
Maison >base de données >tutoriel mysql >Comment une instruction SQL est-elle exécutée dans MySQL Learning ? Parlons du processus d'exécution
Comment une instruction SQL est-elle exécutée dans MySQL Learning ? Parlons du processus d'exécution

- 青灯夜游avant
- 2022-06-30 11:17:152324parcourir
Comment un SQL est-il exécuté dans MySQL ? L'article suivant parlera d'un processus d'exécution SQL pour vous. J'espère qu'il vous sera utile !
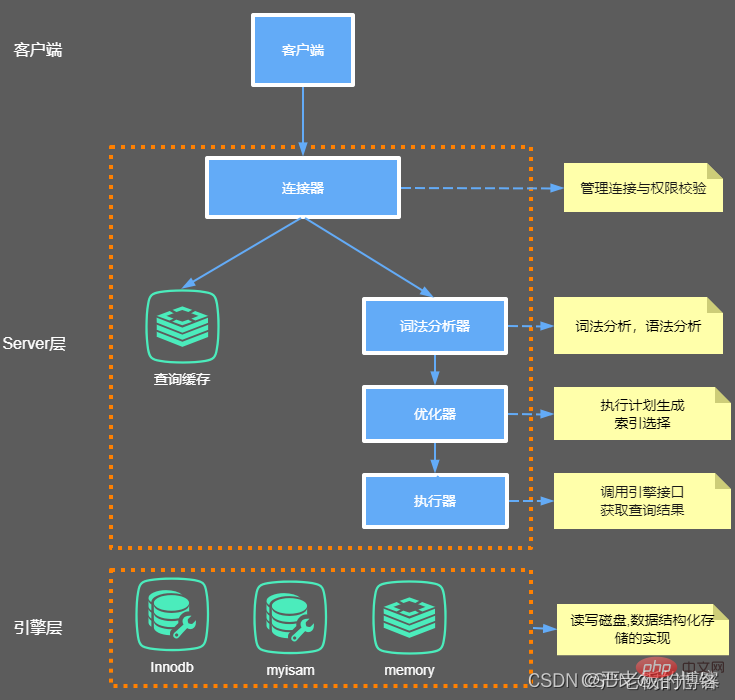
En gros, MySQL peut être divisé en deux parties : la couche serveur et la couche moteur de stockage.
Couche serveur
Comprend principalement des connecteurs, des caches de requêtes, des analyseurs, des optimiseurs, des exécuteurs, etc., couvrant la plupart des fonctions de base du service MySQL, ainsi que toutes les fonctions intégrées (telles que la date, l'heure, les mathématiques et le cryptage fonctions, etc.), toutes les fonctions du moteur de stockage croisé sont implémentées dans cette couche, telles que les procédures stockées, les déclencheurs, les vues, etc.
Couche magasin
La couche moteur de stockage est responsable du stockage et de la récupération des données. Son modèle architectural est plug-in et prend en charge plusieurs moteurs de stockage tels que InnoDB, MyISAM et Memory. Le moteur de stockage le plus couramment utilisé est désormais InnoDB, qui est devenu le moteur de stockage par défaut depuis MySQL 5.5.5. C'est-à-dire que si nous ne précisons pas le type de moteur de stockage de la table lors de la création de la table, le moteur de stockage sera défini par défaut sur InnoDB.
Cette leçon démontre le DDL de la table :
CREATE TABLE `test` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8;
Concentrons-nous sur l'analyse de ce que font respectivement le connecteur, le cache de requêtes, l'analyseur, l'optimiseur et l'exécuteur.
1. Connecteur
Nous savons que MySQL étant open source, il possède de nombreux types de clients : navicat, mysql front, jdbc, SQLyog et d'autres clients très riches, ces clients doivent être connectés à mysql. Pour lancer la communication, vous devez d'abord établir une connexion de communication avec le serveur, et le travail d'établissement de la connexion est complété par le connecteur.
