
Maison >base de données >tutoriel mysql >Comment optimiser la requête de pagination MySQL
Comment optimiser la requête de pagination MySQL

- 青灯夜游original
- 2022-06-20 13:09:103694parcourir
Méthodes d'optimisation pour les requêtes de pagination : 1. L'optimisation des sous-requêtes et l'amélioration des performances peuvent être obtenues en réécrivant les instructions SQL de pagination en sous-requêtes. 2. Optimisation de la limitation des identifiants, vous pouvez calculer la plage des identifiants interrogés en fonction du nombre de pages interrogées et du nombre d'enregistrements interrogés, puis interroger en fonction de l'instruction « id entre et ». 3. Optimisez en fonction de la réorganisation de l'index, recherchez les adresses de données pertinentes via l'index et évitez les analyses de table complètes. 4. Pour une optimisation d'association retardée, vous pouvez utiliser JOIN pour terminer d'abord l'opération de pagination sur la colonne d'index, puis revenir à la table pour obtenir les colonnes requises.

L'environnement d'exploitation de ce tutoriel : système windows7, version mysql8, ordinateur Dell G3.
L'efficacité des requêtes de pagination est particulièrement importante lorsque la quantité de données est importante, affectant la réponse frontale et l'expérience utilisateur.
Méthode d'optimisation de la requête de pagination
1. Utilisez l'optimisation de sous-requête
Cette méthode localise d'abord l'identifiant à la position de décalage, puis interroge vers l'arrière. Cette méthode convient au cas où l'identifiant est. croissant.
Principe d'optimisation des sous-requêtes : https://www.jianshu.com/p/0768ebc4e28d
select * from sbtest1 where k=504878 limit 100000,5;Processus de requête :
Tout d'abord, les données du nœud feuille d'index seront interrogées, puis regroupées en fonction de la valeur de clé primaire sur la feuille node Toutes les valeurs de champ requises pour l'interrogation sur l'index. Comme le montre le côté gauche de la figure ci-dessous, vous devez interroger le nœud d'index 100 005 fois, interroger les données d'index clusterisé 100 005 fois, et enfin filtrer les résultats des 100 000 premiers éléments et supprimer les 5 derniers éléments. MySQL dépense beaucoup d'E/S aléatoires pour interroger des données dans l'index clusterisé, et les données interrogées par 100 000 E/S aléatoires n'apparaîtront pas dans l'ensemble de résultats.
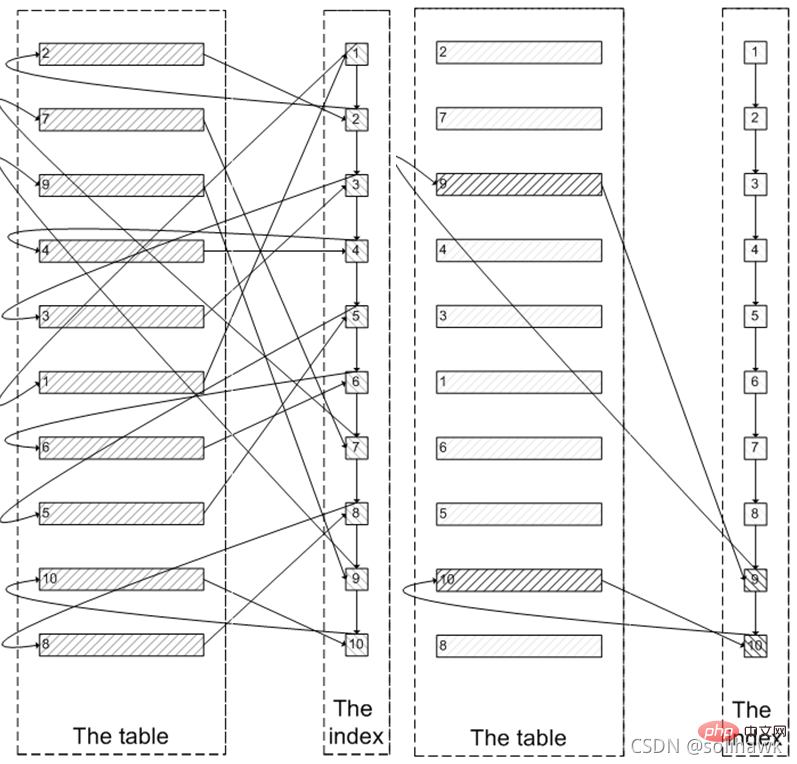
Puisque l'index est utilisé au début, pourquoi ne pas d'abord interroger les nœuds feuilles de l'index jusqu'aux 5 derniers nœuds nécessaires, puis interroger les données réelles dans l'index clusterisé. Cela ne nécessite que 5 E/S aléatoires, similaire au processus sur le côté droit de l'image ci-dessus. Il s'agit d'une optimisation de sous-requête. Cette méthode localise d'abord l'identifiant à la position de décalage, puis interroge plus tard. Cette méthode convient aux situations où l'identifiant augmente. Comme indiqué ci-dessous :
