
Maison >Java >javaDidacticiel >Algorithmes de tri courants pour les structures de données Java (partage de résumé)
Algorithmes de tri courants pour les structures de données Java (partage de résumé)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-01-22 06:30:011895parcourir
Cet article vous apporte des connaissances pertinentes sur Java, qui présentent principalement certains algorithmes de tri courants, notamment le tri par insertion directe, le tri Hill (réduction du tri incrémentiel), le tri par sélection et le tri par tas, etc., comme suit Jetons un coup d'œil, j'espère que cela sera utile à tout le monde.

1. Comprendre l'ordre
À l'école, si on veut participer à une rencontre sportive ou à un entraînement militaire, on s'alignera du petit au grand, comme la feuille de présence tenue par le professeur en classe . Habituellement, ils sont triés par numéro d’étudiant de bas en haut. Un autre exemple est le classement des langages de programmation, qui est également trié.
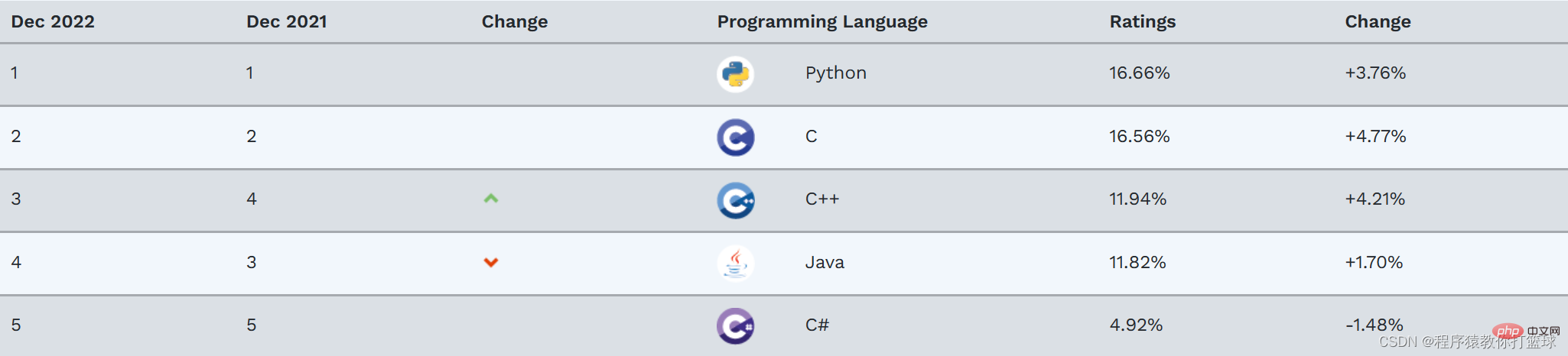
Il existe de nombreux scénarios de tri dans la vie. On peut voir que le tri est toujours très important. Ce chapitre présentera quelques algorithmes de tri courants.
Le soi-disant tri, prenons notre exemple ci-dessus, est l'opération de tri par ordre croissant ou décroissant selon la taille d'un ou de certains mots-clés. Il s'agit d'un tri, qui implique également la stabilité du tri , par exemple. :
Par exemple, il existe un ensemble de données comme celui-ci : B D A C A F, qui doivent être triés en fonction de leurs codes ascll. Il y a ici deux A. Nous appelons le premier A qui apparaît A1, le deuxième A qui apparaît est appelé. A2.
Supposons que le résultat après tri soit : A1 A2 B C D F, alors cet algorithme de tri est stable.
Supposons que le résultat après le tri soit : A2 A1 B C D F, alors cet algorithme de tri est instable.
En bref, s'il y a deux éléments identiques dans les données à trier, la relation entre les deux éléments n'a pas changé une fois le tri terminé. Par exemple, A1 est devant A2 avant le tri, A1. Toujours devant A2, il s'agit d'un algorithme de tri stable.
Remarque : Un algorithme de tri instable est intrinsèquement instable, mais un algorithme de tri stable peut être conçu pour être instable.