Dans un premier temps, vous vous connecterez d'abord à cette base de données, et le connecteur sera là pour vous recevoir. Le connecteur est chargé d'établir une connexion avec le client, d'obtenir les autorisations, de maintenir et de gérer la connexion. La commande de connexion s'écrit généralement ainsi :
[root@192 ~]# mysql ‐h host[数据库地址] ‐u root[用户] ‐p root[密码] ‐P 3306
Le mysql dans la commande de connexion est un outil client utilisé pour établir une connexion avec le serveur. Après avoir terminé la négociation TCP classique, le connecteur commencera à authentifier votre identité. Cette fois, le nom d'utilisateur et le mot de passe que vous avez saisis seront utilisés.
1. Si le nom d'utilisateur ou le mot de passe est incorrect, vous recevrez une erreur « Accès refusé pour l'utilisateur », puis le programme client mettra fin à son exécution.
2. Si l'authentification du nom d'utilisateur et du mot de passe est réussie, le connecteur vérifiera le tableau des autorisations dont vous disposez. Après cela, la logique de jugement des autorisations à cet égard dépendra des autorisations lues à ce moment-là.
Cela signifie qu'une fois qu'un utilisateur a réussi à établir une connexion, même si vous utilisez le compte administrateur pour modifier les autorisations de l'utilisateur, cela n'affectera pas les autorisations de la connexion existante. Une fois la modification terminée, seules les nouvelles connexions utiliseront les nouveaux paramètres d'autorisation. La table des autorisations de l'utilisateur se trouve dans la table utilisateur de MySQL dans l'espace table système.

Modifier le mot de passe utilisateur
mysql> CREATE USER 'username'@'host' IDENTIFIED BY 'password'; //创建新用户 mysql> grant all privileges on *.* to 'username'@'%'; //赋权限,%表示所有(host) mysql> flush privileges //刷新数据库 mysql> update user set password=password(”123456″) where user=’root’;(设置用户名密码) mysql> show grants for root@"%"; 查看当前用户的权限
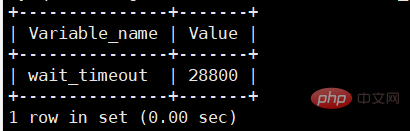
Une fois la connexion terminée, si vous n'avez aucune action ultérieure, la connexion sera dans un état inactif. Vous pouvez le voir dans la commande show processlist. L'image dans le texte est le résultat de show processlist. La colonne Commande affiche la ligne "Veille", ce qui signifie qu'il y a une connexion inactive dans le système.

Si le client n'envoie pas de commande au serveur pendant une longue période, le connecteur le déconnectera automatiquement. Ce temps est contrôlé par le paramètre wait_timeout et la valeur par défaut est de 8 heures. Vérifiez wait_timeout
mysql> show global variables like "wait_timeout"; mysql>set global wait_timeout=28800; 设置全局服务器关闭非交互连接之前等待活动的秒数
Si le client envoie à nouveau une requête après la déconnexion de la connexion, il recevra un rappel d'erreur : connexion perdue au serveur MySQL pendant la requête. Si vous souhaitez continuer à ce moment-là, vous devez vous reconnecter puis exécuter la requête.
Dans la base de données, une connexion longue signifie qu'une fois la connexion réussie, si le client continue de faire des requêtes, la même connexion sera toujours utilisée. Une connexion courte signifie que la connexion est déconnectée après l'exécution de quelques requêtes et rétablie pour la requête suivante. La plupart du temps lors du développement, nous utilisons des connexions longues et gérons les connexions dans le Pool. Cependant, les connexions longues entraînent parfois une augmentation très rapide de la mémoire occupée par MySQL. Ceci est dû au fait que la mémoire temporairement utilisée par MySQL lors de l'exécution est gérée dans le Pool. objet de connexion. Ces ressources seront libérées lorsque la connexion sera déconnectée. Par conséquent, si de longues connexions s'accumulent, elles peuvent occuper trop de mémoire et être interrompues de force par le système (MOO). À en juger par le phénomène, MySQL redémarre anormalement. Comment résoudre ce genre de problème ?
