
Maison >base de données >tutoriel mysql >13 mots-clés que vous devez connaître pour apprendre MySQL (partage de résumé)
13 mots-clés que vous devez connaître pour apprendre MySQL (partage de résumé)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-11-30 17:12:492714parcourir
Cet article vous apporte des connaissances pertinentes sur mysql, qui présente principalement des problèmes liés aux mots-clés, notamment trois formes normales, des jeux de caractères, des quantités personnalisées, des vues, des tables de partition, etc., comme suit Jetons un coup d'œil, j'espère que ce sera le cas être utile à tout le monde.

Apprentissage recommandé : Tutoriel vidéo mysql
1. Trois formes normales
- Première forme normale : Chaque colonne de chaque table doit conserver son atomicité, c'est-à-dire que chaque colonne de la table ne peut pas être divisée ;
- Deuxième forme normale : sur la base de la satisfaction de la première forme normale, chaque table doit conserver son unicité, c'est-à-dire que les champs de clé non primaire de la table dépendent entièrement des champs de clé primaire ;
- Troisième forme normale : après avoir satisfait ; la première forme normale Sur la base de la forme normale et de la deuxième forme normale, les relations transitives ne peuvent pas être générées dans le tableau et la redondance dans le tableau doit être éliminée
2. Jeu de caractères
Le jeu de caractères spécifie le stockage ; format des caractères dans la base de données, comme la prise en compte de la quantité d'espace, des caractères pris en charge, etc. Différents jeux de caractères ont des règles de codage différentes. Dans certains cas, il existe même des règles de relecture qui font référence au tri d'un jeu de caractères. Dans le fonctionnement, la maintenance et l'utilisation de la base de données MySQL, il est très important de sélectionner le caractère approprié. Si la sélection est inappropriée, les performances de la base de données peuvent au moins être affectées et le stockage des données peut être tronqué dans les cas graves.
Il existe principalement quatre jeux de caractères MySQL courants :
| Jeu de caractères | Longueur | Instructions |
|---|---|---|
| GBK | 2 | prend en charge le chinois, mais n'est pas un jeu de caractères international. |
| UTF-8 | 3 | prend en charge des scénarios mixtes chinois et anglais et est un jeu de caractères universel international |
| latin1 | 1 | Jeu de caractères MySQL par défaut |
| utf8mb4 | 4 | entièrement compatible avec UTF- 8, utilisez quatre octets pour stocker plus de caractères |
Dans le développement et l'exploitation de la base de données MySQL, les règles de sélection du jeu de caractères sont les suivantes :
- Si le système est développé pour des entreprises étrangères et doit gérer différents pays et langues, vous devez choisir utf-8 ou utf8mb4 ; Si vous n'avez besoin de prendre en charge que le chinois, s'il n'y a pas d'entreprise étrangère, pour des raisons de performances, GBK peut être utilisé
3. Variables personnalisées Une variable personnalisée est un conteneur temporaire utilisé pour stocker du contenu et existe dans tout le pays ; tout le processus de connexion à MySQL. Il peut être défini à l’aide de set.
SET @last_week := CURRENT_DATE-INTERVAL 1 WEEK;SELECT id,name from user where create_time > @last_week;
Remarques sur l'utilisation de variables personnalisées :
- Les requêtes utilisant des variables personnalisées ne peuvent pas utiliser le cache ;
- Vous ne pouvez pas utiliser de variables personnalisées lorsque des constantes ou des identifiants sont utilisés, tels que des noms de table, des noms de colonnes et dans la clause limit ;
- Le cycle de vie des variables personnalisées est valide dans une seule connexion, et elles ne peuvent pas être utilisées pour la communication entre les connexions
- Évitez les requêtes répétées pour les données qui viennent d'être mises à jour
Si vous mettez à jour la ligne ; En même temps, si je souhaite obtenir des informations sur cette ligne, que puis-je faire pour éviter les requêtes répétées ?
Cela se fait généralement :
update user set update_time = now() where id = 1;select update_time from user where id = 1;
L'utilisation de variables personnalisées peut l'optimiser :
update user set update_time = now() where id = 1 and @now := now();select @now;
Cela ressemble toujours à deux requêtes, mais la deuxième requête n'a pas besoin d'accéder à des tables de données, elle sera donc beaucoup plus rapide.
