
Maison >Java >javaDidacticiel >Résumé des connaissances Java et explication détaillée de JVM
Résumé des connaissances Java et explication détaillée de JVM

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-07-12 17:20:032164parcourir
Cet article vous apporte des connaissances pertinentes sur java, qui organise principalement les problèmes liés à la JVM, notamment la division de la zone mémoire JVM, le mécanisme de chargement des classes JVM, le garbage collection VM, etc. Jetons un coup d'œil, j'espère que cela aidera tout le monde.

Étude recommandée : "Tutoriel vidéo Java"
1. Division des zones de mémoire JVM
Pourquoi la JVM divise-t-elle ces zones est-elle appliquée à partir du système d'exploitation et la JVM est basée sur les fonctions ? pour les diviser en quelques petits modules, afin qu'un grand site puisse être divisé en quelques petits modules, et ensuite chaque module est responsable de sa propre fonction. Voyons ensuite quelles sont les fonctions de ces zones.
1. Compteur de programme
Le compteur de programme est la plus petite zone de la mémoire. Il enregistre principalement l'adresse de la prochaine instruction à exécuter (l'instruction est le bytecode. Généralement, le programme doit être exécuté par la JVM. Vous devez charger le bytecode dans la mémoire, puis le programme prend les instructions une par une de la mémoire et les place sur le CPU pour exécution, vous devez donc vous rappeler quelle instruction est actuellement exécutée et où se trouve la suivante. Le processeur ne fournit pas seulement des services à un processus, il fournit des services à tous les processus et exécute les programmes simultanément. Et comme le système d'exploitation planifie l'exécution en unités de threads, chaque thread doit avoir sa propre position d'exécution, c'est-à-dire que chaque thread a besoin d'une position d'exécution. compteur de programme pour enregistrer la position !)
2. StackLa pile stocke principalement
les variables locales et les informations d'appel de méthode, tant qu'elle implique l'appel d'une nouvelle méthode, il y aura une opération "push" à chaque fois. chaque fois qu'une méthode est exécutée, il y aura une opération "push", et chaque thread a une copie de la pile
Par conséquent, pour la récursivité, la récursivité doit être contrôlée, sinon une exception de débordement de pile (StackOverflowException) est probable. se produire !
3. Tas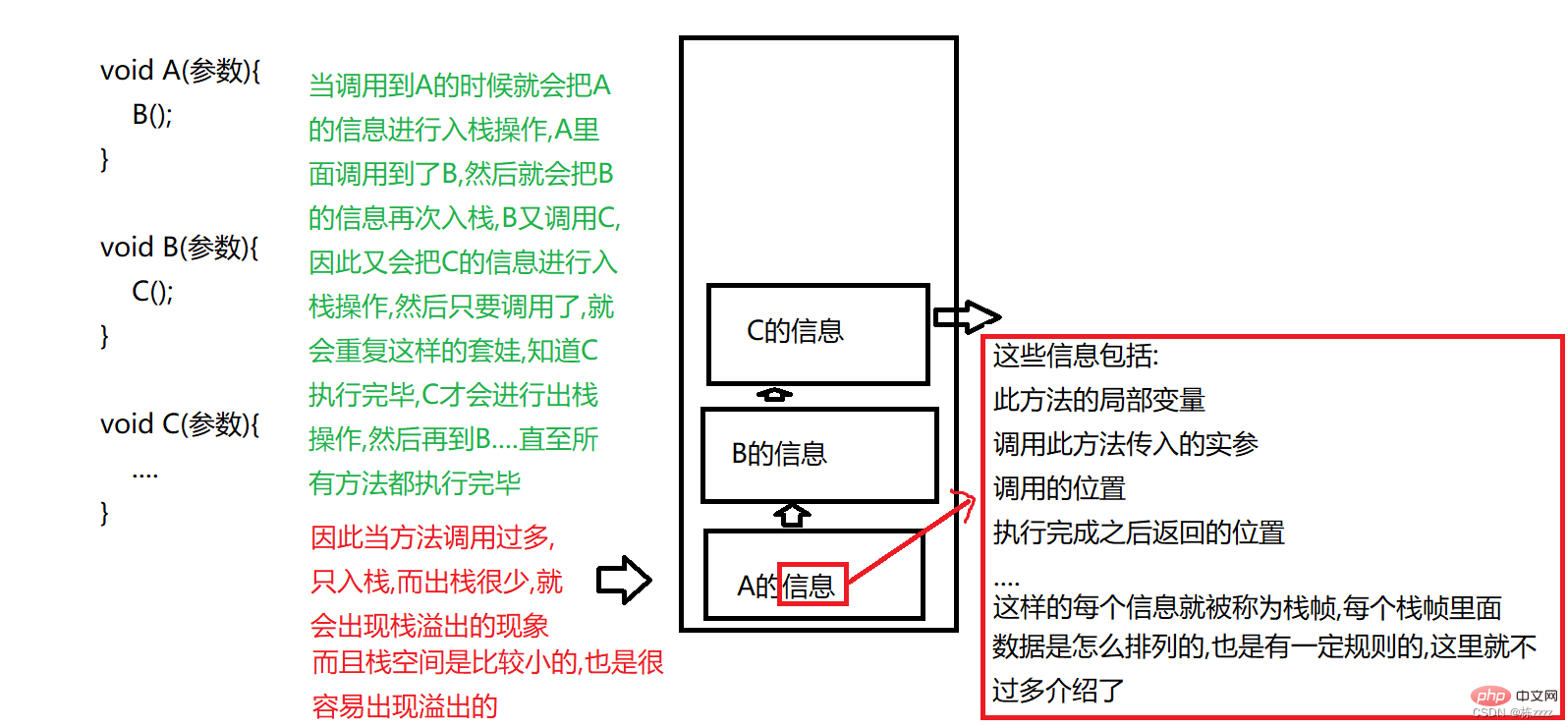
Le tas est la plus grande zone d'espace dans la mémoire, et le tas n'est qu'une copie pour chaque processus, et est partagé par plusieurs threads dans le processus. stocke principalement les nouveaux objets et les variables membres des objets. Par exemple, String s = new String() si le s ici dans la méthode est une variable locale sur la pile, si ce s est une variable membre, il est sur le tas, et new String() est l'ontologie de l'objet. L'objet est sur le tas, ce qui est facile à confondre. De plus, un autre point important du tas est la question du garbage collection, qui sera présenté en détail plus tard !