1. Débranchez régulièrement les longues connexions. Après l'avoir utilisé pendant un certain temps, ou après que le programme a déterminé qu'une requête volumineuse occupant de la mémoire a été exécutée, la connexion est déconnectée, puis la requête est requise puis reconnectée.
2、如果你用的是 MySQL 5.7 或更新版本,可以在每次执行一个比较大的操作后,通过执行 mysql_reset_connection 来重新初始化连接资 源。这个过程不需要重连和重新做权限验证,但是会将连接恢复到刚刚创建完时的状态。
2、查询缓存
常用的一些操作
mysql>show databases; 显示所有数据库 mysql>use dbname; 打开数据库: mysql>show tables; 显示数据库mysql中所有的表; mysql>describe user; 显示表mysql数据库中user表的列信息);
连接建立完成后,你就可以执行 select 语句了。执行逻辑就会来到第二步:查询缓存。 MySQL 拿到一个查询请求后,会先到查询缓存看看,之前是不是执行过这条语句。之前执行过的语句及其结果可能会以 key-value 对的形式,被直接缓存在内存中。key 是查询的语句,value 是查询的结果。如果你的查询能够直接在这个缓存中找 到 key,那么这个 value 就会被直接返回给客户端。
如果语句不在查询缓存中,就会继续后面的执行阶段。执行完成后,执行结果会被存入查询缓存中。你可以看到,如果查 询命中缓存,MySQL 不需要执行后面的复杂操作,就可以直接返回结果,这个效率会很高。
大多数情况查询缓存就是个鸡肋,为什么呢?
因为查询缓存往往弊大于利。查询缓存的失效非常频繁,只要有对一个表的更新,这个表上所有的查询缓存都会被清空。 因此很可能你费劲地把结果存起来,还没使用呢,就被一个更新全清空了。对于更新压力大的数据库来说,查询缓存的命中率 会非常低。
一般建议大家在静态表里使用查询缓存,什么叫静态表呢?就是一般我们极少更新的表。比如,一个系统配置表、字典 表,那这张表上的查询才适合使用查询缓存。好在 MySQL 也提供了这种“按需使用”的方式。你可以将my.cnf参数 query_cache_type 设置成 DEMAND。
