
Maison >Java >javaDidacticiel >Exemple d'introduction pour implémenter un filtre d'expression relationnelle complexe basé sur Java
Exemple d'introduction pour implémenter un filtre d'expression relationnelle complexe basé sur Java

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-08-01 14:56:321686parcourir
Cet article vous apporte des connaissances pertinentes sur java Il présente principalement en détail comment implémenter un filtre d'expression relationnelle complexe basé sur Java. L'exemple de code dans l'article est expliqué en détail. J'espère qu'il sera utile à tout le monde.

Étude recommandée : "Tutoriel vidéo Java"
Contexte
Récemment, il y a une nouvelle exigence, qui nécessite de mettre en place une expression relationnelle complexe en arrière-plan et d'analyser si l'utilisateur remplit la condition en fonction de l'identifiant spécifié par l'utilisateur. , le paramètre d'arrière-plan est similaire aux conditions de recherche de ZenTao

Mais la différence est que ZenTao n'a que deux groupes, chaque groupe a jusqu'à trois conditions
Et les groupes et les relations ici peuvent être plus complexe, il existe des groupes au sein des groupes, et chaque condition a une relation ET ou. Pour des raisons de confidentialité, le prototype ne sera pas diffusé.
Quand j'ai vu cette exigence, en tant que backend, la première chose à laquelle j'ai pensé était un framework d'expression comme QLEpress. Tant que vous construisez une expression, vous pouvez filtrer rapidement les utilisateurs cibles en analysant l'expression. que Le camarade de classe front-end a quitté, car en tant que framework basé sur les données utilisant Vue ou React, il est trop difficile de convertir l'expression dans la forme ci-dessus, alors j'y ai réfléchi et j'ai décidé de définir moi-même une structure de données pour implémenter l'expression .analyser. Pratique à traiter pour les étudiants front-end.
Préparation de l'analyse
Bien que l'expression soit implémentée à l'aide d'une classe, il s'agit toujours essentiellement d'une expression. Énumérons une expression simple : en supposant que les conditions sont a, b, c, d, nous pouvons construire une expression à volonté :
boolean result=a>100 && b=10 || (c != 3 && d c726c10349b1b4a3771343bf1a3a9eb7100 && b=10 || (c != 3 && d 5a1b319c9256b5adbf09f78b85738671100 中的100)。
另外,还有关联关系(且、或)和计算优先级这几个属性组成。
于是我们对表达式进行简化:
令a>100 =>A,b=10 =>B,c!=3=>C ,dc849c18f1683bfc1ac5adfe2d1f542bdD,于是我们得到:
result=A && B || (C && D)
现在问题来了,如何处理优先级呢?
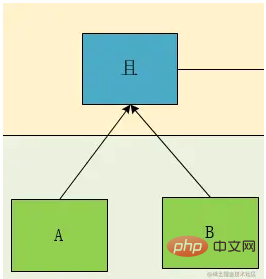
如上表达式,很明显,这是一个大学里学过的标准的中序表达式,于是,我们画一下它的树形图:
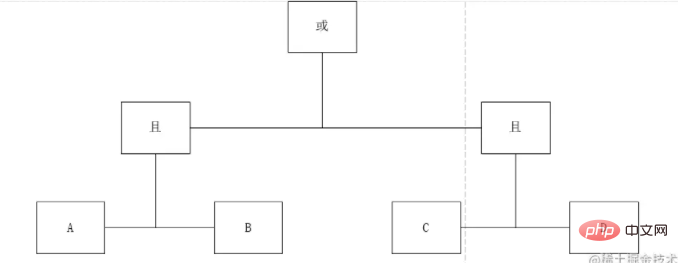
根据这个图,我们可以明显的看到,A且B 和C且D是同一级别,于是,我们按照这个理论设计一个层级的概念Deep,我们标注一下,然后再对节点的类型做一下区分,可得:
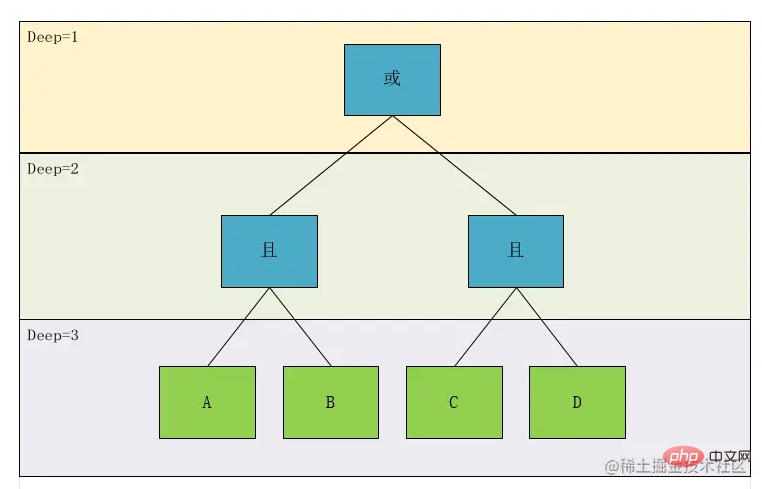
我们可以看到作为叶子节点(上图绿色部分),相对于其计算计算关系,遇到了一定是优先计算的,所以对于深度的优先级,我们仅需要考虑非叶子节点即可,即上图中的蓝色节点部分,于是我们得到了,计算优先级这个概念我们可以转换为表达式的深度。