4. Choisissez des types de données optimisés MySQL prend en charge de nombreux types de données, et choisir le bon type de données est crucial pour obtenir des performances élevées.
(1) Plus petit En général, vous devriez essayer d'utiliser des types de données plus petits. Les types de données plus petits sont généralement plus rapides car ils occupent moins de disque, de mémoire et de cache CPU, qui sont nécessaires au traitement.
(2) Plus simple Les types de données simples nécessitent généralement moins de cycles CPU et les entiers sont moins chers que les types de chaînes car les jeux de caractères et les règles de validation rendent les comparaisons de caractères plus complexes que les comparaisons d'entiers.
(3) Essayez d'éviter NULLDe nombreuses tables contiennent des colonnes pouvant être NULL, même si l'application n'a pas besoin d'enregistrer NULL, car NULL est l'attribut par défaut de la colonne, généralement, il est préférable de spécifier Column n'est PAS NULL.
Si la requête contient des colonnes NULLable, il est plus difficile à optimiser pour MySQL car les colonnes NULLable rendent les index, les statistiques d'index et les comparaisons de valeurs plus complexes. Les colonnes compatibles NULL utilisent plus d'espace de stockage et nécessitent un traitement spécial dans MySQL. Lorsque les colonnes compatibles NULL sont indexées, chaque enregistrement d'index nécessite un octet supplémentaire, ce qui peut même entraîner une taille fixe dans MyISAM. .
5. Vue Une vue (view) est une table virtuelle, une table logique qui ne contient pas elle-même de données. Enregistré dans le dictionnaire de données en tant qu'instruction select. Pour les requêtes complexes sur plusieurs tables, l'utilisation de vues peut simplifier les requêtes. Lorsque la vue utilise une table temporaire, la condition Where ne peut pas être utilisée et l'index ne peut pas être utilisé.
La vue table unique est généralement utilisée pour les requêtes et les modifications, ce qui modifiera les données de la table de base. La vue multi-tables est généralement utilisée pour les requêtes et ne modifiera pas les données de la table de base.
Le but de l'utilisation des vues est d'assurer la sécurité des données et d'améliorer l'efficacité des requêtes.
Avantages des vues :
- Les utilisateurs qui utilisent des vues n'ont pas besoin de se soucier de la structure, des conditions d'association et des conditions de filtrage des tables correspondantes suivantes. Pour les utilisateurs, il s'agit déjà d'un ensemble de résultats de conditions composées filtrées.
- Les utilisateurs utilisant des vues ne peuvent accéder qu'aux ensembles de résultats qu'ils sont autorisés à interroger. La gestion des autorisations de la table ne peut pas être limitée à une certaine ligne ou colonne, mais elle peut être facilement réalisée via les vues.
- Une fois la structure de la vue déterminée, l'impact des modifications de la structure de la table sur les utilisateurs peut être protégé. L'ajout de colonnes à la table source n'a aucun impact sur la modification des noms de colonnes dans la table source ; en modifiant la vue, ce qui n'aura aucun impact sur l'influence des visiteurs.
6. Tables de cache et tables récapitulatives Parfois, le meilleur moyen d'améliorer les performances est de sauvegarder les données redondantes dérivées dans la même table. Parfois, vous devez également créer une table récapitulative ou une table de cache complètement indépendante.
La table cache est utilisée pour stocker des données faciles à obtenir mais lentes- La table récapitulative est utilisée pour sauvegarder les données agrégées et interrogées à l'aide de l'instruction group by
- Pour la table cache, si la table principale ; table utilise InnoDB, utilisez En tant que moteur de mise en cache des tables, MyISAM obtiendra une empreinte d'index plus petite et pourra effectuer une recherche en texte intégral.
Lorsque vous utilisez des tables de cache et des tables récapitulatives, vous devez décider si vous souhaitez conserver les données en temps réel ou les reconstruire périodiquement. La meilleure solution dépend de l'application, mais une reconstruction régulière permet non seulement d'économiser des ressources, mais empêche également la table d'être fragmentée et d'avoir des index entièrement organisés de manière séquentielle.
Lors de la reconstruction des tables récapitulatives et des tables de cache, il est généralement nécessaire de s'assurer que les données sont toujours disponibles pendant les opérations. Cela doit être réalisé en utilisant une table fantôme. La table fantôme fait référence à une table créée derrière la table réelle. la construction est terminée. Après l'opération de table, la table fantôme et la table d'origine peuvent être commutées via une opération de renommage atomique.
