
Maison >Java >javaDidacticiel >Une introduction détaillée à la machine virtuelle Java : JVM garbage collector
Une introduction détaillée à la machine virtuelle Java : JVM garbage collector

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-07-14 16:52:392066parcourir
Cet article vous apporte des connaissances pertinentes sur java, qui règle principalement les problèmes liés aux garbage collectors JVM, notamment les collecteurs Serial et Serial Old, les collecteurs ParNew, les collecteurs Parallel et Parallel Old, etc. Jetons un coup d'œil au contenu ci-dessous. J'espère que cela sera utile à tout le monde.

Apprentissage recommandé : "Tutoriel vidéo Java"
Concurrence et parallélisme
- Parallèle (Parallèle) : Parallel décrit la relation entre plusieurs threads de garbage collector, indiquant qu'il existe plusieurs threads de garbage collector en même temps À ce moment-là, les threads travaillent ensemble et, généralement, par défaut, le thread utilisateur est en attente à ce moment-là.
- Concurrence (concurrente) : la concurrence décrit la relation entre le thread du garbage collector et le thread utilisateur, indiquant que le thread du garbage collector et le thread utilisateur s'exécutent en même temps. Étant donné que le thread utilisateur n'est pas gelé, le programme peut toujours répondre aux demandes de service, mais comme le thread du garbage collector occupe une partie des ressources système, le débit de traitement de l'application sera affecté dans une certaine mesure à ce moment-là.
Classification des garbage collector
1. Selon le nombre de threads
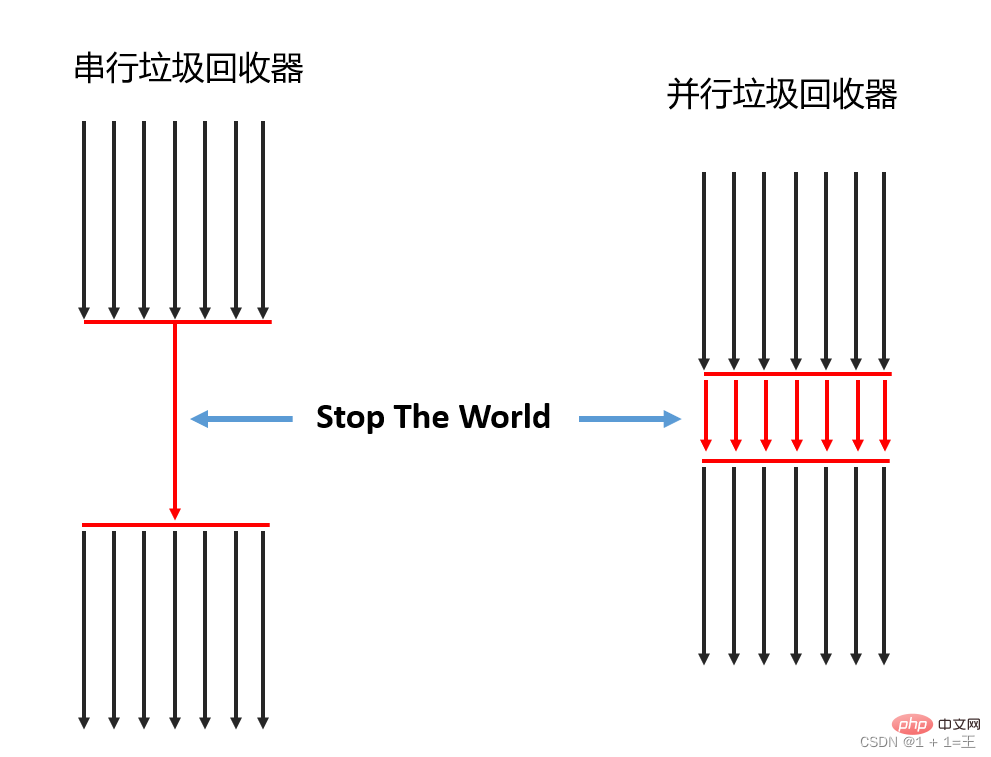
Selon le nombre de threads (utilisés pour le garbage collection), il peut être divisé en garbage collector en série et garbage collector en parallèle.
- Récupérateur de mémoire série : un seul processeur est autorisé à effectuer des opérations de récupération de place en même temps. À ce stade, le thread de travail est suspendu jusqu'à ce que le travail de récupération de place soit terminé.
