
Maison >base de données >Oracle >Une brève analyse de l'architecture Oracle
Une brève analyse de l'architecture Oracle

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-07-22 16:51:372201parcourir
Cet article vous apporte des connaissances pertinentes sur Oracle, qui organise principalement les problématiques liées à l'architecture. L'architecture d'Oracle est généralement divisée en deux parties : Instance (instance) et Base de données (base de données), la suivante Jetons un coup d'œil, espérons-le. aide tout le monde.

Tutoriel recommandé : "Tutoriel vidéo Oracle"
L'architecture d'Oracle est généralement divisée en deux parties : Instance (instance) et Base de données (base de données).
Comme le montre la figure 1 :
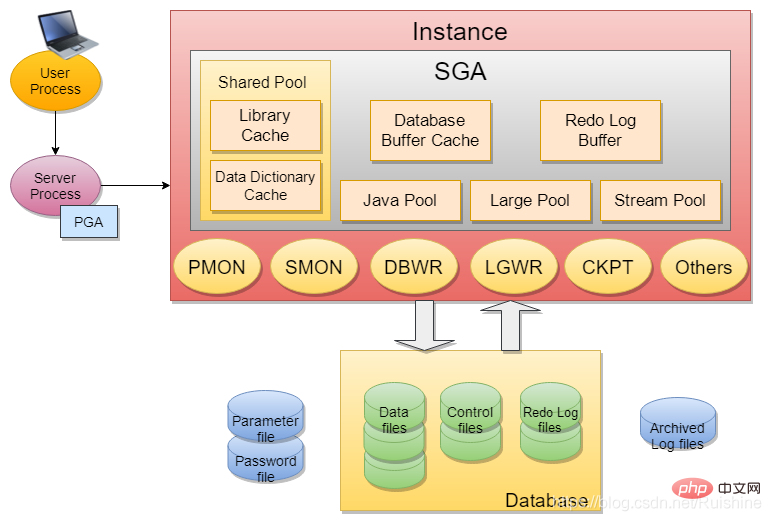
Figure 1 Architecture de la base de données Oracle
Ce que nous appelons habituellement Oracle Server (serveur Oracle) est composé d'une instance Oracle et d'une base de données Oracle, comme le montre la figure 2 :
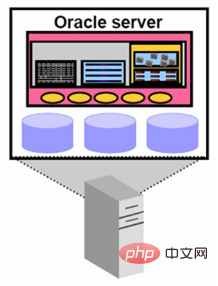
Figure 2 Oracle Server
Oracle InstanceInstance comprend principalement SGA et certains processus backgroud (par exemple : PMON, SMON, DBWR, LGWR, CKPT, etc.).
SGA
SGA contient 6 composants de base : Shared Pool (Bibliothèque Cache, Data Dictionary Cache), Database Buffer Cache, Redo Log Buffer, Java Pool, Large Pool, stream pool.
Les fonctions de ces 6 composants de base seront présentées ci-dessous.
1) pool partagé
- Le pool partagé est une zone mémoire pour l'analyse syntaxique, la compilation et l'exécution de programmes SQL et PL/SQL.
- Le pool partagé comprend le Library Cache (cache de bibliothèque), le Data Dictionary Cache (cache de dictionnaire de données) et le Server Result Cache (cache de résultats).
Quelles sont leurs fonctions ?
Cache de bibliothèque : le lieu d'analyse pour SQL et PL/SQL, qui stocke le contenu des instructions SQL et PL/SQL compilées et analysées pour que tous les utilisateurs puissent les partager.
* Si vous exécutez la même instruction SQL la prochaine fois, il n'est pas nécessaire de l'analyser et elle sera exécutée immédiatement à partir du cache de la bibliothèque.
* La TAILLE du cache de la bibliothèque déterminera la fréquence de compilation et d'analyse des instructions SQL, déterminant ainsi les performances.
* Le cache de bibliothèque contient deux parties : la zone SQL partagée et la zone PL/SQL partagée.
Cache du dictionnaire de données : stocke les informations importantes du dictionnaire de données pour une utilisation dans la base de données.
* Le dictionnaire de données est le plus fréquemment utilisé et presque toutes les opérations nécessitent d'interroger le dictionnaire de données. Afin d'améliorer la vitesse d'accès au dictionnaire de données, un cache est nécessaire à ce moment-là et la mémoire est accessible en cas de besoin.
* Les informations contenues dans le cache du dictionnaire de données comprennent des fichiers de base de données, des tables, des index, des colonnes, des utilisateurs, des privilèges et d'autres objets de base de données.