我们再看上面这个图,Deep1 的关系是Deep2中 A且B 和 C且D两个表达式计算出的结果再进行与或关系的,我们设A 且B 为 G1, C且D为 G2,于是我们发现关系节点关联的类型有两种类型,一种是条件Condition ,一种是组Group
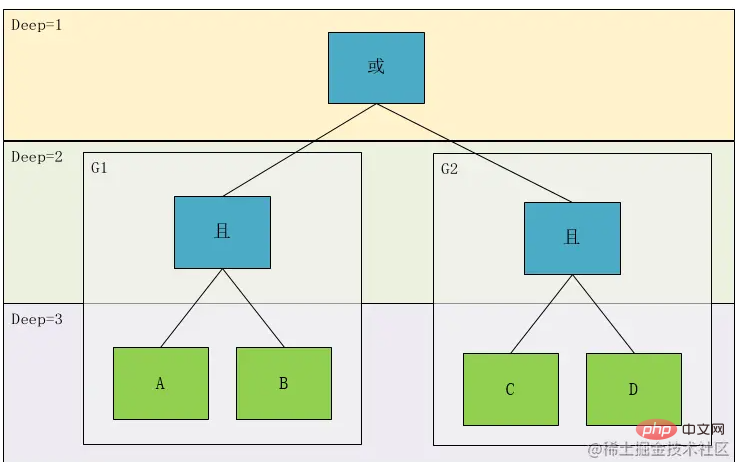
至此,这个类的雏形基本就确定了。这个类包含 关联关系(Relation)、判断字段(Field)、运算符(Operator)、运算值(Values)、类型(Type)、深度(Deep)
但是,有个问题,上面的分析中,我们在将表达式转换成树,现在我们试着将其还原,于是我们一眼可以得到其中一种表达式:
result=(A && B)||(C && D)
result=A && B || (C && D)🎜🎜Maintenant, la question est : comment gérer les priorités ? 🎜🎜L'expression ci-dessus est évidemment une expression d'ordre standard apprise à l'université, dessinons donc son arbre : 🎜🎜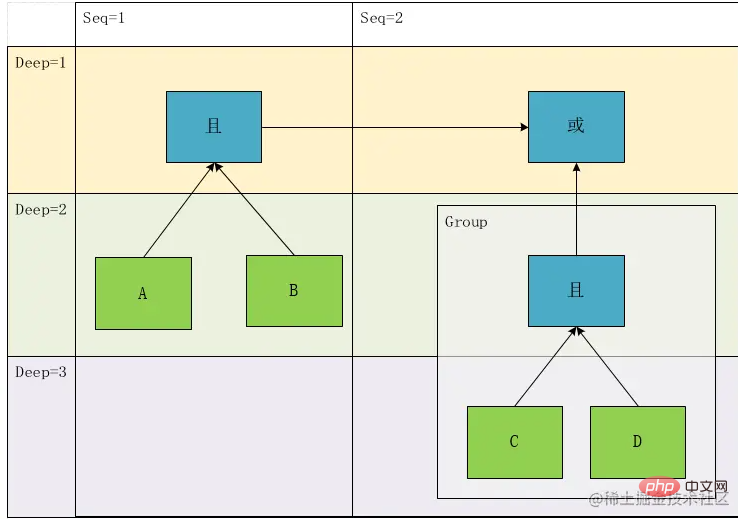 🎜🎜D'après cette image, nous pouvons clairement voir que A et B et C et D sont au même niveau, donc, Nous concevons un concept hiérarchique profond selon cette théorie, marque dessus, puis distinguer les types de nœuds, on peut obtenir : 🎜🎜🎜🎜Nous pouvons voir qu'en tant que nœud feuille (la partie verte dans l'image ci-dessus), par rapport à sa relation de calcul, il doit être calculé en premier lorsqu'il est rencontré, donc pour la priorité en profondeur, il suffit de considérons les nœuds non-feuilles, c'est-à-dire la partie du nœud bleu dans la figure ci-dessus, nous obtenons ainsi le concept de calcul de priorité que nous pouvons convertir en une expression Profondeur. 🎜🎜Regardons à nouveau l'image ci-dessus. La relation entre Deep1 est le ET ou la relation entre les résultats calculés par les deux expressions A et B et C et D dans Deep2. Supposons que A et B soient G1 et que C et D soient G2. , nous avons donc découvert qu'il existe deux types d'associations de nœuds de relation, l'une est ConditionCondition et l'autre est GroupeGroup🎜🎜🎜🎜À ce stade, le prototype de cette classe est fondamentalement déterminé. Cette classe comprend Relation (Relation), Champ de jugement (Champ), Opérateur (Opérateur), Valeurs d'opération (Valeurs), Type(Type), Depth(Deep) 🎜🎜Cependant, il y a un problème dans l'analyse ci-dessus, nous convertissons l'expression en arbre, et maintenant nous essayons de restaurer. it , afin que nous puissions obtenir l'une des expressions en un coup d'œil : 🎜🎜
🎜🎜D'après cette image, nous pouvons clairement voir que A et B et C et D sont au même niveau, donc, Nous concevons un concept hiérarchique profond selon cette théorie, marque dessus, puis distinguer les types de nœuds, on peut obtenir : 🎜🎜🎜🎜Nous pouvons voir qu'en tant que nœud feuille (la partie verte dans l'image ci-dessus), par rapport à sa relation de calcul, il doit être calculé en premier lorsqu'il est rencontré, donc pour la priorité en profondeur, il suffit de considérons les nœuds non-feuilles, c'est-à-dire la partie du nœud bleu dans la figure ci-dessus, nous obtenons ainsi le concept de calcul de priorité que nous pouvons convertir en une expression Profondeur. 