Afin d'améliorer la vitesse de lecture, nous construisons souvent des index supplémentaires, ajoutons des colonnes redondantes ou même créons des tables de cache et des tableaux récapitulatifs. Ces méthodes augmenteront la charge d'écriture et nécessiteront des tâches de maintenance supplémentaires, mais lors de la conception d'une base de données hautes performances. , Il s'agit de techniques courantes qui, bien que ralentissant les opérations d'écriture, améliorent considérablement les performances de lecture.
7. Table de partition
Normalement, les données d'une même table sont stockées ensemble au niveau physique. À mesure que l’entreprise se développe, lorsque la quantité de données dans une même table devient trop importante, cela entraînera des désagréments en matière de gestion. La fonction de partition peut diviser physiquement une table en plusieurs partitions en fonction de certaines règles. Plusieurs partitions peuvent être gérées séparément ou même stockées sur différents disques/systèmes de fichiers pour améliorer l'efficacité.
Avantages de la table de partition :
Les données peuvent être stockées sur des disques, adaptées au stockage de grandes quantités de données
-
La gestion des données est très pratique, l'exploitation des données dans des partitions, sans affecter le fonctionnement normal des autres ; partitions ;
Vous pouvez restreindre la portée de la requête et améliorer les performances de la requête en verrouillant la fonction de partition pendant la requête ;
8. Les clés étrangères exigent généralement que chaque fois que vous modifiez les données, elles doivent être effectuées. être effectué dans une autre table. Une opération de requête supplémentaire, bien qu'InnoDB force les clés étrangères à utiliser des index, il ne peut toujours pas éliminer la surcharge de cette vérification de contrainte. Si la sélectivité de la clé étrangère est très faible, cela se traduira par un index très sélectif.
Cependant, dans certains scénarios, les clés étrangères amélioreront certaines performances. Par exemple, si vous souhaitez vous assurer que deux tables liées ont toujours des données cohérentes, l'utilisation de clés étrangères est bien plus performante que la vérification de la cohérence dans l'application. Les clés étrangères sont également plus efficaces pour supprimer et mettre à jour les données associées que pour les conserver dans l'application. Cependant, les opérations de maintenance des clés étrangères sont effectuées ligne par ligne, et ces mises à jour seront plus lentes que les suppressions et mises à jour par lots.
Les contraintes de clé étrangère nécessitent un accès supplémentaire à d'autres tables lors des requêtes, ce qui nécessite des verrous supplémentaires. Si un enregistrement est écrit dans la table enfant, la contrainte de clé étrangère amènera InnoDB à vérifier l'enregistrement correspondant de la table parent, ce qui signifie que l'enregistrement correspondant de la table parent doit être verrouillé pour garantir que cet enregistrement ne sera pas perdu. une fois la transaction terminée. Cela peut entraîner des attentes de verrouillage supplémentaires et même des blocages. Puisqu’il n’existe pas d’accès direct à ces tables, ce type de blocage est difficile à résoudre.
Ainsi, dans de nombreux projets en cours, les clés étrangères ne sont plus utilisées pour des raisons de performances.
9. Cache de requêtes Le cache de requêtes MySQL enregistre les résultats complets renvoyés par la requête. Lorsque la requête atteint le cache, MySQL renvoie les résultats immédiatement, en ignorant le processus d'analyse, d'optimisation et d'exécution.
 Le système de cache de requête suivra chaque table impliquée dans la requête. Si ces tables changent, toutes les données mises en cache liées à cette table seront invalides. Ce mécanisme semble relativement inefficace car la table de données peut ne pas avoir de changement. impact sur les résultats de la requête, mais le coût de cette implémentation simple est très faible, ce qui est très important pour un système très occupé.
Le système de cache de requête suivra chaque table impliquée dans la requête. Si ces tables changent, toutes les données mises en cache liées à cette table seront invalides. Ce mécanisme semble relativement inefficace car la table de données peut ne pas avoir de changement. impact sur les résultats de la requête, mais le coût de cette implémentation simple est très faible, ce qui est très important pour un système très occupé.