my.cnf #query_cache_type有3个值 0代表关闭查询缓存OFF,1代表开启ON,2(DEMAND)代表当sql语句中有SQL_CACHE 关键词时才缓存 query_cache_type=2
这样对于默认的 SQL 语句都不使用查询缓存。而对于你确定要使用查询缓存的语句,可以用 SQL_CACHE 显式指定,像下 面这个语句一样:
mysql> select SQL_CACHE * from test where ID=5;
查看当前mysql实例是否开启缓存机制
mysql> show global variables like "%query_cache_type%";
监控查询缓存的命中率:
mysql> show status like'%Qcache%'; //查看运行的缓存信息
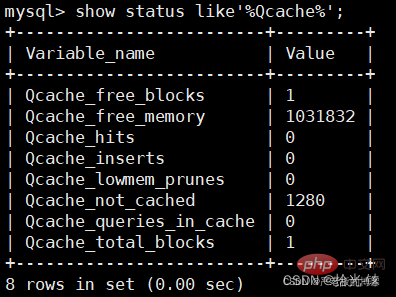
- Qcache_free_blocks:表示查询缓存中目前还有多少剩余的blocks,如果该值显示较大,则说明查询缓存中的内存碎片过多了,可能在一定的时间进行整理。
- Qcache_free_memory:查询缓存的内存大小,通过这个参数可以很清晰的知道当前系统的查询内存是否够用,是多了,还是不够用,DBA可以根据实际情况做出调整。
- Qcache_hits:表示有多少次命中缓存。我们主要可以通过该值来验证我们的查询缓存的效果。数字越大,缓存效果越 理想。
- Qcache_inserts: 表示多少次未命中然后插入,意思是新来的SQL请求在缓存中未找到,不得不执行查询处理,执行查询处理后把结果insert到查询缓存中。这样的情况的次数,次数越多,表示查询缓存应用到的比较少,效果也就不理想。当然系统刚启动后,查询缓存是空的,这很正常。
- Qcache_lowmem_prunes:该参数记录有多少条查询因为内存不足而被移除出查询缓存。通过这个值,用户可以适当的 调整缓存大小。
- Qcache_not_cached: 表示因为query_cache_type的设置而没有被缓存的查询数量。
- Qcache_queries_in_cache:当前缓存中缓存的查询数量。
- Qcache_total_blocks:当前缓存的block数量。
mysql8.0已经移除了查询缓存功能
3、分析器
