
Maison >développement back-end >Golang >Une brève analyse des fermetures à Golang
Une brève analyse des fermetures à Golang

- 青灯夜游avant
- 2022-11-21 20:36:036917parcourir

1. Qu'est-ce que la fermeture ?
Avant de parler de fermetures, préparons le terrain :
- Programmation fonctionnelle
- Portée de la fonction
- Relation d'héritage de portée
[Recommandations associées : Tutoriel vidéo Go]
1.1 Connaissances préalables
1.2.1 Programmation fonctionnelle
La programmation fonctionnelle est un paradigme de programmation, une façon d'aborder les problèmes. Chaque fonction est conçue pour être organisée en fonctions plus grandes à l'aide de petites fonctions. Fonctions, les paramètres des fonctions sont également des fonctions, et les fonctions renvoyées par les fonctions sont également des fonctions. Nos paradigmes de programmation courants sont :
- Programmation impérative :
- L'idée principale est : faire attention aux étapes exécutées par l'ordinateur, c'est-à-dire dire à l'ordinateur étape par étape quoi faire en premier, puis quoi faire.
- Normalisez d'abord les étapes pour résoudre le problème et résumez-le dans un certain algorithme, puis écrivez un algorithme spécifique pour l'implémenter. Généralement, tant que le langage prend en charge le paradigme de programmation procédurale, nous pouvons l'appeler un langage de programmation procédurale, comme BASIC, C, etc.
- Programmation déclarative :
- L'idée principale est la suivante : dire à l'ordinateur ce qu'il doit faire, mais sans spécifier comment le faire, comme SQL, HTML et CSS pour la programmation Web.
- Programmation fonctionnelle :
- Se concentre uniquement sur ce qu'il faut faire plutôt que sur comment le faire. Il y a une trace de programmation déclarative, mais elle se concentre davantage sur le principe de « la fonction vient en premier », c'est-à-dire que les fonctions peuvent apparaître. n'importe où Lieux, paramètres, variables, valeurs de retour, etc.
La programmation fonctionnelle peut être considérée comme l'opposé de la programmation orientée objet. Généralement, seuls certains langages de programmation mettent l'accent sur une méthode de programmation spécifique. La plupart des langages sont des langages multi-paradigmes et peuvent en prendre en charge plusieurs. différentes méthodes de programmation telles que JavaScript, Go, etc.
La programmation fonctionnelle est une façon de penser qui considère les opérations informatiques comme le calcul de fonctions. En fait, je devrais parler de programmation fonctionnelle puis de fermetures, car les fermetures elles-mêmes sont une des fonctions. les caractéristiques de la programmation formelle.
En programmation fonctionnelle, une fonction est un objet de première classe, ce qui signifie qu'une fonction peut être utilisée comme valeur de paramètre d'entrée pour d'autres fonctions, peut également renvoyer une valeur de la fonction, être modifiée ou affectée à une variable. (Wikipédia)
Généralement, les langages de programmation fonctionnels purs ne permettent pas l'utilisation directe de l'état du programme et des objets mutables. La programmation fonctionnelle elle-même consiste à éviter d'utiliser l'état partagé, l'état variable et à éviter autant que possible les effets secondaires. possible .
La programmation fonctionnelle présente généralement les caractéristiques suivantes :
Les fonctions sont des citoyens de première classe : les fonctions sont placées en premier et peuvent être utilisées comme paramètres, peuvent se voir attribuer des valeurs, peuvent être transmises et peuvent être utilisées comme valeurs de retour.
Aucun effet secondaire : la fonction doit rester purement indépendante, ne peut pas modifier la valeur des variables externes, et ne modifie pas les états externes.
Transparence de référence : le fonctionnement de la fonction ne dépend pas de variables ou d'états externes. Avec les mêmes paramètres d'entrée, la valeur de retour doit dans tous les cas être la même.
1.2.2 Function Scope
Scope (scope), un concept de programmation De manière générale, les noms utilisés dans un morceau de code de programme ne sont pas toujours valides/disponibles, ce qui limite la portée du code pour. la disponibilité d'un nom est la portée du nom.