Cache des résultats du serveur : stocke les ensembles de résultats SQL côté serveur et les valeurs de retour des fonctions PL/SQL.
Après avoir lu l'explication ci-dessus, vous penserez peut-être qu'elle est un peu abstraite, je vais donc l'expliquer à travers un exemple ci-dessous.
Supposons qu'une commande soit soumise sur le client, comme suit :
SELECT ename,sal FROM emp WHERE empno=7788;
Si cette instruction est soumise à la base de données pour la première fois, elle doit être analysée. Le processus d'analyse est divisé en analyse matérielle et analyse logicielle.
- Analyse dure : vérifiez la syntaxe, la sémantique, les autorisations, analysez les variables de liaison, etc., et enfin générez un plan d'exécution
- Analyse douce : exécutez-la spécifiquement selon le plan d'exécution ; S'il s'agit d'une instruction select, le jeu de résultats sera renvoyé après l'exécution. S'il s'agit d'une instruction update ou delete, il n'est pas nécessaire de renvoyer un jeu de résultats.
Library Cache y chargera cette instruction SQL et ce plan d'exécution.
Quel est le but d'installer ces choses ?
La prochaine fois que vous taperez la même phrase (la ponctuation, les majuscules et les espaces sont exactement les mêmes), vous n'aurez pas besoin de faire une analyse approfondie.
Questions et réponses rapides :
Si le client soumet une autre commande à ce moment :
select ename,sal from emp where empno=7788;
Devinez, cette déclaration doit-elle être analysée ?
Réponse : Oui.
Conseils : Notez que les déclarations doivent être exactement les mêmes pour éviter toute analyse. La ponctuation, les majuscules, les espaces, etc. doivent être exactement les mêmes ! Les avantages d’une écriture régulière se reflètent ici.
Comme mentionné précédemment, s'il s'agit d'une instruction select, l'ensemble de résultats sera renvoyé après l'exécution. Où est stocké l’ensemble de résultats ?
select ename,sal from emp where empno=7788;
L'ensemble de résultats renvoyé par l'exécution de cette instruction sera stocké dans le cache des résultats du serveur.
2) Cache de tampon de base de données
- Database Buffer Cache用于存储从磁盘数据文件中读入的数据,为所有用户共享。
- Server Process(服务器进程)将读入的数据保存在数据缓冲区中,当后续的请求需要这些数据时可以在内存中找到,则不需要再从磁盘读取。
小说明:逻辑读(从内存读)的速度是物理读(从磁盘读)的1万倍呦,所以还是想办法尽量多从内存读哦。
所以,数据缓冲区的大小对数据库的读取速度有直接的影响。
例如用户访问一个表里面的记录时,数据库接收到这个请求后,首先会在Database Buffer Cache中查找是否存在该数据库表的记录,如果有所需的记录就直接从内存中读取该记录返回给用户(有效提升了访问的速度),否则只能去磁盘上去读取。
继续看上面的例子:
select ename,sal from emp where empno=7788;
该条语句以及它的执行计划被放在Library Cache里,但语句涉及到的数据,会放在 Database Buffer Cache 里。
小问答:
Database Buffer Cache是怎么工作的呢?
这就要说一说Database Buffer Cache的设计思想了。
磁盘上存储的是块(block),文件都有文件号,块也有块号。
若要访问磁盘上的块,并不是CPU拿到指令后直接访问磁盘,而是先把块读到内存中的Database Buffer cache里,生成副本,查询或增删改都是对内存中的副本进行操作。如图3所示。
另外,如果是增删操作,操作后会形成脏块,脏块会在恰当时机再写回磁盘原位置,注意哦,可不是立刻写回呦。
也许你会问,为什么不立刻写回呢?
因为:
(1)减少物理IO;
(2)可共享,若后面又有对该块的访问,可直接在内存中进行逻辑读。
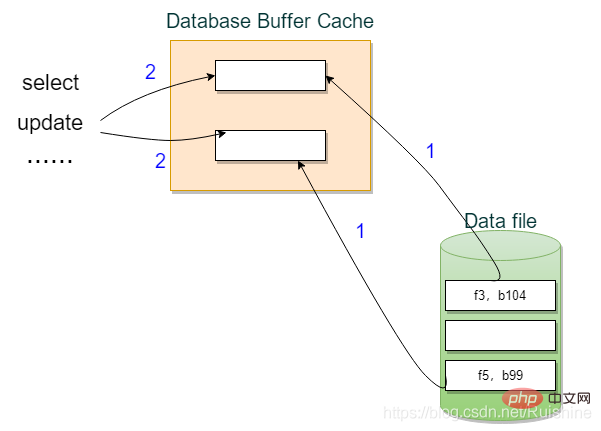
图3 访问数据块
小问答:
为什么要通过内存访问数据块,而不是CPU直接访问磁盘呢?
