
Maison >Opération et maintenance >exploitation et maintenance Linux >Linux a-t-il des threads au niveau du noyau ?
Linux a-t-il des threads au niveau du noyau ?

- 青灯夜游original
- 2022-11-11 14:20:322657parcourir
Linux a des threads au niveau du noyau et Linux prend en charge le multi-threading au niveau du noyau. Le noyau Linux peut être considéré comme un processus de service (gérant les ressources logicielles et matérielles, répondant à divers processus des processus utilisateur) ; le noyau nécessite plusieurs flux d'exécution en parallèle et prend en charge le multithreading afin d'éviter un éventuel blocage. Un thread du noyau est un clone du noyau qui peut être utilisé pour gérer une chose spécifique. Le noyau est responsable de la planification des threads du noyau. Lorsqu'un thread du noyau est bloqué, cela n'affecte pas les autres threads du noyau.

L'environnement d'exploitation de ce tutoriel : système linux7.3, ordinateur Dell G3.
Les threads sont généralement définis comme différentes routes d'exécution de code au sein d'un processus. En termes d'implémentation, il existe deux types de threads : les « threads au niveau utilisateur » et les « threads au niveau du noyau ».
Les threads utilisateur font référence aux threads qui sont implémentés dans les programmes utilisateur sans prise en charge du noyau. Ils ne dépendent pas du cœur du système d'exploitation. Les processus d'application utilisent la bibliothèque de threads pour fournir des fonctions de création, de synchronisation, de planification et de gestion des threads afin de contrôler les threads utilisateur. . Ce type de thread peut même être implémenté dans des systèmes d'exploitation comme DOS, mais la planification des threads doit être effectuée par le programme utilisateur, ce qui est quelque peu similaire au multitâche coopératif de Windows 3.x.
L'autre nécessite la participation du noyau, qui complète la planification des threads. Il s'appuie sur le cœur du système d'exploitation et est créé et détruit par les besoins internes du noyau. Les deux modèles ont leurs propres avantages et inconvénients.
Les threads utilisateur ne nécessitent aucune surcharge supplémentaire du noyau et l'implémentation des threads en mode utilisateur peut être personnalisée ou modifiée pour répondre aux exigences d'applications spéciales, mais lorsqu'un thread est dans un état d'attente en raison d'E/S, l'ensemble du processus sera être planifié Lorsque le programme passe à l'état d'attente, les autres threads n'ont pas la possibilité de s'exécuter ; alors que le thread du noyau n'a aucune restriction, ce qui permet de profiter de la concurrence des multiprocesseurs, mais cela nécessite plus de dépenses système. .
Windows NT et OS/2 prennent en charge les threads du noyau. Linux prend en charge le multithreading au niveau du noyau.
Threads au niveau du noyau sous Linux
1. Présentation des threads du noyau
Le noyau Linux peut être considéré comme un processus de service (gestion des ressources logicielles et matérielles, réponse à divers processus des processus utilisateur)
Besoins du noyau Plusieurs flux d'exécution sont parallèles et afin d'éviter un éventuel blocage, le multithreading est pris en charge.
Un thread du noyau est un clone du noyau qui peut être utilisé pour gérer une chose spécifique. Le noyau est responsable de la planification des threads du noyau. Lorsqu'un thread du noyau est bloqué, cela n'affecte pas les autres threads du noyau.
Les threads du noyau sont des processus démarrés directement par le noyau lui-même. Les threads du noyau délèguent en fait les fonctions du noyau à des processus indépendants pour exécution, qui s'exécutent en parallèle avec d'autres « processus » du noyau. Les threads du noyau sont souvent appelés démons du noyau. Dans le noyau actuel, le thread du noyau est responsable du travail suivant :
- Synchronisez périodiquement la page mémoire modifiée avec le périphérique de bloc source de la page
- Implémentez le journal des transactions du système de fichiers
Le thread du noyau est créé par le noyau, donc le thread du noyau Lors de l'exécution en mode noyau, vous ne pouvez accéder qu'à l'espace d'adressage virtuel du noyau et ne pouvez pas accéder à l'espace utilisateur.