- Corbeille parallèle : plusieurs processeurs peuvent être utilisés pour effectuer simultanément la récupération de place.

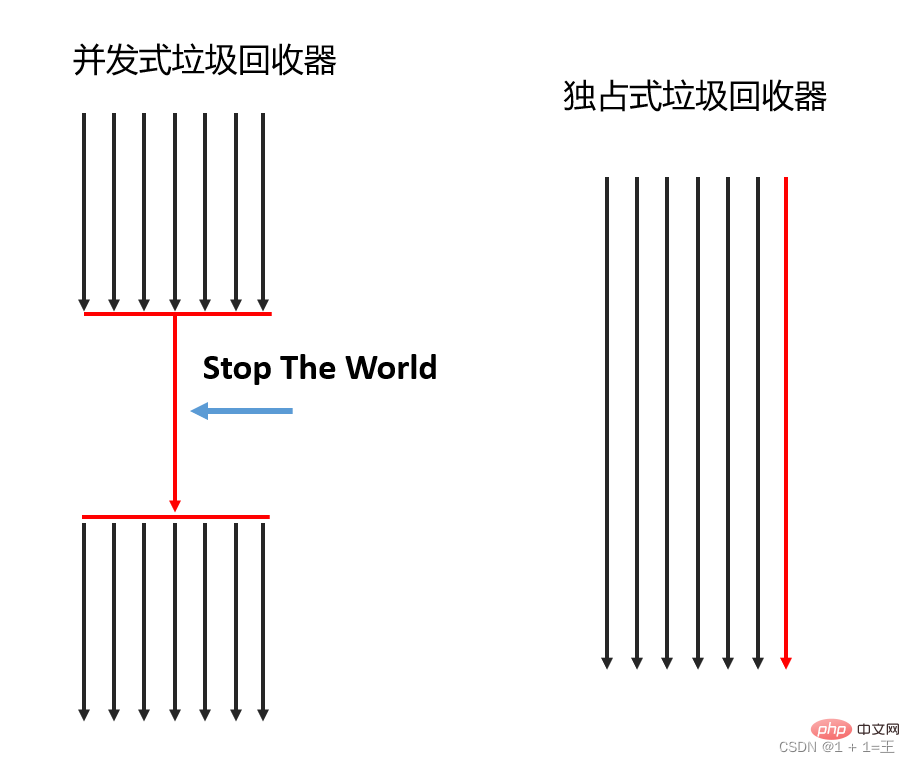
2. Selon le mode de travail
Selon le mode de travail, il peut être divisé en garbage collector simultané et garbage collector exclusif. - Corbeille simultanée : un seul processeur est autorisé à effectuer des opérations de récupération de place en même temps. À ce stade, le thread de travail est suspendu jusqu'à ce que le travail de récupération de place soit terminé.
- Garbage collector exclusif : plusieurs processeurs peuvent être utilisés pour effectuer le garbage collection simultanément.
3. Selon la méthode de traitement de fragmentation
Selon le mode de fonctionnement, il peut être divisé en garbage collector compressé et garbage collector non compressé.
Le collecteur de déchets compressé compressera et organisera les objets survivants une fois le recyclage terminé pour éliminer les fragments après le recyclage.