答:因为相较于CPU,IO的速度实在是太慢了,CPU的速度是IO 的100万倍呢?如果CPU直接访问磁盘的话,会造成大量的IO等待,CPU的利用率会很低。所以,利用速度相当的内存(CPU速度为内存的100倍)做中间缓存,可以有效减少物理IO,提高CPU利用率。
但是,这里会有一个问题。前面说到查询或增删改都是对内存中的副本进行操作,当增删改操作产生脏块时不会立刻写回磁盘。
小问答:
我们设想一下,如果在 Database Buffer Cache 中存放大量未来得及写回磁盘的脏块时,突然出现系统故障(比如断电),导致内存中的数据丢失。而此时磁盘中的块存放的依然是修改前的旧数据,这样岂不是导致前面的修改无效?
要怎样保持事务的一致性呢?
答:如果我们能够保存住提交的记录,在 Database Buffer Cache 中一旦有数据更改,马上写入一个地方记录下来,不就可以保证事务一致性了嘛。
小说明:Instance在断电时会消失,Instance在内存中存放的数据将丢失。这就需要 Redo Log Buffer 发挥它的作用啦。
3)Redo Log Buffer
- 日志条目(Redo Entries )记录了数据库的所有修改信息(包括 DML 和 DDL),一条Redo Entries记录一次对数据库的改变 ,为的是数据库恢复。
- 日志条目首先产生于日志缓冲区。日志缓冲区较小,它是以字节为单位的,它极其重要。
- 在Database Buffer Cache中一旦有数据更改,马上写入Redo Log Buffer,Redo Log Buffer在内存中保留一段时间后,会写入磁盘,然后归档(3级结构)。
4)Large Pool(可选)
为了进行大的后台进程操作而分配的内存空间,与 shared pool 管理不同,主要用于共享服
务器的 session memory,RMAN 备份恢复以及并行查询等。
5)Java Pool(可选)
为了 java 虚拟机及应用而分配的内存空间,包含所有 session 指定的 JAVA 代码和数据。
6)Stream Pool(可选)
为了 stream process 而分配的内存空间。stream 技术是为了在不同数据库之间共享数据,
因此,它只对使用了 stream 数据库特性的系统是重要的。
Background process
在正式介绍 Background Process 之前,先简单介绍 Oracle 的 Process 类型。
Oracle Process 有三种类型:
- User Proces
客户端要与服务器连接,在客户端启动起来的进程就是 User Process,一般分为三种形式(sql*plus, 应用程序,web 方式(OEM))。
- Processus serveur
Le processus utilisateur ne peut pas accéder directement à Oracle. Il doit accéder à l'instance via le processus serveur correspondant, puis accéder à la base de données.
Lorsqu'un utilisateur se connecte à Oracle Server, le processus utilisateur et le processus serveur établissent une connexion.
- Processus d'arrière-plan
Une partie importante d'Oracle Instance. Ceci sera expliqué en détail ci-après.
Petit ajout :
Connexion & Session
Connexion fait référence à la connexion TCP établie par un client Oracle et au processus en arrière-plan et en arrière-plan (Server Process). Comme le montre la figure 4 :
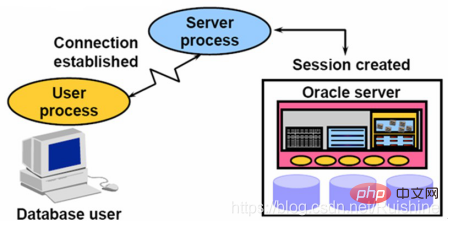
Figure 4 Connexion
Le processus d'établissement de la connexion peut être brièvement décrit comme suit :
1 Établissez d'abord une connexion TCP, Oracle authentifie l'identité de l'utilisateur, effectue des audits de sécurité, etc. .;
2. Lorsque ceux-ci sont passés, le processus serveur d'Oracle permettra au client d'utiliser les services fournis par Oracle ;
3. Lorsque la connexion Oracle est établie, cela signifie qu'une session a été démarrée. la séance disparaît.
Session et Connexion se complètent. Les informations de session seront stockées dans le dictionnaire de données d'Oracle.