🎜🎜Regardons à nouveau l'image ci-dessus. La relation entre Deep1 est le ET ou la relation entre les résultats calculés par les deux expressions A et B et C et D dans Deep2. Supposons que A et B soient G1 et que C et D soient G2. , nous avons donc découvert qu'il existe deux types d'associations de nœuds de relation, l'une est ConditionCondition et l'autre est GroupeGroup🎜🎜🎜🎜À ce stade, le prototype de cette classe est fondamentalement déterminé. Cette classe comprend Relation (Relation), Champ de jugement (Champ), Opérateur (Opérateur), Valeurs d'opération (Valeurs), Type(Type), Depth(Deep) 🎜🎜Cependant, il y a un problème dans l'analyse ci-dessus, nous convertissons l'expression en arbre, et maintenant nous essayons de restaurer. it , afin que nous puissions obtenir l'une des expressions en un coup d'œil : 🎜🎜result=(A && B)||(C && D)🎜De toute évidence, cela n'est pas cohérent avec notre expression originale. En effet, nous ne pouvons enregistrer que l'ordre de calcul de l'expression ci-dessus, mais nous ne pouvons pas représenter cette expression de manière complètement précise. En effet, lors du processus d'analyse de l'expression, non seulement cela le fait. a une profondeur, mais il a aussi une relation temporelle, c'est-à-dire une représentation séquentielle de gauche à droite. À ce stade, le contenu de G1 a en fait une profondeur de 1 au lieu de 2 dans l'expression originale. numéros de séquence à Il s'avère que l'arbre devient un graphe orienté :
D'après ce graphe, on peut restituer la seule expression : result= A && B ||(C && D) . result= A && B ||(C && D)。
好了,我们分析了半天,原理说完了,回到最初始的问题:前后端怎么实现?对着上图想象一下,貌似还是无法处理,因为这个结构还是太复杂了。对于前端,数据最好是方便遍历的,对于后端,数据最好是方便处理的,于是这时候我们需要将上面这个图转换成一个数组。
实现方式
上面说到了需要一个数组的结构,我们具体分析一下这个部分
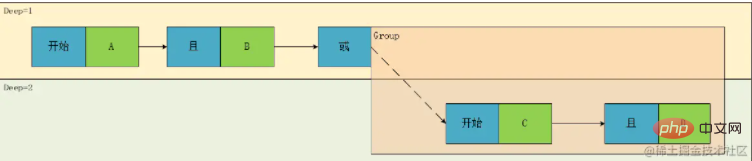
我们发现作为叶子节点,可以始终优先计算,所以我们可以将其压缩,并将关系放置在其中一个表达式中形成 ^A -> &&B或 A&& -> B$ 的形式,这里我用正则的开始(^) 和结束($) 表示了一下开始 和 结束 的概念,这里为了与产品原型保持一致我们用第一种方式,即关系符号表示与前一个元素的关系,于是我们再分析一下:
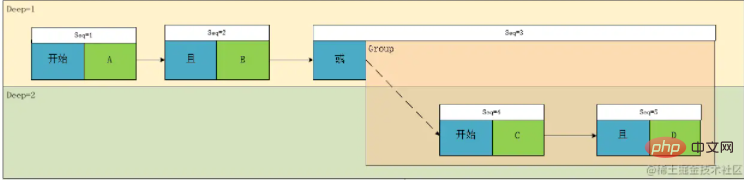
再对序号进行改造:
于是我们得到最终的数据结构:
@Data
@AllArgsConstructor
@NoArgsConstructor
@Accessors(chain = true)
public class ExpressDto {
/**
* 序号
*/
private Integer seq;
/**
* 深度(运算优先级)
*/
private Integer deep;
/**
* 关系运算符
*/
private String relation;
/**
* 类型
*/
private String type;
/**
* 运算条件
*/
private String field;
/**
* 逻辑运算符
*/
private String operator;
/**
* 运算值
*/
private String values;
/**
* 运算结果
*/
private Boolean result;
}现在数据结构终于完成,既方便存储,又(相对)方便前台展示,现在构造一个稍微复杂的表达式
A &&(( B || C )|| (D && E)) && F
 Nous avons constaté qu'en tant que nœud feuille, il peut toujours être calculé en premier, nous pouvons donc le compresser et placer la relation dans l'une des expressions pour former
Nous avons constaté qu'en tant que nœud feuille, il peut toujours être calculé en premier, nous pouvons donc le compresser et placer la relation dans l'une des expressions pour former ^A - > &&B ou A&& -> B$, ici j'utilise start(^) et end($) pour exprimer Jetons un coup d'œil aux concepts de début et de fin Afin d'être cohérents avec le prototype du produit, nous utilisons la première méthode, c'est-à-dire le symbole de relation pour exprimer la relation avec l'élément précédent, nous l'analysons donc à nouveau :
