
Maison >développement back-end >Tutoriel Python >Premiers pas avec le robot d'exploration Python : exploration d'images Web
Premiers pas avec le robot d'exploration Python : exploration d'images Web

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-07-11 12:06:363086parcourir
Cet article vous apporte des connaissances pertinentes sur Python, qui organise principalement les problèmes liés à l'exploration d'images Web. Si vous souhaitez obtenir des données efficacement, les robots d'exploration sont très faciles à utiliser, et utiliser Python pour créer des robots d'exploration est également très utile. est simple et pratique. Jetons un coup d'œil au processus de base d'écriture d'un robot à travers un simple petit programme de robot. Examinons-le ensemble, j'espère que cela sera utile à tout le monde.

【Recommandation associée : Tutoriel vidéo Python3】
Dans cette ère d'explosion de l'information, les robots d'exploration sont très faciles à utiliser si vous souhaitez obtenir des données efficacement. Il est également très simple et pratique d'utiliser Python pour créer un robot. Jetons un coup d'œil au processus de base d'écriture d'un robot via un simple petit programme de robot :
Préparation
Langue : python
IDE : pycharm
.Tout d'abord, vous devez utiliser Parce que c'est le programme le plus simple pour débuter, nous utilisons principalement les deux bibliothèques suivantes :
import requests //用于请求网页 import re //正则表达式,用于解析筛选网页中的信息
Parmi elles, re est livré avec python, et la bibliothèque de requêtes doit être installée par nous-mêmes. Entrez simplement les demandes d'installation pip dans la ligne de commande.
Ensuite, trouvez un site Web au hasard, veillez à ne pas essayer d'explorer des informations sensibles à la confidentialité. Voici un site Web d'émoticônes :
Remarque : le contenu du site Web d'émoticônes ici peut être téléchargé gratuitement, le robot d'exploration simplifie donc simplement notre processus. . Dans ce processus, veillez à ne pas explorer les ressources payantes.
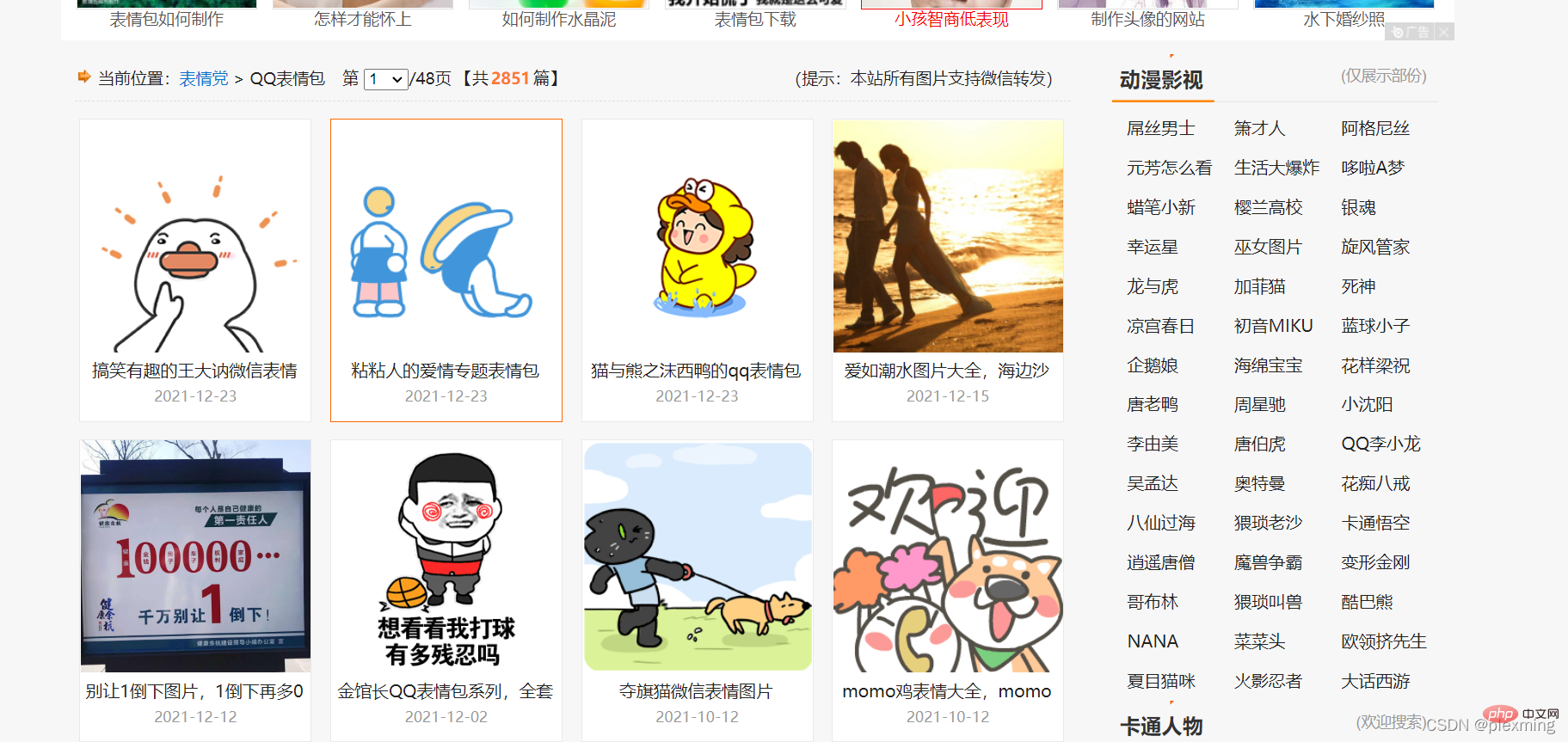
Ce que nous devons faire est de télécharger ces émoticônes sur notre ordinateur via un robot.