7 éboueurs classiques
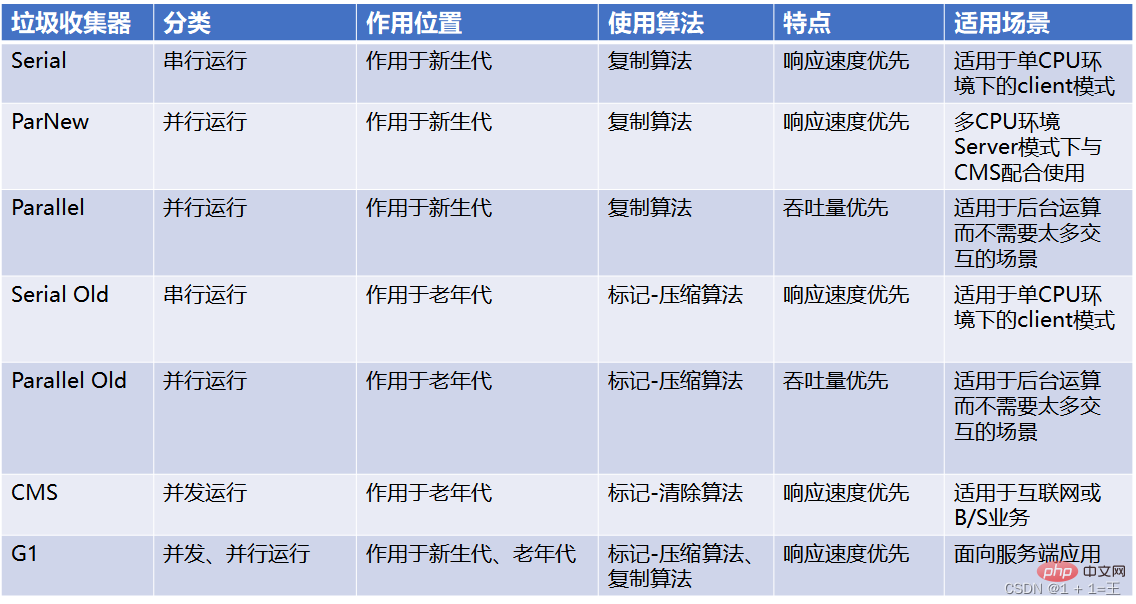
- Collecteur en série : serial, serial old
- Collecteur parallèle : ParNew, Parallel scavenge, Parallel old
- Concurrent collecteur : CMS, G1
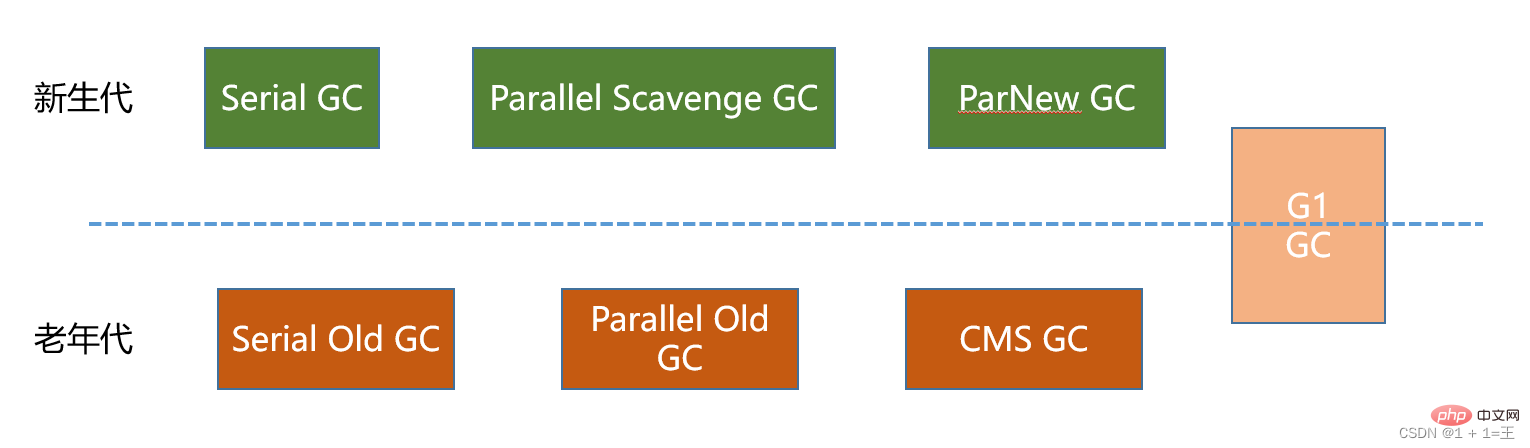
- Collecteur de nouvelle génération : série, ParNew, Parallel scavenge ;
- Collecteur d'ancienne génération : Serial old, Parallel old, CMS
- Full stack collector : G1 ; Ancien collecteur
à thread unique
Lorsqu'il effectue un garbage collection, tous les autres threads de travail doivent être suspendus jusqu'à ce qu'il termine la collecte.Serial Old est la version ancienne génération du Serial collector.
Serial Collector utilise un algorithme de copie, un recyclage en série et un mécanisme "Stop The World"
pour effectuer la collecte des déchets.
- Serial Old collector
- marks : algorithme de compression, collecte en série et mécanisme « Stop The World »effectuent le ramassage des ordures.
