
Maison >Opération et maintenance >exploitation et maintenance Linux >Qu'est-ce que Linux utilise pour implémenter la mémoire virtuelle ?
Qu'est-ce que Linux utilise pour implémenter la mémoire virtuelle ?

- 青灯夜游original
- 2022-11-10 19:34:012608parcourir
La mise en œuvre de la mémoire virtuelle doit être basée sur la méthode de gestion de la mémoire allouée discrètement. Il existe trois méthodes de mise en œuvre : 1. Méthode de gestion du stockage par pagination ; 2. Méthode de gestion du stockage par segmentation des demandes ; Quelle que soit la méthode utilisée, une certaine prise en charge matérielle est requise : 1. Une certaine capacité de mémoire et de mémoire externe ; 2. Un mécanisme de table de pages (ou un mécanisme de table de segments) comme structure de données principale ; 3. Un mécanisme d'interruption, lorsque le programme utilisateur ; besoins Si la partie accédée n'a pas encore été transférée dans la mémoire, une interruption se produira; 4. Mécanisme de conversion d'adresse, conversion d'adresse logique en adresse physique.

L'environnement d'exploitation de ce tutoriel : système linux7.3, ordinateur Dell G3.
1. Présentation de la mémoire virtuelle
La gestion traditionnelle du stockage enregistre plusieurs processus en mémoire en même temps pour permettre la multi-programmation. Ils ont tous en commun les deux caractéristiques suivantes :
Par conséquent, de nombreux programmes (données) qui ne sont pas utilisés pendant le fonctionnement du programme ou qui ne sont pas utilisés temporairement occupent une grande quantité d'espace mémoire, et certains travaux qui doivent être exécutés ne peuvent pas être chargés et exécutés, ce qui gaspille évidemment de précieuses ressources mémoire. .
- Unique : Le travail doit être chargé en mémoire en une seule fois avant de pouvoir commencer à s'exécuter. Cela conduira à deux situations : 1) Lorsque le travail est volumineux et ne peut pas être chargé dans la mémoire, le travail ne pourra pas s'exécuter
2) Lorsqu'un grand nombre de travaux doivent être exécutés, car la mémoire n'est pas disponible ; suffisant pour accueillir tous les travaux, seulement cela peut provoquer l'exécution de quelques travaux en premier, ce qui entraîne une diminution de la multiprogrammation.
- Résidence : Une fois le travail chargé dans la mémoire, il sera toujours résident dans la mémoire, et aucune partie ne sera échangée, jusqu'à ce que le travail soit terminé. Un processus en cours d'exécution sera bloqué en attente d'E/S et peut être dans un état d'attente à long terme.
1.1 La définition et les caractéristiques de la mémoire virtuelle
Basé sur le principe delocalité, lorsque le programme est chargé, vous pouvez charger une partie du programme dans la mémoire et laisser le reste en externe mémoire. Démarrer l’exécution du programme. Lors de l'exécution du programme, lorsque les informations consultées ne sont pas dans la mémoire, le système d'exploitation transfère la partie requise dans la mémoire , puis continue d'exécuter le programme. D'autre part, le système d'exploitation échange le contenu temporairement inutilisé de la mémoire vers la mémoire externe, libérant ainsi de l'espace pour stocker les informations qui seront transférées dans la mémoire. De cette façon, puisque le système fournit des
fonctions de chargement partiel, de chargement de demande et de remplacement(complètement transparentes pour l'utilisateur), l'utilisateur a l'impression qu'il existe une mémoire beaucoup plus grande que la mémoire physique réelle, appelée Mémoire virtuelle. La taille de la mémoire virtuelle est déterminée par la structure d'adresse de l'ordinateur
et n'est pas une simple somme de mémoire et de mémoire externe.La mémoire virtuelle présente les trois caractéristiques principales suivantes :
Plusieurs fois
- : Il n'est pas nécessaire de charger la mémoire en une seule fois lorsque le travail est en cours d'exécution, mais elle peut être divisée en plusieurs fois et chargée dans la mémoire pour fonctionner.