Écrire un programme d'exploration
Tout d'abord, vous devez accéder à ce site Web via python. Le code est le suivant :
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:98.0) Gecko/20100101 Firefox/98.0'
}
response = requests.get('https://qq.yh31.com/zjbq/',headers=headers) //请求网页
La raison pour laquelle la section d'en-têtes est ajoutée est parce que certaines pages Web reconnaîtront que vous faites une demande via python. et vous rejetons, nous passons donc à un en-tête de demande normal. Vous pouvez en trouver un au hasard ou utiliser f12 pour en copier un à partir des informations du réseau.
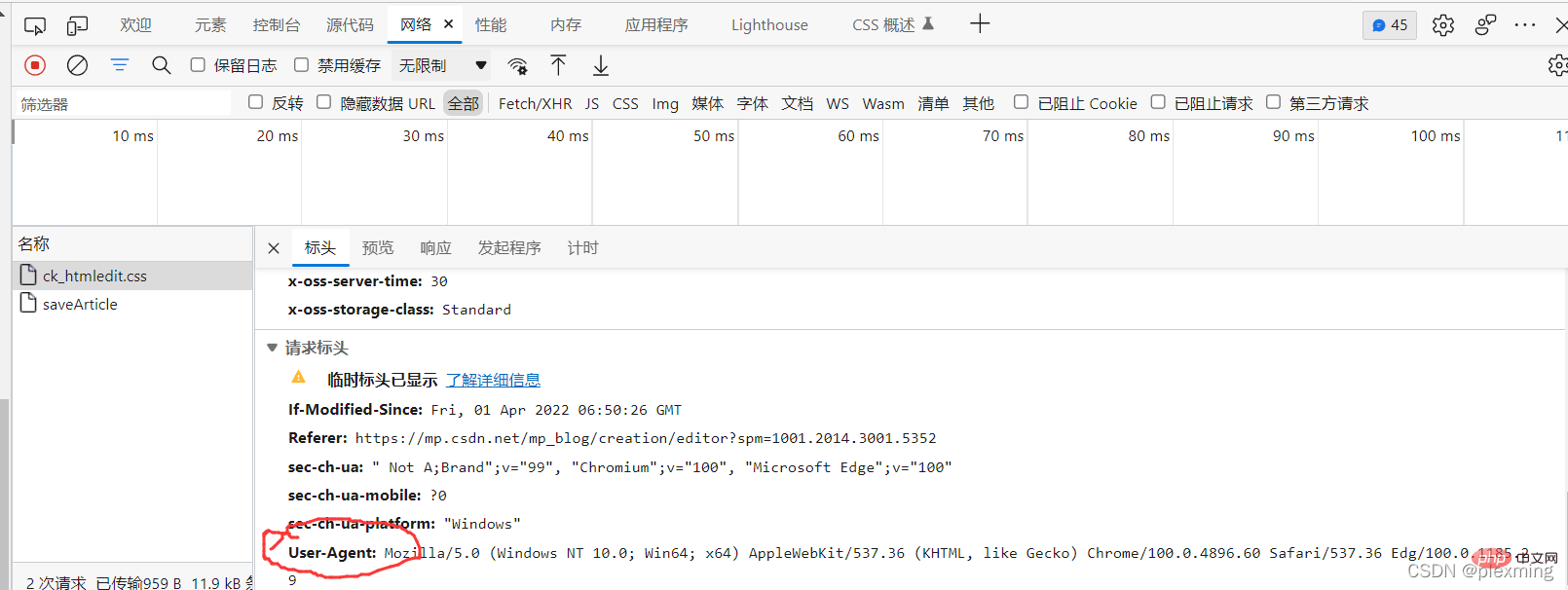
Ensuite, nous devons trouver l'emplacement de l'image que nous voulons explorer dans le code de la page Web. Vérifiez le code source avec f12 et trouvez le package d'émoticônes comme suit :
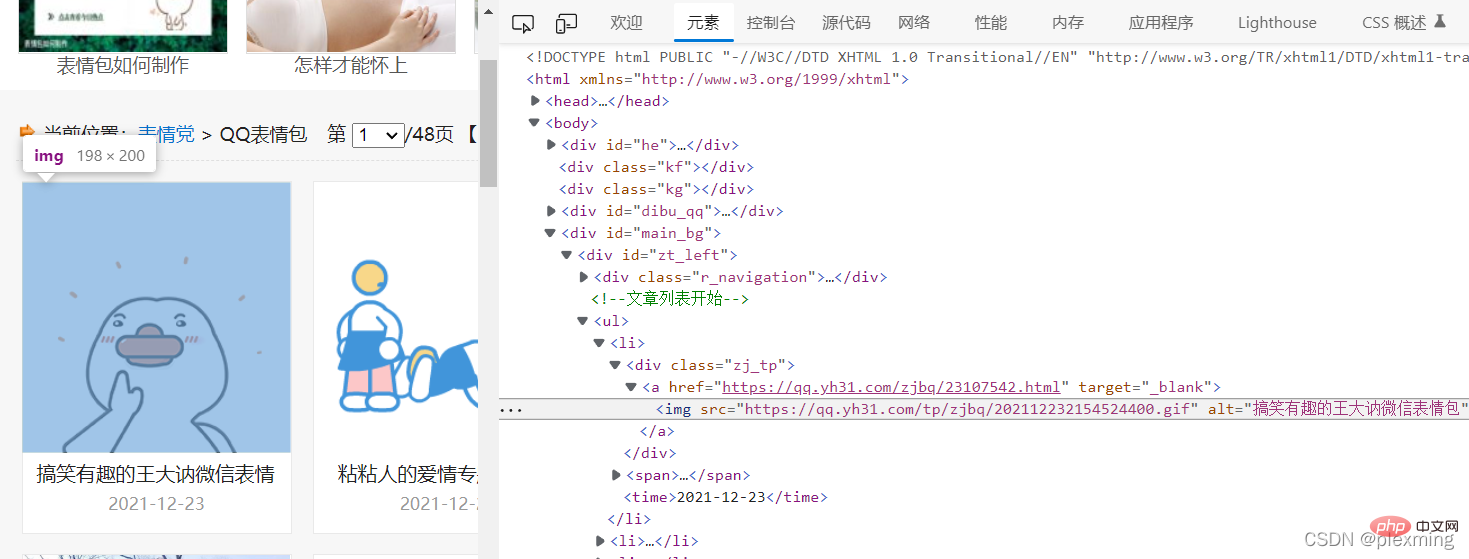
Créez ensuite une règle de correspondance et utilisez des expressions régulières pour faire correspondre la chaîne au milieu. Remplacez-la, la plus simple est .*?
t = '<img src="(.*?)" alt="(.*?)" width="160" height="120">'
comme ça.
Ensuite, vous pouvez appeler la méthode findall dans la bibliothèque re pour parcourir le contenu pertinent :
result = re.findall(t, response.text)