2. Classification du tri commun
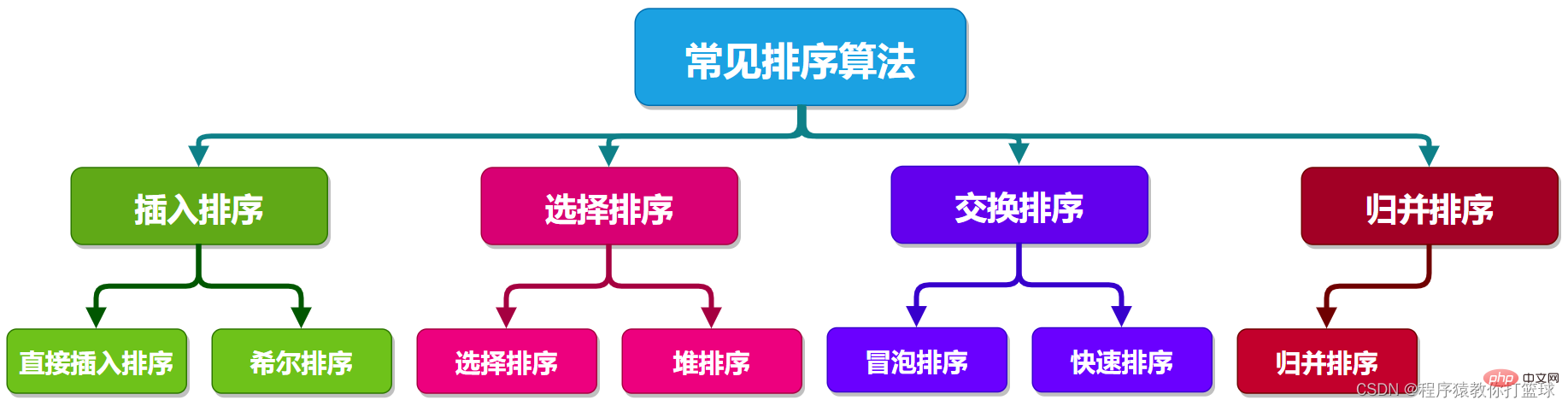
Cette image résume l'algorithme de tri dont nous parlerons plus tard, et entre alors officiellement dans l'étude de ce chapitre ! (Dans le chapitre sur l'algorithme de tri, la valeur par défaut est ordre croissant) Remarque : le journal de complexité mentionné plus tard est basé sur 2, et les spéciaux seront marqués.
3. Tri par insertion directe
Maintenant, je voudrais vous demander à tous d'imaginer que vous touchez des cartes à jouer, vous avez touché la première carte et l'avez mise dans votre main, puis vous avez touché une autre carte, et puis vous avez mis celle-ci. carte dans votre main. Comparez la carte de votre main et placez-la dans la position appropriée. Ensuite, piochez une autre carte avec les deux cartes de votre main et placez-la dans la position appropriée.
Il s'agit d'un tri par insertion directe. Pour faire simple, les éléments que nous prenons à chaque fois seront insérés dans une séquence ordonnée, c'est-à-dire qu'avant que chaque carte ne soit tirée, les cartes en main sont triées. cartes nouvellement tirées avec les cartes commandées dans votre main, et placez-les simplement dans la position appropriée !
Ici, nous utilisons une image statique pour démontrer brièvement :
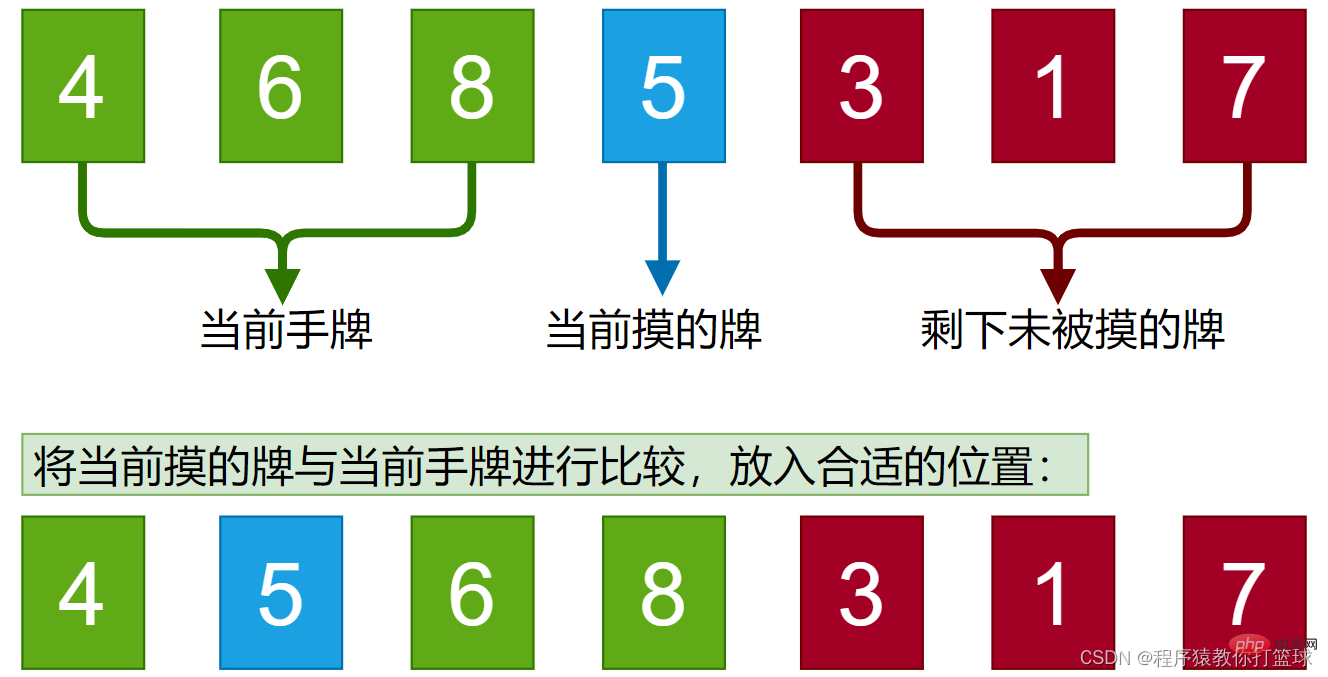
Nous comprenons déjà l'idée générale, et nous devons ensuite utiliser du code pour la mettre en œuvre :
public void insertSort(int[] array) {
// 外循环控制趟数, 第一张牌默认有序, 所以 i 从 1 开始
