
Maison >base de données >tutoriel mysql >Compréhension approfondie du fonctionnement de l'optimiseur d'index MySQL
Compréhension approfondie du fonctionnement de l'optimiseur d'index MySQL

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-11-09 14:05:241829parcourir
Cet article vous apporte des connaissances pertinentes sur mysql, qui présente principalement un contenu pertinent sur le principe de fonctionnement de l'optimiseur d'index, y compris la composition du serveur MySQL, le principe de sélection d'index par l'optimiseur MySQL et l'analyse des coûts SQL, et enfin résumer l'ensemble du processus de requête via une requête de sélection. Examinons-le ensemble, j'espère que cela sera utile à tout le monde.

Apprentissage recommandé : Tutoriel vidéo mysql
1. Comment l'optimiseur MySQL sélectionne les index
Jetons un coup d'œil à ce tableau Le champ SUB_ODR_ID crée deux index liés D'après ce que nous avons dit plus tôt. nous avons appris que nous créons une CLÉ PRIMAIRE (ID)自增主键索引,(LOG_ID, SUB_ODR_ID) et la définissons comme un index conjoint et un index unique, et définissons deux index à deux moments : CREATE_TIME et UPDATE_TIME.
CREATE TABLE `***` ( `ID` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键id', `LOG_ID` varchar(32) NOT NULL COMMENT '交易流水号', `ODR_ID` varchar(32) NOT NULL COMMENT '父单号', `SUB_ODR_ID` varchar(32) NOT NULL COMMENT '子单号', `CREATE_TIME` datetime(0) NOT NULL COMMENT '创建时间', `CREATE_BY` varchar(32) NOT NULL COMMENT ' 创建人', `UPDATE_TIME` datetime(0) NOT NULL DEFAULT CURRENT_TIMESTAMP(0) ON UPDATE CURRENT_TIMESTAMP(0) COMMENT '更新时间', `UPDATE_BY` varchar(32) NOT NULL COMMENT '更新人', PRIMARY KEY (`ID`) USING BTREE, UNIQUE INDEX `UNQ_LOG_SUBODR_ID`(`LOG_ID`, `SUB_ODR_ID`) USING BTREE, INDEX `IDX_ODR_ID`(`ODR_ID`) USING BTREE, INDEX `IDX_SUB_ID`(`SUB_ODR_ID`) USING BTREE, INDEX `IDX_CREATE_TIME`(`CREATE_TIME`) USING BTREE, INDEX `IDX_UPDATE_TIME`(`UPDATE_TIME`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 1 SET = utf8 COLLATE = utf8_general_ci COMMENT = '分摊业务明细表' ROW_FORMAT = Dynamic;
Dans le champ de requête SUB_ODR_ID, trois index liés peuvent théoriquement être utilisés : UNQ_LOG_SUBODR_ID, IDX_SUB_ID Comment l'optimiseur MySQL choisit-il parmi ces trois index ?
Dans une base de données relationnelle, l'arbre B+ n'est qu'une structure de données utilisée pour le stockage.
Comment l'utiliser dépend de l'optimiseur de la base de données. L'optimiseur détermine la sélection d'un index spécifique, appelé plan d'exécution. La sélection de l'optimiseur est basée sur le coût : plus le coût est faible, plus l'indice de préférence est élevé.
