
Maison >interface Web >Questions et réponses frontales >Partage d'outils : réaliser une gestion automatisée des points enterrés front-end
Partage d'outils : réaliser une gestion automatisée des points enterrés front-end

- 青灯夜游avant
- 2022-12-07 16:14:382214parcourir

Le suivi des points a toujours été une partie importante du projet H5, et les données de suivi des points sont une base importante pour l'amélioration ultérieure de l'activité et l'optimisation technique. [Apprentissage recommandé : front-end web, enseignement de la programmation]
Dans le travail quotidien, les étudiants en produit ou en entreprise demandent souvent : "Quels sont les points cachés de ce projet maintenant ?", "Quels sont les points cachés de ce projet ?" Où ? " Des questions comme celle-ci consistent essentiellement à poser et à vérifier le code une seule fois, ce qui est très inefficace.

Cela peut avoir quelque chose à voir avec la nature du point enterré lui-même. Les points enterrés sont des fonctions relativement indépendantes. Au fur et à mesure des itérations, il est difficile pour les développeurs de se souvenir de la fonction des points enterrés. À des fins d'autotest et de vérification, les développeurs doivent également trier les données cachées dans le projet. Ainsi, en combinaison avec le scénario actuel, un outil peut être mis en œuvre : en scannant le code, en analysant le code lié aux points enterrés, en le traitant et en le convertissant en données spécifiques pour une utilisation ultérieure dans d'autres plateformes de gestion.
Idée d'implémentation
Cet outil peut être grossièrement divisé en trois parties, JSDoc extraction des points enterrés, analyse des dépendances de routage et ESLint plug-in.
- JSDoc est un outil permettant de générer une documentation API basée sur des informations d'annotation en JavaScript. Combiné avec cette fonctionnalité de JSDoc, cet outil de suivi utilise JSDoc comme élément central pour générer les données de suivi dans le code.
- Le plug-in Webpack sert d'auxiliaire pour fournir des informations de routage pour JSDoc.
- Le plug-in ESLint est utilisé comme vérification finale pour garantir que le code enfoui dans le fichier contient les commentaires JSDoc correspondants.
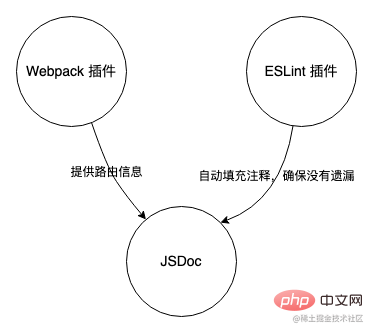
Points de balisage JSDoc personnalisés
Nous savons que JSDoc peut générer un document basé sur des commentaires dans le code. Tout d'abord, nous personnalisons une balise JSDoc pour la marquer comme commentaire masqué, afin que l'interférence d'autres commentaires puisse être filtrée lors du traitement ultérieur. En combinant le code utilisé dans des projets spécifiques, un organigramme comme celui-ci peut être dessiné :

Voici le processus spécifique de mise en œuvre du code.
Écrivez un plug-in JSDoc et personnalisez une balise :
// jsdoc.plugin.js
// 自定义一个 @log,含有 @log 才是埋点的注释
exports.defineTags = function (dictionary) {
dictionary.defineTag('log', {
canHaveName: true,
onTagged: function (doclet, tag) {
doclet.meta.log = tag.text;
},
});
};Analysez les fichiers .ts et .vue.
// jsdoc.plugin.js
exports.handlers = {
beforeParse: function (e) {
// 对文件预处理
if (/.vue/.test(e.filename)) {
// 解析 vue 文件
const component = compiler.parseComponent(e.source);
// 获取 vue 文件的 script 代码
const ast = parse.parse(component.script.content, {
// ...
});
}
if (/.ts/.test(e.filename)) {
// ts 转 js
}
},
};Modèle JSDoc personnalisé.
// publish.js
exports.publish = function (taffyData, opts, tutorials) {
// ...
