
Maison >base de données >tutoriel mysql >Résumé des solutions au délai maître-esclave MySQL et à la séparation lecture-écriture
Résumé des solutions au délai maître-esclave MySQL et à la séparation lecture-écriture

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-05-26 11:53:521986parcourir
Cet article vous apporte des connaissances pertinentes sur mysql, qui présente principalement les solutions au délai maître-esclave et à la séparation lecture-écriture. Jetons un coup d'œil et résumons plusieurs méthodes, j'espère que cela sera utile à tout le monde.

Apprentissage recommandé : Tutoriel vidéo mysql
Nous savons tous que les données Internet ont une caractéristique, la plupart des scénarios sont lire plus et écrire moins, tels que : Weibo, WeChat, Taobao Business , selon le Vingt-huit principes, le taux de trafic de lecture peut même atteindre 90 %读多写少,比如:微博、微信、淘宝电商,按照 二八原则,读流量占比甚至能达到 90%
结合这个特性,我们对底层的数据库架构也会做相应调整。采用 读写分离
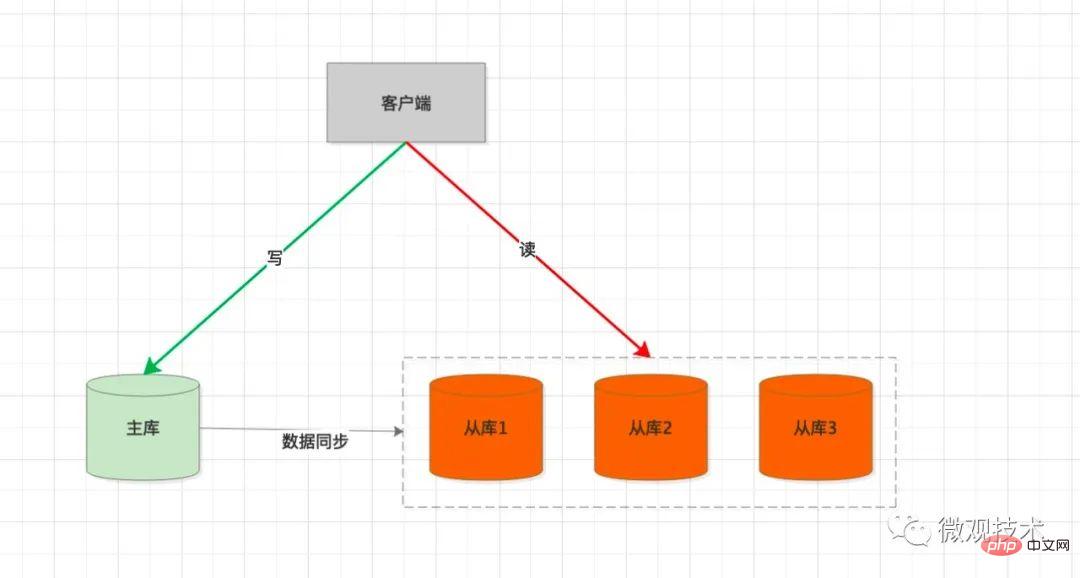
处理过程:
客户端会集成 SDK,每次执行 SQL 时,会判断是
写或读操作如果是
写SQL,请求会发到主库主数据库执行SQL,事务提交后,会生成
binlog,并同步给从库从库通过 SQL 线程回放binlog,并在从库表中生成相应数据如果是
读SQL,请求会通过负载均衡策略,挑选一个从库处理用户请求
看似非常合理,细想却不是那么回事
主库 与 从库 是采用异步复制数据,如果这两者之间数据还没有同步怎么办?
主库刚写完数据,从库还没来得及拉取最新数据,读 请求就来了,给用户的感觉,数据丢了???
针对这个问题,今天,我们就来探讨下有什么解决方案?