for (int i = 1; i < array.length; i++) {
int tmp = array[i]; //当前摸到的牌
// 每次从手中牌的最后一张牌开始比较, 一直比到第一张牌
int j = i - 1;
for (; j >= 0; j--) {
//如果当前位置的牌,大于我摸到的牌,就往后挪
if (array[j] > tmp) {
array[j + 1] = array[j];
} else {
break;
}
}
// 把摸到的牌放到对应位置上
array[j + 1] = tmp;
}
}
- Analyse de la complexité temporelle : L'extérieur la boucle a besoin de n - 1 fois au total, et la boucle interne doit être comparée 1...n fois dans le pire des cas. Supprimez ensuite le petit terme devant n, c'est-à-dire (n - 1) * n fois, Autrement dit, n^2 - n, supprimez le terme minimum, et la complexité temporelle finale est O(n^2)
- Analyse de la complexité spatiale : ouvre simplement une variable tmp i, j, constante, c'est-à-dire , complexité spatiale Degré : O(1)
- Stabilité : Stable
- Plus les données sont proches de la situation ordonnée de ce tri, plus l'efficacité temporelle est élevée.
4. Tri en colline (réduction du tri incrémental)
Ce tri est une optimisation du tri par insertion directe. Vous imaginez bien qu'il y a 8 plaques d'immatriculation d'amour placées côte à côte devant vous, mais elles sont infinies. Dans l'ordre, nous devons regrouper les plaques d'immatriculation. Selon les exigences, le premier intervalle de temps est de 4 plaques d'immatriculation en groupe. Après le regroupement, le tri par insertion directe est effectué. le tri par insertion est effectué et le troisième intervalle est 1 plaque d'immatriculation en tant que groupe, le tri par insertion directe est effectué.