4. Zone de méthode
La zone de méthode stocke les "objets de classe" Le code .java que vous écrivez habituellement deviendra .class (bytecode binaire) après avoir été traduit par le compilateur, puis .class sera chargé en mémoire et. construits en objets de classe par la JVM (le processus de chargement est appelé "chargement de classe"), et ces objets de classe seront stockés dans la zone de méthode, qui décrit spécifiquement la longueur de la classe What (le nom de la classe, les membres de la classe. classe et leurs noms de membres, types de membres, les méthodes de la classe et leurs noms de méthodes, types de méthodes et quelques instructions... De plus, une chose très importante est stockée dans l'objet de classe, qui sont des membres statiques, qui sont généralement Les membres statiques modifiés deviennent des attributs de classe, tandis que les méthodes ordinaires sont appelées attributs d'instance, ce qui est très différent) !
L'introduction ci-dessus est une zone commune dans la JVM, et certaines zones de mémoire JVM La division n'est pas nécessairement conforme à la zone réelle La situation. La division des domaines dans le processus de mise en œuvre de la JVM est différente. Différents fabricants et différentes versions de JVM peuvent avoir des différences. Cependant, pour nous, programmeurs ordinaires, si vous n'implémentez pas JVM, vous n'en avez pas besoin. pour le comprendre si profondément. Parlez simplement des domaines communs ci-dessus et comprenez-le ! 2. Mécanisme de chargement de classe JVMLe chargement de classe est en fait un moyen de concevoir un environnement d'exécution. Les fonctions de base importantes sont très lourdes, donc je Je les présenterai brièvement ici !
Ce qui précède est le processus spécifique de chargement de classe. Les derniers processus d'utilisation et de déchargement sont les processus d'utilisation. Je ne les présenterai pas ici.
1.Chargement
Dans la phase de chargement, vous trouverez d'abord le fichier .class correspondant, puis ouvrirez et lisez (selon le flux d'octets) le fichier .class, et en même temps générerez initialement un objet de classe, ce et le chargement de classe terminé est différent, ne vous y trompez pas ! Le format spécifique du fichier de classe (si vous souhaitez implémenter un compilateur Java, il doit être construit dans ce format, et si vous implémentez la JVM, vous devez charger dans ce format ! ): Si vous observez ce format, vous pouvez voir que le fichier .class exprime toutes les informations de base du fichier .java. Cependant, le format organisationnel a changé, donc le lien de chargement utilisera le. lire les informations. Remplissez au préalable l'objet de classe
Si vous observez ce format, vous pouvez voir que le fichier .class exprime toutes les informations de base du fichier .java. Cependant, le format organisationnel a changé, donc le lien de chargement utilisera le. lire les informations. Remplissez au préalable l'objet de classe
La vérification de la lecture. le contenu reçu correspond exactement au format stipulé dans la spécification ? S'il s'avère que le format des données lues n'est pas conforme à la spécification, le chargement de la classe échouera et une exception sera levée 2.2.
L'étape de préparation est
Dans l'étape d'allocation formelle de mémoire pour les variables définies (variables statiques, qui sont des variables modifiées par statique) et de définition de la valeur initiale de la variable de classe, chaque variable statique se verra attribuer de la mémoire et sera définie sur une valeur de 0 ! 2.3.Résolution (Analyse) L'étape de résolution est le processus dans lequel la machine virtuelle Java remplace les références de symboles dans le pool de constantes par des références directes, qui est également le processus d'initialisation des constantes dans le. Le fichier .class est placé au centre et chaque constante aura un numéro. La situation initiale dans la structure du fichier .class est simplement le numéro d'enregistrement, et vous pouvez ensuite trouver le contenu correspondant en fonction de ce numéro, puis le remplir. l'objet de classe !
3. Initialisation (Initialisation)
L'étape d'initialisation est Initialiser réellement l'objet de classe (selon le code écrit), en particulier pour les membres statiques
4. Questions d'entretien typiques
class A {
public A(){
System.out.println("A的构造方法");
}
{
System.out.println("A的构造代码块");
}
static {
System.out.println("A的静态代码块");
}}class B extends A{
public B(){
System.out.println("B的构造方法");
}
{
System.out.println("B的构造代码块");
}
static {
System.out.println("B的静态代码块");
}}public class Test extends B{
public static void main(String[] args) {
new Test();
new Test();
}}
Vous pouvez essayer pour écrire vous-même d'abord les résultats de sortie
Vous devez maîtriser de telles questions Plusieurs principes majeurs :
Le bloc de code statique sera exécuté pendant la phase de chargement de la classe. Si vous souhaitez créer une instance, vous devez d'abord effectuer une classe. chargement
- Le bloc de code statique n'est exécuté qu'une seule fois pendant la phase de chargement de la classe, et toutes les autres phases sont Il ne sera pas exécuté à nouveau
- La méthode de construction et le bloc de code de construction seront exécutés à chaque fois qu'il sera instancié, et le bloc de code de construction sera exécuté devant la méthode de construction~~
- La classe parent sera exécutée en premier, et la sous-classe sera exécutée plus tard !