Reformer le numéro de série :
Nous obtenons donc la structure de données finale : [
{"seq":1,"deep":1,relation:"BEGIN","type":"CONDITION","field"="A"...},
{"seq":2,"deep":1,relation:"AND","type":"GROUP","field":""...},
{"seq":3,"deep":2,relation:"BEGIN","type":"GROUP","field":""...},
{"seq":4,"deep":3,relation:"BEGIN","type":"CONDITION","field":"B"...},
{"seq":5,"deep":3,relation:"OR","type":"CONDITION","field":"C"...},
{"seq":6,"deep":2,relation:"OR","type":"GROUP","field":""...},
{"seq":7,"deep":3,relation:"BEGIN","type":"CONDITION","field":"D"...},
{"seq":8,"deep":3,relation:"AND","type":"CONDITION","field":"E"...},
{"seq":9,"deep":1,relation:"AND","type":"CONDITION","field":"F"...}
]Maintenant, le la structure des données est enfin terminée, ce qui est à la fois pratique pour le stockage et (relativement) pratique pour l'affichage frontal, construisez maintenant une expression légèrement complexe
A &&(( B || C )|| (D && E) ) && FChangez en un objet tableau et démarrez Il est marqué par BEGIN, le type d'expression est représenté par CONDITION et le groupe est représenté par GROUP. //关系 栈 Deque<String> relationStack=new LinkedList(); //结果栈 Deque<Boolean> resultStack=new LinkedList(); // 当前深度 Integer nowDeep=1;Maintenant, la dernière question reste : comment filtrer les données à travers ce jsonPuisque l'essence de l'objet tableau est toujours une expression infixe, son essence est toujours l'analyse d'une expression infixe, à propos du principe d'analyse, pas beaucoup d'introduction ici, en termes simples, il parcourt la pile de données et la pile de symboles selon les parenthèses (appelées groupes ici). Si vous voulez en savoir plus, vous pouvez le consulter à travers l'article suivant
Nous définissons donc trois variables :
for (ExpressDto expressDto:list) {
if(!StringUtils.equals(expressDto.getType(),"GROUP")){
//TODO 进行具体单个表达式计算并获取结果
resultStack.push(expressDto.getResult());
// 将关系放入栈中
relationStack.push(expressDto.getRelation());
if(deep==0 && resultStack.size()>1){ //由于已处理小于0的deep,当前deep理论上是>=0的,0表示同等级,需要立即运算
relationOperator(relationStack, resultStack);
}
}else{
// 将关系放入栈中
relationStack.push(expressDto.getRelation());
}
}
private void relationOperator(Deque<String> relationStack, Deque<Boolean> resultStack) {
Boolean lastResult= resultStack.pop();
Boolean firstResult= resultStack.pop();
String relation=relationStack.pop();
if(StringUtils.equals(relation,"AND")){
resultStack.push(firstResult&& lastResult) ;
return;
}
if(StringUtils.equals(relation,"OR")){
resultStack.push( firstResult|| lastResult);
return;
}else{
throw new RuntimeException("表达式解析异常:关系表达式错误");
}