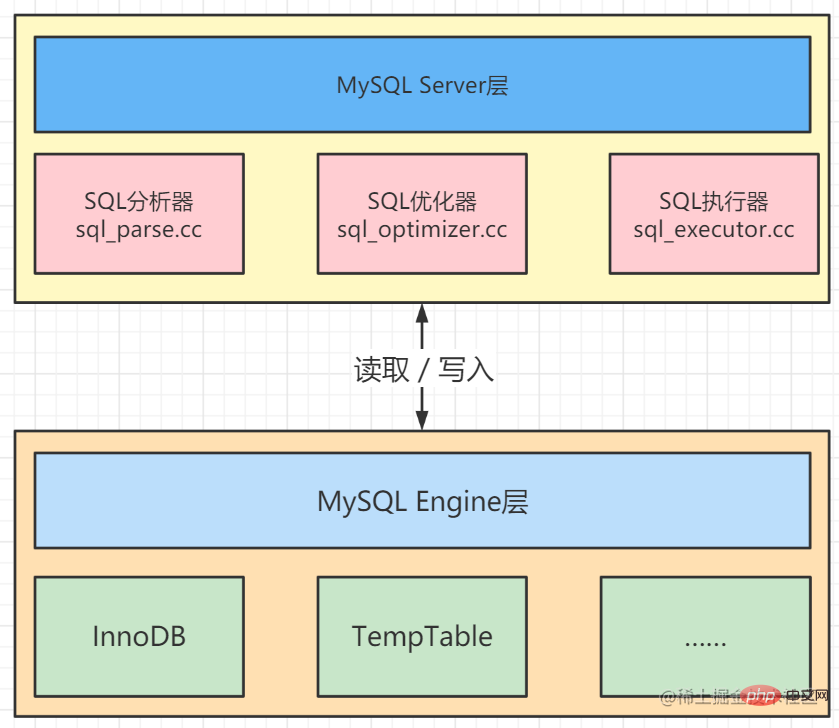
1. Composition de la base de données MySQL
La base de données MySQL est composée d'une couche Serveur (serveur) et d'une couche Moteur (moteur).
La couche Serve possède un analyseur SQL, un optimiseur SQL et un exécuteur SQL, qui sont responsables du processus d'exécution spécifique des instructions SQL.
La couche Moteur est responsable du stockage de données spécifiques, telles que le moteur de stockage InnoDB le plus couramment utilisé et le moteur TempTable utilisé pour stocker les ensembles de résultats temporaires en mémoire.
L'optimiseur SQL analysera tous les plans d'exécution possibles et choisira l'exécution la moins coûteuse. Cet optimiseur est appelé CBO (cost-based optimiseur).
2. Calcul du coût de la base de données MySQL
Dans MySQL, le coût de calcul d'un SQL est facile à comprendre, qui consiste à accéder à la base de données (page de base de données, disque) + traiter les données.
Coût du CPU, qui représente le coût de calcul, tel que la comparaison des valeurs des clés d'index, la comparaison des valeurs d'enregistrement et le tri des ensembles de résultats. Ces opérations sont effectuées au coût de la couche serveur
IO, qui représente le coût des IO au niveau du moteur. MySQL 8.0 peut calculer séparément le coût de lecture des IO de la mémoire et des IO du disque en distinguant si les données de la table sont en mémoire.
Cost = Server Cost + Engine Cost = CPU Cost + IO Cost
L'optimiseur MySQL estime que si un morceau de SQL doit créer une table temporaire basée sur le disque, alors le coût à ce moment est le plus élevé, soit 20 fois celui d'une table temporaire basée sur la mémoire. Le coût de comparaison des valeurs de clé d'index et des enregistrements est très faible, mais s'il existe de nombreux enregistrements à comparer, le coût peut être très élevé.
L'optimiseur MySQL estime que le coût de la lecture à partir du disque est 4 fois supérieur au coût de la mémoire (le coût n'est pas statique et variera en fonction du matériel).
2. Coût des requêtes MySQL
Vérifiez la valeur de chaque coût et le principe de fonctionnement de l'optimiseur MySQL. Nous exécutons l'instruction SQL suivante et analysons le processus d'exécution. La sélection de l'index MySQL est basée sur le coût d'exécution SQL
EXPLAIN FORMAT=json select * from test.fork_business_detail f where f.sub_odr_id = ''.
read_cost signifie from Le coût de lecture par le moteur de stockage InnoDB ;
eval_cost représente le coût CPU de la couche serveur ;
prefix_cost représente le coût total de SQL ;
data_read_per_join représente le nombre total d'octets dans l'enregistrement lu.
