
Maison >base de données >tutoriel mysql >Parlons de la structure de l'index MySQL
Parlons de la structure de l'index MySQL

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-08-31 17:49:262243parcourir

Apprentissage recommandé : Tutoriel vidéo MySQL
Introduction
En plus des données, le système de base de données maintient également des structures de données qui satisfont des algorithmes de recherche spécifiques. Ces structures de données font référence (pointent vers) les données d'une manière ou d'une autre. afin que des algorithmes de recherche avancée puissent être implémentés sur ces structures de données. Cette structure de données est un index.
D'une manière générale, l'index lui-même est également très volumineux et ne peut pas être entièrement stocké en mémoire, c'est pourquoi l'index est souvent stocké sur disque sous la forme d'un fichier d'index.
Avantages :
1. Semblable à la création d'un index bibliographique dans une bibliothèque universitaire, cela améliore l'efficacité de la récupération des données et réduit le coût d'E/S de la base de données.
2. Triez les données via les colonnes d'index pour réduire le coût du tri des données et réduire la consommation du processeur.
Inconvénients :
1. Bien que l'index améliore considérablement la vitesse des requêtes, il réduit également la vitesse de mise à jour de la table, comme INSERT, UPDATE et DELETE sur la table. Parce que lors de la mise à jour de la table, MySQL doit non seulement enregistrer les données, mais également enregistrer le fichier d'index. Chaque fois qu'un champ qui ajoute une colonne d'index est mis à jour, les informations d'index après les modifications de valeur clé provoquées par la mise à jour seront ajustées.
2. En fait, l'index est aussi une table. La table enregistre les champs de clé primaire et d'index et pointe vers les enregistrements de la table d'entité, donc la colonne d'index prend également de la place
Exemple d'index : (utilisez. structure arborescente comme index)
À gauche se trouve le tableau de données, avec un total de deux colonnes et sept enregistrements. Celui le plus à gauche est l'adresse physique de l'enregistrement de données.
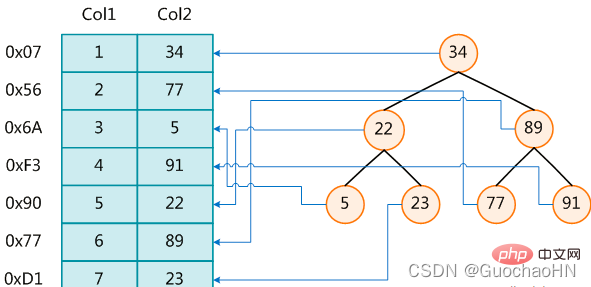
Afin d'accélérer la recherche de Col2, vous pouvez maintenir un arbre de recherche binaire comme indiqué à droite. Chaque nœud contient la valeur de la clé d'index et un pointeur vers l'adresse physique de l'enregistrement de données correspondant, de sorte que. vous pouvez utiliser la recherche binaire dans Les données correspondantes peuvent être obtenues dans une certaine complexité, récupérant ainsi rapidement les enregistrements qui remplissent les conditions.
Structure d'index (arborescence)
Comment accélérer l'interrogation des tables de base de données via des index ? Pour faciliter l'explication, nous limitons la table de base de données à inclure uniquement les deux exigences de requête suivantes :
1, sélectionnez * from user Where id=1234 ;
2, sélectionnez *from user Where id>1234 et id<. ;2345 ;(par intervalle)
Pourquoi utiliser des arbres au lieu de tables de hachage
Les performances de la requête de table de hachage par valeur sont très bonnes, la complexité temporelle est O(1), mais elle ne peut pas prendre en charge la recherche rapide de données par interval , donc l’exigence ne peut pas être satisfaite. De la même manière, bien que les performances des requêtes de l'arbre de recherche binaire équilibré soient très élevées, que la complexité temporelle soit O (logn) et que le parcours dans l'ordre de l'arbre puisse produire une séquence de données ordonnée, il ne peut pas répondre au besoin de trouver rapidement des données selon les intervalles.