- Collecteur ParNew
Le collecteur ParNew est essentiellement une version parallèle multithread du collecteur Serial En plus d'utiliser plusieurs threads pour le garbage collection en même temps, le reste du comportement inclut tous les paramètres de contrôle. disponibles pour le collecteur Serial, l'algorithme de collecte, Stop The World, les règles d'allocation des objets, la stratégie de recyclage, etc. sont totalement cohérents avec le collecteur Serial. 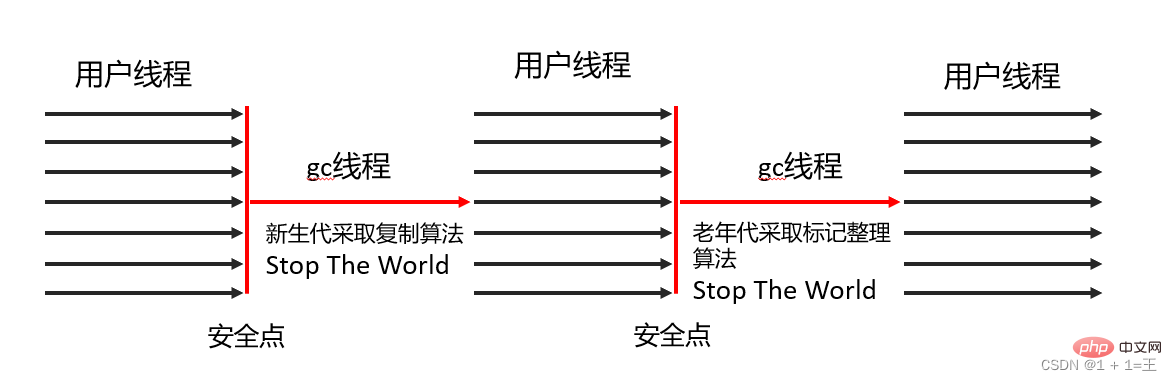
Le collecteur Parallel Scavenge est également un collecteur de nouvelle génération. C'est également un collecteur basé sur l'algorithme de marquage-copie et est également un collecteur multithread qui peut collecter en parallèle. 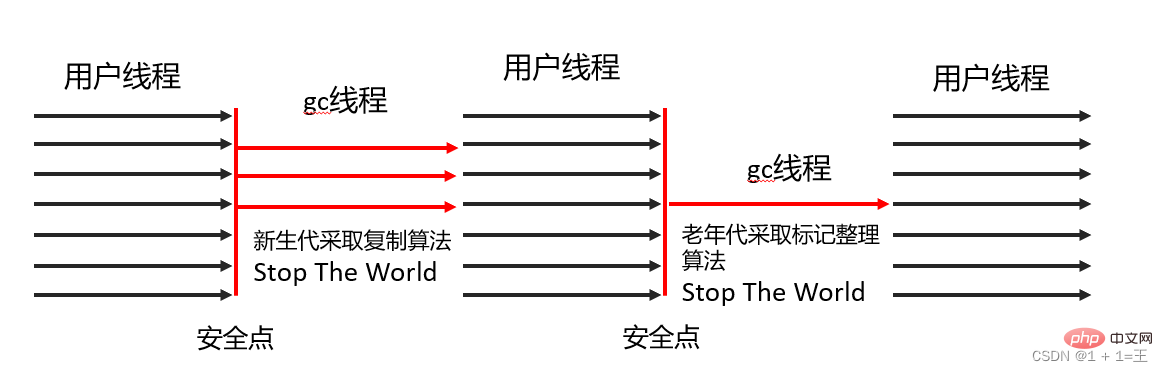 Différent du collecteur ParNew, l'objectif du collecteur de récupération Parallel est d'atteindre un
Différent du collecteur ParNew, l'objectif du collecteur de récupération Parallel est d'atteindre un
contrôlable. Il est également appelé un ramasse-miettes axé sur le débit.
Débit : rapport entre le temps passé par le processeur à exécuter le code utilisateur et le temps total du processeur consommé.
Le haut débit permet d'utiliser le plus efficacement possible les ressources du processeur et d'accomplir les tâches informatiques du programme le plus rapidement possible. Il convient principalement aux tâches d'analyse qui fonctionnent en arrière-plan et ne nécessitent pas trop d'interaction.
Parallel Old est la version d'ancienne génération du collecteur Parallel Scavenge, prend en charge la collecte simultanée multithread et est implémentée sur la base de l'algorithme de marquage-collation.