Sous Linux, tous les threads sont implémentés en tant que processus, et il n'y a pas d'algorithme de planification distinct ni de structure de données définie pour les threads. Un processus équivaut à contenir un thread, qui est lui-même plusieurs threads. Le thread d'origine est appelé le thread principal. , et ils forment ensemble un groupe de discussions.
Le processus a son propre espace d'adressage, donc chaque processus a sa propre table de pages, mais pas le thread. Il ne peut partager que l'espace d'adressage et la table de pages du thread principal avec d'autres threads
2. structures
Chaque processus ou thread se compose de trois structures de données importantes, à savoir struct thread_info, struct task_struct et la pile du noyau.
L'objet thread_info stocke les informations de base du processus/thread. Lui et la pile du noyau du processus/thread sont stockés dans un espace deux fois plus long que la page dans l'espace du noyau. La structure thread_info est stockée à la fin du segment d'adresse et l'espace restant est utilisé comme pile du noyau. Le noyau utilise le système de jumelage pour allouer cet espace.
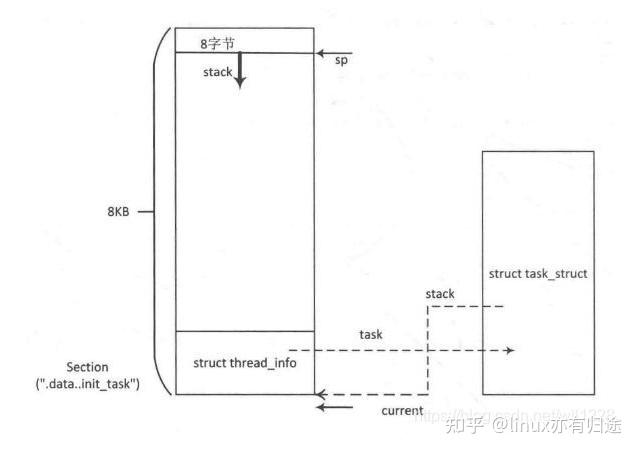

struct thread_info {
int preempt_count; /* 0 => preemptable, bug */
struct task_struct *task; /* main task structure */
__u32 cpu; /* cpu */};Il y a une structure task_struct *task dans la structure thread_info task qui pointe vers l'objet task_struct du thread ou du processus task_struct est également appelé le descripteur de tâche :
struct task_struct {
pid_t pid;
pid_t tgid;
void *stack;
struct mm_struct *mm, *active_mm;
/* filesystem information */
struct fs_struct *fs;
/* open file information */
struct files_struct *files;};#define task_thread_info(task) ((struct thread_info *)(task)->stack)- stack:是指向进程或者线程的thread_info
- mm:对象用来管理该进程/线程的页表以及虚拟内存区
- active_mm:主要用于内核线程访问主内核页全局目录
- pid:每个task_struct都会有一个不同的id,就是pid
- tgid:线程组领头线程的PID,就是主线程的pid
linux系统上虚拟地址空间分为两个部分:供用户态程序访问的虚拟地址空间和供内核访问的内核空间。每当内核执行上下文切换时,虚拟地址空间的用户层部分都会切换,以便匹配运行的进程,内核空间的部分是不会切换的。
3.内核线程创建
在内核版本linux-3.x以后,内核线程的创建被延后执行,并且交给名为kthreadd 2号线程执行创建过程,但是kthreadd本身是怎么创建的呢?过程如下:
pid_t kernel_thread(int (*fn)(void *), void *arg, unsigned long flags)
{
return do_fork(flags|CLONE_VM|CLONE_UNTRACED, (unsigned long)fn,
(unsigned long)arg, NULL, NULL);
}
pid = kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES);kthreadadd本身最终是通过do_fork实现的,do_fork通过传入不同的参数,可以分别用于创建用户态进程/线程,内核线程等。当kthreadadd被创建以后,内核线程的创建交给它实现。
内核线程的创建分为创建和启动两个部分,kthread_run作为统一的接口,可以同时实现,这两个功能:
#define kthread_run(threadfn, data, namefmt, ...) \
({ \
struct task_struct *__k \
= kthread_create(threadfn, data, namefmt, ## __VA_ARGS__); \
if (!IS_ERR(__k)) \
wake_up_process(__k); \
__k; \
})
#define kthread_create(threadfn, data, namefmt, arg...) \
kthread_create_on_node(threadfn, data, -1, namefmt, ##arg)
struct task_struct *kthread_create_on_node(int (*threadfn)(void *data),
void *data, int node,
const char namefmt[],
...)