data().each(function (doclet) {
// 有 log 这个 tag 的才是埋点注释
if (doclet.meta && doclet.meta.log) {
doclet.tags?.forEach((item) => {
// 获取对应的路由地址
});
// 拿到埋点数据
logData.push({});
}
});
// 输出 md 文档
fs.writeFileSync(outpath, mdContent, 'utf8');
};À ce stade, tous les points cachés dans le code peuvent être complètement affichés. À ce stade, jetons un coup d'œil aux capacités actuelles de cet outil :
- Extrayez automatiquement les informations sur les points enterrés et générez des documents sur les points enterrés : ✅
- Ajoutez automatiquement des balises personnalisées (@log) aux commentaires sur les points enterrés : ❌
- Automatiquement ajouter des commentaires sur les points enfouis Ajouter des informations sur les points enfouis signalés : ❌
- Ajouter automatiquement des informations de routage aux commentaires sur les points enfouis : ❌
- Ajouter automatiquement des informations de description des points enfouis aux commentaires sur les points enfouis : ❌
- Inviter automatiquement les codes de points enfouis non commentés : ❌
Réussi Nous pouvons voir à partir de l'analyse ci-dessus :
- Vous devez ajouter manuellement des commentaires à chaque point enterré
- Vous devez vérifier manuellement l'itinéraire correspondant à chaque point enterré
- Et si vous oubliez d'ajouter des commentaires aux points enterrés ?
L'intention initiale de la création de cet outil est d'économiser un travail répétitif et fastidieux. S'il ajoute une autre charge de travail afin de saisir automatiquement un document à partir du code, cela en vaudra largement la peine. Grâce à l'analyse de ces problèmes, les solutions suivantes peuvent être dégagées :
- Vous devez ajouter manuellement des commentaires à chaque point caché-> Remplissez automatiquement le code-> Fonction de correction ESLint/plug-in VSCode
- Vous avez besoin pour vérifier manuellement chacun L'itinéraire correspondant à chaque point enterré -> Trouver automatiquement l'itinéraire correspondant au composant -> Analyse des dépendances Webpack
- Que dois-je faire si j'oublie de commenter le point caché ? -> Il y aura un rappel si vous oubliez d'écrire un commentaire -> Plug-in ESLint
À ce stade, la solution au problème est devenue claire. Examinons ensuite le processus d'implémentation du plug-in webpack et du plug-in ESLint.
Analyse des dépendances d'itinéraire
webpack lui-même est livré avec analyse des dépendances, et vous pouvez facilement obtenir la relation parent-enfant entre les composants.
compiler.hooks.normalModuleFactory.tap('routeAnalysePlugin', (nmf) => {
nmf.hooks.afterResolve.tapAsync('routeAnalysePlugin', (result, callback) => {
const { resourceResolveData } = result;
// 子组件
const path = resourceResolveData.path;
// 父组件
const fatherPath = resourceResolveData.context.issuer;
// 只获取 vue 文件的依赖关系
if (/.vue/.test(path) && /.vue/.test(fatherPath)) {
// 将组件间的父子关系存到变量中
}
});
});Mettez les dépendances entre les composants dans le format de données souhaité
[
{
"path": "src/views/register-v2/index.vue",
"deps": [
{
"path": "src/components/landing-banner/index.vue",
"deps": []
}
]
}
// ...
]组件之间的依赖关系有了,接下来就是找到组件和路由的对应关系,这里我们用 AST 来解析路由文件,获取路由和组件的对应关系。
// 遍历路由文件
for (let i = 0; i < this.routePaths.length; i++) {
// ...
traverse(ast, {
enter(path) {
// 找出组件和路由的对应关系
path.node.properties.forEach((item) => {
// 组件
if (item.key.name === 'component') {
}
// 路由地址
if (item.key.name === 'path') {
}
});
},
});
}同样地,把组件与路由的映射关系拼成合适的数据格式。
{
"src/views/register-v3/index.vue": "/register"
// ...
}再将路由的映射关系和组件间的依赖关系整合到一起,得出每个组件与路由的对应关系。
{
"src/components/landing-banner/index.vue": [
"/register_v2",
"/register"
//...
]
// ...
