
Maison >développement back-end >Tutoriel Python >Enregistrements pratiques de certains problèmes liés à la sauvegarde et au chargement des modèles pytorch
Enregistrements pratiques de certains problèmes liés à la sauvegarde et au chargement des modèles pytorch

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-11-03 17:33:322794parcourir
Cet article vous apporte des connaissances pertinentes sur Python Il présente principalement des enregistrements pratiques de certains problèmes liés à la sauvegarde et au chargement des modèles pytorch. J'espère qu'il sera utile à tout le monde.

【Recommandations associées : Tutoriel vidéo Python3】
1. Comment enregistrer et charger des modèles dans Torch
1. Enregistrez et chargez les paramètres et les structures du modèle
torch.save(model,path) torch.load(path)
2. du chargement du modèle - Cette méthode est plus sûre, mais un peu plus gênante
torch.save(model.state_dict(),path) model_state_dic = torch.load(path) model.load_state_dic(model_state_dic)
2. Problèmes de sauvegarde et de chargement des modèles dans torch
1. Problèmes de chargement des modèles après avoir enregistré la structure et les paramètres du modèle dans un seul modèle de carte
.Modèle Lors de l'enregistrement, le chemin d'accès au fichier de définition de structure du modèle sera enregistré lors du chargement, il sera analysé en fonction du chemin puis chargé avec les paramètres. Lorsque le chemin d'accès au fichier de définition de modèle est modifié, une erreur sera signalée. lors de l'utilisation de torch.load(path).
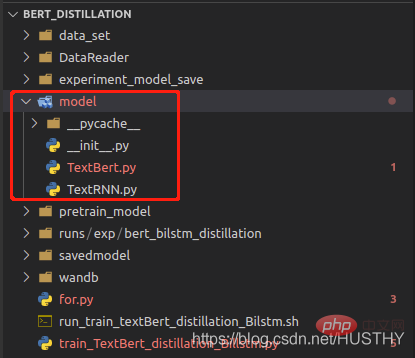
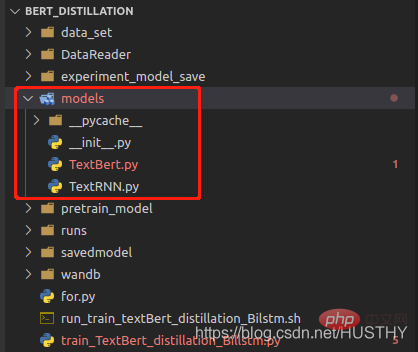

Après avoir modifié le dossier modèle en modèles, une erreur sera signalée lors du nouveau chargement.
import torch from model.TextRNN import TextRNN load_model = torch.load('experiment_model_save/textRNN.bin') print('load_model',load_model)
De cette façon de sauvegarder la structure complète et les paramètres du modèle, veillez à ne pas modifier le chemin du fichier de définition du modèle.
2. Après avoir enregistré le modèle de formation mono-carte sur une machine multi-cartes, une erreur sera signalée lors de son chargement sur une machine mono-carte
À partir de 0 sur une machine multi-cartes avec plusieurs cartes graphiques, maintenant, le modèle est formé sur n>=1 après avoir enregistré la carte graphique. Lorsque la copie est chargée sur une machine à carte unique
import torch from model.TextRNN import TextRNN load_model = torch.load('experiment_model_save/textRNN_cuda_1.bin') print('load_model',load_model)
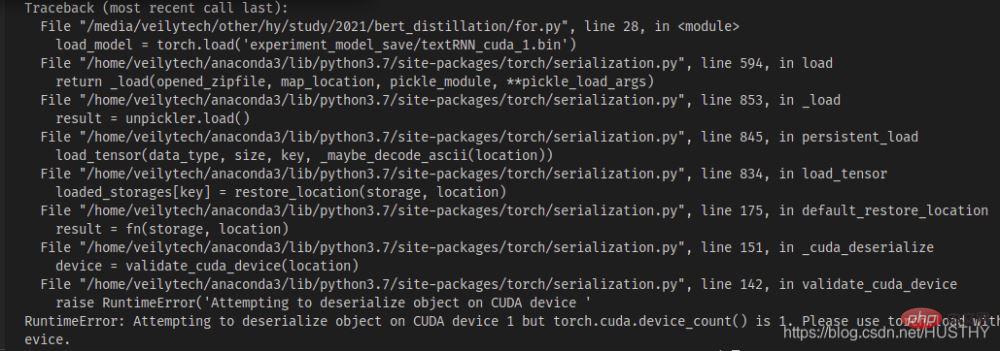
, il y aura un problème de non-concordance de périphérique cuda - le type de widget de segment de code de modèle. vous avez enregistré cuda1, donc lorsque vous l'ouvrez avec torch.load(), il recherchera par défaut cuda1, puis chargera le modèle sur l'appareil. À ce stade, vous pouvez directement utiliser map_location pour résoudre le problème et charger le modèle sur le CPU.
load_model = torch.load('experiment_model_save/textRNN_cuda_1.bin',map_location=torch.device('cpu'))
3. Problèmes qui surviennent lorsque les modèles d'entraînement multi-cartes enregistrent la structure et les paramètres du modèle, puis les chargent
Après avoir entraîné le modèle avec plusieurs GPU en même temps, que la structure et les paramètres du modèle soient enregistrés ensemble ou que le modèle soit enregistré. les paramètres sont enregistrés séparément, puis sous une seule carte. Des problèmes se produiront lors du chargement de
a, enregistrez la structure du modèle et les paramètres ensemble, puis utilisez la méthode multi-processus ci-dessus lors du chargement de