{
"query_block": {
"cost_info": {
"query_cost": "1.20"
},
"table": {
"access_type": "ref",
"possible_keys": [
"IDX_SUB_ID"
],
"key": "IDX_SUB_ID",
"used_key_parts": [
"SUB_ODR_ID"
],
"key_length": "98",
"ref": [
"const"
],
"cost_info": {
"read_cost": "1.00",
"eval_cost": "0.20",
"prefix_cost": "1.20",
"data_read_per_join": "1K"
},
"used_columns": [
"ID",
"LOG_ID",
"ODR_ID",
"SUB_ODR_ID",
"CREATE_TIME",
"CREATE_BY",
"UPDATE_TIME",
"UPDATE_BY"
]
}
}
}
3. Processus d'exécution SELECT
Comment améliorer les performances des requêtes MySQL ? Tout d’abord, vous devez comprendre l’ensemble du processus de traitement SQL par l’optimiseur de requêtes. Le processus d'exécution de SELECT SQL est pris comme exemple, comme le montre la figure ci-dessous :
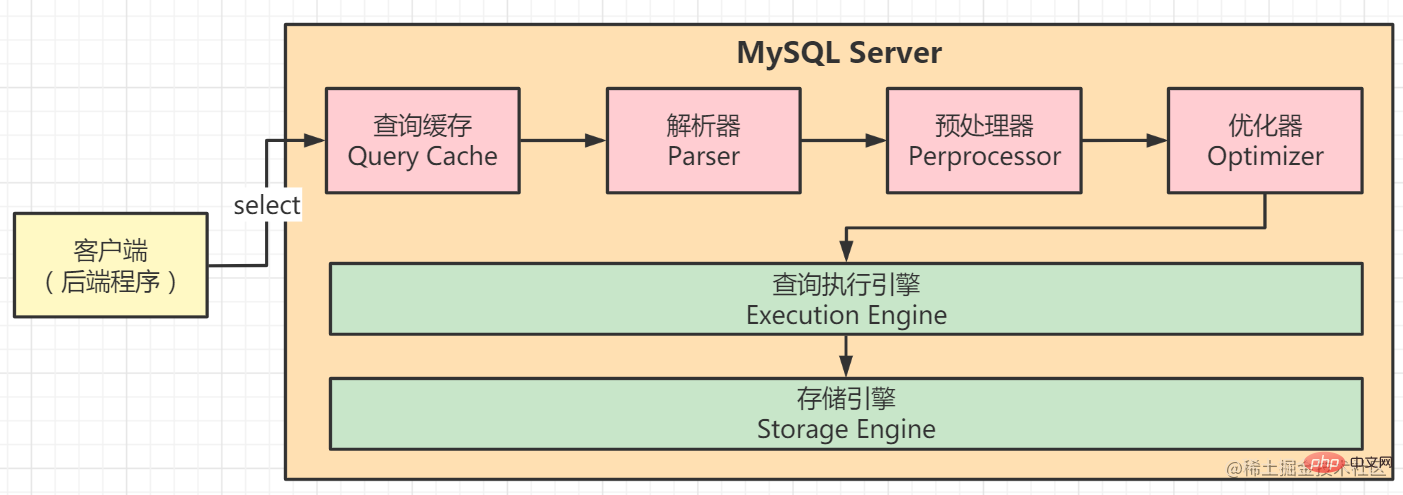
Le client envoie une requête SELECT au serveur ; le serveur vérifie d'abord le cache des requêtes. Si le cache est atteint, les résultats stockés dans le cache seront renvoyés immédiatement. Sinon, passez à l'étape suivante :
Le serveur effectue l'analyse et le prétraitement SQL, et l'optimiseur de requête génère le plan d'exécution correspondant ; MySQL appelle l'API du moteur de stockage pour exécuter la requête en fonction du plan d'exécution généré par l'optimiseur ; le résultat sera renvoyé au client et également placé dans le cache de requêtes.
Apprentissage recommandé : Tutoriel vidéo mysql
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Partage de cas de requête multi-tables de base MySQL
- Parlons des quatre façons de changer le mot de passe dans MySQL (jetez un coup d'œil rapide pour les débutants)
- Parlons brièvement de la requête de jointure dans MySQL
- Ne paniquez pas quand quelque chose se produit, enregistrez-le d'abord : mysql en optimisation lente des requêtes
- Comment utiliser MySQL distinct