En termes simples, la portée d'une fonction fait référence à la plage dans laquelle une fonction peut fonctionner. Une fonction est un peu comme une boîte, une couche dans une autre. On peut comprendre la portée comme une boîte fermée, c'est-à-dire les variables locales de la fonction, qui ne peuvent être utilisées qu'à l'intérieur de la boîte et deviennent une portée indépendante.
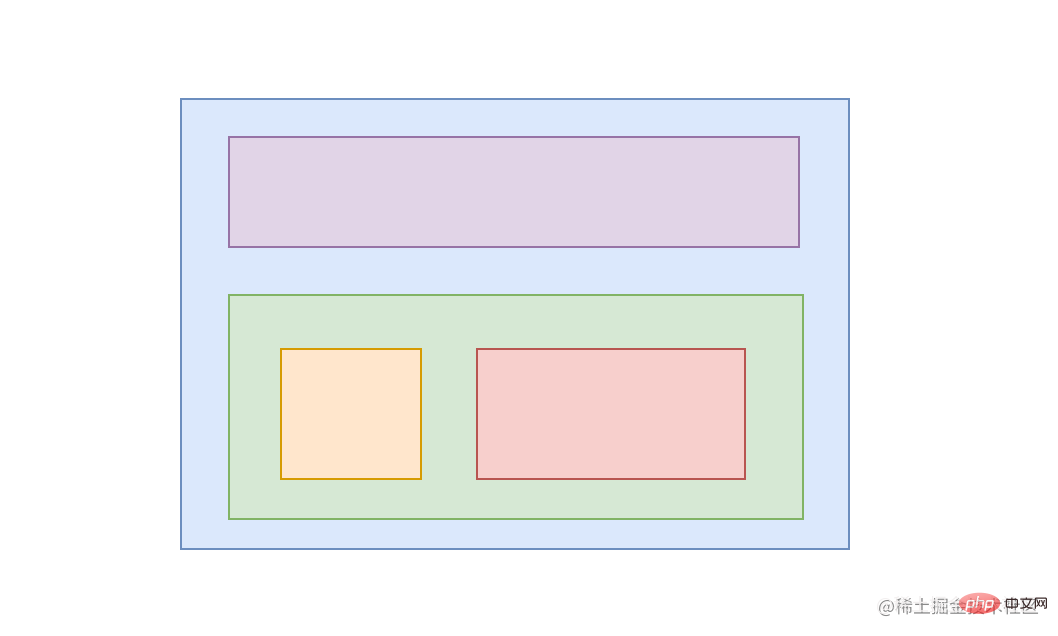
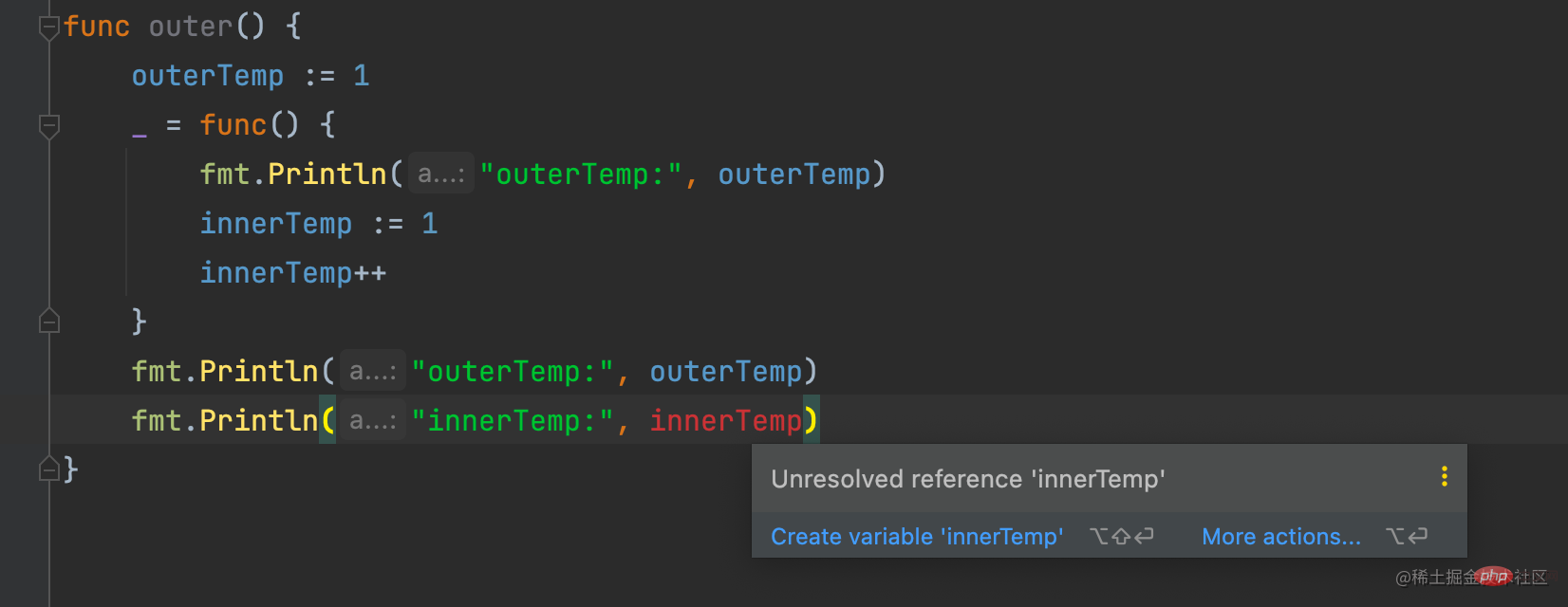
La variable locale dans la fonction sort de la portée après avoir quitté la fonction et la variable est introuvable. (La fonction interne peut utiliser les variables locales de la fonction externe, car la portée de la fonction externe inclut la fonction interne. Par exemple, le innerTmep 出了函数作用域就找不到该变量,但是 outerTemp suivant peut toujours être utilisé dans la fonction interne).
Quelle que soit la langue, il existe fondamentalement un certain mécanisme de recyclage de la mémoire, qui consiste à recycler l'espace mémoire inutilisé. Le mécanisme de recyclage est généralement lié à la portée de la fonction mentionnée ci-dessus, et les variables locales jouent leur rôle. . Le domaine peut être recyclé s'il est toujours référencé, il ne sera pas recyclé.
1.2.3 Relation d'héritage de portée
Le soi-disant héritage de portée signifie que la petite boîte mentionnée précédemment peut hériter de la portée de la grande boîte extérieure. Dans la petite boîte, les éléments de la grande boîte peuvent être directement pris. dehors, mais la grande boîte ne peut pas être retirée. Les objets dans la petite boîte, à moins qu'une évasion ne se produise (l'évasion peut être comprise comme les objets dans la petite boîte donnant une référence, et la grande boîte peut être utilisée dès que vous l'obtenez. ). De manière générale, il existe deux types de portées de variables :
Portée globale : agit n'importe où
Portée locale : généralement des blocs de code, des fonctions, des packages, Fonctions internesDéclaration/définition Les variables sont appelées variables locales , et la portée est limitée à l'intérieur de la fonction
1.2 Définition de la fermeture
"Dans la plupart des cas, nous ne comprenons pas d'abord puis définissons, mais définissons d'abord puis comprenons" , définissons-le d'abord, Peu importe si vous ne le comprenez pas :
Une fermeture est une combinaison d'une fonction et de sa référence groupée à l'environnement environnant (environnement lexical, environnement lexical) . En d’autres termes, les fermetures permettent aux développeurs d’accéder à la portée d’une fonction externe à partir d’une fonction interne. Les fermetures sont créées lors de la création de la fonction.
Expliqué en une phrase :
Les mots langage Go ne peuvent pas être trouvés dans la définition ci-dessus. Les étudiants intelligents doivent savoir que les fermetures n'ont rien à voir avec le langage. Elles ne sont pas propres à JavaScript ou Go, mais sont propres aux langages de programmation fonctionnels. à droite, Tout langage prenant en charge la programmation fonctionnelle prend en charge les fermetures, Go et JavaScript en sont deux. La version actuelle de Java prend également en charge les fermetures, mais certaines personnes peuvent penser que ce n'est pas une fermeture parfaite, les détails sont discutés dans le texte. .
1.3 Comment écrire des fermetures
1.3.1 Premier aperçu des fermetures
Ce qui suit est un morceau de code de fermeture :
import "fmt"
func main() {
sumFunc := lazySum([]int{1, 2, 3, 4, 5})
fmt.Println("等待一会")
fmt.Println("结果:", sumFunc())
}
func lazySum(arr []int) func() int {
fmt.Println("先获取函数,不求结果")
var sum = func() int {
fmt.Println("求结果...")
result := 0
for _, v := range arr {
result = result + v
}
return result
}
return sum
}Le résultat de sortie :
先获取函数,不求结果 等待一会 求结果... 结果: 15
On peut voir que le sum() peut référencer les paramètres et les variables locales de la fonction externe lazySum(), et renvoyer la fonction sum() dans <code> lazySum() code>, les paramètres et variables pertinents sont enregistrés dans la fonction renvoyée et peuvent être appelés ultérieurement. sum() 方法可以引用外部函数 lazySum() 的参数以及局部变量,在lazySum()返回函数 sum() 的时候,相关的参数和变量都保存在返回的函数中,可以之后再进行调用。
上面的函数或许还可以更进一步,体现出捆绑函数和其周围的状态,我们加上一个次数 count:
import "fmt"
func main() {
sumFunc := lazySum([]int{1, 2, 3, 4, 5})
fmt.Println("等待一会")
fmt.Println("结果:", sumFunc())
fmt.Println("结果:", sumFunc())
fmt.Println("结果:", sumFunc())
}func lazySum(arr []int) func() int {
fmt.Println("先获取函数,不求结果")
count := 0
var sum = func() int {
count++
fmt.Println("第", count, "次求结果...")