C'est un peu flou quand j'entends ça. Cela n'a pas d'importance. Comprenons encore ce que j'ai dit ci-dessus en dessinant des images :

由上图我们可以发现,当间隔 > 1 的时候,都是预排序,也就是让我们的数据更接近有序,但是当间隔为 1 的时候,就是直接插入排序了,前面我们说过,直接插入排序,再数据接近有序的时候时间效率是很快的。由此可见,希尔排序,是直接插入排序的优化版。
如何在代码中实现呢?间隔的值如何取呢?代码中把这个间隔的值称为 gap,这个 gap 的取值方法有很多,有的人提出 gap 为奇数好,有的提出 gap 为偶数好,我们就采取一种比较简单的方法来取 gap 值,首次取数组长度一半的值为 gap,后续 gap /= 2,即可。当 gap 为 1,也就是直接插入排序了。
代码实现如下:
public void shellSort(int[] array) {
// gap初始值设置成数组长度的一半
int gap = array.length >> 1;
// gap 为 1 的时候直接插入排序
while (gap >= 1) {
shell(array, gap);
gap >>= 1; // 更新 gap 值 等价于 -> gap /= 2;
}
}
private void shell(int[] array, int gap) {
for (int i = gap; i < array.length; i++) {
int tmp = array[i];
int j = i - gap;
for (; j >= 0; j -= gap) {
if (array[j] > tmp) {
array[j + gap] = array[j];
} else {
break;
}
}
array[j + gap] = tmp;
}
}
如果实在是不好理解,就结合上边讲的直接插入排序来理解,相信你能理解到的。
- 时间复杂度分析:希尔排序的时间复杂度不好分析, 这里我们就大概记一下,约为 O(n^1.3),感兴趣的话,可以查阅一下相关书籍。
- 空间复杂度分析:仍然开辟的是常数个变量,空间复杂度为 O(1)
- 稳定性:不稳定
5、选择排序
这个排序是个很简单的排序,你想象一下,有个小屁孩,喜欢玩小球,我给他安排了个任务,把这一排小球从小到大排列起来,摆给我看,于是小屁孩就找,每次从一排小球中找出最大的,放到最后,固定不动,那是不是也就是说,每次能确定一个最大的石子的最终位置了。我们来看图:
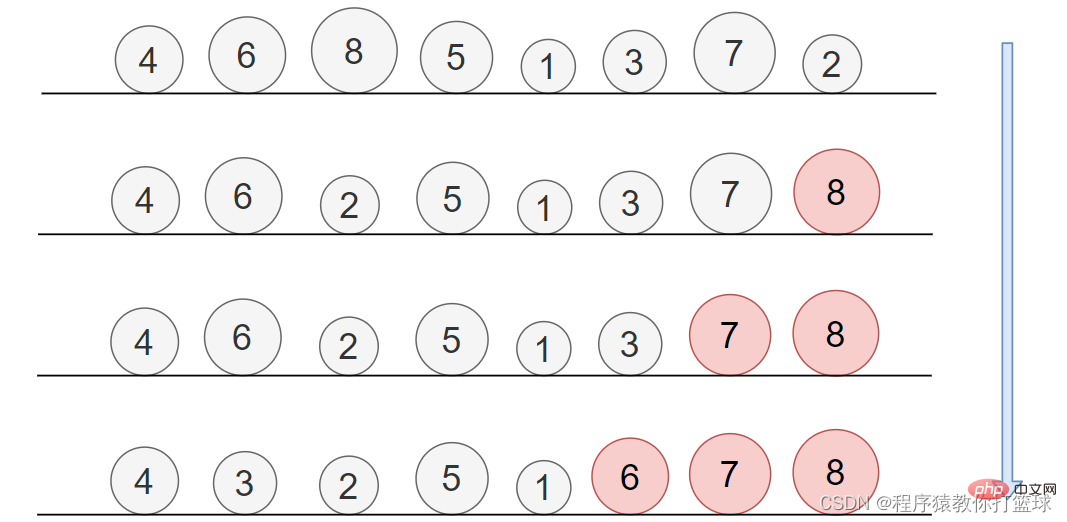
通过图片我们也能看出来,每次找到最大值于最后一个值交换,所以每趟都能把最大的放到最后固定不动,每趟能排序一个元素出来,那这样用代码来实现就很简单了:
public void selectSort(int[] array) {
int end = array.length - 1;
// 剩最后一个元素的时候, 不用比较了, 已经有序了
// 所以 i < array.length - 1
for (int i = 0; i < array.length - 1; i++) {
int max = 0;
int j = 0;
while (j <= end) {
if (array[j] > array[max]) {
max = j;
}
j++;
}
//找到了最大值的下标, 把最大值与最后一个值交换
swap(array, max, end--); // end-- 最后一个元素固定了, 不用参与比较
}
}
这个算法有没有可以优化的空间呢?