Afin de prendre en charge la recherche rapide de données en fonction des intervalles, nous transformons l'arbre de recherche binaire et enchaînons les nœuds feuilles de l'arbre de recherche binaire avec une liste chaînée. Si vous souhaitez trouver des données dans un certain intervalle, il vous suffit de le faire. utilisez la valeur de départ de l'intervalle. Recherchez dans l'arborescence.Après avoir localisé un nœud dans la liste chaînée ordonnée, commencez à partir de ce nœud et parcourez la liste chaînée ordonnée jusqu'à ce que la valeur des données du nœud dans la liste chaînée ordonnée soit supérieure à la fin de l'intervalle. valeur.
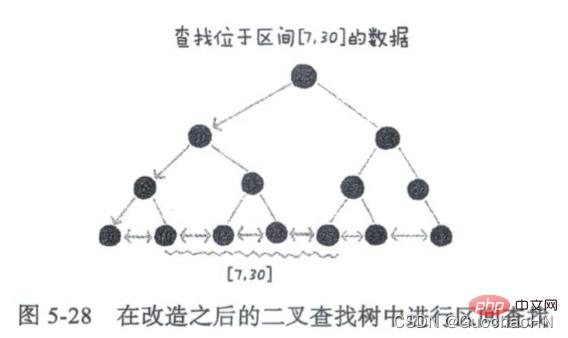
Et comme la complexité temporelle de nombreuses opérations sur l'arborescence est proportionnelle à la hauteur de l'arborescence, réduire la hauteur de l'arborescence peut réduire les opérations d'E/S disque. Par conséquent, nous construisons l'index dans un arbre m-aire (m>2). Veuillez consulter l'article suivant pour plus de détails.
BTree Index
Avant de présenter les arbres B+, comprenons d'abord les arbres B.
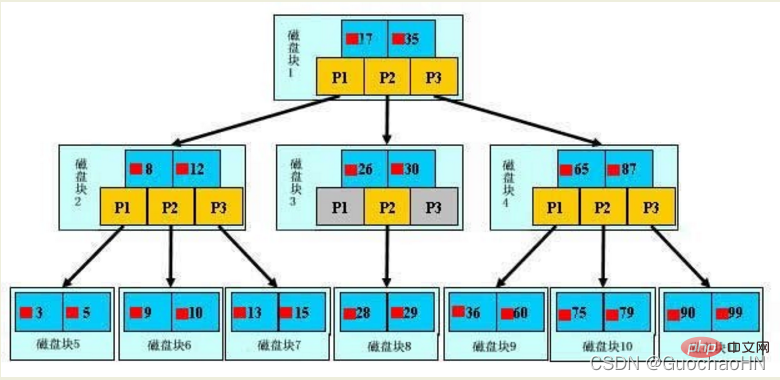
1. Introduction à l'initialisation
Un b-tree, le bloc bleu clair est appelé un bloc de disque. Vous pouvez voir que chaque bloc de disque contient plusieurs éléments de données (affichés en bleu foncé) et des pointeurs ( (affichés dans. jaune), par exemple, le bloc de disque 1 contient les éléments de données 17 et 35 et contient les pointeurs P1, P2 et P3. P1 représente les blocs de disque inférieurs à 17, P2 représente les blocs de disque compris entre 17 et 35 et P3 représente les blocs de disque supérieurs à 35.
Remarque :
Les données réelles n'existent que dans les nœuds feuilles, à savoir 3, 5, 9, 10, 13, 15, 28, 29, 36, 60, 75, 79, 90, 99. (Et c'est un intervalle de données composé de plusieurs éléments de données : 3~5,...,90~99)
Les nœuds non-feuilles ne stockent pas de données réelles, mais stockent uniquement des éléments de données qui guident la direction de recherche. Par exemple, 17 et 35 n'existent pas vraiment dans le tableau de données.