result := 0
for _, v := range arr {
result = result + v
} return result
} return sum
}上面代码输出什么呢?次数 count 会不会发生变化,count明显是外层函数的局部变量,但是在内存函数引用(捆绑),内层函数被暴露出去了,执行结果如下:
先获取函数,不求结果 等待一会 第 1 次求结果... 结果: 15 第 2 次求结果... 结果: 15 第 3 次求结果... 结果: 15
结果是 count 其实每次都会变化,这种情况总结一下:
- 函数体内嵌套了另外一个函数,并且返回值是一个函数。
- 内层函数被暴露出去,被外层函数以外的地方引用着,形成了闭包。
此时有人可能有疑问了,前面是lazySum()被创建了 1 次,执行了 3 次,但是如果是 3 次执行都是不同的创建,会是怎么样呢?实验一下:
import "fmt"
func main() {
sumFunc := lazySum([]int{1, 2, 3, 4, 5})
fmt.Println("等待一会")
fmt.Println("结果:", sumFunc())
sumFunc1 := lazySum([]int{1, 2, 3, 4, 5})
fmt.Println("等待一会")
fmt.Println("结果:", sumFunc1())
sumFunc2 := lazySum([]int{1, 2, 3, 4, 5})
fmt.Println("等待一会")
fmt.Println("结果:", sumFunc2())
}func lazySum(arr []int) func() int {
fmt.Println("先获取函数,不求结果")
count := 0
var sum = func() int {
count++
fmt.Println("第", count, "次求结果...")
result := 0
for _, v := range arr {
result = result + v
} return result
} return sum
}执行的结果如下,每次执行都是第 1 次:
先获取函数,不求结果 等待一会 第 1 次求结果... 结果: 15 先获取函数,不求结果 等待一会 第 1 次求结果... 结果: 15 先获取函数,不求结果 等待一会 第 1 次求结果... 结果: 15
从以上的执行结果可以看出:
闭包被创建的时候,引用的外部变量count就已经被创建了 1 份,也就是各自调用是没有关系的。
继续抛出一个问题,**如果一个函数返回了两个函数,这是一个闭包还是两个闭包呢?**下面我们实践一下:
一次返回两个函数,一个用于计算加和的结果,一个计算乘积:
import "fmt"
func main() {
sumFunc, productSFunc := lazyCalculate([]int{1, 2, 3, 4, 5})
fmt.Println("等待一会")
fmt.Println("结果:", sumFunc())
fmt.Println("结果:", productSFunc())
}func lazyCalculate(arr []int) (func() int, func() int) {
fmt.Println("先获取函数,不求结果")
count := 0
var sum = func() int {
count++
fmt.Println("第", count, "次求加和...")
result := 0
for _, v := range arr {
result = result + v
} return result
} var product = func() int {
count++
fmt.Println("第", count, "次求乘积...")
result := 0
for _, v := range arr {
result = result * v
} return result
} return sum, product
}运行结果如下:
先获取函数,不求结果 等待一会 第 1 次求加和... 结果: 15 第 2 次求乘积... 结果: 0
从上面结果可以看出,闭包是函数返回函数的时候,不管多少个返回值(函数),都是一次闭包,如果返回的函数有使用外部函数变量,则会绑定到一起,相互影响:
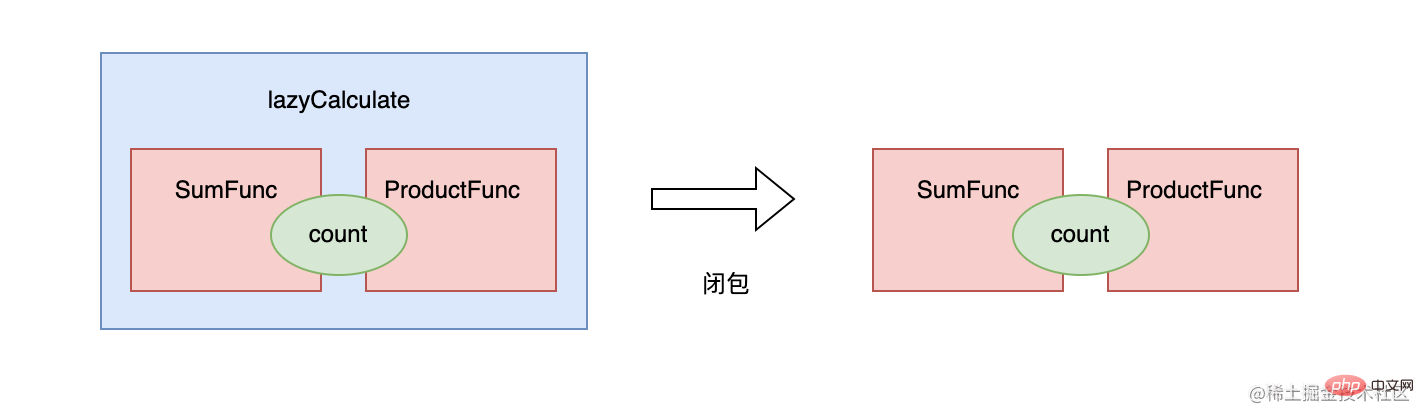
闭包绑定了周围的状态,我理解此时的函数就拥有了状态,让函数具有了对象所有的能力,函数具有了状态。
1.3.2 闭包中的指针和值
上面的例子,我们闭包中用到的都是数值,如果我们传递指针,会是怎么样的呢?
import "fmt"
func main() {
i := 0
testFunc := test(&i)
testFunc()
fmt.Printf("outer i = %d\n", i)
}func test(i *int) func() {
*i = *i + 1
fmt.Printf("test inner i = %d\n", *i) return func() {
*i = *i + 1
fmt.Printf("func inner i = %d\n", *i)
}
}运行结果如下:
test inner i = 1 func inner i = 2 outer i = 2
可以看出如果是指针的话,闭包里面修改了指针对应的地址的值,也会影响闭包外面的值。这个其实很容易理解,Go 里面没有引用传递,只有值传递,那我们传递指针的时候,也是值传递,这里的值是指针的数值(可以理解为地址值)。
当我们函数的参数是指针的时候,参数会拷贝一份这个指针地址,当做参数进行传递,因为本质还是地址,所以内部修改的时候,仍然可以对外部产生影响。
闭包里面的数据其实地址也是一样的,下面的实验可以证明:
func main() {
i := 0
testFunc := test(&i)
testFunc()
fmt.Printf("outer i address %v\n", &i)
}
func test(i *int) func() {
*i = *i + 1
fmt.Printf("test inner i address %v\n", i)
return func() {
*i = *i + 1
fmt.Printf("func inner i address %v\n", i)
}
}输出如下, 因此可以推断出,闭包如果引用外部环境的指针数据,只是会拷贝一份指针地址数据,而不是拷贝一份真正的数据(==先留个问题:拷贝的时机是什么时候呢==):
test inner i address 0xc0003fab98 func inner i address 0xc0003fab98 outer i address 0xc0003fab98
1.3.2 闭包延迟化
上面的例子仿佛都在告诉我们,闭包创建的时候,数据就已经拷贝了,但是真的是这样么?