mysql> select * from sbtest1 where k=5020952 limit 50,1; mysql> select id from sbtest1 where k=5020952 limit 50,1; mysql> select * from sbtest1 where k=5020952 and id>=( select id from sbtest1 where k=5020952 limit 50,1) limit 10; mysql> select * from sbtest1 where k=5020952 limit 50,10;
Dans l'optimisation des sous-requêtes, le fait que k dans le prédicat ait un index a un grand impact sur l'efficacité de la requête. L'instruction ci-dessus n'utilise pas l'index et une analyse complète de la table prend 24,2 secondes, mais après avoir utilisé l'index. , cela ne prend que 0,67 seconde.
mysql> explain select * from sbtest1 where k=5020952 and id>=( select id from sbtest1 where k=5020952 limit 50,1) limit 10; +----+-------------+---------+------------+-------------+---------------+------------+---------+-------+------+----------+------------------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+-------------+---------------+------------+---------+-------+------+----------+------------------------------------------+ | 1 | PRIMARY | sbtest1 | NULL | index_merge | PRIMARY,c1 | c1,PRIMARY | 8,4 | NULL | 19 | 100.00 | Using intersect(c1,PRIMARY); Using where | | 2 | SUBQUERY | sbtest1 | NULL | ref | c1 | c1 | 4 | const | 88 | 100.00 | Using index | +----+-------------+---------+------------+-------------+---------------+------------+---------+-------+------+----------+------------------------------------------+ 2 rows in set, 1 warning (0.11 sec)
Mais cette méthode d'optimisation a aussi des limites :
Cette façon d'écrire nécessite que l'ID de clé primaire soit continu
La clause Where ne permet pas d'ajouter d'autres conditions
2. Optimisation de la qualification
Cette méthode suppose que l'identifiant de la table de données augmente continuellement. Nous pouvons ensuite calculer la plage de l'identifiant interrogé en fonction du nombre de pages interrogées et du nombre d'enregistrements interrogés. Vous pouvez utiliser l'identifiant entre et vers. requête.
En supposant que l'identifiant de la table dans la base de données augmente continuellement, la plage de l'identifiant interrogé peut être calculée en fonction du nombre de pages interrogées et du nombre d'enregistrements interrogés, puis interrogée en fonction de l'identifiant entre et de l'instruction. La plage d'identifiant peut être calculée via la formule de pagination. Par exemple, si la taille de la page actuelle est m et le numéro de page actuel est no1, alors la valeur maximale de la page est max=(no1+1)m-1, et la valeur minimale est min=no1m. Les instructions SQL peuvent être exprimées sous la forme d'un identifiant compris entre min et max.