}En parcourant le tableau, poussez la relation et le résultat sur la pile Lorsqu'il s'avère qu'un calcul de priorité est nécessaire, retirez deux valeurs de la pile de résultats, retirez l'opérateur relationnel de la pile de relations. , remettez-le sur la pile après le calcul et attendez la prochaine fois. Lors du calcul
/**
* 处理层级遗留元素
*
* @param relationStack
* @param resultStack
*/
private void computeBeforeEndGroup(Deque<String> relationStack, Deque<Boolean> resultStack) {
boolean isBeginSymbol=StringUtils.equals(relationStack.peek(),"BEGIN");//防止group中仅有一个判断条件
while(!isBeginSymbol){//上一个运算符非BEGIN,说明该group中还有运算需要优先处理,正常这里应该仅循环一次
relationOperator(relationStack, resultStack);
isBeginSymbol=StringUtils.equals(relationStack.peek(),"BEGIN");
}
if(isBeginSymbol){
relationStack.pop();//该优先级处理完毕,将BEGIN运算符弹出
}
}parlons des limites à noter :
1. Tout d'abord, il n'y a que deux types de relations dans notre même niveau, et, ou, et les priorités de calcul de ces deux types sont les mêmes. Par conséquent, sous le même Deep, il suffit de parcourir et de calculer de gauche à droite. 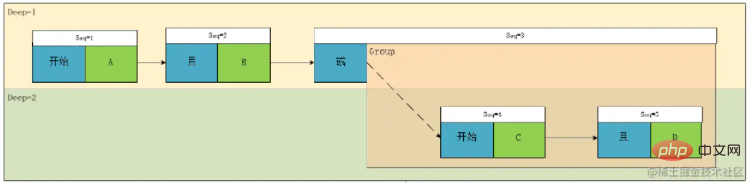
/**
* 表达式解析器
* 表达式规则:
* 关系relation属性有:BEGIN、AND、OR 三种
* 表达式类型 Type 属性有:GROUP、CONDITION 两种
* 深度 deep 属性 根节点为 1,每增加一个括号(GROUP)deep+1,括号结束deep-1
* 序号req:初始值为1,往后依次递增,用于防止表达式解析顺序错误
* exp1:表达式:A &&(( B || C )|| (D && E)) && F
* 分解对象:
* [
* {"seq":1,"deep":1,relation:"BEGIN","type":"CONDITION","field"="A"...},
* {"seq":2,"deep":1,relation:"AND","type":"GROUP","field":""...},
* {"seq":3,"deep":2,relation:"BEGIN","type":"GROUP","field":""...},
* {"seq":4,"deep":3,relation:"BEGIN","type":"CONDITION","field":"B"...},
* {"seq":5,"deep":3,relation:"OR","type":"CONDITION","field":"C"...},
* {"seq":6,"deep":2,relation:"OR","type":"GROUP","field":""...},
* {"seq":7,"deep":3,relation:"BEGIN","type":"CONDITION","field":"D"...},
* {"seq":8,"deep":3,relation:"AND","type":"CONDITION","field":"E"...},
* {"seq":9,"deep":1,relation:"AND","type":"CONDITION","field":"F"...}
* ]
*
* exp2:(A || B && C)||(D && E && F)
* [
* {"seq":1,"deep":1,relation:"BEGIN","type":"GROUP","field":""...},
* {"seq":2,"deep":2,relation:"BEGIN","type":"CONDITION","field":"A"...},
* {"seq":3,"deep":2,relation:"OR","type":"CONDITION","field":"B"...},
* {"seq":4,"deep":2,relation:"AND","type":"CONDITION","field":"C"...},
* {"seq":5,"deep":1,relation:"OR","type":"GROUP","field":""...},
* {"seq":6,"deep":2,relation:"BEGIN","type":"CONDITION","field":"D"...},
* {"seq":7,"deep":2,relation:"AND","type":"CONDITION","field":"E"...},
* {"seq":8,"deep":2,relation:"AND","type":"CONDITION","field":"F"...}
* ]
*
*
* @param list
* @return
*/
public boolean expressProcessor(Listlist){
//关系 栈
Deque relationStack=new LinkedList();
//结果栈
Deque resultStack=new LinkedList();
// 当前深度
Integer nowDeep=1;
Integer seq=0;
for (ExpressDto expressDto:list) {
// 顺序检测,防止顺序错误
int checkReq=expressDto.getSeq()-seq;
if(checkReq!=1){
throw new RuntimeException("表达式异常:解析顺序异常");
}
seq=expressDto.getSeq();
//计算深度(计算优先级),判断当前逻辑是否需要处理括号