下面是继续前面的实验:
func main() {
i := 0
testFunc := test(&i)
i = i + 100
fmt.Printf("outer i before testFunc %d\n", i)
testFunc()
fmt.Printf("outer i after testFunc %d\n", i)
}func test(i *int) func() {
*i = *i + 1
fmt.Printf("test inner i = %d\n", *i)
return func() {
*i = *i + 1
fmt.Printf("func inner i = %d\n", *i)
}
}我们在创建闭包之后,把数据改了,之后执行闭包,答案肯定是真实影响闭包的执行,因为它们都是指针,都是指向同一份数据:
test inner i = 1 outer i before testFunc 101 func inner i = 102 outer i after testFunc 102
假设我们换个写法,让闭包外部环境中的变量在声明闭包函数的之后,进行修改:
import "fmt"
func main() {
sumFunc := lazySum([]int{1, 2, 3, 4, 5})
fmt.Println("等待一会")
fmt.Println("结果:", sumFunc())
}
func lazySum(arr []int) func() int {
fmt.Println("先获取函数,不求结果")
count := 0
var sum = func() int {
fmt.Println("第", count, "次求结果...")
result := 0
for _, v := range arr {
result = result + v
}
return result
}
count = count + 100
return sum
}实际执行结果,count 会是修改后的值:
等待一会 第 100 次求结果... 结果: 15
这也证明了,实际上闭包并不会在声明var sum = func() int {...}这句话之后,就将外部环境的 countLa fonction ci-dessus peut aller plus loin pour refléter la fonction groupée et son état environnant. Nous ajoutons un certain nombre de fois count :
func main() {
funcs := testFunc(100)
for _, v := range funcs {
v()
}
}
func testFunc(x int) []func() {
var funcs []func()
values := []int{1, 2, 3}
for _, val := range values {
funcs = append(funcs, func() {
fmt.Printf("testFunc val = %d\n", x+val)
})
}
return funcs
}Que produit le code ci-dessus ? Le nombre de fois où count changera ? count est évidemment une variable locale de la fonction externe, mais dans la référence de la fonction mémoire (bundling), la fonction interne est exposée et exécutée. Le résultat est le suivant : 🎜testFunc val = 103 testFunc val = 103 testFunc val = 103🎜Le résultat est
count En fait, cela changera à chaque fois : 🎜- Il y a une autre fonction imbriquée dans la fonction. body, et la valeur de retour est une fonction.
- La fonction interne est exposée et référencée par des endroits autres que la fonction externe, formant une fermeture.
lazySum() a été créé une fois et exécuté trois fois, mais s'il est exécuté trois fois, il sera différent Créer, à quoi ça ressemblera ? Expérience : Les résultats d'exécution de 🎜import (
"fmt"
"time"
)
func main() {
sumFunc := lazySum([]int{1, 2, 3, 4, 5})
fmt.Println("等待一会")
fmt.Println("结果:", sumFunc())
time.Sleep(time.Duration(3) * time.Second)
fmt.Println("结果:", sumFunc())
}
func lazySum(arr []int) func() int {
fmt.Println("先获取函数,不求结果")
count := 0
var sum = func() int {
count++
fmt.Println("第", count, "次求结果...")
result := 0
for _, v := range arr {
result = result + v
}
return result
}
go func() {
time.Sleep(time.Duration(1) * time.Second)
count = count + 100
fmt.Println("go func 修改后的变量 count:", count)
}()
return sum
}🎜 sont les suivants, chaque exécution est la première fois : 🎜先获取函数,不求结果 等待一会 第 1 次求结果... 结果: 15 go func 修改后的变量 count: 101 第 102 次求结果... 结果: 15🎜 Cela peut être vu à partir des résultats d'exécution ci-dessus : 🎜🎜🎜Lorsque la fermeture est créée, la variable externe référencée
count a déjà été créé 1 copie, c'est-à-dire que peu importe si vous appelez chacun d'eux🎜. 🎜🎜Continuez à soulever une question : **Si une fonction renvoie deux fonctions, s'agit-il d'une fermeture ou de deux fermetures ? **Pratirons-le ci-dessous : 🎜🎜Renvoyer deux fonctions à la fois, l'une est utilisée pour calculer le résultat de la somme et l'autre est utilisée pour calculer le produit : 🎜import "fmt"
func testFunc(i int) func() int {
i = i * 2
testFunc := func() int {
i++
return i
}
i = i * 2
return testFunc
}
func main() {
test := testFunc(1)
fmt.Println(test())
}🎜Les résultats courants sont les suivants : 🎜5🎜 Comme le montrent les résultats ci-dessus, la fermeture est un retour de fonction. Lors de l'utilisation d'une fonction, quel que soit le nombre de valeurs de retour (fonctions), ce sont toutes des fermetures. Si la fonction renvoyée utilise des variables de fonction externes, elles le seront. être liés et s'influencer mutuellement : 🎜🎜
 🎜🎜La fermeture lie l'état environnant, je comprends cela. Lorsque la fonction a un état, la fonction a toutes les capacités de l'objet et la fonction a un état. 🎜
🎜🎜La fermeture lie l'état environnant, je comprends cela. Lorsque la fonction a un état, la fonction a toutes les capacités de l'objet et la fonction a un état. 🎜🎜1.3.2 Pointeurs et valeurs dans les fermetures🎜🎜🎜Dans l'exemple ci-dessus, toutes les valeurs utilisées dans nos fermetures sont des valeurs numériques. Que se passera-t-il si nous réussissons. des pointeurs ? Quel genre de chose ? 🎜 go build --gcflags=-m main.go
🎜Les résultats d'exécution sont les suivants : 🎜go tool compile -N -l -S main.go
🎜On voit que s'il s'agit d'un pointeur, si la valeur de l'adresse correspondant au pointeur est modifiée dans la fermeture, cela affectera également la valeur en dehors de la fermeture. C'est en fait très facile à comprendre. Il n'y a pas de passage de référence dans Go, seulement un passage de valeur. Lorsque nous passons un pointeur, il est également transmis par valeur. La valeur ici est la valeur du pointeur (qui peut être comprise comme l'adresse). valeur). 🎜🎜Lorsque le paramètre de notre fonction est un pointeur, le paramètre copiera l'adresse du pointeur et la passera en paramètre. Car l'essence est toujours une adresse, lorsqu'elle est modifiée en interne, elle peut toujours avoir un impact à l'extérieur. 🎜🎜Les données dans la fermeture ont en fait la même adresse. L'expérience suivante peut le prouver : 🎜"".testFunc STEXT size=218 args=0x8 locals=0x38 funcid=0x0 align=0x0