如果没有命中查询缓存,就要开始真正执行语句了。首先,MySQL 需要知道你要做什么,因此需要对 SQL 语句做解析。 分析器先会做“词法分析”。你输入的是由多个字符串和空格组成的一条 SQL 语句,MySQL 需要识别出里面的字符串分别是 什么,代表什么。 MySQL 从你输入的"select"这个关键字识别出来,这是一个查询语句。它也要把字符串“T”识别成“表名 T”,把字符 串“ID”识别成“列 ID”。 做完了这些识别以后,就要做“语法分析”。根据词法分析的结果,语法分析器会根据语法规则,判断你输入的这个 SQL 语句 是否满足 MySQL 语法。 如果你的语句不对,就会收到“You have an error in your SQL syntax”的错误提醒,比如下面这个语句 from 写成了 “fro”。
mysql> select * fro test where id=1; ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds t o your MySQL server version for the right syntax to use near 'fro test where id=1' at line 1
词法分析器原理
词法分析器分成6个主要步骤完成对sql语句的分析
1、词法分析 2、语法分析 3、语义分析 4、构造执行树 5、生成执行计划 6、计划的执行
下图是SQL词法分析的过程步骤: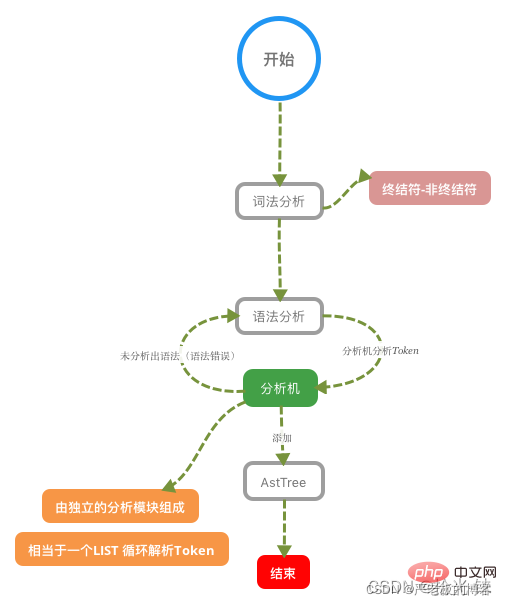
SQL语句的分析分为词法分析与语法分析,mysql的词法分析由MySQLLex[MySQL自己实现的]完成,语法分析由Bison生 成。关于语法树大家如果想要深入研究可以参考这篇wiki文章:https://en.wikipedia.org/wiki/LR_parser。那么除了Bison 外,Java当中也有开源的词法结构分析工具例如Antlr4,ANTLR从语法生成一个解析器,可以构建和遍历解析树,可以在IDEA 工具当中安装插件:antlr v4 grammar plugin。插件使用详见课程 经过bison语法分析之后,会生成一个这样的语法树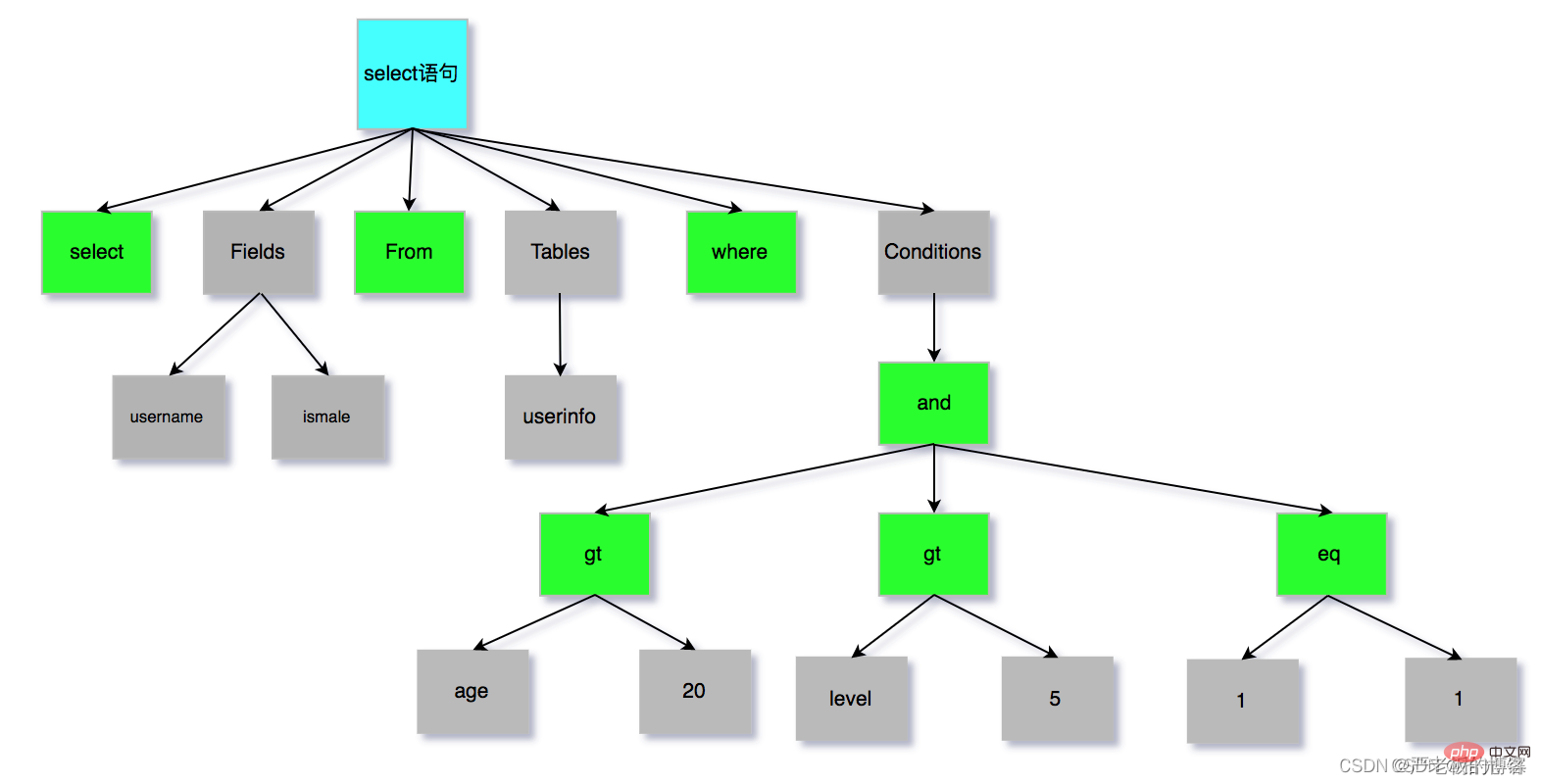
我们分析器的工作任务也基本圆满了。接下来进入到优化器
4、优化器
经过了分析器,MySQL 就知道你要做什么了。在开始执行之前,还要先经过优化器的处理。 优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接 顺序。比如你执行下面这样的语句,这个语句是执行两个表的 join:
