prédire quand des pages pourraient être nécessaires en fonction des pages déjà présentes dans le pool de mémoire tampon, quel que soit l'ordre dans lequel ces pages sont lues. Si 13 pages consécutives de la même étendue sont trouvées dans le pool de mémoire tampon, InnoDB émettra de manière asynchrone une demande pour préextraire les pages restantes de l'étendue. Contrôlez la lecture aléatoire en configurant la variable innodb_random_read_ahead.
Comment le LRU traditionnel gère-t-il les pages tampon ?
Utilisez l'algorithme LRU pour gérer les pages tampon les moins récemment utilisées et former une liste chaînée correspondante pour une élimination facile.
Lorsqu'une page est consultée [c'est-à-dire récemment consultée]
- La page est dans le pool tampon, déplacez le bloc de contrôle correspondant en tête de la liste chaînée LRU
- La page n'est pas dans le pool tampon, éliminez le moins page récemment utilisée à la fin, et supprimez-la du disque Chargez la page et placez-la en tête de la liste chaînée LRU
Alors pourquoi InnoDB n'utilise-t-il pas un algorithme LRU aussi intuitif ? Les raisons sont les suivantes :
-
Échec de la lecture anticipée
Les pages du pool de tampons en lecture anticipée seront placées en tête de la liste chaînée LRU, mais beaucoup d'entre elles risquent de ne pas être lues.
-
Pollution du pool tampon
Le chargement de nombreuses pages moins fréquemment utilisées dans le pool tampon éliminera les pages les plus fréquemment utilisées du pool tampon. Par exemple, analyse complète de la table
Comment le LRU optimisé gère-t-il les pages tampon ?
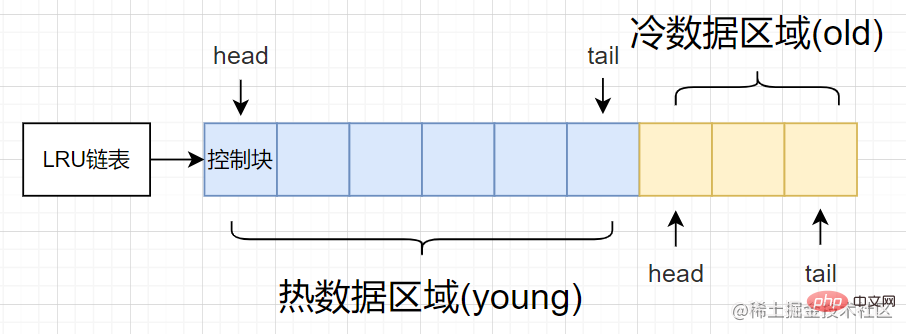
Sur la base des lacunes ci-dessus, la méthode spécifique optimisée divise la liste chaînée LRU traditionnelle en deux parties : zone de données chaudes [zone jeune] et zone de données froides [ancienne zone]
- zone de données chaudes [zone jeune] : fréquence d'utilisation Page tampon élevé
- Zone de données froides [zone des personnes âgées] : Zone à faible fréquence d'utilisation
Le schéma structurel est le suivant :
Comme le montre la figure, la zone de données chaudes et la zone de données froides La zone de données occupe différentes proportions, nous pouvons alors contrôler la proportion de innodb_old_blocks_pct启动选项来控制冷数据区域所占比例。
改进后的LRU如何更好的解决预读失效问题呢?
- 某个页在初次加载到缓冲池中时,先淘汰掉冷数据区域尾部的控制块(即其对应的页淘汰掉),然后新页对应的控制块会先放到冷数据区域的头部。
- 若后续该页不被进行访问就会慢慢从冷数据区域中被淘汰掉,总体不会影响热数据区域访问频繁的缓冲页。
改进后的LRU如何更好的解决缓冲池污染问题呢?
先说结论,并没有很好的优化这个问题,原因如下【以全表扫描为例】:
- 某个初次访问的页同样会放到冷数据区域的头部,但后续访问又会将其放到热数据区域的头部,这样同样会把访问频率较高的页给挤掉。
那么到底该如何解决缓冲池污染问题呢?