0x0000 00000 (main.go:5) TEXT "".testFunc(SB), ABIInternal, -8
0x0000 00000 (main.go:5) CMPQ SP, 16(R14)
0x0004 00004 (main.go:5) PCDATA rrreee, $-2
0x0004 00004 (main.go:5) JLS 198
0x000a 00010 (main.go:5) PCDATA rrreee, $-1
0x000a 00010 (main.go:5) SUBQ , SP
0x000e 00014 (main.go:5) MOVQ BP, 48(SP)
0x0013 00019 (main.go:5) LEAQ 48(SP), BP
0x0018 00024 (main.go:5) FUNCDATA rrreee, gclocals·69c1753bd5f81501d95132d08af04464(SB)
0x0018 00024 (main.go:5) FUNCDATA , gclocals·d571c0f6cf0af59df28f76498f639cf2(SB)
0x0018 00024 (main.go:5) FUNCDATA , "".testFunc.arginfo1(SB)
0x0018 00024 (main.go:5) MOVQ AX, "".i+64(SP)
0x001d 00029 (main.go:5) MOVQ rrreee, "".~r0+16(SP)
0x0026 00038 (main.go:5) LEAQ type.int(SB), AX
0x002d 00045 (main.go:5) PCDATA , rrreee
0x002d 00045 (main.go:5) CALL runtime.newobject(SB)
0x0032 00050 (main.go:5) MOVQ AX, "".&i+40(SP)
0x0037 00055 (main.go:5) MOVQ "".i+64(SP), CX
0x003c 00060 (main.go:5) MOVQ CX, (AX)
0x003f 00063 (main.go:6) MOVQ "".&i+40(SP), CX
0x0044 00068 (main.go:6) MOVQ "".&i+40(SP), DX
0x0049 00073 (main.go:6) MOVQ (DX), DX
0x004c 00076 (main.go:6) SHLQ , DX
0x004f 00079 (main.go:6) MOVQ DX, (CX)
0x0052 00082 (main.go:7) LEAQ type.noalg.struct { F uintptr; "".i *int }(SB), AX
0x0059 00089 (main.go:7) PCDATA ,
0x0059 00089 (main.go:7) CALL runtime.newobject(SB)
0x005e 00094 (main.go:7) MOVQ AX, ""..autotmp_3+32(SP)
0x0063 00099 (main.go:7) LEAQ "".testFunc.func1(SB), CX
0x006a 00106 (main.go:7) MOVQ CX, (AX)
0x006d 00109 (main.go:7) MOVQ ""..autotmp_3+32(SP), CX
0x0072 00114 (main.go:7) TESTB AL, (CX)
0x0074 00116 (main.go:7) MOVQ "".&i+40(SP), DX
0x0079 00121 (main.go:7) LEAQ 8(CX), DI
0x007d 00125 (main.go:7) PCDATA rrreee, $-2
0x007d 00125 (main.go:7) CMPL runtime.writeBarrier(SB), rrreee
0x0084 00132 (main.go:7) JEQ 136
0x0086 00134 (main.go:7) JMP 142
0x0088 00136 (main.go:7) MOVQ DX, 8(CX)
0x008c 00140 (main.go:7) JMP 149
0x008e 00142 (main.go:7) CALL runtime.gcWriteBarrierDX(SB)
0x0093 00147 (main.go:7) JMP 149
0x0095 00149 (main.go:7) PCDATA rrreee, $-1
0x0095 00149 (main.go:7) MOVQ ""..autotmp_3+32(SP), CX
0x009a 00154 (main.go:7) MOVQ CX, "".testFunc+24(SP)
0x009f 00159 (main.go:11) MOVQ "".&i+40(SP), CX
0x00a4 00164 (main.go:11) MOVQ "".&i+40(SP), DX
0x00a9 00169 (main.go:11) MOVQ (DX), DX
0x00ac 00172 (main.go:11) SHLQ , DX
0x00af 00175 (main.go:11) MOVQ DX, (CX)
0x00b2 00178 (main.go:12) MOVQ "".testFunc+24(SP), AX
0x00b7 00183 (main.go:12) MOVQ AX, "".~r0+16(SP)
0x00bc 00188 (main.go:12) MOVQ 48(SP), BP
0x00c1 00193 (main.go:12) ADDQ , SP
0x00c5 00197 (main.go:12) RET
0x00c6 00198 (main.go:12) NOP
0x00c6 00198 (main.go:5) PCDATA , $-1
0x00c6 00198 (main.go:5) PCDATA rrreee, $-2
0x00c6 00198 (main.go:5) MOVQ AX, 8(SP)
0x00cb 00203 (main.go:5) CALL runtime.morestack_noctxt(SB)
0x00d0 00208 (main.go:5) MOVQ 8(SP), AX
0x00d5 00213 (main.go:5) PCDATA rrreee, $-1
0x00d5 00213 (main.go:5) JMP 0🎜Le résultat est le suivant, on peut donc en déduire que si la fermeture fait référence aux données du pointeur de l'environnement externe, elle. ne copiera que les données d'adresse du pointeur, et ce n'est pas une copie des données réelles (== Laissez d'abord une question : quel est le moment de la copie ==) : 🎜rrreee🎜1.3.2 Report de fermeture 🎜🎜 🎜Les exemples ci-dessus semblent nous dire que lors de la création de la fermeture, les données ont été copiées, mais est-ce vraiment le cas ? 🎜🎜Ce qui suit est une continuation de l'expérience précédente : 🎜rrreee🎜Après avoir créé la fermeture, nous avons modifié les données puis exécuté la fermeture. La réponse doit être que cela affecte vraiment l'exécution de la fermeture, car ce sont tous des pointeurs et. pointez vers la même copie. Données : 🎜rrreee🎜Supposons que nous changions la façon d'écrire et laissons les variables dans l'environnement externe de la fermeture être modifiées après avoir déclaré la fonction de fermeture : 🎜rrreee🎜Le résultat réel de l'exécution, count<.> sera la valeur modifiée:🎜rrreee🎜Cela prouve également qu'en fait, la fermeture ne change pas le <code> de l'environnement externe après avoir déclaré <code>var sum = func() int {...} code> count est lié à la fermeture, mais il est lié lorsque la fonction renvoie la fonction de fermeture. Il s'agit d'une 🎜liaison retardée🎜. 🎜
count<.> sera la valeur modifiée:🎜rrreee🎜Cela prouve également qu'en fait, la fermeture ne change pas le <code> de l'environnement externe après avoir déclaré <code>var sum = func() int {...} code> count est lié à la fermeture, mais il est lié lorsque la fonction renvoie la fonction de fermeture. Il s'agit d'une 🎜liaison retardée🎜. 🎜如果还没看明白没关系,我们再来一个例子:
func main() {
funcs := testFunc(100)
for _, v := range funcs {
v()
}
}
func testFunc(x int) []func() {
var funcs []func()
values := []int{1, 2, 3}
for _, val := range values {
funcs = append(funcs, func() {
fmt.Printf("testFunc val = %d\n", x+val)
})
}
return funcs
}上面的例子,我们闭包返回的是函数数组,本意我们想入每一个 val 都不一样,但是实际上 val都是一个值,==也就是执行到return funcs 的时候(或者真正执行闭包函数的时候)才绑定的 val值==(关于这一点,后面还有个Demo可以证明),此时 val的值是最后一个 3,最终输出结果都是 103:
testFunc val = 103 testFunc val = 103 testFunc val = 103
以上两个例子,都是闭包延迟绑定的问题导致,这也可以说是 feature,到这里可能不少同学还是对闭包绑定外部变量的时机有疑惑,到底是返回闭包函数的时候绑定的呢?还是真正执行闭包函数的时候才绑定的呢?