- Le programme est exécuté depuis main, la méthode Test de main, donc pour exécuter main, vous devez d'abord charger la classe Test
- Seulement lorsque cette classe est impliquée, les éléments de la classe seront chargés
-
输出结果: A的静态代码块 B的静态代码块 A的构造代码块 A的构造方法 B的构造代码块 B的构造方法 A的构造代码块 A的构造方法 B的构造代码块 B的构造方法
Modèle de délégation parentale -
Cette chose est. un lien dans le chargement de la classe. C'est dans l'étape de chargement (la partie précédente). Le modèle de délégation parent
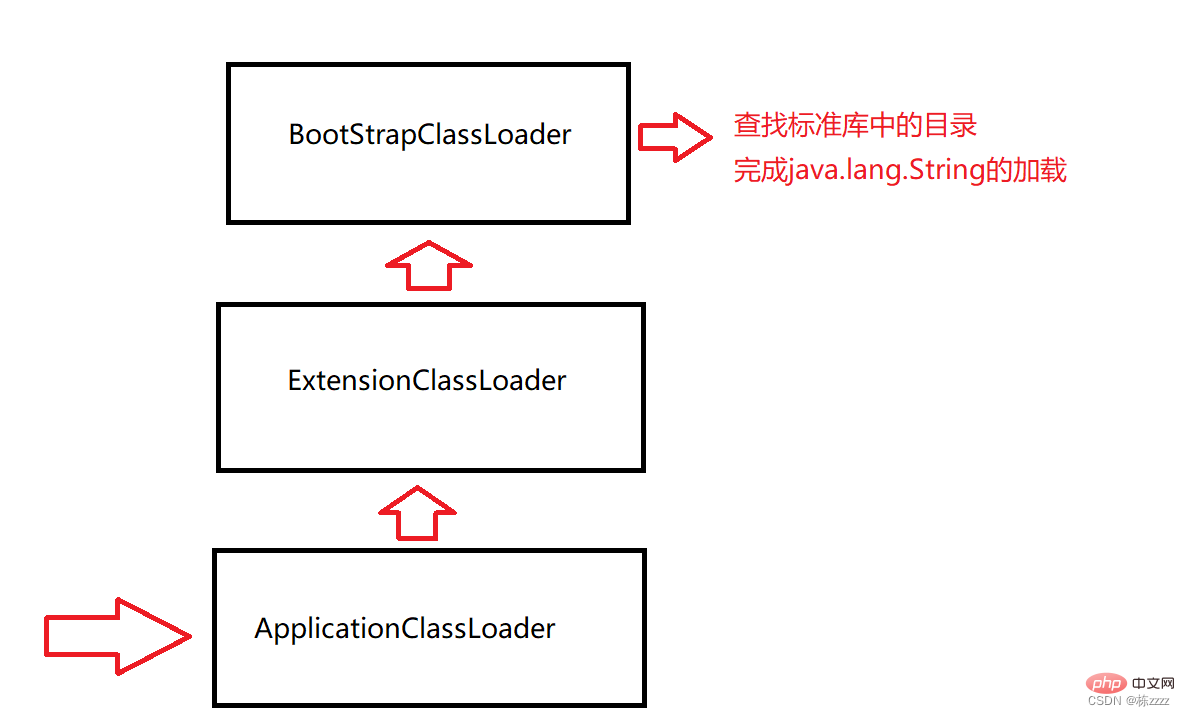
décrit le chargeur de classe dans la JVM, comment utiliser le nom complet de la classe (java.lang.String) Le processus. de trouver le fichier .class . Le chargeur de classe ici est un objet spécialement fourni par la JVM. Il est principalement responsable du chargement des classes, donc le processus de recherche de fichiers est également responsable du chargeur de classe. Il existe de nombreux endroits où les fichiers .class peuvent être placés, et certains d'entre eux. ils doivent être placés dans le répertoire JDK, certains sont placés dans le répertoire du projet et d'autres dans d'autres emplacements spécifiques, donc la JVM fournit plusieurs chargeurs de classes, chaque chargeur de classe est responsable d'une tranche, et il y a principalement 3 classes par défaut. chargeurs :
BootStrapClassLoader : Responsable du chargement des classes dans la bibliothèque standard (String, ArrayList, Random, Scanner...)
- ExtensionClassLoader : Responsable du chargement des classes d'extension JDK (rarement utilisé maintenant)
- ApplicationClassLoader : Responsable du chargement des classes actuelles dans le répertoire du projet
- De plus, les programmeurs peuvent également personnaliser les chargeurs de classes pour charger des classes dans d'autres répertoires. Tomcat a personnalisé un chargeur de classes pour charger spécifiquement les .classes dans les applications Web
- Le parent. Le modèle de délégation décrit le processus de recherche d'un répertoire, c'est-à-dire la manière dont les chargeurs de classe ci-dessus coopèrent. Pensez à rechercher java.lang.String :
- Lorsque le programme démarre, il entrera d'abord dans le chargeur de classe ApplicationClassLoader
. Le chargeur de classe ApplicationClassLoader vérifiera si son chargeur parent a été chargé. Sinon, appelez le chargeur de classe parent ExtensionClassLoader
- Le chargeur de classe ExtensionClassLoader vérifiera si son chargeur de classe parent a été chargé. été chargé, puis constate qu'il n'y a pas de père, alors il s'analyse Répertoire responsable
Ensuite, la classe java.lang.String peut être trouvée dans la bibliothèque standard, puis le chargeur BootStrapClassLoader sera responsable du processus de chargement ultérieur, et le processus de recherche est terminé

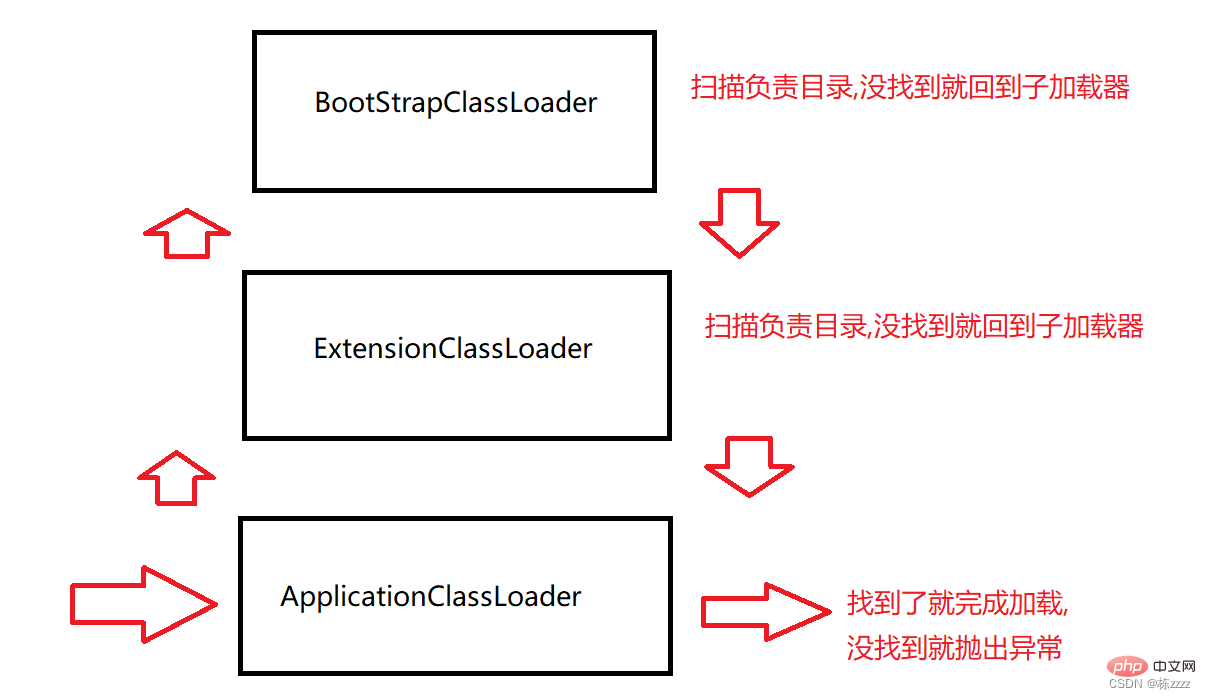