Vous pouvez voir visuellement la différence entre la connexion et la session grâce à la figure 5.
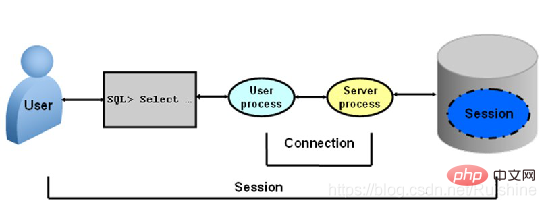
Figure 5 Connexion et session
Le processus d'arrière-plan (processus d'arrière-plan) comprend principalement : SMON (processus de surveillance du système), PMON (processus de surveillance du processus), DBWR (processus d'écriture de base de données), LGWR (processus d'écriture de journaux), CKPT (processus de point de contrôle).
1) PMON (Process Monitor)
Les principales fonctions de PMON sont les suivantes :
- Surveiller si chaque processus d'arrière-plan Oracle est normal, effacer le processus anormal s'il est trouvé et régénérer le processus.
- (Remarque : lorsque le processus utilisateur est déconnecté, le processus serveur est inutile s'il reste, mais il prend quand même de l'espace. PMON vérifiera régulièrement le processus serveur. S'il ne peut pas être connecté au processus utilisateur, PMON prendra back le processus serveur. , l'espace PGA est récupéré et les verrous à l'intérieur sont également récupérés)
- Surveillez si la session inactive atteint le seuil.
- Inscription et suivi dynamiques.
2) SMON (System Monitor)
Les principales fonctions de SMON sont les suivantes :
- Lorsque Oracle plante soudainement pendant l'exécution, la récupération d'instance (Instance Recovery) est requise pour le prochain démarrage. SMON est responsable du fonctionnement complet. surveillance de la récupération de l'instance ;
- Lorsqu'Oracle plante soudainement pendant l'exécution, au prochain démarrage d'Oracle Instance, certaines ressources non publiées seront nettoyées par SMON ;
- Certaines transactions seront également nettoyées par SMON en cas d'échec ; l'espace mémoire est très dispersé (discontinu) SMON est nécessaire pour intégrer cet espace dispersé
- libérer des segments temporaires (Segments) qui ne sont plus utilisés ;
3) DBWR (Database Writer)
DBWn est le processus le plus lourd d'Oracle. Les fonctions principales sont les suivantes :
- Écrivez des blocs sales (Dirty Buffer) dans le cache de tampon de base de données dans un fichier de données.
- Libérez l'espace du cache du tampon de données.
Petite remarque :
Si la charge de la base de données est relativement importante, qu'il y a de nombreuses requêtes des clients, qu'il y a un grand nombre d'opérations d'E/S et que le contenu du tampon doit être écrit fréquemment dans les fichiers disque, vous pouvez alors configurer plusieurs DBWn (Oracle prend en charge 20 DBWn au total, DBW0-DBW9, DBWa-DBWg). Habituellement, un Oracle de petite et moyenne taille n’a besoin que d’un seul processus DBW0.
Remarque : lorsque les situations suivantes se produisent, le processus DBWR sera déclenché pour écrire le contenu du cache de tampon de base de données dans des fichiers de données :
- Un point de contrôle se produit
- Seuil d'atteinte du tampon sale
- Il n'y a pas de tampons gratuits
- Un délai d'attente se produit
- La demande de ping RAC est effectuée
- Tablespace OFFLINE
- Tablespace READ ONLY
- Table DROP ou TRUNCATE
- Tablespace BEGIN
- BACKUP
Petit ajout :
Le processus serveur effectue des opérations de lecture sur les fichiers de données, et DBWR est responsable du traitement des données. Le fichier effectue une opération d'écriture.
Questions et réponses rapides :
Que fait DBWR lors d'un commit ?
Réponse : Ne faites rien !
4) LGWR ((LOG Writer))
Il n'y a qu'un seul processus LGWR dans l'instance Oracle Le travail de ce processus est similaire au processus DBWR. Les fonctions principales sont les suivantes :
Écrivez le contenu du tampon de journalisation dans les fichiers de journalisation (le journal doit être écrit avant que DBWR n'écrive des blocs sales).
(Redo Log Buffer est un tampon cyclique, et les fichiers Redo Log correspondants sont également un groupe de fichiers cycliques. Il commence à écrire à partir de la tête du fichier. Lorsque le fichier est plein, il recommencera à écrire à partir de la tête du fichier, et le le contenu précédent sera écrasé. Afin d'éviter d'écraser les fichiers de journalisation, vous pouvez choisir de l'écrire dans les fichiers de journalisation archivés.)