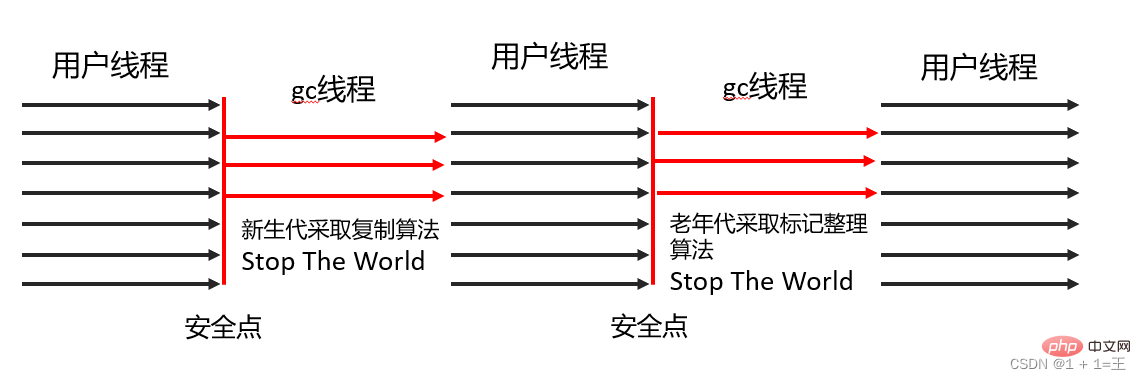
CMS Collector
Le collecteur CMS (Concurrent Mark Sweep) est un collecteur qui vise à obtenir le temps de pause de recyclage le plus court.
Le collecteur CMS est implémenté sur la base de l'algorithme mark-clear. Son fonctionnement peut être divisé en quatre étapes, dont :
- Marquage initial
Le marquage initial ne marque que les objets auxquels GC Roots peut directement s'associer, vitesse très élevée. rapide ; - Marquage simultané
La phase de marquage simultané est le processus de parcours de l'ensemble du graphe d'objets à partir des objets directement associés de GC Roots. Ce processus prend beaucoup de temps mais ne nécessite pas l'arrêt du thread utilisateur et peut s'exécuter simultanément avec. le fil de récupération de place ; - Re-marquage
La phase de re-marquage consiste à corriger les enregistrements de marquage de la partie des objets qui ont changé en raison du fonctionnement continu du programme utilisateur pendant le marquage simultané. est généralement légèrement plus longue que la phase de marquage initiale, mais elle est également beaucoup plus courte que la phase de marquage simultanée - Effacement simultané
Nettoie et supprime les objets morts jugés lors de la phase de marquage puisqu'il n'est pas nécessaire de déplacer les objets survivants ; , cette phase peut également être concurrente avec le thread utilisateur.
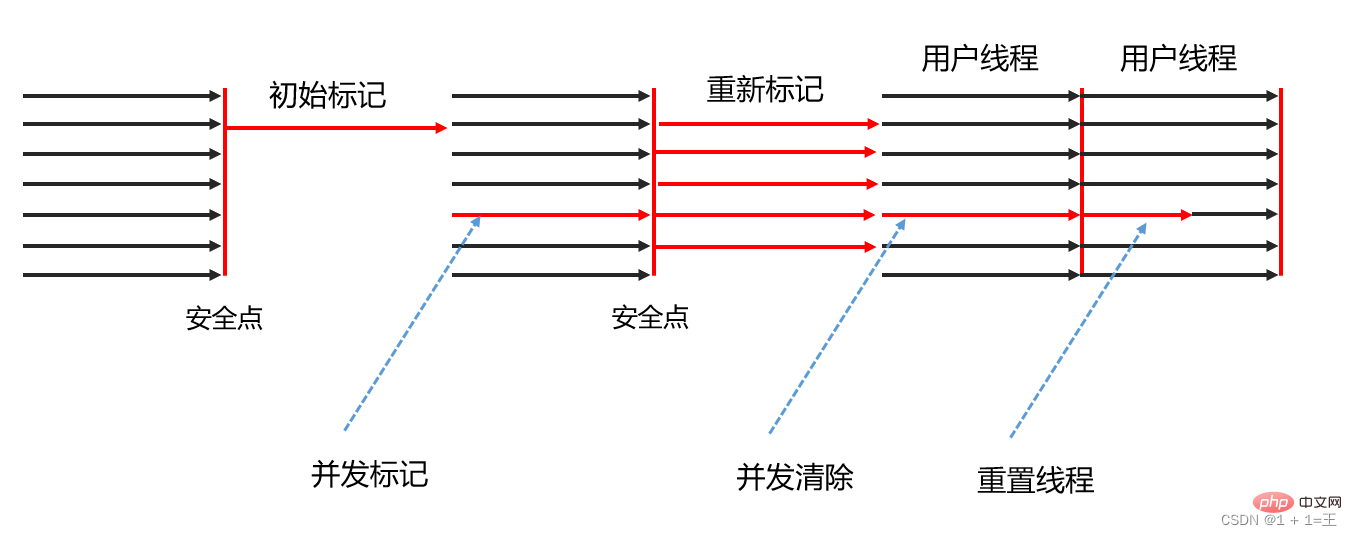
Le collecteur CMS est incapable de gérer les "Floating Garbage", et un "échec du mode simultané" peut échouer, ce qui peut conduire à un autre GC complet "Stop The World".