- Swapability : Il n'est pas nécessaire de conserver la mémoire résidente pendant l'exécution du travail, mais permet d'effectuer des échanges entrants et sortants pendant le processus d'exécution du travail.
- Virtualité : augmentez logiquement la capacité de mémoire afin que la capacité de mémoire vue par l'utilisateur soit beaucoup plus grande que la capacité de mémoire réelle.
La mémoire virtuelle permet à un travail d'être transféré plusieurs fois dans la mémoire
.Lors de l'utilisation de la méthode d'allocation continue, une partie considérable de l'espace mémoire sera dans un état d'inactivité temporaire ou "permanent", provoquant un grave gaspillage de ressources mémoire, et il ne sera logiquement pas possible d'étendre la capacité mémoire.
Par conséquent, la mise en œuvre de la mémoire virtuelle doit être basée sur la allocation discrèteméthode de gestion de la mémoire. Il existe trois façons d'implémenter la mémoire virtuelle :
Pagination des requêtes- Gestion du stockage
- Segmentation des requêtes Gestion du stockage
- Pagination des segments Gestion du stockage
- Quelle que soit la méthode, certaines exigences sont requises Support matériel
Une certaine quantité de mémoire et de stockage externe.
- Mécanisme de table de pages (ou mécanisme de table de segments), comme structure de données principale.
- Mécanisme d'interruption, lorsque la partie à laquelle accéder par le programme utilisateur n'a pas été transférée dans la mémoire, une interruption est générée.
- Mécanisme de conversion d'adresse, conversion d'adresse logique en adresse physique.
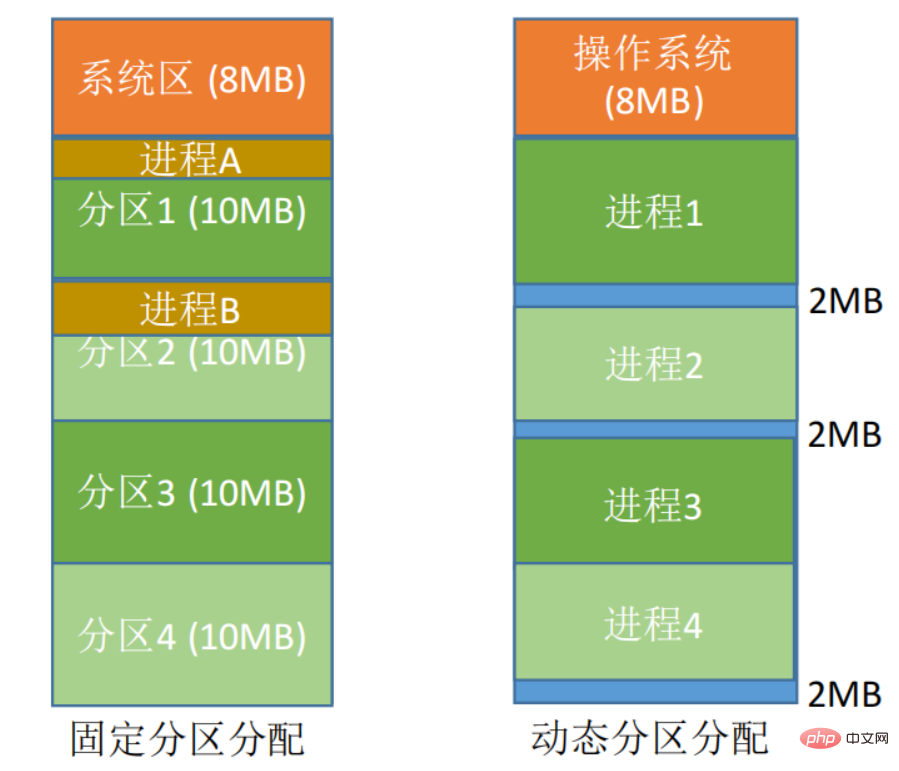
Méthode d'allocation continue: fait référence à l'allocation d'un espace mémoire continu pour un programme utilisateur.