}因为使用 AST 遍历的方式来解析路由文件,目前支持的解析的路由文件写法有以下四种,基本上满足了当前的场景:
const page1 = (resolve) => {
require.ensure(
[],
() => {
resolve(require('page1.vue'));
},
'page1',
);
};
const page2 = () =>
import(
/* webpackChunkName: "page2" */
'page2.vue'
);
export default [
{ path: '/page1', component: page1 },
{ path: '/page2', component: page2 },
{
path: '/page3',
component: (resolve) => {
require.ensure(
[],
() => {
resolve(require('page3.vue'));
},
'page3',
);
},
},
{
path: '/page4',
component: () =>
import(
/* webpackChunkName: "page4" */
'page4.vue'
),
},
];
再得到了上面的对应关系之后,可以把埋点数据放到传到埋点管理平台上,从而实现一键查询:
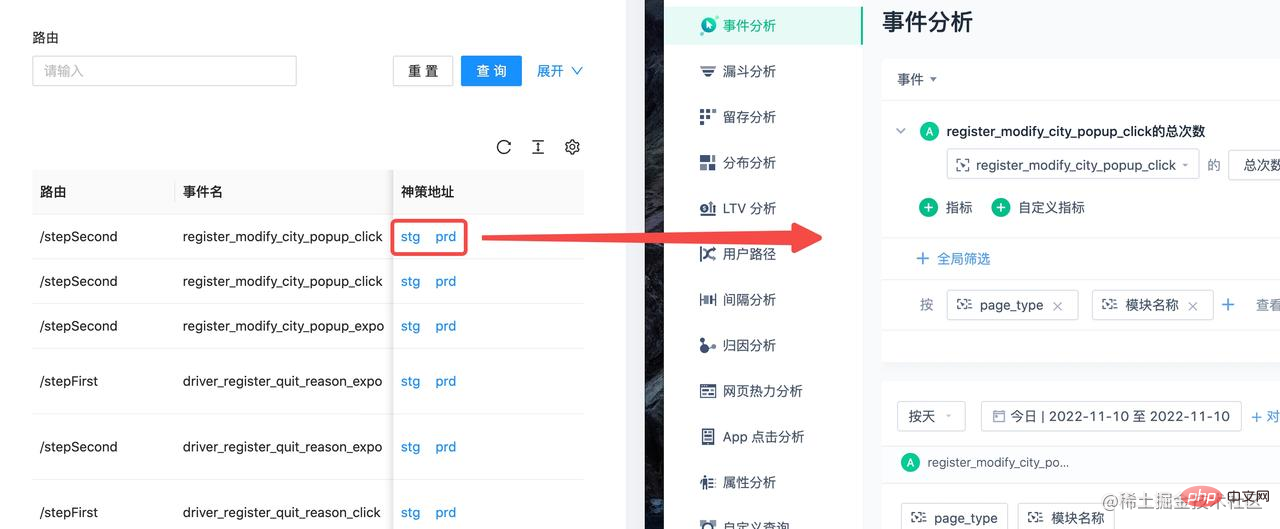
编写 ESLint 插件
先来看看代码中埋点上报的三种方式:
// 神策 sdk
sensors.track('xxx', {});
// 挂载到 Vue 实例中
this.$sa.track('xxx', {});
// 装饰器
@SensorTrack('xxx', {})观察上面三种方式,可以知道埋点上报是通过 track 函数和 SensorTrack 函数,所以我们的 ESLint 插件对这两个函数进行校验。
function create(context) {
// 调用 track 函数的对象
const checkList = ['sensor', 'sensors', '$sa', 'sa'];
return {
Literal: function (node) {
// ...
// 调用埋点函数而缺少注释时
if (
isNoComment &&
((isTrack && isSensor) || (is$Track && isThisExpression))
) {
context.report({
node,
messageId: 'missingComment',
fix: function (fixer) {
// 自动修复
},
});
}
// 使用修饰器但没有注释时
if (
callee.name === 'SensorTrack' &&
sourceCode.getCommentsBefore(node).length === 0
) {
context.report({
node,
messageId: 'missingComment',
fix: function (fixer) {