(1) Comment MySQL détermine-t-il un accès au cache ? Pour déterminer s'il s'agit d'un accès au cache, MySQL ne l'analysera pas, mais utilisera directement l'instruction SQL et d'autres informations originales envoyées par le client. Toute différence de caractères, tels que des espaces ou des commentaires, entraînera des échecs de cache. En général, l’utilisation de règles de codage unifiées est une bonne habitude et permettra à votre système de fonctionner plus rapidement. Lorsqu'il y a des données incertaines dans l'instruction de requête, elles ne seront pas mises en cache, comme la fonction now(). En fait, si le cache contient des fonctions définies par l'utilisateur, des fonctions stockées, des variables utilisateur, des tables temporaires, des tables système MySQL ou des tables contenant des autorisations au niveau des colonnes, elles ne seront pas mises en cache.
(2) Soyez prudent lorsque vous utilisez le cache de requêtes
L'ouverture du cache de requêtes entraînera une consommation supplémentaire aux opérations de lecture et d'écriture :
La requête de lecture doit d'abord vérifier si elle atteint le cache avant de s'exécuter ;
- Si les requêtes de lecture peuvent être mises en cache, donc une fois l'exécution terminée, si MySQL constate que la requête n'existe pas dans le cache, il stockera les résultats dans le cache des requêtes, ce qui entraînera une consommation système supplémentaire ;
- a également un impact sur les opérations d'écriture, car lors de l'écriture de données dans une table, MySQL doit invalider tous les paramètres de cache de la table correspondante. Si le cache de requêtes est très volumineux ou fragmenté, cette opération peut entraîner une consommation importante du système
- Cependant, le cache de requêtes améliorera quand même les performances du système ; Cependant, la consommation supplémentaire mentionnée ci-dessus peut également continuer à augmenter. De plus, l'opération de cache de requêtes est une opération de verrouillage exclusive, et cette consommation n'est pas minime. Pour les utilisateurs d'InnoDB, certaines caractéristiques des transactions limiteront l'utilisation du cache de requêtes. Lorsqu'une instruction modifie une table dans une transaction, MySQL invalidera le paramètre du cache de requêtes correspondant à la table avant que la transaction ne soit soumise. Par conséquent, les transactions de longue durée réduiront considérablement le taux de réussite du cache de requêtes.
Réduire le trafic réseau
Améliorer la vitesse d'exécution
Réduire le nombre de connexions à la base de données
Haute sécurité
-
Haute réutilisabilité
Mauvaise portabilité
(3) Comment analyser et configurer le cache de requêtes
10. Procédure stockée
Une procédure stockée est un ensemble d'instructions SQL pour remplir une fonction spécifique. Elle est compilée et enregistrée dans la base de données en spécifiant le nom. de la procédure stockée. Et donnez la valeur du paramètre, vous pouvez également renvoyer le résultat.
Avantages des procédures stockées :
Inconvénients des procédures stockées :
11. Transactions
Les instructions au sein d'une transaction sont soit toutes exécutées, soit pas exécutées du tout. Les transactions ont des caractéristiques ACID, qui représentent l'atomicité, la cohérence, l'isolement et la durabilité.
(1) Atomicité
Une transaction doit être considérée comme une unité de travail minimale indivisible. Toutes les opérations de la transaction entière sont soit entièrement exécutées et soumises avec succès, soit toutes sont annulées sans échec.
(2) Cohérence
La base de données passe toujours d'un état cohérent à un autre état cohérent.
(3) Isolement
Les modifications apportées par une transaction ne sont pas visibles par les autres transactions avant d'être finalement soumises.
(4) Durabilité
Une fois la transaction soumise, les modifications apportées seront enregistrées définitivement dans la base de données.
12. Index
L'index est une structure de données utilisée par le moteur de stockage pour trouver rapidement des enregistrements. Je pense que le point de connaissance le plus important de la base de données est l'index.
Les moteurs de stockage utilisent les index B-Tree de différentes manières, et leurs performances sont également différentes, chacune avec ses propres avantages et inconvénients. Par exemple, MyISAM utilise la technologie de compression de préfixe pour réduire la taille de l'index, mais InnoDB le stocke dans le format de données d'origine. Les index MyISAM référencent les lignes indexées par l'emplacement physique des données, tandis qu'InnoDB référence les lignes indexées par leur clé primaire.