- Allocation de partition fixe : Divisez l'espace mémoire en plusieurs zones de taille fixe. Un seul travail est chargé dans chaque partition et plusieurs travaux peuvent être exécutés simultanément. Le manque de flexibilité produira beaucoup de fragments internes et l'utilisation de la mémoire est très faible.
- Allocation dynamique de partition : Allouez dynamiquement de l'espace mémoire au processus en fonction de ses besoins réels. Lorsqu'une tâche est chargée en mémoire, la mémoire disponible est divisée en une zone continue pour la tâche et la taille de la partition est exactement adaptée à la taille de la tâche. Il y aura beaucoup de débris extérieurs.
Méthode d'allocation discrète : Charger un processus de manière dispersée dans de nombreuses partitions non adjacentes, afin que la mémoire puisse être pleinement utilisée.
La pagination des demandesLe concept de stockage de pagination :
2. Gestion de la pagination des demandes pour implémenter la mémoire virtuelle
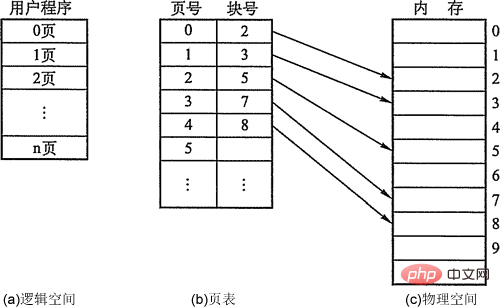
- Page, cadre de page et bloc. Le bloc dans process est appelé page ou page (Page), avec le numéro de page ; le bloc dans memory est appelé Page Frame (Page Frame, page frame = bloc mémoire = bloc physique = physique Page ), avec numéro de cadre de page. Le stockage externe est également divisé dans la même unité, directement appelée Block. Lorsqu'un processus est exécuté, il doit demander de l'espace mémoire principale, ce qui signifie que chaque page doit se voir attribuer un cadre de page disponible dans la mémoire principale, ce qui crée une correspondance biunivoque entre les pages et les cadres de page. Chaque page n'a pas besoin d'être stockée consécutivement et peut être placée dans des cadres de page non adjacents.
- Structure de l'adresse : la première partie est le numéro de page P et la dernière partie est le décalage en page W. La longueur de l'adresse est de 32 bits, dont les bits 0 à 11 sont l'adresse intra-page, c'est-à-dire que la taille de chaque page est de 4 Ko ; les bits 12 à 31 sont le numéro de page et l'espace d'adressage permet jusqu'à 2 ^ 20. pages.
- Tableau des pages. Afin de faciliter la recherche du bloc physique correspondant à chaque page du processus dans la mémoire, le système établit une table de pages pour chaque processus pour enregistrer le numéro de bloc physique correspondant à la page dans la mémoire. La table des pages est généralement stockée dans la mémoire. mémoire. . Une fois la table des pages configurée, lorsque le processus est exécuté, le numéro de bloc physique de chaque page dans la mémoire peut être trouvé en consultant la table. On peut voir que le rôle de la table des pages est d'implémenter le mappage d'adresses des numéros de page aux numéros de blocs physiques.