Envisagez de chercher quelque chose ! écrit par vous-même Classe de test : lorsque le programme démarre, il entrera d'abord dans le chargeur de classe ApplicationClassLoader. Le chargeur de classe ApplicationClassLoader vérifiera si son chargeur parent a été chargé. Sinon, il appellera le chargeur de classe parent. vérifiez si son chargeur parent a été chargé. Sinon, il appellera le chargeur de classe parent BootStrapClassLoader
BootStrapClassLoader. Le chargeur de classe vérifiera également si le chargeur parent a été chargé, puis le trouvera. n'est pas un père, il analyse donc le répertoire dont il est responsable, et s'il n'est pas analysé, il reviendra au chargeur enfant pour continuer l'analyse
ExtensionClassLoader analyse le répertoire dont il est responsable, et il n'y a pas d'après l'analyse , revenez au sous-chargeur et continuez l'analyse
ApplicationClassLoader analyse également le répertoire dont il est responsable. Les classes que vous écrivez se trouvent dans votre propre répertoire de projet, vous pouvez donc les trouver, puis le chargement ultérieur des classes est effectué par ApplicationClassLoad. , à ce stade, le processus de recherche dans le répertoire est terminé ~~ (De plus, si ApplicationClassLoader ne les trouve pas, il lèvera une exception ClassNotFoundException)
- Cet ensemble de règles de recherche est appelé la délégation parent modèle, alors pourquoi la JVM a-t-elle besoin La raison de cette conception est qu'une fois que la classe écrite par le programmeur a le même nom de classe complet, la classe de la bibliothèque standard peut être chargée avec succès au lieu de la classe écrite par le programmeur !! !
- De plus, s'il s'agit d'un chargeur de classes personnalisé, souhaitez-vous vous conformer à ce modèle de délégation parentale ?
La réponse est que vous pouvez vous y conformer ou non, cela dépend principalement des exigences. Par exemple, si Tomcat charge les classes. dans la webapp, il n'est pas conforme, car il est impossible de trouver le chargeur de classe qui soit conforme à ce qui précède !
3 Le garbage collection de la JVM -
Le
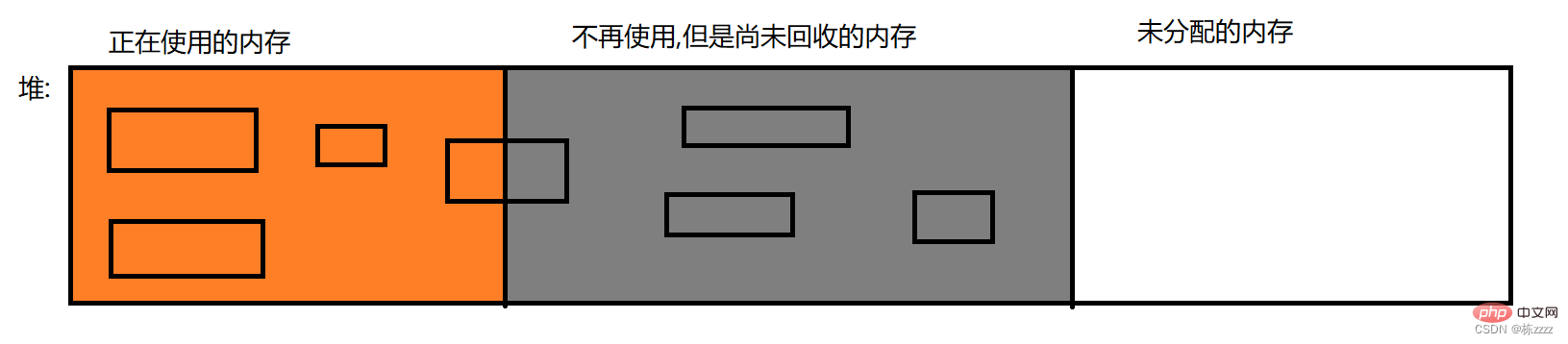
La libération de mémoire doit être parfaite
garbage collection (GC) dans la JVM. code, cela implique souvent une demande de mémoire, comme créer une variable, un nouvel objet et appeler une méthode, charger une classe... Le timing de l'application de la mémoire est généralement clair (vous devez demander de la mémoire si vous avez besoin de sauvegarder certains données ou données), mais le moment de la libération de la mémoire n'est pas si clair, et cela ne fonctionnera pas si vous la libérez trop tôt (si elle doit encore être utilisée, mais en conséquence, elle a été libérée, ce qui signifie qu'il y a Il n'y a pas de mémoire disponible et les données n'ont "nulle part où aller"), et cela ne fonctionnera pas si elles sont libérées trop tard (si elles sont libérées tardivement, une grande quantité de thésaurisation est susceptible de les rendre disponibles) Au fur et à mesure que la mémoire augmente devient moindre, il est très probable que des fuites de mémoire se produiront (c'est-à-dire qu'il n'y a pas de mémoire à utiliser), donc !