mysql> select * from test1 join test2 using(ID) where test1.name=yangguo and test2.name=xiaol ongnv;
既可以先从表 test1 里面取出 name=yangguo的记录的 ID 值,再根据 ID 值关联到表 test2,再判断 test2 里面 name的 值是否等于 yangguo。
也可以先从表 test2 里面取出 name=xiaolongnv 的记录的 ID 值,再根据 ID 值关联到 test1,再判断 test1 里面 name 的值是否等于 yangguo。
这两种执行方法的逻辑结果是一样的,但是执行的效率会有不同,而优化器的作用就是决定选择使用哪一个方案。优化器阶段 完成后,这个语句的执行方案就确定下来了,然后进入执行器阶段。如果你还有一些疑问,比如优化器是怎么选择索引的,有 没有可能选择错等等。
5、执行器
开始执行的时候,要先判断一下你对这个表 T 有没有执行查询的权限,如果没有,就会返回没有权限的错误,如下所示 (在工程实现上,如果命中查询缓存,会在查询缓存返回结果的时候,做权限验证。查询也会在优化器之前调用 precheck 验证权限)。
mysql> select * from test where id=1;
如果有权限,就打开表继续执行。打开表的时候,执行器就会根据表的引擎定义,去使用这个引擎提供的接口。 比如我们这个例子中的表 test 中,ID 字段没有索引,那么执行器的执行流程是这样的:
调用 InnoDB 引擎接口取这个表的第一行,判断 ID 值是不是 10,如果不是则跳过,如果是则将这行存在结果集中;
调用引擎接口取“下一行”,重复相同的判断逻辑,直到取到这个表的最后一行。
执行器将上述遍历过程中所有满足条件的行组成的记录集作为结果集返回给客户端。
至此,这个语句就执行完成了。对于有索引的表,执行的逻辑也差不多。第一次调用的是“取满足条件的第一行”这个接口,之后循环取“满足条件的下一行”这个接口,这些接口都是引擎中已经定义好的。你会在数据库的慢查询日志中看到一个 rows_examined 的字段,表示这个语句执行过程中扫描了多少行。这个值就是在执行器每次调用引擎获取数据行的时候累加的。在有些场景下,执行器调用一次,在引擎内部则扫描了多行,因此引擎扫描行数跟 rows_examined 并不是完全相同的。
6、bin-log归档