torch.distributed.init_process_group(backend='nccl')
formation du modèle, vous devez donc déclarez-le également lors du chargement, sinon une erreur sera signalée.
b. Enregistrer les paramètres du modèle séparément
model = Transformer(num_encoder_layers=6,num_decoder_layers=6) state_dict = torch.load('train_model/clip/experiment.pt') model.load_state_dict(state_dict)
posera également des problèmes, mais le problème ici est que la clé du dictionnaire de paramètres est différente de la clé définie par le modèle

La raison est que sous multi-GPU formation, une formation distribuée est utilisée Le modèle sera empaqueté à un moment donné, et le code est le suivant :
model = torch.load('train_model/clip/Vtransformers_bert_6_layers_encoder_clip.bin') print(model) model.cuda(args.local_rank) 。。。。。。 model = nn.parallel.DistributedDataParallel(model,device_ids=[args.local_rank],find_unused_parameters=True) print('model',model)
La structure du modèle avant l'empaquetage :

Le modèle empaqueté
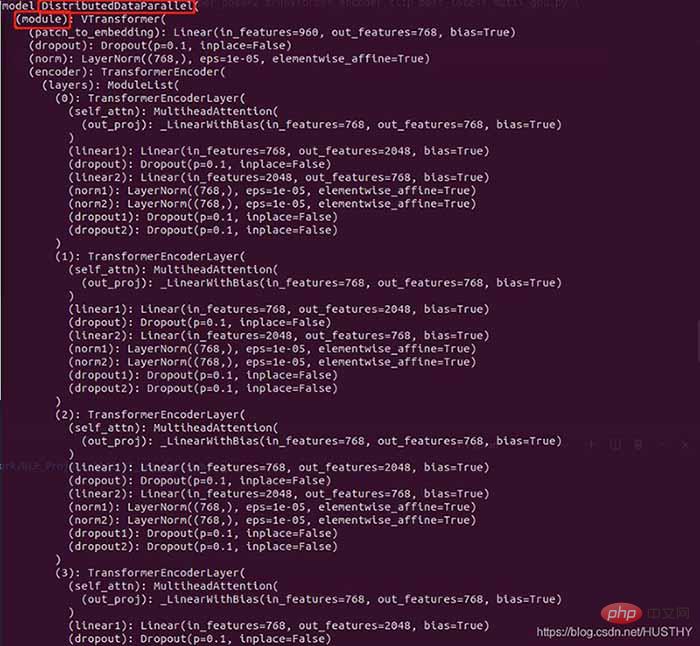
Il y a plus de DistributedDataParallel et de modules dans la couche externe, cela conduira donc à un environnement à carte unique. Lors du chargement des poids du modèle, les clés de poids sont incohérentes.
3. La bonne façon de sauvegarder et de charger le modèle
if gpu_count > 1:
torch.save(model.module.state_dict(),save_path)
else:
torch.save(model.state_dict(),save_path)
model = Transformer(num_encoder_layers=6,num_decoder_layers=6)
state_dict = torch.load(save_path)
model.load_state_dict(state_dict)C'est un meilleur paradigme, et il n'y aura aucune erreur de chargement.
【Recommandation associée : Tutoriel vidéo Python3】
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Obtenez des informations sur les produits Amazon à l'aide de Python
- Analyse détaillée de la mise en œuvre par Python des tâches planifiées apscheduler
- Découvrez le garbage collector dans CPython dans un article
- Comment utiliser la bibliothèque libpcap pour la capture de paquets et le traitement des données en Python