一、强制走主库
针对不用的业务诉求,区别性对待
场景一:
如果是对数据的 实时性 要求不是很高,比如:大V有千万粉丝,发布一条微博,粉丝晚几秒钟收到这条信息,并不会有特别大的影响。这时,可以走 从库。
场景二:
如果对数据的 实时性 要求非常高,比如金融类业务。我们可以在客户端代码标记下,让查询强制走主库。
二、从库延迟查询
由于主从库之间数据同步需要一定的时间间隔,那么有一种策略是延迟从从库查询数据。
比如:
select sleep(1) select * from order where order_id=11111;
在正式的业务查询时,先执行一个sleep 语句,给从库预留一定的数据同步缓冲期。
因为是采用一刀切,当面对高并发业务场景时,性能会下降的非常厉害,一般不推荐这个方案。
三、判断主从是否延迟?决定选主库还是从库
方案一:
在从库 执行 命令 show slave status
查看 seconds_behind_master 的值,单位为秒,如果为 0,表示主备库之间无延迟
方案二:
比较主从库的文件点位
还是执行 show slave status,响应结果里有截个关键参数
Master_Log_File 读到的主库最新文件
Read_Master_Log_Pos 读到的主库最新文件的坐标位置
Relay_Master_Log_File 从库执行到的最新文件
Exec_Master_Log_Pos 从库执行到的最新文件的坐标位置
两两比较,上面的参数是否相等
方案三:
比较 GTID 集合
Auto_Position=1 主从之间使用 GTID 协议
Retrieved_Gtid_Set 从库收到的所有binlog日志的 GTID 集合
Executed_Gtid_Set 从库已经执行完成的 GTID 集合
比较 Retrieved_Gtid_Set 和 Executed_Gtid_Set
séparation lecture-écriture

Processus de traitement :
Le client intégrera le SDK, et à chaque fois que SQL est exécuté, il sera jugée comme une opération
écritureoulecture- 🎜S'il s'agit d'une opération
écritureSQL, la requête sera envoyée à labibliothèque principale🎜 - 🎜La base de données maître exécute SQL Une fois la transaction soumise, le
binlogsera généré et synchronisé avec leesclave. library🎜 - 🎜
Bibliothèque esclavelitbinlogvia le thread SQL et génère les données correspondantes dans la table de la bibliothèque esclave🎜 - 🎜S'il s'agit de
lectureSQL, la requête passera par la stratégieLoad Balancing, et unebibliothèque esclavesera sélectionnée pour gérer la demande de l'utilisateur🎜
Bibliothèque principale et . La bibliothèque esclave utilise la réplication asynchrone des données. Que se passe-t-il si les données entre les deux ne sont pas encore synchronisées ? 🎜🎜La bibliothèque principale vient de terminer l'écriture des données, et avant que la bibliothèque esclave n'ait le temps d'extraire les dernières données, la requête read arrive, donnant à l'utilisateur le sentiment que les données sont perdues. ? ? ? 🎜🎜En réponse à ce problème, discutons aujourd'hui des solutions possibles ? 🎜🎜1. Utilisation forcée de la base de données principale🎜🎜Traitez différentes exigences métier pour les exigences métier inutilisées🎜🎜🎜Scénario 1 : 🎜🎜🎜Si les exigences en matière de temps réel ne sont pas très élevées, par exemple comme : le grand V a des dizaines de millions de fans. S'il publie un message sur Weibo et que ses fans reçoivent le message quelques secondes plus tard, cela n'aura pas un impact particulièrement important. À ce stade, vous pouvez accéder à depuis la bibliothèque. 🎜🎜🎜Scénario 2 : 🎜🎜🎜Si les exigences en matière de temps réel pour les données sont très élevées, comme dans le cas des services financiers. Nous pouvons forcer la requête à accéder à la base de données principale sous la balise de code client. 