删库是不需要跑路的,因为我们的SQL执行时,会将sql语句的执行逻辑记录在我们的bin-log当中,什么是bin-log呢? binlog是Server层实现的二进制日志,他会记录我们的cud操作。Binlog有以下几个特点:
1、Binlog在MySQL的Server层实现(引擎共用) 2、Binlog为逻辑日志,记录的是一条语句的原始逻辑 3、Binlog不限大小,追加写入,不会覆盖以前的日志
如果,我们误删了数据库,可以使用binlog进行归档!要使用binlog归档,首先我们得记录binlog,因此需要先开启MySQL的 binlog功能。 配置my.cnf
配置开启binlog
log‐bin=/usr/local/mysql/data/binlog/mysql‐bin
注意5.7以及更高版本需要配置本项:server‐id=123454(自定义,保证唯一性);
#binlog格式,有3种statement(记录产生结果的过程的sql语句),row(记录产生的结果),mixed binlog‐format=ROW #表示每1次执行写入就与硬盘同步,会影响性能,为0时表示,事务提交时mysql不做刷盘操作,由系统决定 sync‐binlog=1
binlog命令
mysql> show variables like '%log_bin%'; 查看bin‐log是否开启 mysql> flush logs; 会多一个最新的bin‐log日志 mysql> show master status; 查看最后一个bin‐log日志的相关信息 mysql> reset master; 清空所有的bin‐log日志
查看binlog内容
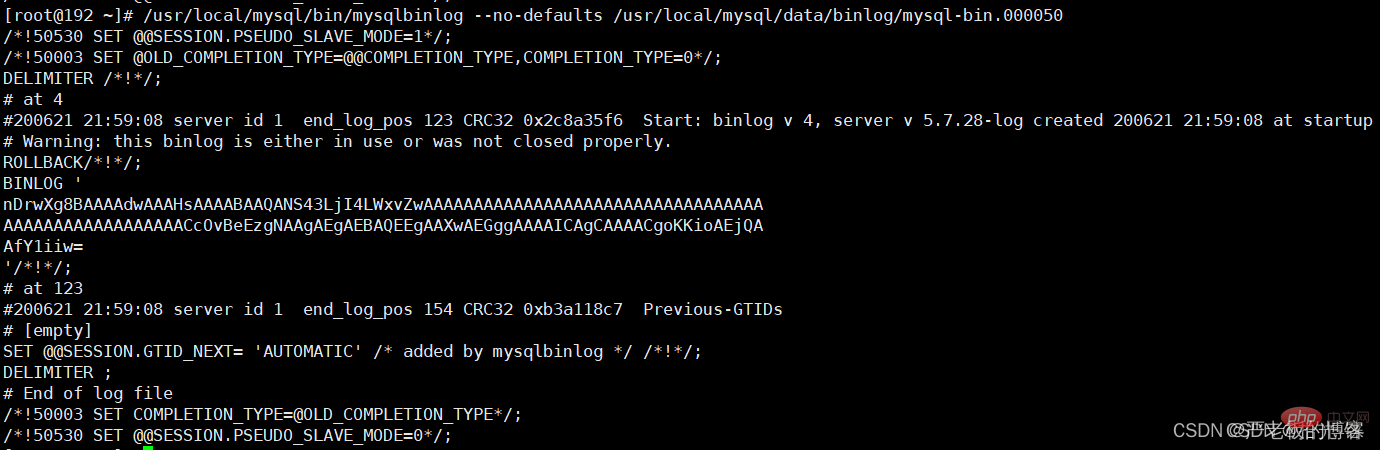
mysql> /usr/local/mysql/bin/mysqlbinlog ‐‐no‐defaults /usr/local/mysql/data/binlog/mysql‐bin. 000001 查看binlog内容
binlog里的内容不具备可读性,所以需要我们自己去判断恢复的逻辑点位,怎么观察呢?看重点信息,比如begin,commit这种 关键词信息,只要在binlog当中看到了,你就可以理解为begin-commit之间的信息是一个完整的事务逻辑,然后再根据位置 position判断恢复即可。
binlog内容如下:
数据归档操作:
从bin‐log恢复数据 恢复全部数据 /usr/local/mysql/bin/mysqlbinlog ‐‐no‐defaults /usr/local/mysql/data/binlog/mysql‐bin.000001 |mysql ‐uroot ‐p tuling(数据库名) 恢复指定位置数据 /usr/local/mysql/bin/mysqlbinlog ‐‐no‐defaults ‐‐start‐position="408" ‐‐stop‐position="731" /usr/local/mysql/data/binlog/mysql‐bin.000001 |mysql ‐uroot ‐p tuling(数据库) 恢复指定时间段数据 /usr/local/mysql/bin/mysqlbinlog ‐‐no‐defaults /usr/local/mysql/data/binlog/mysql‐bin.000001 ‐‐stop‐date= "2018‐03‐02 12:00:00" ‐‐start‐date= "2019‐03‐02 11:55:00"|mysql ‐uroot ‐p test(数据库)
归档测试准
1、定义一个存储过程,写入数据
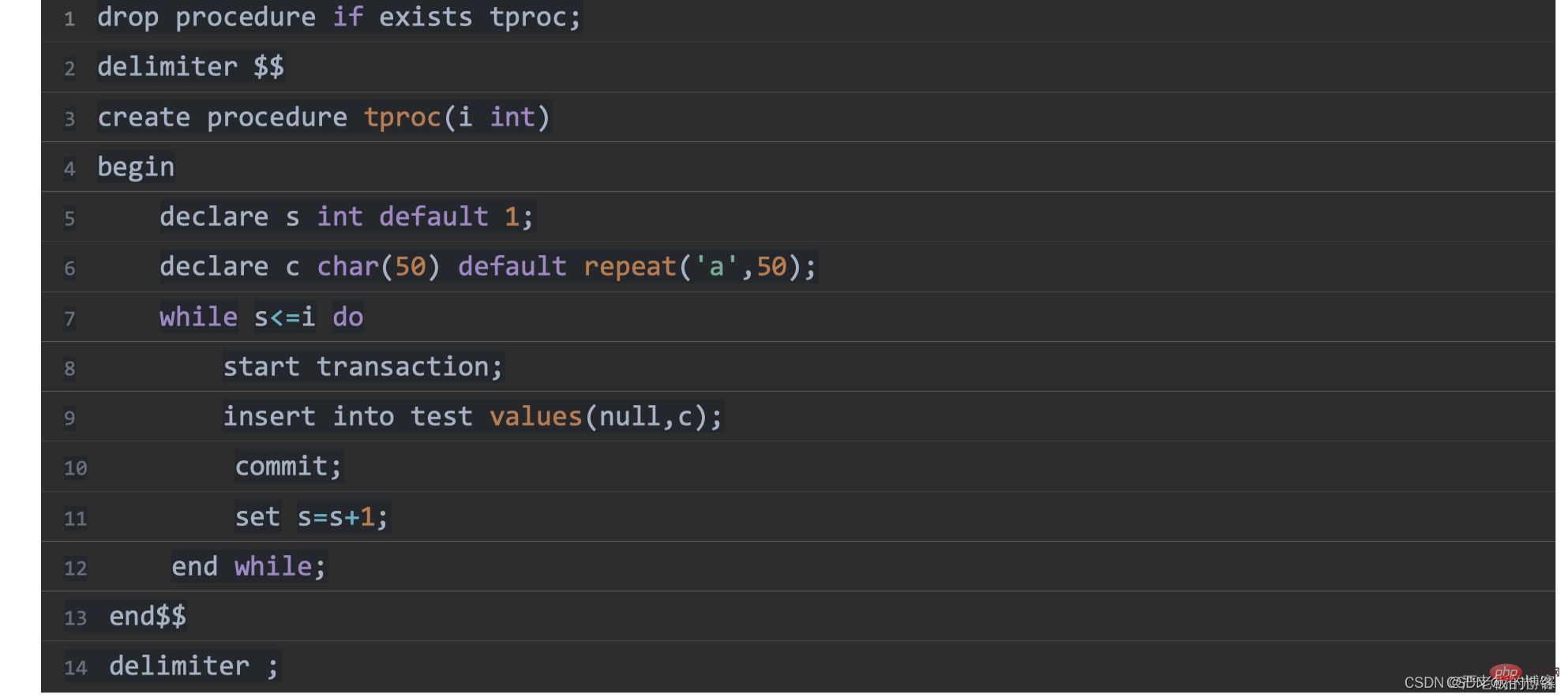
2、删除数据
mysql> truncate test;
3、利用binlog归档
mysql> /usr/local/mysql/bin/mysqlbinlog ‐‐no‐defaults /usr/local/mysql/data/binlog/mysqlbin.000001 |mysql ‐uroot ‐p tuling(数据库名)
4、归档完毕,数据恢复
【相关推荐:mysql视频教程】
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment faire bon usage des index MySQL ? Vous devez savoir ces choses !
- Gestion des logs MySQL (partage de résumé)
- 66 questions d'entretien pour vous aider à trier les points de connaissances MySQL !
- Apprenez-en plus sur les verrous dans Mysql et discutez des scénarios d'utilisation !
- Maîtrisez complètement la solution au délai maître-esclave MySQL