Le contenu renvoyé est une liste composée de chaînes. Enfin, nous téléchargeons l'image et l'enregistrons dans un fichier via l'instruction python via. l'adresse explorée. Mettez-la simplement dans le dossier.
Code du programme
import requests
import re
import os
image = '表情包'
if not os.path.exists(image):
os.mkdir(image)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:98.0) Gecko/20100101 Firefox/98.0'
}
response = requests.get('https://qq.yh31.com/zjbq/',headers=headers)
response.encoding = 'GBK'
response.encoding = 'utf-8'
print(response.request.headers)
print(response.status_code)
t = '<img src="(.*?)" alt="(.*?)" width="160" height="120">'
result = re.findall(t, response.text)
for img in result:
print(img)
res = requests.get(img[0])
print(res.status_code)
s = img[0].split('.')[-1] #截取图片后缀,得到表情包格式,如jpg ,gif
with open(image + '/' + img[1] + '.' + s, mode='wb') as file:
file.write(res.content)
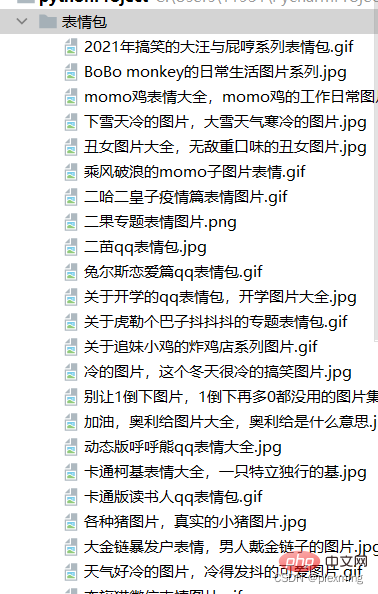
Le résultat final ressemble à ceci :
[Recommandations associées : Tutoriel vidéo Python3 ]
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Parlons des idées de programmation Python
- Python peut-il remplacer JavaScript ?
- Explication détaillée des paramètres de base de matplotlib.pyplot dans le résumé de la visualisation Python
- Compréhension approfondie des règles d'indentation de code en python
- Explication détaillée des exemples de modèles de forêt aléatoire Python