Pendant les phases de marquage simultané et de nettoyage simultané du CMS, le thread utilisateur est toujours en cours d'exécution. De nouveaux objets poubelles seront naturellement générés pendant l'exécution du programme, mais cette partie des objets poubelles apparaîtra une fois le processus de marquage terminé. être éliminés lors de la collecte en cours et devront être nettoyés lors de la prochaine collecte des déchets. Cette partie des déchets est appelée « déchets flottants ».
C'est aussi parce que le thread utilisateur doit continuer à s'exécuter pendant la phase de garbage collection, donc suffisamment d'espace mémoire doit être réservé pour que le thread utilisateur puisse l'utiliser, de sorte que le collecteur CMS ne peut pas attendre que l'ancienne génération soit presque complètement remplie comme les autres collecteurs. Afin de collecter à nouveau, un certain espace doit être réservé pour le fonctionnement du programme pendant la collecte simultanée.
CMS est un collecteur basé sur l'algorithme "mark-and-clear", ce qui signifie qu'un grand nombre de fragments d'espace sera généré à la fin de la collection. Lorsqu'il y aura trop de fragments d'espace, cela causera de gros problèmes. pour l'allocation d'objets volumineux.
Pourquoi ne pas utiliser un algorithme de compression de balises pour éviter la fragmentation ?
Parce que lorsque l'effacement simultané est utilisé pour organiser la mémoire avec la compression de marques, la mémoire utilisée par le thread utilisateur d'origine ne peut pas être utilisée. Pour garantir que le thread utilisateur continue de s'exécuter, le principe est que les ressources sur lesquelles il s'exécute ne sont pas affectées. La compression des drapeaux est plus adaptée aux scénarios « Stop The World ».
G1 (Garbage First) collector
Garbage First a été le pionnier de l'idée de conception du collecteur pour la collecte locale et du formulaire de disposition de la mémoire basé sur la région. Il s'agit d'un garbage collector principalement pour les applications côté serveur, principalement pour les multi-. équipement de base. Les machines dotées d'un processeur et d'une mémoire de grande capacité peuvent respecter le temps de pause du GC avec une très forte probabilité et ont également des caractéristiques de performances de débit élevées.
Pour tous les autres collecteurs avant le collecteur G1, la plage cible du garbage collection était soit l'intégralité de la nouvelle génération, l'intégralité de l'ancienne génération ou l'intégralité du tas Java. G1 peut former un ensemble de collecte pour n'importe quelle partie de la mémoire tas à recycler. Le critère de mesure n'est plus la génération à laquelle il appartient, mais quelle partie de la mémoire stocke la plus grande quantité de déchets et présente les plus grands avantages de recyclage. Caractéristiques du collecteur G1
1. Parallélisme et concurrenceParallélisme : pendant le recyclage G1, plusieurs threads GC peuvent fonctionner en même temps et le thread utilisateur arrête le monde à ce moment-là.
- Concurrency : G1 a la capacité de s'exécuter en alternance avec l'application, et une partie du travail peut être exécutée en même temps que l'application. Par conséquent, d'une manière générale, l'application ne sera pas complètement bloquée pendant toute la phase de recyclage.