select * from sbtest1 where id between 1000000 and 1000100 limit 100;
Cette méthode de requête peut considérablement optimiser la vitesse de requête et peut essentiellement être complétée en quelques dizaines de millisecondes. La limitation est que vous devez connaître clairement l'identifiant, mais généralement dans la table métier de la requête de pagination, le champ id de base sera ajouté, ce qui apporte beaucoup de commodité à la requête de pagination. Il existe une autre façon d'écrire le SQL ci-dessus :
select * from sbtest1 where id >= 1000001 limit 100;
Vous pouvez voir la différence de temps d'exécution :
mysql> show profiles; +----------+------------+--------------------------------------------------------------------------------------------------------------+ | Query_ID | Duration | Query | +----------+------------+--------------------------------------------------------------------------------------------------------------+ | 6 | 0.00085500 | select * from sbtest1 where id between 1000000 and 1000100 limit 100 | | 7 | 0.12927975 | select * from sbtest1 where id >= 1000001 limit 100 | +----------+------------+--------------------------------------------------------------------------------------------------------------+
Vous pouvez également utiliser la méthode in pour interroger. Cette méthode est souvent utilisée pour interroger lorsque plusieurs tables sont associées. ID de requête de table défini sur query :
select * from sbtest1 where id in (select id from sbtest2 where k=504878) limit 100;
Lors de l'utilisation d'une requête in, veuillez noter que certaines versions de MySQL ne prennent pas en charge l'utilisation de limit dans la clause in.
3. Optimisation basée sur la réorganisation de l'index
La réorganisation basée sur l'index utilise l'algorithme d'optimisation dans la requête d'index pour trouver l'adresse de données pertinente via l'index afin d'éviter une analyse complète de la table, ce qui permet de gagner beaucoup de temps. De plus, Mysql dispose également d'un cache d'index associé, et il sera préférable d'utiliser le cache lorsque la concurrence est élevée. Vous pouvez utiliser l'instruction suivante dans MySQL :
SELECT * FROM 表名称 WHERE id_pk > (pageNum*10) ORDER BY id_pk ASC LIMIT M
Cette méthode convient aux situations où la quantité de données est importante (des dizaines de milliers de tuples). Il est préférable que l'objet colonne après ORDER BY soit la clé primaire ou l'index unique. , de sorte que l'opération ORDER BY puisse utiliser l'index est éliminée mais le jeu de résultats est stable. Par exemple, les deux instructions suivantes :
mysql> show profiles; +----------+------------+--------------------------------------------------------------------------------------------------------------+ | Query_ID | Duration | Query | +----------+------------+--------------------------------------------------------------------------------------------------------------+ | 8 | 3.30585150 | select * from sbtest1 limit 1000000,10 | | 9 | 1.03224725 | select * from sbtest1 order by id limit 1000000,10 | +----------+------------+--------------------------------------------------------------------------------------------------------------+
Après avoir utilisé l'instruction order by pour l'identifiant du champ d'index, les performances ont été considérablement améliorées.
4. Utilisez l'association retardée pour optimiser
Semblable à la méthode de sous-requête ci-dessus, nous pouvons utiliser JOIN pour terminer d'abord l'opération de pagination sur la colonne d'index, puis revenir à la table pour obtenir les colonnes requises.
select a.* from t5 a inner join (select id from t5 order by text limit 1000000, 10) b on a.id=b.id;

从实验中可以得出,在采用JOIN改写后,上面的两个局限性都已经解除了,而且SQL的执行效率也没有损失。
5、记录上次查询结束的位置
和上面使用的方法都不同,记录上次结束位置优化思路是使用某种变量记录上一次数据的位置,下次分页时直接从这个变量的位置开始扫描,从而避免MySQL扫描大量的数据再抛弃的操作。
select * from t5 where id>=1000000 limit 10;

6、使用临时表优化
使用临时存储的表来记录分页的id然后进行in查询
这种方式已经不属于查询优化,这儿附带提一下。
对于使用 id 限定优化中的问题,需要 id 是连续递增的,但是在一些场景下,比如使用历史表的时候,或者出现过数据缺失问题时,可以考虑使用临时存储的表来记录分页的id,使用分页的id来进行 in 查询。这样能够极大的提高传统的分页查询速度,尤其是数据量上千万的时候。
【相关推荐:mysql视频教程】
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!