2. Processus de recherche
Si vous souhaitez trouver l'élément de données 29, vous chargerez d'abord le bloc de disque 1 du disque vers la mémoire. À ce moment, une E/S se produit. Utilisez une recherche binaire dans la mémoire pour déterminer que 29 est compris entre 17 et 35. verrouiller le pointeur P2 du bloc de disque 1. Le temps mémoire est négligeable car il est très court (par rapport aux E/S du disque). Le bloc de disque 3 est chargé du disque vers la mémoire via l'adresse disque du pointeur P2 du bloc de disque 1. Le deuxième IO se produit et 29 est compris entre 26 et 30. Verrouillez le pointeur P2 du bloc de disque 3, chargez le bloc de disque 8 dans la mémoire via le pointeur et le troisième IO se produit en même temps, une recherche binaire est effectuée. la mémoire pour trouver 29, et la requête est terminée Un total de trois IO.
Indice B+Tree
L'arbre B+ est similaire à l'arbre B, et l'arbre B+ est une version améliorée de l'arbre B. Autrement dit : l'arbre formé par l'arbre de recherche m-fork et la liste chaînée ordonnée est l'arbre B+, qui est l'index de l'arbre à stocker
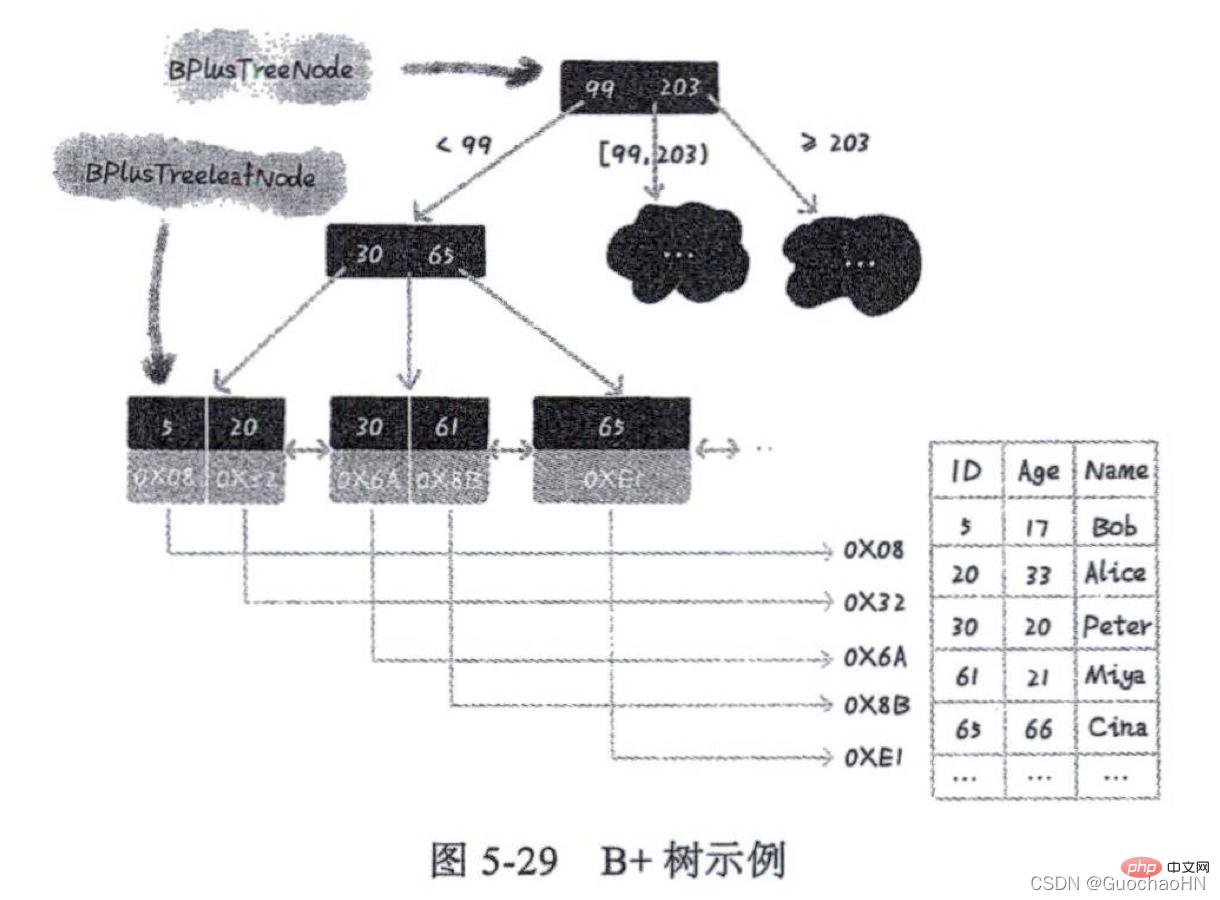
Comme le montre la figure : Les principales différences entre l'arbre B+. et l'arbre B sont les deux points suivants :
1 Les nœuds feuilles de l'arbre B+ sont connectés en série à l'aide d'une liste chaînée. Pour rechercher des données dans un certain intervalle, il vous suffit d'utiliser la valeur de départ de l'intervalle pour rechercher dans l'arborescence. Après avoir localisé un nœud dans la liste chaînée ordonnée, commencez à partir de ce nœud et parcourez en arrière le long de la liste chaînée ordonnée jusqu'à ce que. la valeur des données du nœud dans la liste chaînée ordonnée est supérieure à la valeur de fin de l'intervalle.