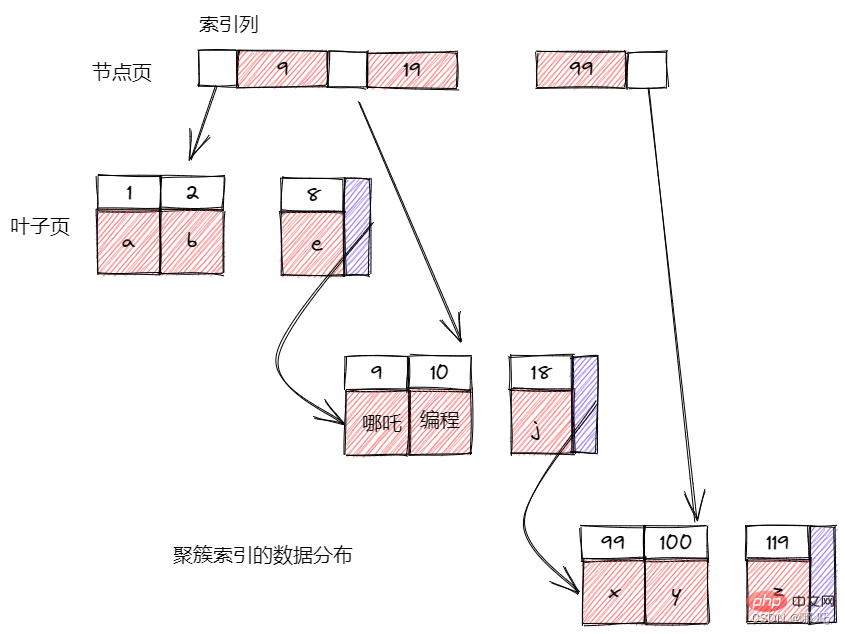
B-Tree signifie généralement que toutes les valeurs sont stockées dans l'ordre et que chaque page feuille est à la même distance de la racine.
L'index B-Tree peut accélérer l'accès aux données, car le moteur de stockage n'a plus besoin d'effectuer une analyse complète de la table pour obtenir les données requises, mais recherche plutôt à partir du nœud racine de l'index. Les emplacements du nœud racine stockent des pointeurs vers les nœuds enfants, et le moteur de stockage effectue une recherche vers le bas en fonction de ces pointeurs. En comparant la valeur de la page du nœud avec la valeur que vous recherchez, vous pouvez trouver des pointeurs appropriés vers les nœuds enfants inférieurs. Ces pointeurs définissent en fait les limites supérieure et inférieure des valeurs dans la page du nœud enfant. Finalement, le moteur de stockage trouve la valeur correspondante ou l'enregistrement n'existe pas.
Les nœuds feuilles sont spéciaux, leurs pointeurs pointent vers les données indexées, pas vers d'autres pages de nœuds. B-Tree organise et stocke les colonnes d'index de manière séquentielle, il est donc très approprié pour rechercher des données de plage. B-Tree convient à la recherche de valeurs de clé complètes, de plages de valeurs de clé ou de préfixes de clé.
Étant donné que les nœuds de l'arborescence d'index sont ordonnés, en plus de rechercher par valeur, l'index peut également être utilisé pour trier par opérations dans les requêtes. D'une manière générale, si un B-Tree peut trouver une valeur d'une certaine manière, il peut également être utilisé pour trier de cette manière.
13. Index de texte intégral
Le but de l'index de texte intégral est de filtrer les requêtes par correspondance de mots clés, basées sur des requêtes de similarité, plutôt que sur des requêtes précises.
L'index de texte intégral utilise la technologie de segmentation de mots pour analyser la fréquence et l'importance de certains mots-clés dans le texte et filtre intelligemment les résultats souhaités selon un certain algorithme.
L'index de texte intégral est généralement utilisé pour interroger certains mots-clés dans des chaînes, tels que char, varchar et text. Il prend également en charge l'index de texte intégral en langage naturel et l'index de texte intégral booléen.
Apprentissage recommandé : Tutoriel vidéo mysql
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- MySQL Explication détaillée du mécanisme d'isolation des transactions et des principes de mise en œuvre
- Comment interroger l'année en cours dans MySQL
- Explication détaillée de l'ajout, de la suppression, de la modification de MySQL et des pièges courants
- Comment générer une erreur MySQL en PHP
- Réponse à l'entretien : il est préférable que chaque table MySQL ne contienne pas plus de 20 millions de données, n'est-ce pas ?