🎜🎜2. Requête retardée de la base de données esclave🎜🎜Étant donné que la synchronisation des données entre les bases de données maître et esclave nécessite un certain intervalle de temps, il existe une stratégie pour retarder l'interrogation des données des bases de données esclaves. 🎜🎜Par exemple : 🎜select master_pos_wait(file, pos[, timeout]);🎜Dans une requête métier formelle, exécutez d'abord une instruction sleep pour réserver une certaine période de tampon de synchronisation des données pour la base de données esclave. 🎜🎜Parce qu'il s'agit d'une solution universelle, face à des scénarios commerciaux à forte concurrence, les performances chuteront considérablement. Cette solution n'est généralement pas recommandée. 🎜🎜3. Déterminer si le maître et l'esclave sont en retard ? Décidez si vous souhaitez choisir la bibliothèque maître ou la bibliothèque esclave🎜🎜🎜Option 1 : 🎜🎜🎜Exécutez la commande
show slave status🎜🎜depuis la bibliothèque esclave pour afficher la valeur de seconds_behind_master code>, l'unité est la seconde, si elle vaut 0, ce qui signifie qu'il n'y a pas de délai entre les bases de données maître et esclave🎜🎜🎜Option 2 : 🎜🎜🎜Comparez les points de fichier des bases de données maître et esclave🎜🎜Ou exécutez <code>afficher l'état de l'esclave, il y a une clé dans le résultat de la réponse Paramètres🎜- 🎜Master_Log_File Le dernier fichier lu depuis la bibliothèque principale🎜
- 🎜Read_Master_Log_Pos La position des coordonnées du dernier fichier lu depuis la bibliothèque principale🎜
- 🎜Relay_Master_Log_File Exécuté depuis la bibliothèque La position des coordonnées du dernier fichier obtenu🎜
- 🎜Exec_Master_Log_Pos exécuté depuis la bibliothèque🎜 ul>🎜Comparez les deux paramètres pour voir si les paramètres ci-dessus sont égaux🎜🎜🎜Option 3 :🎜 🎜🎜Comparez les ensembles GTID🎜
- 🎜Auto_Position=1 Utiliser le protocole GTID entre le maître et l'esclave🎜
- 🎜Retrieved_Gtid_Set Ensemble GTID de tous les journaux binlog reçus de la bibliothèque🎜 🎜Executed_Gtid_Set L'ensemble GTID qui a été exécuté depuis la bibliothèque🎜
Retrieved_Gtid_Set et Executed_Gtid_Set sont égaux🎜🎜Lors de l'exécution de SQL métier Pendant le fonctionnement, déterminez d'abord si la base de données esclave a synchronisé les dernières données. Ceci détermine s’il faut exploiter la base de données maître ou la base de données esclave. 🎜🎜🎜Inconvénients : 🎜🎜🎜Peu importe laquelle des solutions ci-dessus est adoptée, si la bibliothèque principale a des opérations d'écriture fréquentes, la valeur de la bibliothèque esclave ne suivra jamais la valeur de la bibliothèque principale et le trafic de lecture sera frappez toujours la bibliothèque principale. 🎜针对这个问题,有什么解决方案?