{
DECLARE_COMPLETION_ONSTACK(done);
struct task_struct *task;
/*分配kthread_create_info空间*/
struct kthread_create_info *create = kmalloc(sizeof(*create),
GFP_KERNEL);
if (!create)
return ERR_PTR(-ENOMEM);
create->threadfn = threadfn;
create->data = data;
create->node = node;
create->done = &done;
/*加入到kthread_creta_list列表中,等待ktherad_add中断线程去创建改线程*/
spin_lock(&kthread_create_lock);
list_add_tail(&create->list, &kthread_create_list);
spin_unlock(&kthread_create_lock);
wake_up_process(kthreadd_task);
/*
* Wait for completion in killable state, for I might be chosen by
* the OOM killer while kthreadd is trying to allocate memory for
* new kernel thread.
*/
if (unlikely(wait_for_completion_killable(&done))) {
/*
* If I was SIGKILLed before kthreadd (or new kernel thread)
* calls complete(), leave the cleanup of this structure to
* that thread.
*/
if (xchg(&create->done, NULL))
return ERR_PTR(-EINTR);
/*
* kthreadd (or new kernel thread) will call complete()
* shortly.
*/
wait_for_completion(&done);
}
task = create->result;
.
.
.
kfree(create);
return task;
}kthread_create_on_node函数中:
- 首先利用kmalloc分配kthread_create_info变量create,利用函数参数初始化create
- 将create加入kthread_create_list链表中,然后唤醒kthreadd内核线程创建当前线程
- 唤醒kthreadd后,利用completion等待内核线程创建完成,completion完成后,释放create空间
下面来看下kthreadd的处理过程:
int kthreadd(void *unused)
{
struct task_struct *tsk = current;
/* Setup a clean context for our children to inherit. */
set_task_comm(tsk, "kthreadd");
ignore_signals(tsk);
set_cpus_allowed_ptr(tsk, cpu_all_mask);
set_mems_allowed(node_states[N_MEMORY]);
current->flags |= PF_NOFREEZE;
for (;;) {
set_current_state(TASK_INTERRUPTIBLE);
if (list_empty(&kthread_create_list))
schedule();
__set_current_state(TASK_RUNNING);
spin_lock(&kthread_create_lock);
while (!list_empty(&kthread_create_list)) {
struct kthread_create_info *create;
create = list_entry(kthread_create_list.next,
struct kthread_create_info, list);
list_del_init(&create->list);
spin_unlock(&kthread_create_lock);
create_kthread(create);
spin_lock(&kthread_create_lock);
}
spin_unlock(&kthread_create_lock);
}
return 0;
}kthreadd利用for(;;)一直驻留在内存中运行:主要过程如下:
- 检查kthread_create_list为空时,kthreadd让出cpu的执行权
- kthread_create_list不为空时,利用while循环遍历kthread_create_list链表
- 每取下一个链表节点后调用create_kthread,创建内核线程
static void create_kthread(struct kthread_create_info *create)
{
int pid;
/* We want our own signal handler (we take no signals by default). */
pid = kernel_thread(kthread, create, CLONE_FS | CLONE_FILES | SIGCHLD);
if (pid done, NULL);
if (!done) {
kfree(create);
return;
}
create->result = ERR_PTR(pid);
complete(done);
}
}可以看到内核线程的创建最终还是和kthreadd一样,调用kernel_thread实现。
static int kthread(void *_create)
{
.