 . code, cela implique souvent une demande de mémoire, comme créer une variable, un nouvel objet et appeler une méthode, charger une classe... Le timing de l'application de la mémoire est généralement clair (vous devez demander de la mémoire si vous avez besoin de sauvegarder certains données ou données), mais le moment de la libération de la mémoire n'est pas si clair, et cela ne fonctionnera pas si vous la libérez trop tôt (si elle doit encore être utilisée, mais en conséquence, elle a été libérée, ce qui signifie qu'il y a Il n'y a pas de mémoire disponible et les données n'ont "nulle part où aller"), et cela ne fonctionnera pas si elles sont libérées trop tard (si elles sont libérées tardivement, une grande quantité de thésaurisation est susceptible de les rendre disponibles) Au fur et à mesure que la mémoire augmente devient moindre, il est très probable que des fuites de mémoire se produiront (c'est-à-dire qu'il n'y a pas de mémoire à utiliser), donc
. code, cela implique souvent une demande de mémoire, comme créer une variable, un nouvel objet et appeler une méthode, charger une classe... Le timing de l'application de la mémoire est généralement clair (vous devez demander de la mémoire si vous avez besoin de sauvegarder certains données ou données), mais le moment de la libération de la mémoire n'est pas si clair, et cela ne fonctionnera pas si vous la libérez trop tôt (si elle doit encore être utilisée, mais en conséquence, elle a été libérée, ce qui signifie qu'il y a Il n'y a pas de mémoire disponible et les données n'ont "nulle part où aller"), et cela ne fonctionnera pas si elles sont libérées trop tard (si elles sont libérées tardivement, une grande quantité de thésaurisation est susceptible de les rendre disponibles) Au fur et à mesure que la mémoire augmente devient moindre, il est très probable que des fuites de mémoire se produiront (c'est-à-dire qu'il n'y a pas de mémoire à utiliser), donc le garbage collection présente également des inconvénients : ① Cela consomme une surcharge supplémentaire (plus de ressources sont consommées) ; le programme (La collecte des déchets introduit souvent des problèmes STW (Stop The World))
Quel type de mémoire les déchets sont-ils collectés ?
Heap : C'est la mémoire qui nécessite le plus de GC. Une grande quantité de mémoire en général est sur le tas Laquelle de ces trois zones doit être libérée pour ce genre d'objets, certains sont utilisés ? certains ne sont plus utilisés, en général, ils ne sont pas libérés. Ce n'est que lorsque l'objet n'est plus utilisé qu'il sera publié. Par conséquent, la moitié de l'objet n'apparaîtra pas dans le GC. l'objet. Au lieu d'octets !
Zone de méthode : les objets de classe, le chargement de classe et la mémoire ne doivent être libérés que lorsque la classe est déchargée, et l'opération de déchargement est à très basse fréquence, il n'y a donc presque aucun GC impliqué !
Regardons de plus près comment recycler :
1. Rechercher les déchets/déterminer les déchetsIl existe actuellement deux solutions courantes :
- 1.1 Basée sur le comptage de références
- Ce n'est pas la solution adoptée en Java, this C'est une solution pour Python et d'autres langages, je vais donc la présenter brièvement ici sans entrer trop dans les détails~
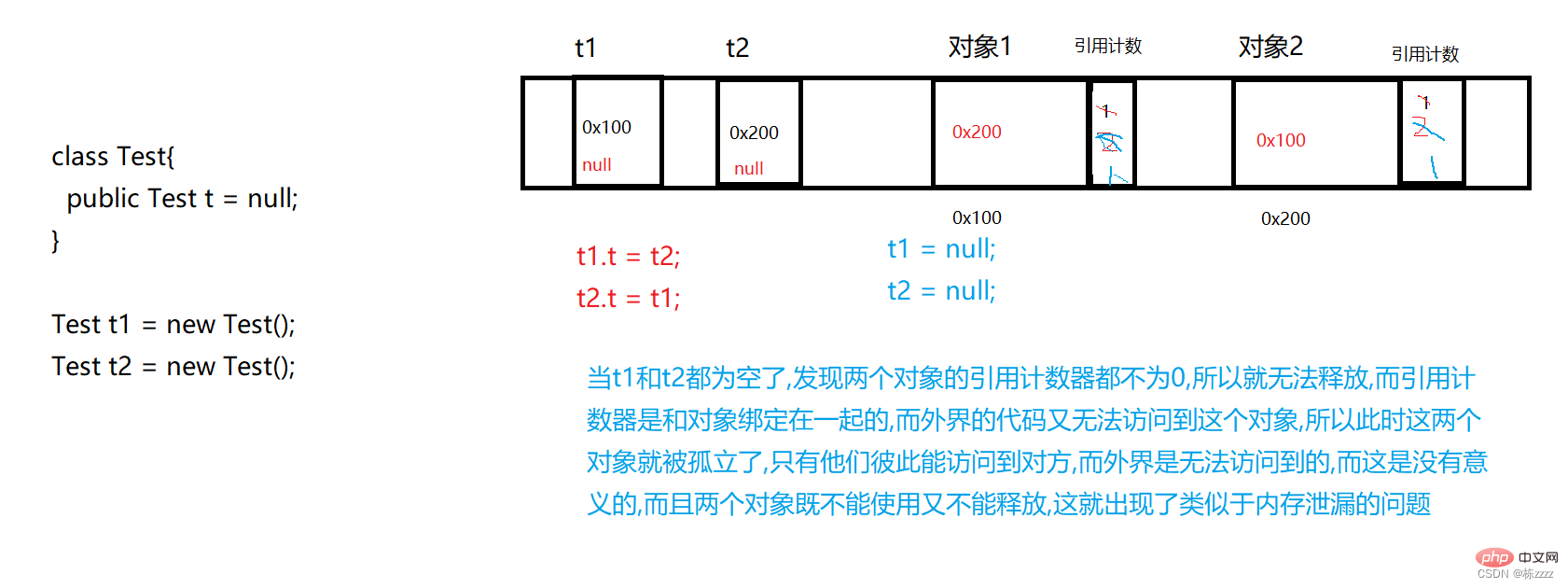
- L'idée spécifique du comptage de références est que pour chaque objet, un petit morceau de mémoire supplémentaire sera introduit dans enregistrez le nombre de références de cet objet. Pointez-le
Et il y a deux défauts dans un tel décompte de références :
- L'utilisation de l'espace est relativement faible !!!, chaque nouvel objet doit être équipé d'un compteur, en supposant qu'un compteur fait 4 octets, si l'objet lui-même est relativement grand (des centaines d'octets), alors ce compteur ne le fait pas C'est important, et une fois que l'objet lui-même est relativement petit (4 octets), alors les 4 octets supplémentaires équivaudront à doubler l'utilisation de l'espace, donc l'utilisation de l'espace sera relativement faible ~
- Il y a une boucle Problèmes de référence
Par conséquent, l'utilisation du comptage de références posera de nombreux problèmes. Des langages tels que Python et PHP n'utilisent pas seulement des compteurs de références pour compléter le GC, mais utilisent également d'autres mécanismes pour le compléter !Basé. sur l'analyse d'accessibilité
l'analyse d'accessibilité est une solution adoptée par Java. L'analyse d'accessibilité consiste à analyser périodiquement les objets dans tout l'espace mémoire via certains threads supplémentaires, à quelques exceptions près. La position de départ (GCRoots), puis elle est similaire à la profondeur- premier parcours (peut être imaginé comme un arbre), marquant tous les objets accessibles d'un côté (les objets marqués sont des objets accessibles), mais les objets non marqués sont des objets inaccessibles, c'est-à-dire des déchets, et doivent être libérés Les GCRoots ici (début ! traversant à partir de ces emplacements) :
Variables locales sur la pile ;