有!那么既然小屁孩能一次找出最大的球,那能不能让小屁孩一次找出两个球出来呢?分别是这些球中,最大的和最小的,最大的放在最右边,最小的放在最左边,那么我们每次就能确定两个球的最终位置,也就是我们一次能排序两个元素。图解:
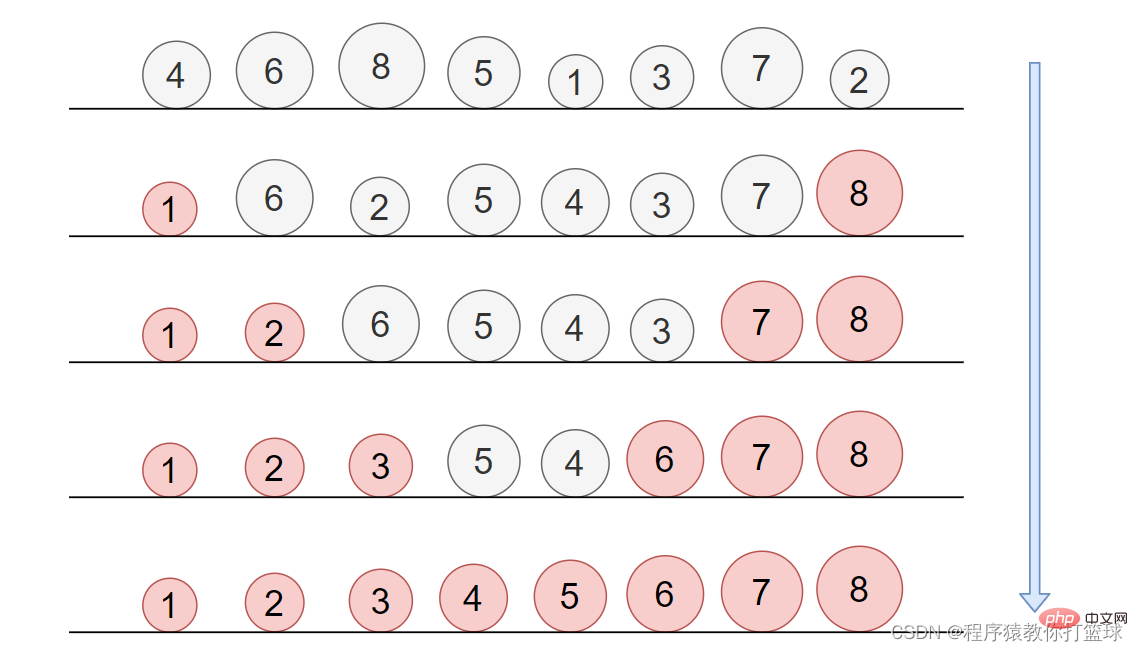
代码实现如下:
public void selectSort(int[] array) {
int left = 0;
int right = array.length - 1;
while (left < right) {
int maxIndex = left;
int minIndex = left;
// i = left + 1 -> 每次找最大最小值下标的时候, 可以不用算默认给的最大值和最小值下标
for (int i = left + 1; i <= right; i++) {
if (array[i] > array[maxIndex]) {
maxIndex = i;
}
if (array[i] < array[minIndex]) {
minIndex = i;
}
}
swap(array, minIndex, left);
// 如果最大值为 left 的位置情况的话, 走到这, 最大值已经被交换到 min 位置上了
if (maxIndex == left) {
// 更新最大值的位置
maxIndex = minIndex;
}
swap(array, maxIndex, right);
left++;
right--;
}
}
- 时间复杂度分析:虽然是优化了,但去小项之后,还是 O(n^2)
- 空间复杂度分析:O(1)
- 稳定性:不稳定
- 实际开发中用的不多
6、堆排序
如果你有学习过优先级队列,或者看过博主优先级队列的文章,那么这个排序对于你来说还是很轻松的,当然在堆排序的讲解中,不会过多的去介绍堆的概念,如果对这部分概念还不理解,可以移至博主的上一篇文章进行学习。
堆排序,简单来说,就是把一组数据,看成一个完全二叉树,再把这棵树,建大堆或者建小堆,接着进行排序的一种思路。至于如何建大堆或小堆,和向上调整算法以及向下调整算法,这里也不多介绍了,博主的上篇文章都详细介绍过。
这里我们来分析一下,排升序应该建什么堆?大堆!排降序建小堆!