est actuellement la méthode la plus couramment utilisée pour implémenter la mémoire virtuelle. Le système de pagination de demande est construit sur le
système de pagination de baseAfin de prendre en charge la fonction de mémoire virtuelle, la fonction requête de pagination et la fonction
remplacement de pagesont ajoutées. Dans le système de pagination des requêtes, seule une partie des pages actuellement requises doit être chargée dans la mémoire avant que le travail puisse être démarré. Pendant l'exécution du travail, lorsque la page à accéder n'est pas dans la mémoire, elle peut être importée via la fonction de pagination. En même temps, les pages temporairement inutilisées peuvent être transférées vers un stockage externe via la fonction de remplacement. pour libérer de l'espace mémoire. Afin de mettre en œuvre la pagination des demandes, le système doit fournir une certaine prise en charge matérielle. En plus d'un système informatique qui nécessite
une certaine quantité de mémoire et de stockage externe
, il a également besoin d'un
mécanisme de table de pages, d'un mécanisme d'interruption de faute de page et d'un mécanisme de conversion d'adresse. 2.1 Mécanisme de table de pages
Le mécanisme de table de pages du système de pagination de requêtes est différent du système de pagination de base le système de pagination de requêtes ne nécessite pas que toutes les données soient chargées dans la mémoire en même temps avant une tâche. est exécuté. Par conséquent, pendant le processus d'exécution du travail, il y aura inévitablement une situation où la page à laquelle accéder n'est pas dans la mémoire. Comment détecter et gérer cette situation sont deux problèmes fondamentaux que le système de pagination des requêtes doit résoudre. À cette fin, quatre champs sont ajoutés à l'entrée du tableau de la page de demande, à savoir :
Entrée du tableau des pages dans le système de pagination des demandes| Bit d'état P | Champ d'accès A | Modifier le bit M | Adresse de stockage externe |
2.2 Mécanisme d'interruption de page manquante Dans le système de pagination de requête, chaque fois que la page à accéder n'est pas dans la mémoire, une Interruption de page manquante est générée, demandant au système d'exploitation d'ajuster le page manquante en mémoire. À ce stade, le processus de défaut de page doit être bloqué (réveillez-vous une fois la pagination terminée). S'il y a un bloc libre dans la mémoire, allouez un bloc, chargez la page à charger dans le bloc et modifiez le entrée correspondante de la table des pages dans la table des pages ; s'il n'y a pas de bloc libre dans la mémoire à ce moment, une certaine page doit être éliminée (si la page éliminée a été modifiée pendant la période de mémoire, elle doit être réécrite dans la mémoire externe) . Les interruptions de défaut de page doivent également être vécues comme des interruptions, telles que la protection de l'environnement du processeur, l'analyse de la cause de l'interruption, le transfert vers le gestionnaire d'interruption de défaut de page et la restauration de l'environnement du processeur. Mais par rapport aux interruptions générales, elle présente les deux différences évidentes suivantes :
2.3 Mécanisme de transformation d'adresse Le mécanisme de transformation d'adresse dans le système de pagination de requêtes est basé sur le mécanisme de transformation d'adresse du système de pagination et ajoute certaines fonctions pour réaliser une mémoire virtuelle. 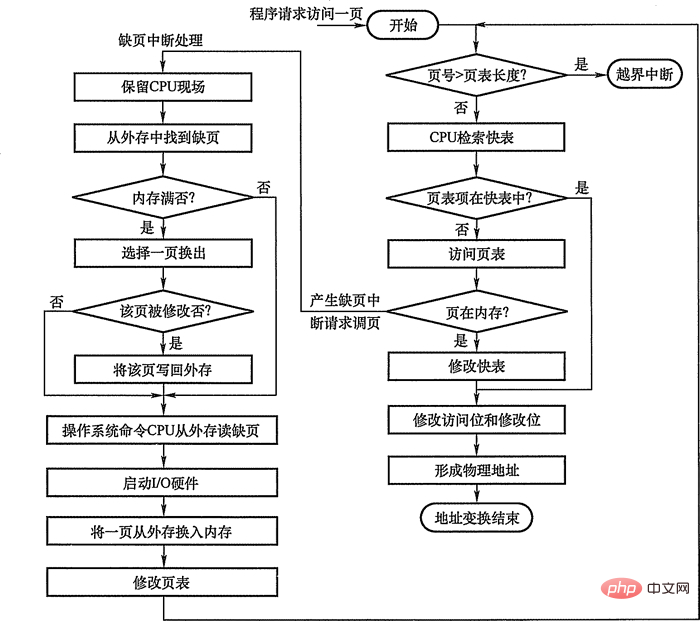 Lors de la conversion d'adresse, recherchez d'abord dans la table rapide :