.
.
.
/* If user was SIGKILLed, I release the structure. */
done = xchg(&create->done, NULL);
if (!done) {
kfree(create);
do_exit(-EINTR);
}
/* OK, tell user we're spawned, wait for stop or wakeup */
__set_current_state(TASK_UNINTERRUPTIBLE);
create->result = current;
complete(done);
schedule();
ret = -EINTR;
if (!test_bit(KTHREAD_SHOULD_STOP, &self.flags)) {
__kthread_parkme(&self);
ret = threadfn(data);
}
/* we can't just return, we must preserve "self" on stack */
do_exit(ret);
}kthread以struct kthread_create_info 类型的create为参数,create中带有创建内核线程的回调函数,以及函数的参数。kthread中,完成completion信号量的处理,然后schedule让出cpu的执行权,等待下次返回 时,执行回调函数threadfn(data)。
4.内核线程的退出
线程一旦启动起来后,会一直运行,除非该线程主动调用do_exit函数,或者其他的进程调用kthread_stop函数,结束线程的运行。
int kthread_stop(struct task_struct *k)
{
struct kthread *kthread;
int ret;
trace_sched_kthread_stop(k);
get_task_struct(k);
kthread = to_live_kthread(k);
if (kthread) {
set_bit(KTHREAD_SHOULD_STOP, &kthread->flags);
__kthread_unpark(k, kthread);
wake_up_process(k);
wait_for_completion(&kthread->exited);
}
ret = k->exit_code;
put_task_struct(k);
trace_sched_kthread_stop_ret(ret);
return ret;
}如果线程函数正在处理一个非常重要的任务,它不会被中断的。当然如果线程函数永远不返回并且不检查信号,它将永远都不会停止。在执行kthread_stop的时候,目标线程必须没有退出,否则会Oops。所以在创建thread_func时,可以采用以下形式:
thread_func()
{
// do your work here
// wait to exit
while(!thread_could_stop())
{
wait();
}
}
exit_code()
{
kthread_stop(_task); //发信号给task,通知其可以退出了
}如果线程中在等待某个条件满足才能继续运行,所以只有满足了条件以后,才能调用kthread_stop杀掉内核线程。
5.内核线程使用
#include "test_kthread.h"
#include <linux>
#include <linux>
#include <linux>
#include <linux>
#include <linux>
static struct task_struct *test_thread = NULL;
unsigned int time_conut = 5;
int test_thread_fun(void *data)
{
int times = 0;
while(!kthread_should_stop())
{
printk("\n printk %u\r\n", times);
times++;
msleep_interruptible(time_conut*1000);
}
printk("\n test_thread_fun exit success\r\n\n");
return 0;
}
void register_test_thread(void)
{
test_thread = kthread_run(test_thread_fun , NULL, "test_kthread" );
if (IS_ERR(test_thread)){
printk(KERN_INFO "create test_thread failed!\n");
}
else {
printk(KERN_INFO "create test_thread ok!\n");
}
}
static ssize_t kthread_debug_start(struct device *dev, struct device_attribute *attr, char *buf)
{
register_test_thread();
return 0;
}
static ssize_t kthread_debug_stop(struct device *dev, struct device_attribute *attr, char *buf)
{
kthread_stop(test_thread);
return 0;
}
static DEVICE_ATTR(kthread_start, S_IRUSR, kthread_debug_start,NULL);
static DEVICE_ATTR(kthread_stop, S_IRUSR, kthread_debug_stop,NULL);
struct attribute * kthread_group_info_attrs[] =
{
&dev_attr_kthread_start.attr,
&dev_attr_kthread_stop.attr,
NULL,
};
struct attribute_group kthread_group =
{
.name = "kthread",
.attrs = kthread_group_info_attrs,
};</linux></linux></linux></linux></linux>
相关推荐:《Linux视频教程》
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!