下面的例子可以有效的解答:
import (
"fmt"
"time"
)
func main() {
sumFunc := lazySum([]int{1, 2, 3, 4, 5})
fmt.Println("等待一会")
fmt.Println("结果:", sumFunc())
time.Sleep(time.Duration(3) * time.Second)
fmt.Println("结果:", sumFunc())
}
func lazySum(arr []int) func() int {
fmt.Println("先获取函数,不求结果")
count := 0
var sum = func() int {
count++
fmt.Println("第", count, "次求结果...")
result := 0
for _, v := range arr {
result = result + v
}
return result
}
go func() {
time.Sleep(time.Duration(1) * time.Second)
count = count + 100
fmt.Println("go func 修改后的变量 count:", count)
}()
return sum
}输出结果如下:
先获取函数,不求结果 等待一会 第 1 次求结果... 结果: 15 go func 修改后的变量 count: 101 第 102 次求结果... 结果: 15
第二次执行闭包函数的时候,明显 count被里面的 go func()修改了,也就是调用的时候,才真正的获取最新的外部环境,但是在声明的时候,就会把环境预留保存下来。
其实本质上,Go Routine的匿名函数的延迟绑定就是闭包的延迟绑定,上面的例子中,go func(){}获取到的就是最新的值,而不是原始值0。
总结一下上面的验证点:
- 闭包每次返回都是一个新的实例,每个实例都有一份自己的环境。
- 同一个实例多次执行,会使用相同的环境。
- 闭包如果逃逸的是指针,会相互影响,因为绑定的是指针,相同指针的内容修改会相互影响。
- 闭包并不是在声明时绑定的值,声明后只是预留了外部环境(逃逸分析),真正执行闭包函数时,会获取最新的外部环境的值(也称为延迟绑定)。
- Go Routine的匿名函数的延迟绑定本质上就是闭包的延迟绑定。
2、闭包的好处与坏处?
2.1 好处
纯函数没有状态,而闭包则是让函数轻松拥有了状态。但是凡事都有两面性,一旦拥有状态,多次调用,可能会出现不一样的结果,就像是前面测试的 case 中一样。那么问题来了:
Q:如果不支持闭包的话,我们想要函数拥有状态,需要怎么做呢?
A: 需要使用全局变量,让所有函数共享同一份变量。
但是我们都知道全局变量有以下的一些特点(在不同的场景,优点会变成缺点):
- 常驻于内存之中,只要程序不停会一直在内存中。
- 污染全局,大家都可以访问,共享的同时不知道谁会改这个变量。
闭包可以一定程度优化这个问题:
- 不需要使用全局变量,外部函数局部变量在闭包的时候会创建一份,生命周期与函数生命周期一致,闭包函数不再被引用的时候,就可以回收了。
- 闭包暴露的局部变量,外界无法直接访问,只能通过函数操作,可以避免滥用。
除了以上的好处,像在 JavaScript 中,没有原生支持私有方法,可以靠闭包来模拟私有方法,因为闭包都有自己的词法环境。
2.2 坏处
函数拥有状态,如果处理不当,会导致闭包中的变量被误改,但这是编码者应该考虑的问题,是预期中的场景。
闭包中如果随意创建,引用被持有,则无法销毁,同时闭包内的局部变量也无法销毁,过度使用闭包会占有更多的内存,导致性能下降。一般而言,能共享一份闭包(共享闭包局部变量数据),不需要多次创建闭包函数,是比较优雅的方式。
3、闭包怎么实现的?
从上面的实验中,我们可以知道,闭包实际上就是外部环境的逃逸,跟随着闭包函数一起暴露出去。
我们用以下的程序进行分析:
import "fmt"
func testFunc(i int) func() int {
i = i * 2
testFunc := func() int {
i++
return i
}
i = i * 2
return testFunc
}
func main() {
test := testFunc(1)
fmt.Println(test())
}执行结果如下:
5
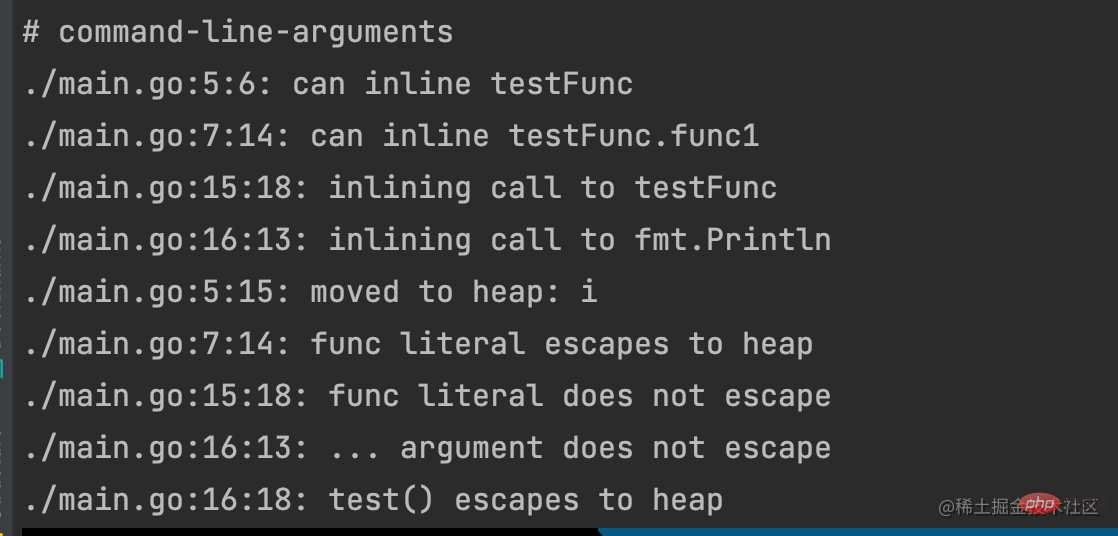
先看看逃逸分析,用下面的命令行可以查看:
go build --gcflags=-m main.go
可以看到 变量 i被移到堆中,也就是本来是局部变量,但是发生逃逸之后,从栈里面放到堆里面,同样的 test()函数由于是闭包函数,也逃逸到堆上。
下面我们用命令行来看看汇编代码:
go tool compile -N -l -S main.go
生成代码比较长,我截取一部分:
"".testFunc STEXT size=218 args=0x8 locals=0x38 funcid=0x0 align=0x0
0x0000 00000 (main.go:5) TEXT "".testFunc(SB), ABIInternal, $56-8
0x0000 00000 (main.go:5) CMPQ SP, 16(R14)
0x0004 00004 (main.go:5) PCDATA $0, $-2
0x0004 00004 (main.go:5) JLS 198
0x000a 00010 (main.go:5) PCDATA $0, $-1
0x000a 00010 (main.go:5) SUBQ $56, SP
0x000e 00014 (main.go:5) MOVQ BP, 48(SP)
0x0013 00019 (main.go:5) LEAQ 48(SP), BP
0x0018 00024 (main.go:5) FUNCDATA $0, gclocals·69c1753bd5f81501d95132d08af04464(SB)
0x0018 00024 (main.go:5) FUNCDATA $1, gclocals·d571c0f6cf0af59df28f76498f639cf2(SB)
0x0018 00024 (main.go:5) FUNCDATA $5, "".testFunc.arginfo1(SB)
0x0018 00024 (main.go:5) MOVQ AX, "".i+64(SP)
0x001d 00029 (main.go:5) MOVQ $0, "".~r0+16(SP)
0x0026 00038 (main.go:5) LEAQ type.int(SB), AX
0x002d 00045 (main.go:5) PCDATA $1, $0
0x002d 00045 (main.go:5) CALL runtime.newobject(SB)
0x0032 00050 (main.go:5) MOVQ AX, "".&i+40(SP)
0x0037 00055 (main.go:5) MOVQ "".i+64(SP), CX
0x003c 00060 (main.go:5) MOVQ CX, (AX)
0x003f 00063 (main.go:6) MOVQ "".&i+40(SP), CX
0x0044 00068 (main.go:6) MOVQ "".&i+40(SP), DX
0x0049 00073 (main.go:6) MOVQ (DX), DX
0x004c 00076 (main.go:6) SHLQ $1, DX
0x004f 00079 (main.go:6) MOVQ DX, (CX)