3. Algorithme de remplacement de page Lorsqu'un processus est en cours d'exécution, si la page à laquelle il accède n'est pas dans la mémoire et doit être importée, maisil n'y a pas d'espace libre dans la mémoire, une page de le programme doit être appelé de la mémoire ou les données sont envoyées à la zone d'échange du disque. 3.1 Algorithme de remplacement optimal (OPT) Meilleur algorithme de remplacement (Optimal, OPT)La page éliminée sélectionnée ne sera plus jamais utilisée à l'avenir, ou ne sera plus utilisée dans la période la plus longue visitée Pages, afin d'assurer le taux de défauts de page le plus bas. Mais parce que les gens actuellement ne peuvent pas prédirelaquelle des milliers de pages dans la mémoire du processus ne sera plus consultée dans le futur le plus longtemps, donc cet algorithme ne peut pas être implémenté, mais le meilleur algorithme de remplacement peut être utilisé pour évaluer d'autres algorithmes . Supposons que le système alloue trois blocs physiques à un processus et considérons la chaîne de référence de numéro de page suivante : 7, 0, 1, 2, 0, 3, 0, 4, 2, 3, 0, 3, 2, 1, 2, 0, 1, 7, 0, 1
Lors de l'utilisation de l'algorithme FIFO, 12 remplacements de pages sont effectués, soit exactement deux fois plus que l'algorithme de remplacement optimal. L'algorithme FIFO produira également un phénomène anormal où lorsque le nombre de blocs physiques alloués augmente, le nombre de défauts de page augmente au lieu de diminuer. Cela a été découvert par Belady en 1969, c'est pourquoi on l'appelle Anomalie Belady, comme. indiqué dans le tableau ci-dessous.
Seul l'algorithme FIFO peut rencontrer des anomalies Belady, tandis que les algorithmes LRU et OPT ne connaîtront jamais d'anomalies Belady. 3.3 Algorithme de remplacement les moins récemment utilisés (LRU) Les moins récemment utilisées (LRU, Les moins récemment utilisées)Sélection de l'algorithme de remplacementLes pages qui n'ont pas été visitées depuis le plus longtemps seront éliminées, Il est supposé que les pages qui n'ont pas été visitées au cours de la période écoulée pourraient ne pas l'être dans un avenir proche. Cet algorithme définit un champ de visite pour chaque page afin d'enregistrer le temps écoulé depuis le dernier accès à la page Lors de l'élimination des pages, sélectionnez celle avec la plus grande valeur parmi les pages existantes à éliminer.
LRU a de meilleures performances, mais nécessite une prise en charge matérielle pour les registres et les piles, et est plus cher. LRU est un algorithme de stack class. Théoriquement, il peut être prouvé que l’exception Belady est impossible à produire dans les algorithmes de pile. L'algorithme FIFO est implémenté sur la base d'une file d'attente et non d'un algorithme de pile. 3.4 Algorithme de remplacement d'horloge (CLOCK) Les performances de l'algorithme LRU sont proches de l'OPT, mais il est difficile à mettre en œuvre et coûteux ; l'algorithme FIFO est simple à mettre en œuvre, mais a des performances médiocres. Par conséquent, les concepteurs de systèmes d'exploitation ont essayé de nombreux algorithmes, essayant d'approcher les performances de LRU avec une surcharge relativement faible. Ces algorithmes sont tous des variantes de l'algorithme CLOCK. L'algorithme simple CLOCK associe un bit supplémentaire à chaque trame, appelé bit d'utilisation. Lorsqu'une page est chargée pour la première fois dans la mémoire principale puis consultée, le bit d'utilisation est défini sur 1. Pour l'algorithme de remplacement de page, l'ensemble de cadres candidats au remplacement est considéré comme un tampon circulaire et est associé à un pointeur. Lorsqu'une page est remplacée, le pointeur est défini pour pointer vers l'image suivante dans le tampon. Lorsqu'une page doit être remplacée, le système d'exploitation analyse le tampon pour trouver la première image avec un bit d'utilisation de 0. Chaque fois qu'une trame avec un bit d'utilisation de 1 est rencontrée, le système d'exploitation réinitialise le bit à 0 ; si toutes les trames ont un bit d'utilisation de 1, le pointeur termine un cycle dans le tampon, effaçant tous les bits d'utilisation mis à 0 et reste. à la position d'origine, en remplaçant la page dans le cadre. Étant donné que cet algorithme vérifie cycliquement l'état de chaque page, il est appelé algorithme CLOCK, également connu sous le nom d'algorithme Non récemment utilisé (NRU). Les performances de l'algorithme CLOCK sont relativement proches de celles de LRU, et en augmentant le nombre de bits utilisés, l'algorithme CLOCK peut être rendu plus efficace. En ajoutant un bit modifié modifié au bit utilisé, nous obtenons un algorithme de remplacement CLOCK amélioré. Chaque image se trouve dans l'une des quatre situations suivantes :