Remarque : lorsque les situations suivantes se produisent, le processus LGWR sera déclenché pour écrire le contenu. du tampon de journalisation aux fichiers de journalisation :
- Lors de la validation
- Quand un tiers est plein
- Lorsqu'il y a 1 Mo de restauration
- Toutes les trois secondes
- Avant que DBWn n'écrive
Comment s'assurer que la transaction validée est conservée de manière permanente ?
Réponse : L'opération de mise à jour a été effectuée à titre d'exemple.
1. Lors de l'écriture de l'instruction de validation, les modifications ont été écrites dans le tampon de journalisation
2 Lorsque vous voyez que la soumission est réussie, cela signifie que les modifications ont été écrites dans le fichier de journalisation du disque
3. une fois la soumission réussie, les modifications ont été synchronisées sur le disque et ne seront pas perdues.
5) CKPT (Checkpoint)
Les principales fonctions de CKPT sont les suivantes :
- Générer des points de contrôle, notifier ou inciter DBWR à écrire des blocs sales
- * Point de contrôle complet : assurer la cohérence des données ;
- * Point de contrôle incrémentiel : mettez à jour en permanence l'emplacement du point de contrôle dans le fichier de contrôle. Lorsqu'un crash d'instance se produit, le temps de récupération de l'instance peut être raccourci autant que possible. Mettez à jour les informations de point de contrôle dans l'en-tête du fichier de données ; mettez à jour les informations de point de contrôle dans le fichier de contrôle.
6) ARCn (Archiver)
- ARCn est un processus d'arrière-plan facultatif (presque considéré comme un processus obligatoire).
- Oracle peut fonctionner en deux modes : ARCHIVELOG MODE (mode archive) et NOARCHIVELOG MODE (mode non-archive).
- Une décision importante que le DBA doit prendre est de savoir s'il doit configurer la base de données pour qu'elle s'exécute en mode ARCHIVELOG ou en mode NOARCHIVELOG.
- Une fois le fichier de journalisation en ligne rempli, l'instance Oracle commence à écrire le fichier de journalisation en ligne suivant.
- Le processus de passage d'un fichier de journalisation en ligne à un autre fichier de journalisation en ligne est appelé changement de journal.
Les principales fonctions d'ARCn sont les suivantes :
Lorsque Oracle fonctionne en mode archive
- Le processus ARCn commencera à sauvegarder ou à archiver le groupe de journaux rempli à chaque fois qu'un changement de journal est effectué.
- Le processus ARCn archive automatiquement les fichiers de journalisation avant que les journaux puissent être réutilisés, de sorte que toutes les modifications apportées à la base de données sont préservées.
De cette façon, même si le lecteur de disque est endommagé, la base de données peut être restaurée jusqu'au point de défaillance.
Grâce à l'apprentissage ci-dessus, mettez d'abord à jour la figure 1 comme suit :
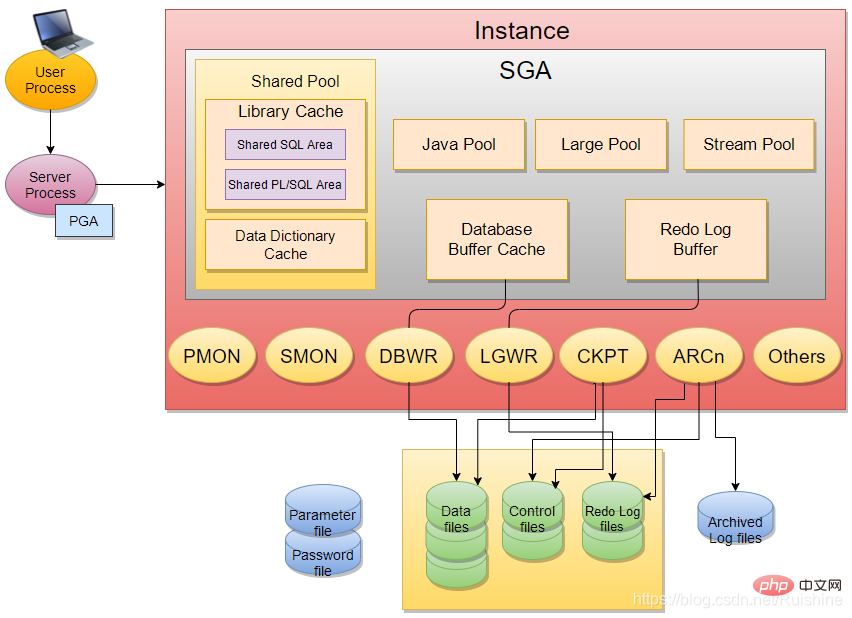
Figure 6 Architecture de la base de données Oracle
Base de données
La base de données est en fait composée d'un ensemble de fichiers physiques, principalement utilisés pour stocker des données, dans la base de données. contient trois types de fichiers : les fichiers de données, les fichiers de contrôle et les fichiers de journalisation.
