
Maison >base de données >Oracle >Comment dédoublonner des données dans Oracle
Comment dédoublonner des données dans Oracle

- 青灯夜游original
- 2023-01-04 14:42:2513844parcourir
Méthode de suppression : 1. Utilisez le mot-clé distinct pour supprimer les doublons, syntaxe "SELECT DISTINCT field name FROM table name;"; 2. Utilisez la fonction de fenêtre row_number () over() pour supprimer les doublons ; dédupliquer, la syntaxe est "sélectionner le nom du champ dans le groupe de noms de table par nom de champ ;" 4. Utilisez rowid pour déduplicater les pseudo-colonnes.

L'environnement d'exploitation de ce tutoriel : système Windows 7, version Oracle 11g, ordinateur Dell G3.
Scénario commercial
Besoin d'interroger certaines données. Étant donné que trois tables sont requises pour les requêtes associées, les résultats de la requête sont les suivants :

Instruction SQL originale
SELECT D.ORDER_NUM AS "申请单号" , D.CREATE_TIME , D.EMP_NAME AS "申请人", (SELECT extractvalue(t1.row_data,'/root/row/FI13_wasteName') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "废料名称", (SELECT extractvalue(t1.row_data,'/root/row/FI13_units') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "单位", (SELECT extractvalue(t1.row_data,'/root/row/FI13_estimate') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "预估数量", (SELECT extractvalue(t1.row_data,'/root/row/FI13_stockRemoval') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "累计出库数量", (SELECT extractvalue(t1.row_data,'/root/row/FI13_receivingTime') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdCGYTX' ) AS "收购方收货时间", (SELECT extractvalue(t2.row_data,'/root/row/FI13_collectionTime') FROM dat_table_row t2 WHERE d.document_id = t2.document_id AND t2.table_id = 'dynamicRowsIdPTSJSKSJ' ) AS "实际收款时间" FROM dat_document d, dat_table_row dtr WHERE d.form_name ='FI14' AND d.document_id =dtr.document_id AND (D.DOCUMENT_STATUS != 'deleted' OR D.DOCUMENT_STATUS IS NULL ) --AND TO_CHAR(d.create_time,'yyyy-MM-dd') BETWEEN '2020-01-01' AND '2021-03-26' AND d.order_num = 'FI1420210708002' --FI1420210708002 ORDER BY d.CREATE_TIME DESC;
Méthode 1 : déduplication distincte.
SELECT DISTINCT peut être utilisé pour filtrer les lignes en double dans l'ensemble de résultats afin de garantir que les valeurs de la ou des colonnes spécifiées renvoyées dans la clause SELECT sont uniques. La syntaxe de l'instruction
DISTINCT est la suivante :
SELECT DISTINCT column_1,
column_2,
...
FROM
table_name;Exemple :
SELECT D.ORDER_NUM AS "申请单号" , D.CREATE_TIME , D.EMP_NAME AS "申请人", (SELECT extractvalue(t1.row_data,'/root/row/FI13_wasteName') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "废料名称", (SELECT extractvalue(t1.row_data,'/root/row/FI13_units') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "单位", (SELECT extractvalue(t1.row_data,'/root/row/FI13_estimate') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "预估数量", (SELECT extractvalue(t1.row_data,'/root/row/FI13_stockRemoval') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "累计出库数量", (SELECT extractvalue(t1.row_data,'/root/row/FI13_receivingTime') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdCGYTX' ) AS "收购方收货时间", (SELECT extractvalue(t2.row_data,'/root/row/FI13_collectionTime') FROM dat_table_row t2 WHERE d.document_id = t2.document_id AND t2.table_id = 'dynamicRowsIdPTSJSKSJ' ) AS "实际收款时间" FROM dat_document d, dat_table_row dtr WHERE d.form_name ='FI14' AND d.document_id =dtr.document_id AND (D.DOCUMENT_STATUS != 'deleted' OR D.DOCUMENT_STATUS IS NULL ) --AND TO_CHAR(d.create_time,'yyyy-MM-dd') BETWEEN '2020-01-01' AND '2021-03-26' AND d.order_num = 'FI1420210708002' --FI1420210708002 ORDER BY d.CREATE_TIME DESC;
Remarque : DISTINCT doit être suivi d'un champ ORDER BY. Oracle exécute d'abord DISTINCT pour supprimer les doublons, puis utilise ORDER BY pour le tri. Par conséquent, si le champ qui doit être trié dans ORDER BY n'est pas dans le champ après distinct, une erreur sera naturellement générée.
Le message d'erreur est le suivant :
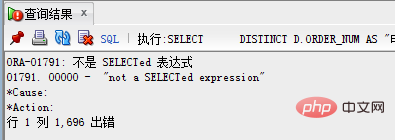
Méthode 2 : row_number() over()
Format de syntaxe
select * from (select A.*, row_number() over(partition by A.name1 order by A.name12 desc) rn from A) where rn = 1
Exemple
select * from ( select d.order_num as "申请单号" , d.create_time , d.emp_name as "申请人", (select extractvalue(t1.row_data,'/root/row/FI13_wasteName') from dat_table_row t1 where d.document_id = t1.document_id and t1.table_id = 'dynamicRowsIdPTFLXX' ) as "废料名称", (select extractvalue(t1.row_data,'/root/row/FI13_units') from dat_table_row t1 where d.document_id = t1.document_id and t1.table_id = 'dynamicRowsIdPTFLXX' ) as "单位", (select extractvalue(t1.row_data,'/root/row/FI13_estimate') from dat_table_row t1 where d.document_id = t1.document_id and t1.table_id = 'dynamicRowsIdPTFLXX' ) as "预估数量", (select extractvalue(t1.row_data,'/root/row/FI13_stockRemoval') from dat_table_row t1 where d.document_id = t1.document_id and t1.table_id = 'dynamicRowsIdPTFLXX' ) as "累计出库数量", (select extractvalue(t1.row_data,'/root/row/FI13_receivingTime') from dat_table_row t1 where d.document_id = t1.document_id and t1.table_id = 'dynamicRowsIdCGYTX' ) as "收购方收货时间", (select extractvalue(t2.row_data,'/root/row/FI13_collectionTime') from dat_table_row t2 where d.document_id = t2.document_id and t2.table_id = 'dynamicRowsIdPTSJSKSJ' ) as "实际收款时间", row_number() over(partition by d.order_num order by d.create_time desc) rn from dat_document d, dat_table_row dtr where d.form_name ='FI14' and d.document_id =dtr.document_id and (d.document_status != 'deleted' or d.document_status is null ) --AND TO_CHAR(d.create_time,'yyyy-MM-dd') BETWEEN '2020-01-01' AND '2021-03-26' and d.order_num = 'FI1420210708002' --FI1420210708002 ) where rn = 1;
Résultats de la requête
Méthode 3 : regrouper par
select 字段名 from 表名 group by 字段名;
Méthode 4 : Utiliser rowid (déduplication de pseudo-colonnes)
select id,name,age from test t1 where t1.rowid in (select min(rowid) from test t2 where t1.name=t2.name and t1.age=t2.age);
Tutoriel recommandé : "Tutoriel Oracle"
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!