int deep=expressDto.getDeep()-nowDeep;
// 赋予当前深度
nowDeep=expressDto.getDeep();
//deep 减小,说明有括号结束,需要处理括号到对应的层级,deep减少数量等于组(")")结束的数量
while(deep++ < 0){
computeBeforeEndGroup(relationStack, resultStack);
}
if(!StringUtils.equals(expressDto.getType(),"GROUP")){
//TODO 进行具体单个表达式计算并获取结果
resultStack.push(expressDto.getResult());
// 将关系放入栈中
relationStack.push(expressDto.getRelation());
if(deep==0 && resultStack.size()>1){ //由于已处理小于0的deep,当前deep理论上是>=0的,0表示同等级,需要立即运算
relationOperator(relationStack, resultStack);
}
}else{
// 将关系放入栈中
relationStack.push(expressDto.getRelation());
}
}
//遍历完毕,处理栈中未进行运算的节点
while(nowDeep-- > 0){ // 这里使用 nowdeep>0 的原因是最后deep=1的关系表达式也需要进行处理
computeBeforeEndGroup(relationStack, resultStack);
}
if(resultStack.size()!=1){
throw new RuntimeException("表达式解析异常:解析结果数量异常解析数量:"+resultStack.size());
}
return resultStack.pop();
}
/**
* 处理层级遗留元素
*
* @param relationStack
* @param resultStack
*/
private void computeBeforeEndGroup(Deque<String> relationStack, Deque<Boolean> resultStack) {
boolean isBeginSymbol=StringUtils.equals(relationStack.peek(),"BEGIN");//防止group中仅有一个判断条件
while(!isBeginSymbol){//上一个运算符非BEGIN,说明该group中还有运算需要优先处理,正常这里应该仅循环一次
relationOperator(relationStack, resultStack);
isBeginSymbol=StringUtils.equals(relationStack.peek(),"BEGIN");
}
if(isBeginSymbol){
relationStack.pop();//该优先级处理完毕,将BEGIN运算符弹出
}
}
/**
* 关系运算处理
* @param relationStack
* @param resultStack
*/
private void relationOperator(Deque relationStack, Deque resultStack) {
Boolean lastResult= resultStack.pop();
Boolean firstResult= resultStack.pop();
String relation=relationStack.pop();
if(StringUtils.equals(relation,"AND")){
resultStack.push(firstResult&& lastResult) ;
return;
}
if(StringUtils.equals(relation,"OR")){
resultStack.push( firstResult|| lastResult);
return;
}else{
throw new RuntimeException("表达式解析异常:关系表达式错误");
}
} 🎜4. Lorsqu'on constate que le dernier élément Deep n'est pas égal à 1 à la fin du parcours, cela signifie qu'il y a une fin de parenthèses. A ce moment, la fin des parenthèses doit également être traitée🎜. 🎜Enfin, le code complet : 🎜 /**
* 表达式:A
*/
@Test
public void expTest0(){
ExpressDto E1=new ExpressDto().setDeep(1).setResult(false).setSeq(1).setType("CONDITION").setField("A").setRelation("BEGIN");
List<ExpressDto> list = new ArrayList();
list.add(E1);
boolean re=expressProcessor(list);
Assertions.assertFalse(re);
}
/**
* 表达式:(A && B)||(C || D)
*/
@Test
public void expTest1(){
ExpressDto E1=new ExpressDto().setDeep(1).setSeq(1).setType("GROUP").setRelation("BEGIN");
ExpressDto E2=new ExpressDto().setDeep(2).setResult(true).setSeq(2).setType("Condition").setField("A").setRelation("BEGIN");
ExpressDto E3=new ExpressDto().setDeep(2).setResult(false).setSeq(3).setType("Condition").setField("B").setRelation("AND");
ExpressDto E4=new ExpressDto().setDeep(1).setSeq(4).setType("GROUP").setRelation("OR");