// 自动修复
},
});
}
},
};
}看下完成后的效果:
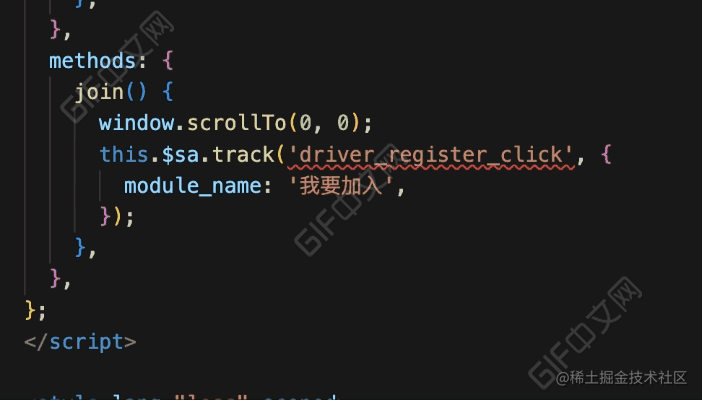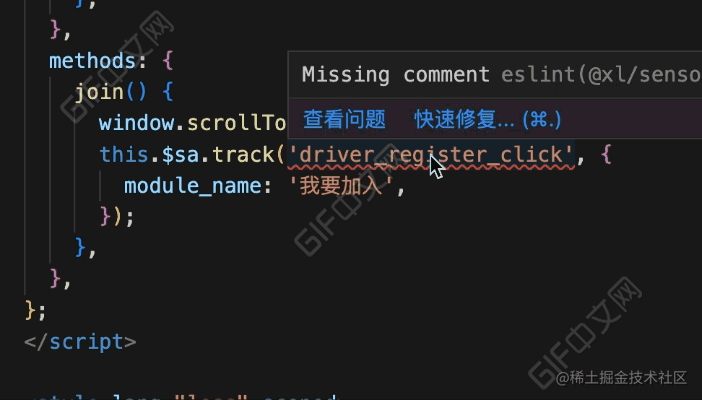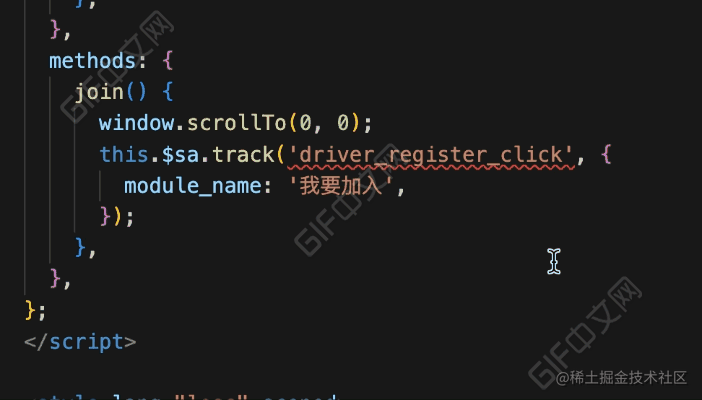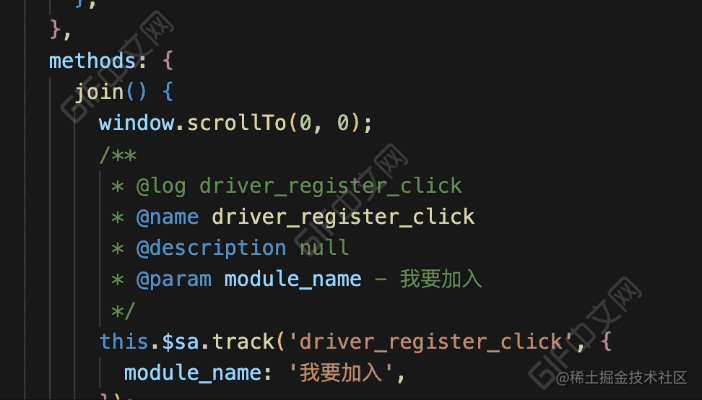
效果对比
我们再来对比下优化前后的区别:
| 优化前 | 优化后 | |
|---|---|---|
| 自动提取埋点信息,生成埋点文档 | ✅ | ✅ |
| 自动给埋点注释添加自定义 tag(@log) | ❌ | ✅ |
| 自动给埋点注释添加上报的埋点信息 | ❌ | ✅ |
| 自动给埋点注释添加路由信息 | ❌ | ✅ |
| 自动给埋点注释添加埋点描述信息 | ❌ | ❌ |
| 自动提示没有注释的埋点代码 | ❌ | ✅ |
优化之后除了整个流程基本都由工具自动完成,剩下一个埋点描述信息。因为埋点的描述信息只是为了让我们更好地理解这个埋点,本身并不在上报的代码中,所以工具没有办法自动生成,但是我们可以直接在产品提供的埋点文档中拷贝过来完成这一步。
总结
在项目中接入这个工具之后,可以快速地知道项目的埋点有哪些以及各个埋点所在的页面,也方便我们对埋点的梳理,同时利用导出的埋点数据开发后台应用,有效地提升了开发者效率。
这个工具的实现是在 JSDoc、webpack 和 ESLint 插件的加持下水到渠成的,说是水到渠成是因为一开始的想法只是做到第一步,先有个一键查询功能和能够输出一份文档用着先。但是第一版出来后发现要手动去处理这些埋点注释还是比较繁琐,恰巧平常开发中常见的 webpack 插件和 ESLint 插件可以很好地解决这些问题,于是便有路由依赖分析和 ESLint 插件。像是《牧羊少年奇幻之旅》中所说的,“如果你下定决心要做一件事情,整个宇宙都会合力帮助你。”
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Partagez deux bibliothèques frontales Vue capables de dessiner des organigrammes Flowable
- [Compétences avancées] Neuf questions d'entretien frontales pour vous aider à consolider vos connaissances !
- [Compilation et partage] 75 points de test haute fréquence en CSS pour les entretiens front-end
- Parlons en profondeur de l'idée du front-end de limiter les captures d'écran des utilisateurs
- Le Web3.0 arrive ! Est-ce convivial pour le front-end ?