这里我们来排升序,建大堆,因为大堆堆顶元素一定是堆中最大的,所以我们可以把堆顶元素和最后一个元素进行交换,这样我们就确认了最大值的位置,接着将交换后的堆顶元素进行向下调整,仍然使得该数组满足大堆的特性!图解如下:
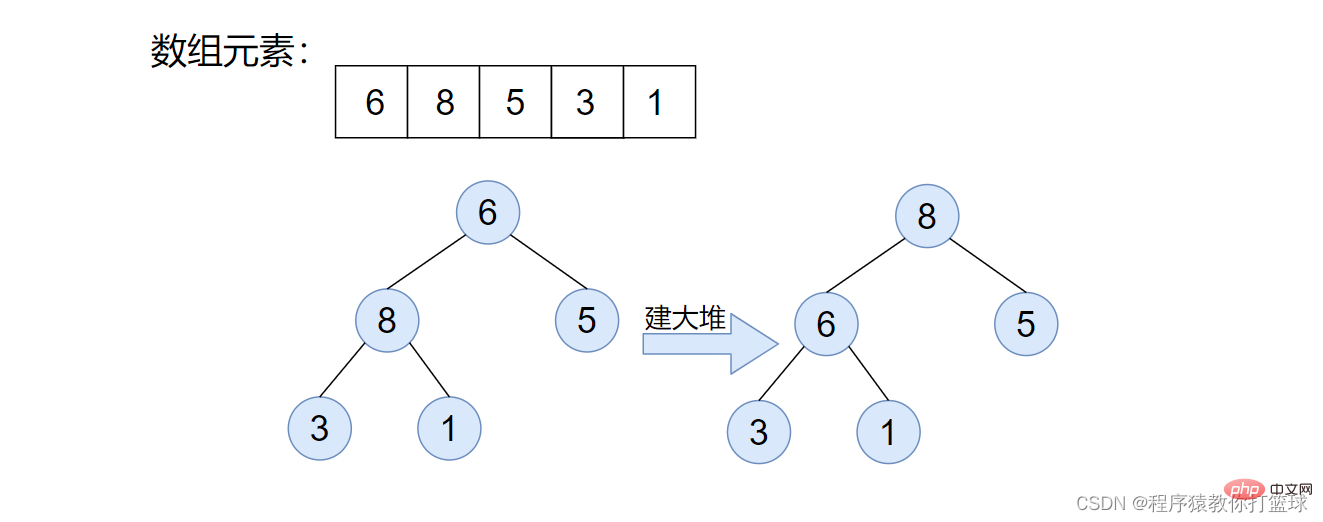
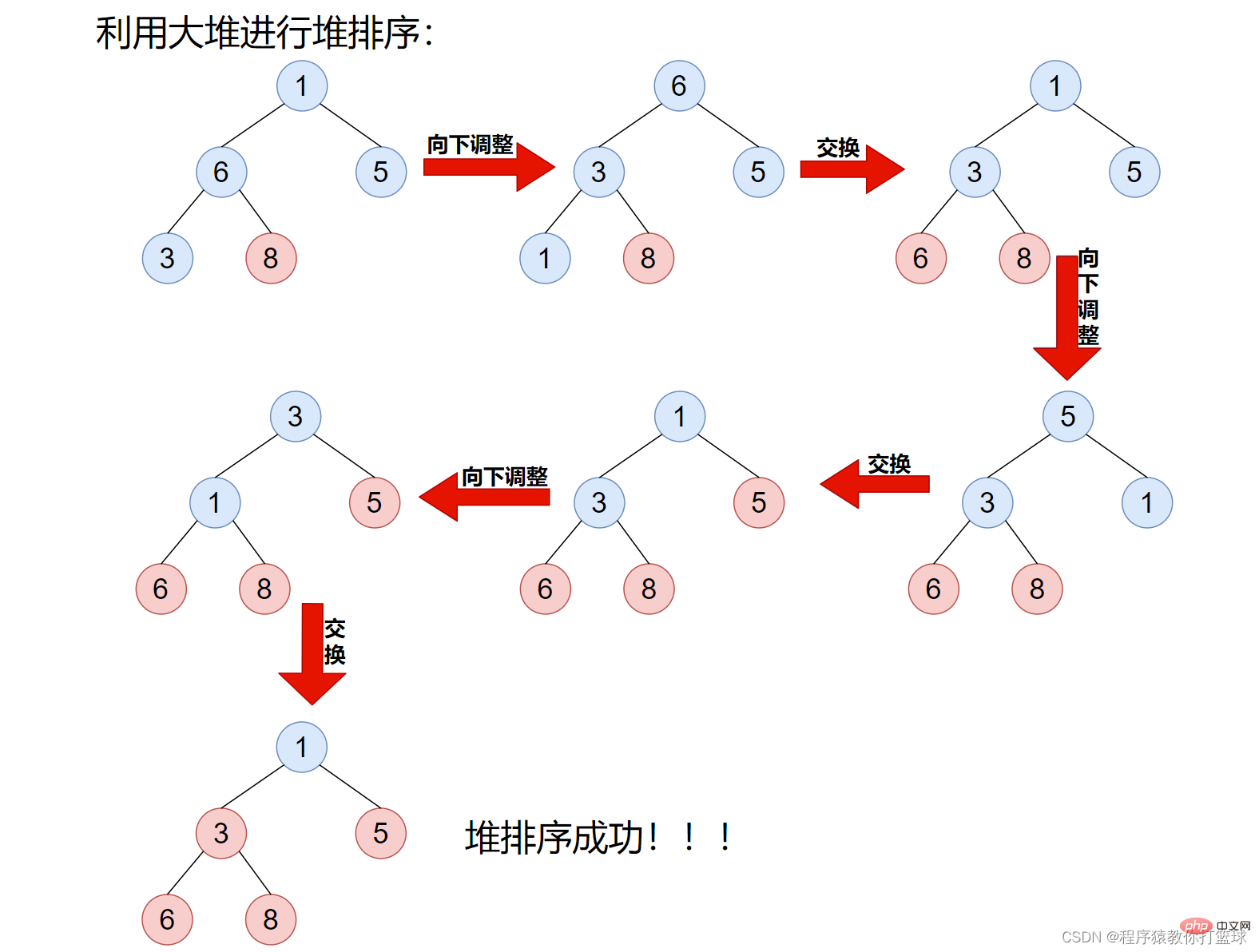
如上图步骤也很简单,先是将数组建成大堆,然后利用大堆来进行堆排序,首先将堆顶元素和最后一个元素交换,由此最大的元素就有序了,接着将该堆进行向下调整,使继续满足大堆性质,依次进行下去即可。
代码实现:
public void heapSort(int[] array) {
// 建大堆 从最后一个非叶子节点开始向下调整
// 非叶子节点下标 = (孩子节点下标 - 1) / 2
for (int parent = (array.length - 1 - 1) / 2; parent >= 0; parent--) {
shiftDown(array, parent, array.length);
}
// 建大堆完成后, 每次堆顶元素与最后一个元素交换, 锁定最大元素的位置
for (int len = array.length - 1; len > 0; len--) {
swap(array, 0, len); //根节点与最后一个元素交换
shiftDown(array, 0, len); //根节点位置向下调整
}
}
private void shiftDown(int[] array, int parent, int len) {
int child = parent * 2 + 1;
while (child < len) {
if (child + 1 < len && array[child + 1] > array[child]) {
child++;
}
// 判断父节点是否大于较大的孩子节点
if (array[parent] < array[child]) {
swap(array, parent, child);
// 更新下标的位置
parent = child;
child = parent * 2 + 1;
} else {
return;
}
}
}
- 时间复杂度分析:建堆的时间复杂度优先级队列那期有说过为 O(n),排序调整堆的时候,一共要调整 n-1 次,每次向下调整的时间复杂度是 logn,所以即 logn(n - 1),即 O(n*logn),加上面建堆的时间复杂度:O(n) + O(n*logn),最终时间复杂度也就是:O(n*logn)。
- 空间复杂度分析:O(1)
- 稳定性:不稳定
推荐学习:《java视频教程》
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Un article pour comprendre ce problème de pointage en JavaScript
- L'utilisation des propriétés calculées JavaScript et des propriétés de surveillance (écoute)
- Quelle est la différence entre passer par valeur et passer par référence en Java
- Plusieurs façons d'implémenter le multithreading en Java
- Quelles sont les trois formes de commentaires Java ?