Donc l'avantage de l'accessibilité ; L'analyse est qu'elle résout les défauts du comptage de références : la faible utilisation de l'espace et les références circulaires- Objets pointés par des références dans le pool constant ;
- L'objet pointé par les membres statiques dans la zone de méthode ;
; ainsi que les défauts de l'analyse d'accessibilité sont également évidents :La surcharge du système est élevée, et le parcourir une fois peut être lent~Donc, trouver des ordures est également très simple. L'essentiel est de confirmer si cet objet sera utilisé à l'avenir et de voir s'il y a des références pointant vers lui, et s'il doit être publié !
2. Libérez les ordures
Maintenant que nous l'avons. Après avoir clarifié ce qu'est un déchet, l'étape suivante consiste à recycler les déchets. Il existe trois stratégies de base pour recycler les déchets. Jetons un coup d'œil !
2.1 Balises - Veuillez supprimer
Le marquage est le processus d'analyse de l'accessibilité. , et l'effacement consiste à libérer de la mémoire
. Supposons que ce qui précède est un morceau de mémoire et que la zone cochée représente des déchets si vous la libérez directement à ce moment-là, bien que la mémoire soit renvoyée au système, la mémoire sera libérée. La mémoire est discrète, non continue, et le problème qui en résulte est la « fragmentation de la mémoire ». Il peut y avoir beaucoup de mémoire libre. Supposons que le total soit de 1 Go. Si vous souhaitez demander 500 Mo d'espace à ce moment-là, vous devez le faire. peut s'appliquer est arrivé, mais l'application peut échouer ici (car les 500 Mo à demander sont de la mémoire continue, la mémoire appliquée à chaque fois est un espace mémoire continu, et le 1G ici peut être la somme de plusieurs fragments), donc un tel. Le problème affecte en fait grandement le fonctionnement du programme2.2. Algorithme de copie
Étant donné que la stratégie d'effacement des marques ci-dessus peut provoquer des problèmes de fragmentation de la mémoire,
L'algorithme de copie est introduit pour résoudre ce problèmeFaible utilisation de l'espace mémoire (seule la mémoire générale est utilisée) );
Ci-dessus, c'est un morceau de mémoire. La stratégie de l'algorithme de copie est d'utiliser la moitié de la mémoire, d'en jeter la moitié et de ne pas l'utiliser en totalité. Copiez les parties qui ne sont pas des ordures dans l'autre moitié (cette copie est traitée en interne par la JVM, donc ne la copiez pas). ne vous inquiétez pas), puis mettez le précédent. Toute la mémoire utilisée est libérée, de sorte que le problème de fragmentation de la mémoire soit résolu !
- S'il y a beaucoup d'objets à conserver et peu d'objets à libérer, le coût de la copie sera très élevé
- 2.3 Marquage-organisation
C'est une autre
amélioration supplémentaire de l'algorithme de copie. !
Marquage et organisation La stratégie consiste à
C'est similaire à l'opération de suppression d'éléments intermédiaires dans une table de séquence. ! Cette solution a une utilisation élevée de l'espace. Mais il n'y a toujours aucun moyen de résoudre le problème de la surcharge élevée liée à la copie/déplacement d'éléments
Bien que les trois solutions ci-dessus puissent résoudre le problème, elles ont toutes leurs propres défauts, donc en fait ! , l'implémentation dans la JVM combinera plusieurs solutions. , c'est-à-dire le "recyclage générationnel" !!!2.4 Recyclage générationnel
La génération consiste ici à classer les objets (classement selon "l'âge" de l'objet, et le L'âge signifie ici qu'un objet a survécu à un cycle de numérisation GC est appelé "un an de plus"), et différents plans sont adoptés pour les objets d'âges différents !!!
C'est tout le processus de recyclage générationnel !3. Garbage collector
Le garbage collection et la garbage release ci-dessus ne sont que des idées algorithmiques, pas un véritable processus de mise en œuvre. Ce qui implémente réellement le module d'algorithme ci-dessus est le "garbage collector". Introduisons quelques Garbage collector spécifiques :
3.1. Serial Collector et Serial Old Collector
Le Serial Old Collector est un garbage collector pour la nouvelle génération, et le Serial Old collector est un garbage collector pour l'ancienne génération. Ces deux collecteurs sont collectés en série, et lorsque les déchets sont analysés et libérés. , le fil d'affaires doit cesser de fonctionner, donc le scan est plein et la sortie est lente de cette façon, et il peut également produire de sérieux STW
3.2 Collecteur ParNew collection, Parallel Scavenge collector et Parallel Old collector
ParNew collector ! , Le collecteur Parallel Scavenge est fourni à la nouvelle génération. Le collecteur Parallel Scavenge ajoute certains paramètres par rapport au collecteur ParNew, qui peut contrôler le temps STW, c'est-à-dire qu'avec des fonctions plus puissantes, le collecteur Parallel Old est fourni pour l'ancienne génération. les collecteurs collectent tous en parallèle, ce qui introduit une approche multithread pour résoudre les fonctions d'analyse des déchets et de libération des déchets !