- 缓冲池引入了冷数据区域时间窗口机制,即只有后续访问该页与第一访问该页的时间间隔大于规定的窗口值,就会将该页从冷数据区域移到热数据区域的头部。小于规定的窗口值,就不会进行移动操作。
- 同样,窗口值可通过
innodb_old_blocks_timezone de données froides via l'option de démarrage
innodb_old_blocks_pct.
Comment le LRU amélioré peut-il mieux résoudre le problème de l'échec de la lecture anticipée ?
- Lorsqu'une page est chargée pour la première fois dans le pool tampon, le bloc de contrôle à la fin de la zone de données froides est d'abord éliminé (c'est-à-dire que sa page correspondante est éliminée), puis le bloc de contrôle correspondant à la nouvelle page est d'abord placée dans la zone de données froides.
- Si la page n'est pas consultée par la suite, elle sera lentement éliminée de la zone de données froides. Généralement, cela n'affectera pas les pages tampon fréquemment consultées dans la zone de données chaudes.
Comment le LRU amélioré peut-il mieux résoudre le problème de la pollution du bassin tampon ?
Parlons d'abord de la conclusion. Ce problème n'a pas été bien optimisé. Les raisons sont les suivantes [prenons l'exemple du scan complet du tableau] : 🎜🎜🎜Une page visitée pour la première fois sera également placée en tête. de la zone de données froides, mais les visites ultérieures Il sera placé en tête de la zone de données chaudes, ce qui évincera également les pages avec une fréquence d'accès plus élevée. 🎜🎜🎜Alors comment résoudre le problème de pollution du bassin tampon ? 🎜🎜🎜Le pool de tampons introduit le mécanisme de fenêtre temporelle de la zone de données froides, c'est-à-dire que tant que l'intervalle de temps entre l'accès ultérieur à la page et le premier accès à la page est supérieur à la valeur de fenêtre spécifiée, la page sera déplacée de la zone de données froides à la zone de données chaudes. Si la valeur de la fenêtre est inférieure à la valeur spécifiée, l'opération de déplacement ne sera pas effectuée. 🎜🎜De même, la valeur de la fenêtre peut être définie via le paramètreinnodb_old_blocks_time [unité ms]. La valeur par défaut est de 1 000 ms, et 1 s filtrera la plupart des opérations telles que les analyses de table complètes. Par exemple, lors d'une analyse complète d'une table, l'intervalle de temps entre plusieurs accès à une page ne dépassera pas 1 seconde. 🎜🎜🎜Pool de tampons VS cache de requêtes🎜🎜🎜Le pool de tampons et le cache de requêtes sont-ils la même chose ? →Non 🎜🎜🎜🎜Le pool de tampons essaiera de sauvegarder les données fréquemment utilisées Lorsque MySQL lit une page, il déterminera d'abord si la page est dans le pool de tampons. Si elle existe, elle sera lue directement. existe, elle sera lue directement. La page sera stockée dans le pool de mémoire tampon via la mémoire ou le disque puis lue. 🎜🎜Le cache de requête met en cache les résultats des requêtes à l'avance afin que vous puissiez obtenir les résultats directement sans les exécuter la prochaine fois. Il convient de noter que le cache de requêtes dans MySQL ne met pas en cache le plan de requête, mais les résultats correspondants de la requête. Les conditions d'accès sont strictes et tant que la table de données change, le cache de requêtes deviendra invalide, le taux d'accès est donc faible. 🎜🎜🎜【Recommandations associées : 🎜tutoriel vidéo mysql🎜】🎜Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quelles sont les différences entre nosql et mysql
- Comment compresser un stockage de texte volumineux dans MySQL
- Que dois-je faire si le service MySQL ne peut pas être démarré ?
- Un article analysant brièvement comment MySQL résout le problème de lecture fantôme
- Comment installer PHP et MySQL dans RedHat
- MySQL a-t-il des variables temporaires ?