les pages qui n'ont pas changé sont préférées lors de leur remplacement. Cela fait gagner du temps puisque les pages modifiées doivent être réécrites avant d'être remplacées. 4. Stratégie d'allocation de pages4.1 Taille de l'ensemble résident Pour la mémoire virtuelle paginée, lors de la préparation à l'exécution, il n'est pas nécessaire ni impossible de lire toutes les pages d'un processus dans la mémoire principale. , par conséquent, le système d'exploitation doit décider du nombre de pages à lire. Autrement dit,combien d'espace mémoire principale allouer à un processus spécifique, cela doit prendre en compte les points suivants :
4.2 Moment de chargement des pages Afin de déterminer le moment où le système charge les pages manquantes lorsque le processus est en cours d'exécution, les deux stratégies de pagination suivantes peuvent être adoptées :
Le stockage externe dans le système de pagination des requêtes est divisé en deux parties : la zone de fichiers pour le stockage des fichiers et la page d'échange. zone d'échange. La zone d'échange utilise généralement la méthode d'allocation continue, tandis que la zone de fichiers utilise la méthode d'allocation discrète, de sorte que la vitesse d'E/S disque de la zone d'échange est plus rapide que celle de la zone de fichiers. Il existe trois situations dans lesquelles les pages peuvent être transférées : Le système dispose de suffisamment d'espace dans la zone d'échange : Vous pouvez transférer toutes les pages requises depuis la zone d'échange pour augmenter la vitesse de transfert des pages. Pour cette raison, avant l'exécution du processus, les fichiers liés au processus doivent être copiés de la zone de fichiers vers la zone d'échange.
comportement de planification de page fréquent est appelé gigue, ou turbulence. Si un processus passe plus de temps à paginer qu'il n'en faut à s'exécuter, alors le processus est en difficulté.Les interruptions de faute de page (gigue) se produisent fréquemment. La raison principale est quele nombre de pages fréquemment consultées par un processus est supérieur au nombre de cadres de page physiques disponibles. La technologie de mémoire virtuelle peut conserver davantage de processus en mémoire pour améliorer l'efficacité du système. En régime permanent, la quasi-totalité de la mémoire principale est occupée par des blocs de processus, et le processeur et le système d'exploitation ont un accès direct à autant de processus que possible. Mais s'il n'est pas géré correctement, la majeure partie du temps du processeur sera consacrée à échanger des blocs, c'est-à-dire à demander l'opération de chargement de pages, plutôt qu'à exécuter les instructions du processus, ce qui réduira considérablement l'efficacité du système. 5.2 Ensemble de travail (ensemble résident)
L'ensemble de travail (ou ensemble résident) fait référence à l'ensemble de pages auxquelles un processus doit accéder dans un certain intervalle. Les pages fréquemment utilisées doivent figurer dans l'ensemble de travail, tandis que les pages qui n'ont pas été utilisées depuis longtemps sont supprimées de l'ensemble de travail. Afin d'éviter les perturbations du système, vous devez choisir une taille d'ensemble de travail appropriée. 6. Résumé La méthode de gestion depagination et la méthode de gestion de segmentation sont similaires à de nombreux endroits, comme la mémoire est discontinue, et il existe des mécanismes de traduction d'adresses pour le mappage d'adresses, etc. Cependant, il existe de nombreuses différences entre les deux. Le Tableau 3-20 répertorie la comparaison entre la gestion de pagination et la gestion de segmentation sous divers aspects.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!