3. Intégration spatiale 4. Modèle de temps de pause prévisible Utilisez des jeux de mémoire pour éviter d'analyser l'intégralité du tas en tant que racines GC. Chaque région conserve son propre jeu de mémoire. Ces jeux de mémoire enregistrent les pointeurs pointés par d'autres régions et marquent les plages de pages de carte de ces pointeurs. L'ensemble de mémoire de G1 est essentiellement une table de hachage en termes de structure de stockage. La clé est l'adresse de départ des autres régions, la valeur est un ensemble et les éléments qui y sont stockés sont les numéros d'index de la table de cartes. Shenandoah utilise également une disposition de mémoire de tas basée sur les régions. Il dispose également de régions gigantesques pour stocker les objets volumineux. La stratégie de recyclage par défaut consiste également à donner la priorité aux régions ayant la plus grande valeur de recyclage. Mais en termes de gestion de la mémoire tas, il présente au moins trois différences évidentes par rapport au G1. Le processus de travail du collectionneur Shenandoah peut être grossièrement divisé en neuf étapes suivantes : Les objectifs de ZGC et de Shenandoah sont très similaires. Ils espèrent tous deux limiter le temps de pause du garbage collection quelle que soit la taille de la mémoire tas sans affecter autant que possible le débit. Faible latence en dix millisecondes. Le collecteur ZGC est basé sur la disposition de la mémoire Région, (temporairement) sans génération. Il utilise des technologies telles que des barrières de lecture, des pointeurs colorés et un mappage multiple de mémoire pour implémenter des algorithmes de tri par marques simultanés, à faible coût. comme son objectif premier. ZGC