ExpressDto E5=new ExpressDto().setDeep(2).setResult(true).setSeq(5).setType("Condition").setField("C").setRelation("BEGIN");
ExpressDto E6=new ExpressDto().setDeep(2).setResult(false).setSeq(6).setType("Condition").setField("D").setRelation("OR");
List<ExpressDto> list = new ArrayList();
list.add(E1);
list.add(E2);
list.add(E3);
list.add(E4);
list.add(E5);
list.add(E6);
boolean re=expressProcessor(list);
Assertions.assertTrue(re);
}
/**
* 表达式:A && (B || C && D)
*/
@Test
public void expTest2(){
ExpressDto E1=new ExpressDto().setDeep(1).setResult(true).setSeq(1).setType("Condition").setField("A").setRelation("BEGIN");
ExpressDto E2=new ExpressDto().setDeep(1).setSeq(2).setType("GROUP").setRelation("AND");
ExpressDto E3=new ExpressDto().setDeep(2).setResult(false).setSeq(3).setType("Condition").setField("B").setRelation("BEGIN");
ExpressDto E4=new ExpressDto().setDeep(2).setResult(false).setSeq(4).setType("Condition").setField("C").setRelation("OR");
ExpressDto E5=new ExpressDto().setDeep(2).setResult(true).setSeq(5).setType("Condition").setField("D").setRelation("AND");
List<ExpressDto> list = new ArrayList();
list.add(E1);
list.add(E2);
list.add(E3);
list.add(E4);
list.add(E5);
boolean re=expressProcessor(list);
Assertions.assertFalse(re);
E4.setResult(true);
list.set(3,E4);
re=expressProcessor(list);
Assertions.assertTrue(re);
E1.setResult(false);
list.set(0,E1);
re=expressProcessor(list);
Assertions.assertFalse(re);
}
@Test
public void expTest3(){
ExpressDto E1=new ExpressDto().setDeep(1).setResult(true).setSeq(1).setType("Condition").setField("A").setRelation("BEGIN");
ExpressDto E2=new ExpressDto().setDeep(1).setSeq(2).setType("GROUP").setRelation("OR");
ExpressDto E3=new ExpressDto().setDeep(2).setResult(true).setSeq(3).setType("Condition").setField("B").setRelation("BEGIN");
ExpressDto E4=new ExpressDto().setDeep(2).setSeq(4).setType("GROUP").setRelation("AND");
ExpressDto E5=new ExpressDto().setDeep(3).setResult(true).setSeq(5).setType("Condition").setField("C").setRelation("BEGIN");
ExpressDto E6=new ExpressDto().setDeep(3).setResult(false).setSeq(6).setType("Condition").setField("D").setRelation("OR");
List<ExpressDto> list = new ArrayList();
list.add(E1);
list.add(E2);
list.add(E3);
list.add(E4);
list.add(E5);
list.add(E6);
boolean re=expressProcessor(list);
Assertions.assertTrue(re);
}
/**
* 表达式:A &&(( B || C )|| (D && E))
*/
@Test
public void expTest4(){
ExpressDto E1=new ExpressDto().setDeep(1).setSeq(1).setType("CONDITION").setResult(true).setField("A").setRelation("BEGIN");
ExpressDto E2=new ExpressDto().setDeep(1).setSeq(2).setType("GROUP").setRelation("AND");
ExpressDto E3=new ExpressDto().setDeep(2).setSeq(3).setType("GROUP").setRelation("BEGIN");
ExpressDto E4=new ExpressDto().setDeep(3).setSeq(4).setType("CONDITION").setResult(true).setField("B").setRelation("BEGIN");
ExpressDto E5=new ExpressDto().setDeep(3).setSeq(5).setType("CONDITION").setResult(true).setField("C").setRelation("OR");