Ci-dessus Ces collecteurs sont des vestiges de l'histoire, qui sont des méthodes de collecte des déchets plus anciennes.
3.3. Collecteur CMS
Le collecteur CMS est conçu de manière plus intelligente. L'intention originale de sa conception est de rendre le temps STW aussi court que possible. Java8 utilise le collecteur CMS. processus du collecteur CMS :
Marquage initial : la vitesse est très rapide et provoquera un court STW (il suffit de rechercher GCRoots) ;
Collecteur 3.4.G1 Le collecteur G1 est- Marquage simultané : il est très rapide, mais peut être exécuté simultanément avec le thread métier, et ne générera pas STW ;
- Remarque : 2 codes métier peuvent affecter les résultats du marquage simultané (lorsque le thread métier est en cours d'exécution, de nouveaux déchets peuvent être générés), cette étape consiste donc à affiner les résultats de 2. Bien que cela provoque du STW, il ne s'agit que d'un réglage fin et la vitesse est très rapide ;
- Les trois étapes ci-dessus sont toutes basées sur l'analyse d'accessibilité !
Recyclage de la mémoire : les threads métier s'exécutent également simultanément et ne généreront pas de STW. basé sur le tri des marques ;
le seul ramasse-miettes de région complète, et G1 est utilisé depuis Java11 Collector, ce collecteur divise la mémoire entière en plusieurs petites régions et les marque régions différemment. Certaines régions placent des objets de nouvelle génération et certaines régions mettent des objets d'ancienne génération. Ensuite, lors de l'analyse, analysez plusieurs régions à la fois (vous ne souhaitez pas terminer l'analyse en un seul cycle de GC, mais devez analyser plusieurs fois). , donc l'impact sur le code métier est également minime.