utilise également une disposition de mémoire de tas basée sur la région, mais contrairement à eux, la région de ZGC est dynamique - création et destruction dynamiques, ainsi que taille de capacité de région dynamique. Le processus de fonctionnement de ZGC peut être divisé en quatre étapes : Quel est l'objectif principal de l'application pour ajuster le tas en premier ? Si la mémoire est inférieure à 100 Mo, utilisez le collecteur série
Comment résoudre les objets de référence inter-Régions qui existent dans Région ?
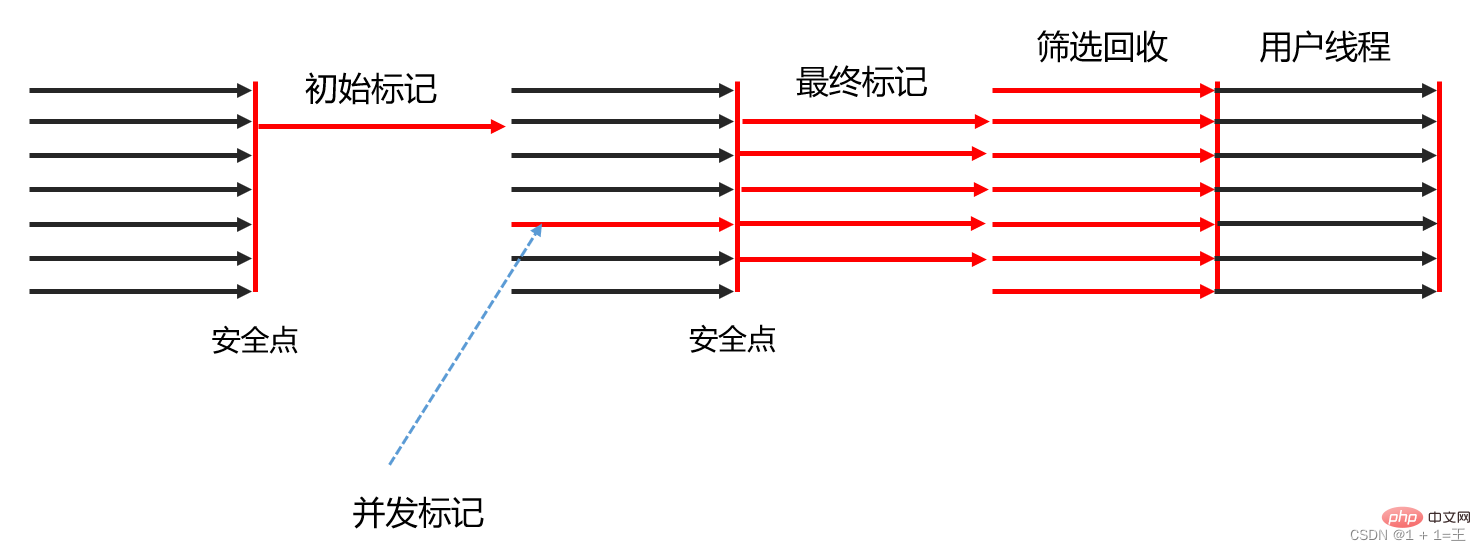
Le processus de fonctionnement du collecteur G1
Comparaison de 7 éboueurs classiques
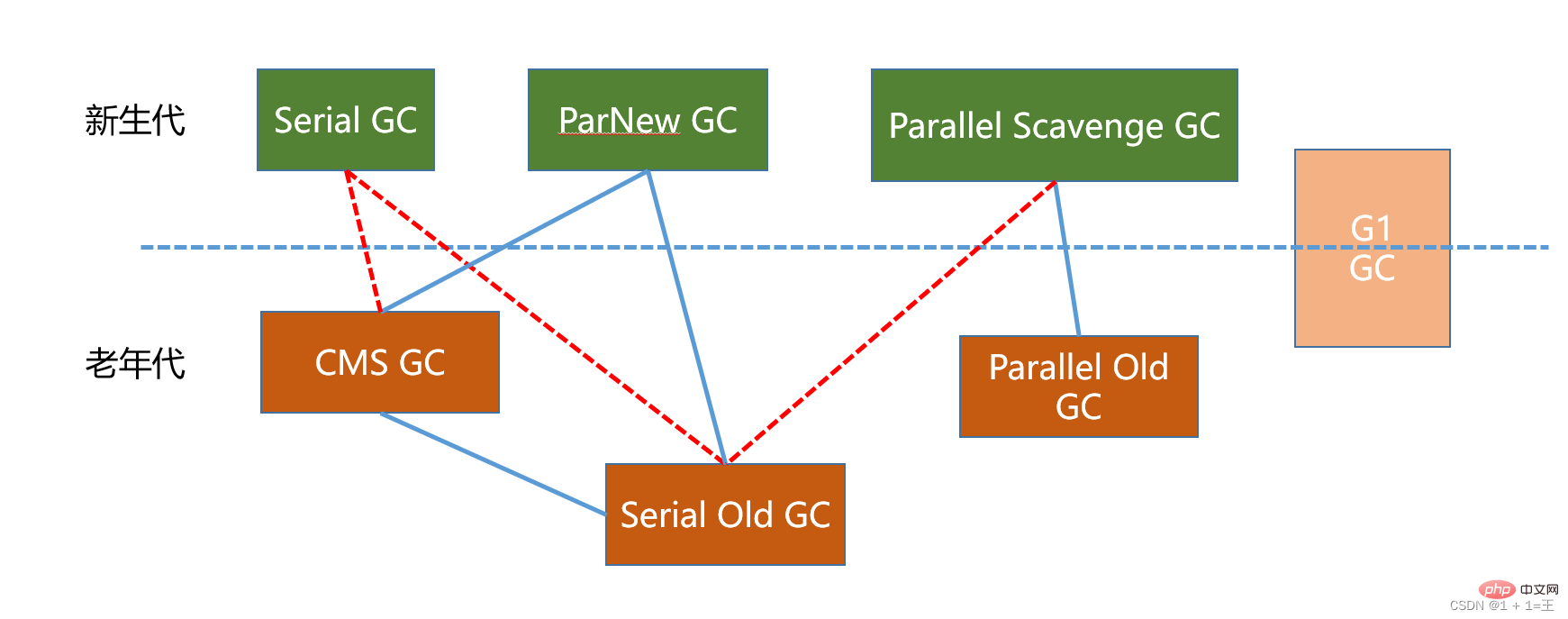
Combinaisons d'éboueurs
Récupérateur de déchets à faible latence
Collecteur Shenandoah
ZGC Collector
Considérez les trois questions suivantes :
L'architecture système impliquée est x86-32/64. ARM/Aarch64 ;
Le nombre de processeurs et la taille de la mémoire allouée ;
Comment choisir le garbage collector
S'il s'agit d'un programme monocœur autonome et qu'il n'y a pas d'exigence de temps de pause, le collecteur série
S'il est multi-CPU, il nécessite une mémoire élevée Débit, laissez le temps de pause dépasser 1 seconde, choisissez le choix parallèle ou JVM
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- [Compilation d'hématémèse] Questions et réponses d'entretien de base à haute fréquence Java 2023 (Collection)
- Qu'est-ce qu'une fermeture ? Parlons des fermetures en JavaScript et voyons quelles fonctions elles ont ?
- Analyse détaillée des interfaces JAVA et des classes abstraites
- Résumé des objets Number courants en JavaScript
- Résumer et partager les concepts de base de l'asynchrone et des rappels en JavaScript