2. Tout nœud de l'arborescence B+ ne stocke pas de données réelles, mais n'est utilisé que pour l'indexation. L'arbre B obtient les données directement via les nœuds feuilles ; tandis que chaque nœud feuille de l'arbre B+ stocke la valeur clé et les informations d'adresse de la ligne de données. Lorsqu'un certain nœud feuille est interrogé, les informations de données réelles sont trouvées via l'adresse du nœud feuille. .
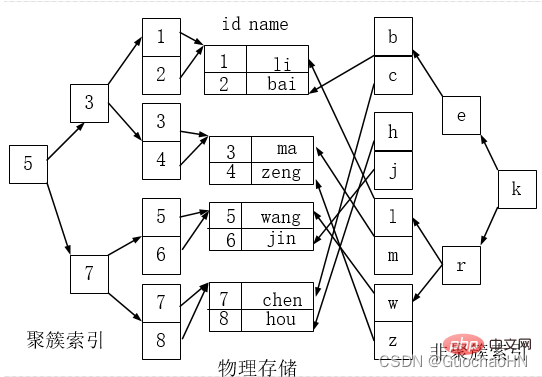
Index clusterisé et index non cluster
L'index clusterisé n'est pas un type d'index distinct, mais une méthode de stockage de données. Le terme « clustérisé » fait référence au stockage ensemble de lignes de données et de clusters de valeurs-clés adjacents.
Avantages de l'index clusterisé :
Selon l'ordre de disposition des index clusterisés, lors de l'interrogation et de l'affichage d'une certaine plage de données, puisque les données sont étroitement liées, la base de données n'a pas besoin d'extraire les données de plusieurs blocs de données, économisant ainsi un beaucoup d'IO fonctionnent.
Limitations de l'index clusterisé :
1. Pour la base de données mysql, actuellement, seul le moteur de données innodb prend en charge l'index clusterisé, tandis que Myisam ne prend pas en charge l'index clusterisé.
2. Puisqu'il ne peut y avoir qu'une seule méthode de tri de stockage physique pour les données, chaque table Mysql ne peut avoir qu'un seul index clusterisé. Il s'agit généralement de la clé primaire de la table.
3. Afin d'utiliser pleinement les caractéristiques de clustering de l'index clusterisé, la colonne de clé primaire de la table innodb doit essayer d'utiliser des ID séquentiels ordonnés, et il n'est pas recommandé d'utiliser des ID non ordonnés, tels que uuid.