ExpressDto E6=new ExpressDto().setDeep(2).setSeq(6).setType("GROUP").setRelation("OR");
ExpressDto E7=new ExpressDto().setDeep(3).setSeq(7).setType("CONDITION").setResult(false).setField("D").setRelation("BEGIN");
ExpressDto E8=new ExpressDto().setDeep(3).setSeq(8).setType("CONDITION").setResult(false).setField("E").setRelation("AND");
List<ExpressDto> list = new ArrayList();
list.add(E1);
list.add(E2);
list.add(E3);
list.add(E4);
list.add(E5);
list.add(E6);
list.add(E7);
list.add(E8);
boolean re=expressProcessor(list);
Assertions.assertTrue(re);
}
/**
* 表达式:(A)
*/
@Test
public void expTest5(){
ExpressDto E1=new ExpressDto().setDeep(1).setSeq(1).setType("GROUP").setRelation("BEGIN");
ExpressDto E2=new ExpressDto().setDeep(2).setResult(true).setSeq(2).setType("Condition").setField("A").setRelation("BEGIN");
List<ExpressDto> list = new ArrayList();
list.add(E1);
list.add(E2);
boolean re=expressProcessor(list);
Assertions.assertTrue(re);
E2.setResult(false);
list.set(1,E2);
Assertions.assertFalse(expressProcessor(list));
}🎜J'ai simplement écrit quelques cas de test :🎜rrreee🎜Résultat du test :🎜🎜🎜🎜🎜Écrit à la fin🎜🎜À ce stade, une analyse d'expression est terminée, revenons en arrière et regarde encore cette photo :🎜🎜🎜🎜On constate qu'en fait, la fonction de Seq3 est uniquement d'identifier le début d'un groupe et d'enregistrer l'association entre le groupe et d'autres éléments du même niveau. En fait, une optimisation peut être effectuée ici : on constate qu'à chaque fois. le début d'un groupe La relation de pré-association du premier nœud doit être Begin, Deep+1. En effet, on peut envisager de placer l'association du Groupe sur ce nœud, et ensuite contrôler uniquement la relation du groupe par l'augmentation ou la diminution de Deep. .De cette façon, nous n'avons pas besoin de ce champ d'expression de type ou de groupe, et la longueur du tableau sera réduite en conséquence, mais je pense personnellement que ce sera un peu plus difficile à comprendre. Voici une idée générale de la transformation, et le code ne sera pas publié :
- Changez le jugement sur Type="GROUP" dans le code pour juger par la différence de deep = 1
- La logique de la pile de jugement de profondeur modification
- Dans Lors du stockage du symbole de relation, vous devez également stocker la profondeur correspondant au symbole de relation. Lors du traitement des éléments hérités avec la même profondeur, c'est-à-dire : Dans la méthode, la méthode d'origine consiste à utiliser l'élément Begin pour distinguer si le groupe a été traité. Il faut maintenant le modifier selon la méthode suivante : déterminer si la profondeur d'un symbole est la même que la profondeur actuelle et supprimer la logique contextuelle concernant l'élément BEGIN
computeBeforeEndGroup()Apprentissage recommandé. : "
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!