De plus, il existe un fichier de paramètres, un fichier de mot de passe, des fichiers journaux obtenus, etc.
1) Fichiers de données
Les fichiers de données sont utilisés pour stocker des données et les données du tableau sont stockées dans des fichiers de données.
2) Fichiers de contrôle
Afin de faire fonctionner le fichier de données, Oracle fournit des fichiers de contrôle. Ces fichiers de contrôle enregistrent principalement certaines informations de contrôle de la base de données.
3) Fichiers de journalisation
Les fichiers de journalisation enregistrent les modifications dans la base de données ou si vous modifiez les données à l'intérieur, tant que la base de données est modifiée, les modifications doivent être l'état précédent et celui modifié. L'état est enregistré dans les fichiers Redo Log, dont la fonction est de restaurer le fichier de données.
* Par exemple : il y a une transaction dans la base de données qui doit être soumise, mais la soumission échoue et la transaction doit être annulée. La base de l'annulation de la transaction provient alors des fichiers journaux de rétablissement. Les fichiers de journalisation enregistrent les modifications de la base de données. Concernant cette modification de transaction, si vous devez annuler, vous devez supprimer les données des fichiers de journalisation et restaurer les fichiers de données à l'état avant la modification en fonction des données des fichiers de journalisation.
4) Fichier de paramètres
Toute base de données doit avoir un fichier de paramètres. Ce fichier de paramètres spécifie les valeurs de certains paramètres de base et paramètres d'initialisation dans Oracle.
5) Fichiers journaux archivés
Les fichiers journaux archivés et les fichiers de journalisation se complètent. Les fichiers de journalisation archivés sont en fait un processus d'utilisation répétée. Il y aura plusieurs (généralement 3) fichiers corrigés qui seront utilisés dans l'ordre. Lorsqu'ils seront pleins, Oracle réécrira l'en-tête du fichier et éliminera les éléments précédents. Afin d'améliorer encore les capacités de sauvegarde et de récupération de la base de données, ces informations modifiées sont archivées dans les fichiers journaux archivés avant d'être écrasées.
6) Fichier de mot de passe
Le client utilisateur stocke le mot de passe lorsqu'il se connecte au système de base de données backend.
Question et réponse rapides :
Quelle est la relation correspondante entre l'instance et la base de données ?
Réponse : Instance : Base de données = n : 1
1 Instance ne peut appartenir qu'à 1 base de données, et plusieurs instances peuvent accéder à 1 base de données en même temps.
Petit ajout :
La structure de la mémoire d'Oracle
La structure de la mémoire d'Oracle se compose en fait de deux parties : SGA et PGA
SGA (System Global Area)
- Une instance Oracle correspond à un SGA alloué au démarrage de l'instance Oracle. SGA est le composant de base d'Oracle Instance.
- Une instance Oracle n'a qu'un seul SGA, c'est un espace mémoire très important et peut même occuper 80 % de la mémoire physique.
PGA (Program Global Area)
- Un PGA sera alloué au démarrage d'un processus serveur. Il peut y avoir de nombreux PGA dans Oracle Instance. Par exemple, si vous démarrez 10 processus serveur, il y aura 10 PGA.
- PGA stocke les curseurs utilisateur, les variables, les contrôles, le tri des données et stocke les valeurs de hachage.
- Contrairement à SGA, PGA est indépendante et non partagée. Est une zone mémoire allouée à un processus et privée à ce processus.
Tutoriel recommandé : "Tutoriel vidéo Oracle"
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Exemples détaillés d'importation et d'exportation de tables de données Oracle
- Dictionnaire de données Oracle, vue du dictionnaire de données et vue dynamique des performances (partage de résumé)
- Maîtrisez le processus de démarrage d'Oracle en un seul article
- Docker peut-il installer Oracle ?
- Exemple d'analyse de l'installation et de l'utilisation de la base de données de conteneur Oracle