0x0052 00082 (main.go:7) LEAQ type.noalg.struct { F uintptr; "".i *int }(SB), AX
0x0059 00089 (main.go:7) PCDATA $1, $1
0x0059 00089 (main.go:7) CALL runtime.newobject(SB)
0x005e 00094 (main.go:7) MOVQ AX, ""..autotmp_3+32(SP)
0x0063 00099 (main.go:7) LEAQ "".testFunc.func1(SB), CX
0x006a 00106 (main.go:7) MOVQ CX, (AX)
0x006d 00109 (main.go:7) MOVQ ""..autotmp_3+32(SP), CX
0x0072 00114 (main.go:7) TESTB AL, (CX)
0x0074 00116 (main.go:7) MOVQ "".&i+40(SP), DX
0x0079 00121 (main.go:7) LEAQ 8(CX), DI
0x007d 00125 (main.go:7) PCDATA $0, $-2
0x007d 00125 (main.go:7) CMPL runtime.writeBarrier(SB), $0
0x0084 00132 (main.go:7) JEQ 136
0x0086 00134 (main.go:7) JMP 142
0x0088 00136 (main.go:7) MOVQ DX, 8(CX)
0x008c 00140 (main.go:7) JMP 149
0x008e 00142 (main.go:7) CALL runtime.gcWriteBarrierDX(SB)
0x0093 00147 (main.go:7) JMP 149
0x0095 00149 (main.go:7) PCDATA $0, $-1
0x0095 00149 (main.go:7) MOVQ ""..autotmp_3+32(SP), CX
0x009a 00154 (main.go:7) MOVQ CX, "".testFunc+24(SP)
0x009f 00159 (main.go:11) MOVQ "".&i+40(SP), CX
0x00a4 00164 (main.go:11) MOVQ "".&i+40(SP), DX
0x00a9 00169 (main.go:11) MOVQ (DX), DX
0x00ac 00172 (main.go:11) SHLQ $1, DX
0x00af 00175 (main.go:11) MOVQ DX, (CX)
0x00b2 00178 (main.go:12) MOVQ "".testFunc+24(SP), AX
0x00b7 00183 (main.go:12) MOVQ AX, "".~r0+16(SP)
0x00bc 00188 (main.go:12) MOVQ 48(SP), BP
0x00c1 00193 (main.go:12) ADDQ $56, SP
0x00c5 00197 (main.go:12) RET
0x00c6 00198 (main.go:12) NOP
0x00c6 00198 (main.go:5) PCDATA $1, $-1
0x00c6 00198 (main.go:5) PCDATA $0, $-2
0x00c6 00198 (main.go:5) MOVQ AX, 8(SP)
0x00cb 00203 (main.go:5) CALL runtime.morestack_noctxt(SB)
0x00d0 00208 (main.go:5) MOVQ 8(SP), AX
0x00d5 00213 (main.go:5) PCDATA $0, $-1
0x00d5 00213 (main.go:5) JMP 0可以看到闭包函数实际上底层也是用结构体new创建出来的:
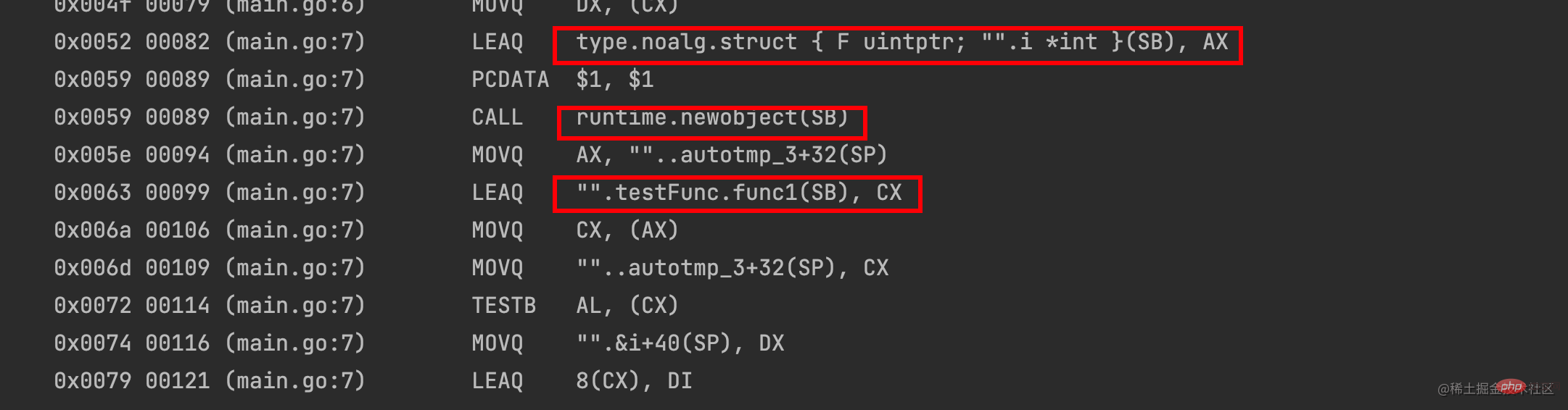
Utilisez le i sur le tas : i:
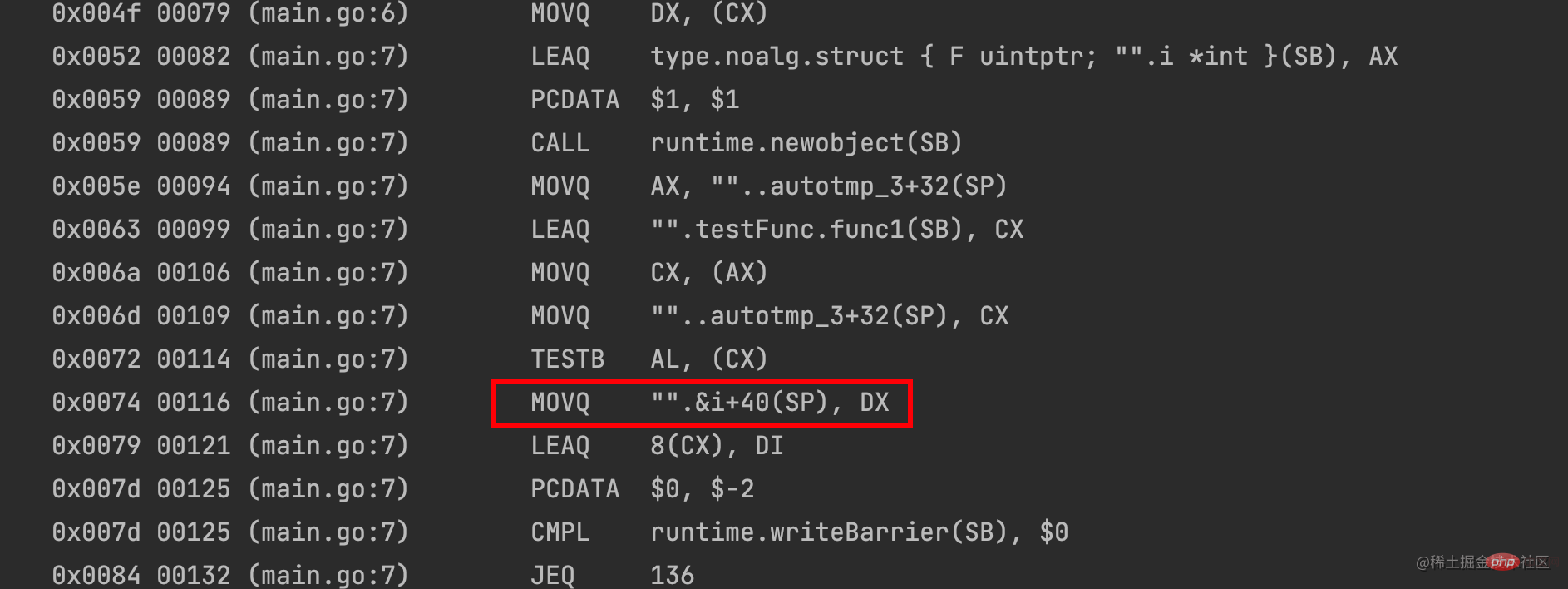
也就是返回函数的时候,实际上返回结构体,结构体里面记录了函数的引用环境。
4、浅聊一下
4.1 Java 支不支持闭包?
网上有很多种看法,实际上 Java 虽然暂时不支持返回函数作为返参,但是Java 本质上还是实现了闭包的概念的,所使用的的方式是内部类的形式,因为是内部类,所以相当于自带了一个引用环境,算是一种不完整的闭包。
目前有一定限制,比如是 final

4. Parlons brièvement
4.1 Java prend-il en charge les fermetures ? Il existe de nombreuses opinions sur Internet. En fait, bien que Java ne prenne actuellement pas en charge les fonctions de retour comme paramètres de retour, Java implémente essentiellement le concept de fermeture, et la méthode utilisée se présente sous la forme d'une classe interne, car elle est une classe interne, cela équivaut donc à apporter un environnement de référence, ce qui est considéré comme une fermeture incomplète.
Il existe actuellement certaines restrictions. Par exemple, seulement si elle est déclarée avec final ou si une valeur clairement définie peut être transmise :
Il existe des réponses associées sur Stack Overflow :stackoverflow.com/questions. /5…
4.2 Quel est l'avenir de la programmation fonctionnelle ?
🎜Voici ce que dit le Wiki : 🎜🎜🎜La programmation fonctionnelle est depuis longtemps populaire dans le monde universitaire mais a peu d'applications industrielles. La principale raison de cette situation est que la programmation fonctionnelle est souvent considérée comme consommant beaucoup de ressources CPU et mémoire [🎜18]🎜 Cela est dû au fait que les problèmes d'efficacité n'ont pas été pris en compte lors de la mise en œuvre précoce des langages de programmation fonctionnels et en raison des caractéristiques des langages de programmation fonctionnels. la programmation, par exemple, assurer la 🎜transparence des références🎜, etc. nécessite des structures de données et des algorithmes uniques. [🎜19]🎜🎜🎜Cependant, récemment, plusieurs langages de programmation fonctionnels ont été utilisés dans des systèmes commerciaux ou industriels [🎜20]🎜, par exemple : 🎜