L'idée principale de ces deux nouveaux collecteurs est de les diviser en parties. G1 peut actuellement être optimisé pour rendre le temps de pause STW inférieur à 1 ms, ce qui est tout à fait acceptable. ! Ce qui précède est un apprentissage sur la JVM. Le collecteur ici concerne principalement la compréhension, et les idées de garbage collection ci-dessus sont très importantes !!! Apprentissage recommandé : "Tutoriel vidéo Java"
 ici
ici 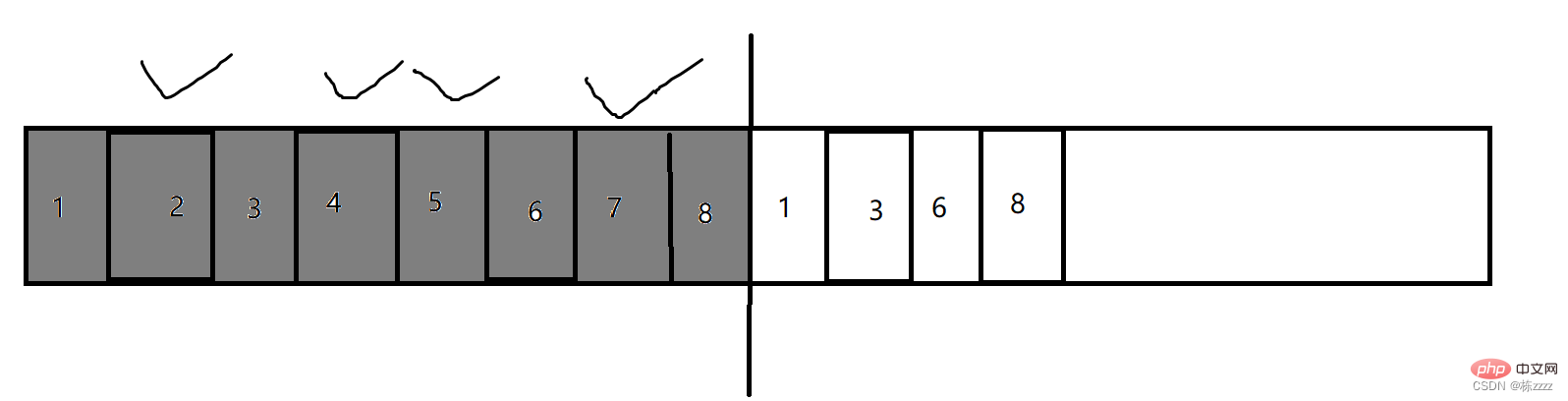 L'algorithme de copie a donc deux gros problèmes :
L'algorithme de copie a donc deux gros problèmes : 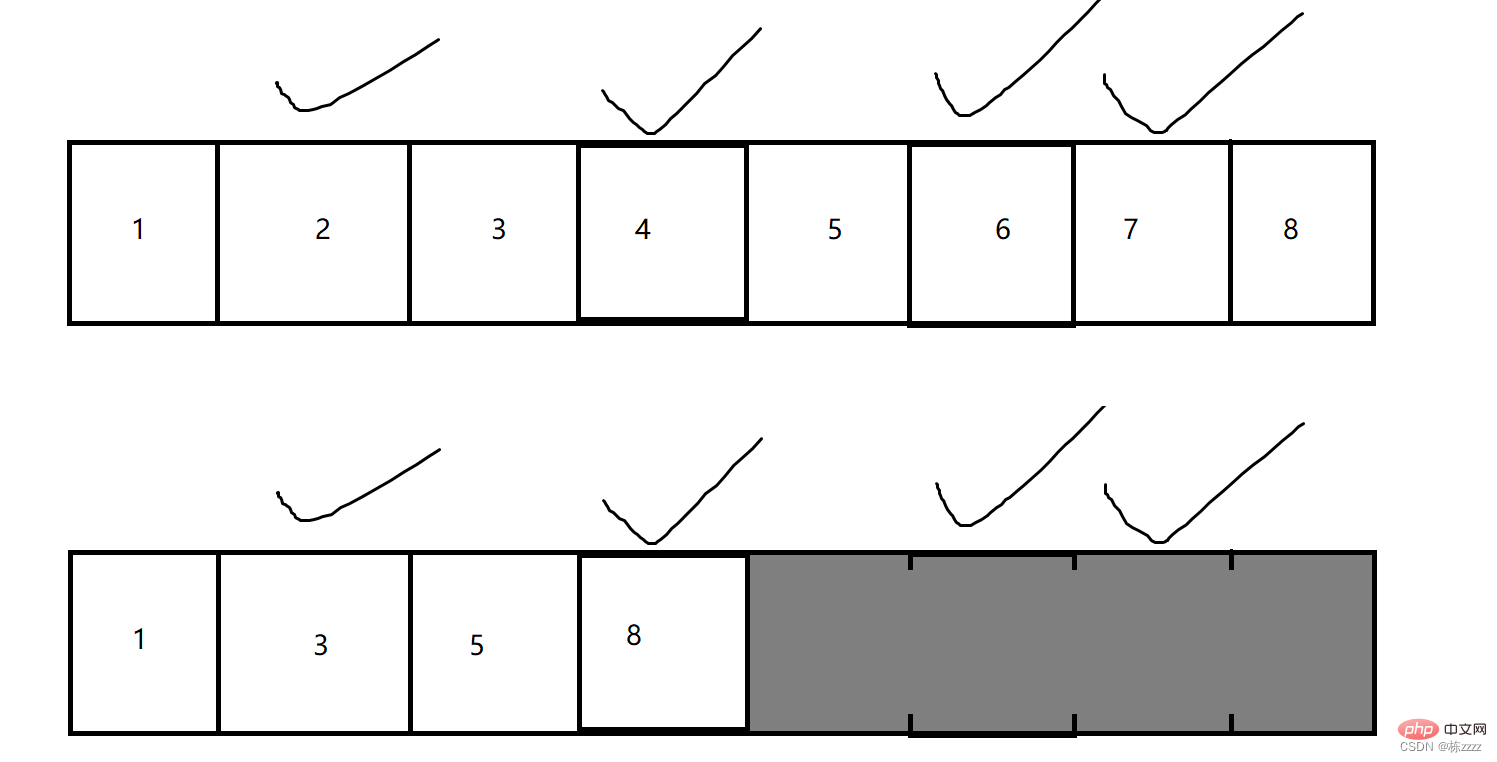 organiser la mémoire qui n'est pas un déchet ensemble, puis à libérer toute la mémoire suivante
organiser la mémoire qui n'est pas un déchet ensemble, puis à libérer toute la mémoire suivante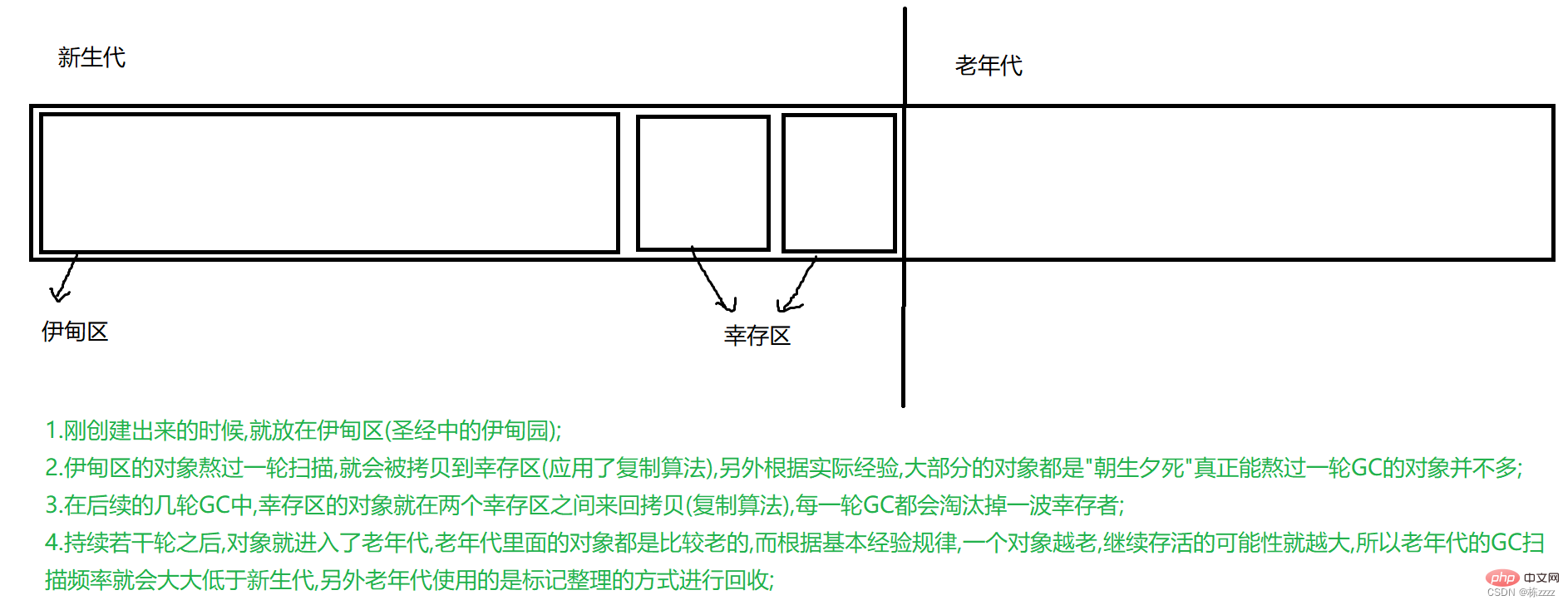
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- float est-il un mot-clé JavaScript ?
- Quatre façons d'implémenter le multithreading en Java
- Explication détaillée des points de connaissance du prototype JavaScript et de la chaîne de prototypes
- [Compilation d'hématémèse] Questions et réponses d'entretien de base à haute fréquence Java 2023 (Collection)
- Qu'est-ce qu'une fermeture ? Parlons des fermetures en JavaScript et voyons quelles fonctions elles ont ?