Comme le montre la figure ci-dessous, l'index de gauche est un index clusterisé, car la disposition des lignes de données sur le disque est cohérente avec le tri de l'index.
Classification d'index
Indice à valeur unique
C'est-à-dire qu'un index ne contient qu'une seule colonne et qu'une table peut avoir plusieurs index à une seule colonne
随表一起建索引: CREATE TABLE customer ( id INT(10) UNSIGNED AUTO_INCREMENT , customer_no VARCHAR(200), customer_name VARCHAR(200), PRIMARY KEY(id), KEY (customer_name) ); 单独建单值索引: CREATE INDEX idx_customer_name ON customer(customer_name); 删除索引: DROP INDEX idx_customer_name on customer;
Indice unique
La valeur de la colonne d'index doit être unique , mais les valeurs nulles sont autorisées
随表一起建索引: CREATE TABLE customer ( id INT(10) UNSIGNED AUTO_INCREMENT , customer_no VARCHAR(200), customer_name VARCHAR(200), PRIMARY KEY(id), KEY (customer_name), UNIQUE (customer_no) ); 单独建唯一索引: CREATE UNIQUE INDEX idx_customer_no ON customer(customer_no); 删除索引: DROP INDEX idx_customer_no on customer ;
Index de clé primaire
Après avoir défini la clé primaire, la base de données créera automatiquement un index Innodb est un index cluster
随表一起建索引: CREATE TABLE customer ( id INT(10) UNSIGNED AUTO_INCREMENT , customer_no VARCHAR(200), customer_name VARCHAR(200), PRIMARY KEY(id) ); CREATE TABLE customer2 ( id INT(10) UNSIGNED , customer_no VARCHAR(200), customer_name VARCHAR(200), PRIMARY KEY(id) ); 单独建主键索引: ALTER TABLE customer add PRIMARY KEY customer(customer_no); 删除建主键索引: ALTER TABLE customer drop PRIMARY KEY ; 修改建主键索引: 必须先删除掉(drop)原索引,再新建(add)索引
Index composé
C'est-à-dire qu'un index contient plusieurs colonnes.
随表一起建索引: CREATE TABLE customer ( id INT(10) UNSIGNED AUTO_INCREMENT , customer_no VARCHAR(200), customer_name VARCHAR(200), PRIMARY KEY(id), KEY (customer_name), UNIQUE (customer_name), KEY (customer_no,customer_name) ); 单独建索引: CREATE INDEX idx_no_name ON customer(customer_no,customer_name); 删除索引: DROP INDEX idx_no_name on customer ;
Analyse des performances
Scénario de création d'index
Dans quelles situations il est nécessaire de créer un index
1 La clé primaire crée automatiquement un index unique
2 Les champs fréquemment utilisés comme conditions de requête doivent être. indexé
3. Les champs associés à d'autres tables dans la requête et les relations de clé étrangère sont indexés
4. Unique Le problème de sélection d'index clé/combinaison, l'index combiné est plus rentable
5. , si l'on accède au champ de tri via l'index, la vitesse de tri sera grandement améliorée
6 Statistiques ou regroupement de champs dans la requête
Dans quels cas il n'est pas nécessaire de créer un index
1.
2. Tables ou champs fréquemment ajoutés, supprimés ou modifiés Raisons : Cela améliore la vitesse de requête, mais réduit en même temps la vitesse de mise à jour de la table, comme INSERT, UPDATE et DELETE sur la table. Parce que lors de la mise à jour de la table, MySQL doit non seulement sauvegarder les données, mais aussi le fichier d'index3 Aucun index ne sera créé pour les champs qui ne sont pas utilisés dans la condition Where4. pour créer des indexApprentissage recommandé :Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Analysons la différence entre remplacer dans et remplacer dans MySQL
- Qu'est-ce qu'une impasse ? Parlons de la compréhension du blocage de MySQL
- Disposition spéciale des journaux MySQL : refaire le journal et annuler le journal
- Quelle est la différence entre MySQL et Myisam
- quelle est la différence entre les moteurs de stockage MySQL