- Erlang, développé à la fin des années 1980 par la société suédoise Ericsson, était à l'origine utilisé pour mettre en œuvre des systèmes de télécommunications tolérants aux pannes. Depuis, il a été utilisé comme langage populaire pour créer une série d'applications par des entreprises telles que Nortel, Facebook, Électricité de France et WhatsApp. [21][22]
- Scheme, qui a été utilisé comme base pour plusieurs applications sur les premiers ordinateurs Apple Macintosh, et a récemment été appliqué à des choses comme les logiciels de simulation de formation et la direction de contrôle des télescopes .
- OCaml, lancé au milieu des années 1990, a trouvé des applications commerciales dans des domaines tels que l'analyse financière, la vérification des pilotes, la programmation de robots industriels et l'analyse statique des logiciels embarqués.
- Haskell, bien qu'il ait été à l'origine utilisé comme langage de recherche, il a également été utilisé par une série d'entreprises dans des domaines tels que les systèmes aérospatiaux, la conception de matériel et la programmation de réseaux.
Les autres langages de programmation fonctionnels utilisés dans l'industrie incluent le multi-paradigme Scala[23], F#, ainsi que Wolfram Language, Common Lisp, Standard ML et Clojure. Attendez.
De mon point de vue personnel, je ne suis pas optimiste quant à la programmation fonctionnelle pure, mais je crois que presque tous les besoins de programmation avancés auront l'idée deprogrammation fonctionnelle à l'avenir. J'attends particulièrement avec impatience que Java adopte. programmation fonctionnelle. À en juger par les langages que je connais, les fonctionnalités de programmation fonctionnelle de Go et JavaScript sont profondément appréciées des développeurs (bien sûr, si vous écrivez des bugs, vous les détesterez).
La raison pour laquelle il est soudainement devenu populaire récemment est aussi parce que le monde continue de se développer et que la mémoire devient de plus en plus grande. Les restrictions de ce facteur sont presque libérées.
Je crois que le monde est coloré. Il est absolument impossible qu'une seule chose gouverne le monde. Il s'agit plutôt d'une centaine d'écoles de pensée qui s'affrontent. Il en va de même pour les langages de programmation ou les paradigmes de programmation. à l’avenir, et l’histoire finira par filtrer celles qui correspondent au développement de la société humaine.
Pour plus de connaissances sur la programmation, veuillez visiter : Vidéos de programmation ! !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Explication graphique et textuelle détaillée de la façon dont Goland ide résout les conflits
- Explication détaillée du problème d'erreur d'ajout lorsque Go a une concurrence élevée !
- Un article explique en détail comment Golang implémente les opérations liées à SSH
- Explication détaillée de Struct (structure) dans Golang
- Parlons du mécanisme de délai d'attente HttpClient de Golang