这个问题跟 MQ消息队列 既要求高吞吐量又要保证顺序是一样的,从全局来看确实无解,但是缩小范围就容易多了,我们可以保证一个分区内的消息有序。
回到 主从库 之间的数据同步问题,从库查询哪条记录,我们只要保证之前对应的写binglog已经同步完数据即可,可以不用管主从库的所有的事务binlog 是否同步。
问题是不是一下简单多了
四、从库节点判断主库位点
在从库执行下面命令,返回是一个正整数 M,表示从库从参数节点开始执行了多少个事务
select master_pos_wait(file, pos[, timeout]);
file 和 pos 表示主库上的文件名和位置
timeout 可选, 表示这个函数最多等待 N 秒
缺点:
master_pos_wait 返回结果无法与具体操作的数据行做关联,所以每次接收读请求时,从库还是无法确认是否已经同步数据,方案实用性不高。
五、比较 GTID
执行下面查询命令
阻塞等待,直到从库执行的事务中包含 gtid_set,返回 0
超时,返回 1
select wait_for_executed_gtid_set(gtid_set, 1);
MySQL 5.7.6 版本开始,允许在执行完更新类事务后,把这个事务的 GTID 返回给客户端。具体操作,将参数
session_track_gtids设置为OWN_GTID,调用 API 接口mysql_session_track_get_first返回结果解析出 GTID
处理流程:
发起
写SQL 操作,在主库成功执行后,返回这个事务的 GTID发起
读SQL 操作时,先在从库执行select wait_for_executed_gtid_set (gtid_set, 1)如果返回 0,表示已经从库已经同步了数据,可以在从库执行
查询操作否则,在主库执行
查询操作
缺点:
跟上面的 master_pos_wait 类似,如果 写操作 与 读操作 没有上下文关联,那么 GTID 无法传递 。方案实用性不高。
六、引入缓存中间件
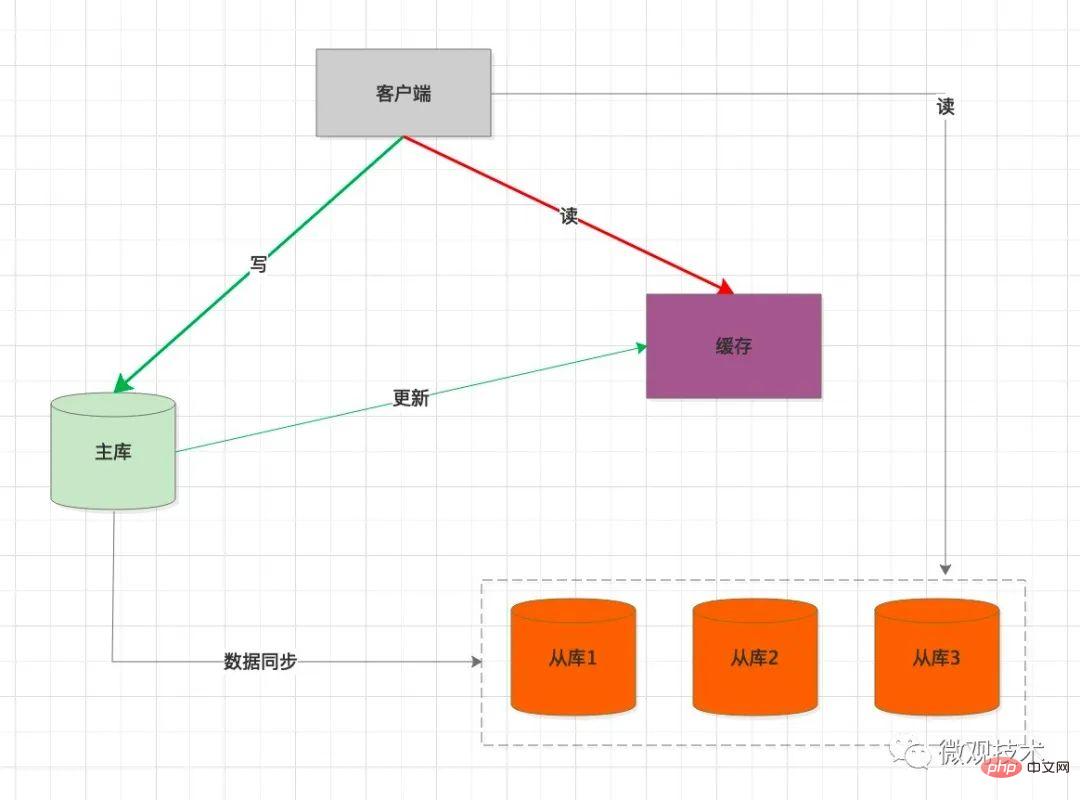
高并发系统,缓存作为性能优化利器,应用广泛。我们可以考虑引入缓存作为缓冲介质
处理过程:
客户端
写SQL ,操作主库同步将缓存中的数据删除
当客户端读数据时,优先从缓存加载
如果 缓存中没有,会强制查询主库预热数据
缺点:
K-V 存储,适用一些简单的查询条件场景。如果复杂的查询,还是要查询从库。
七、数据分片
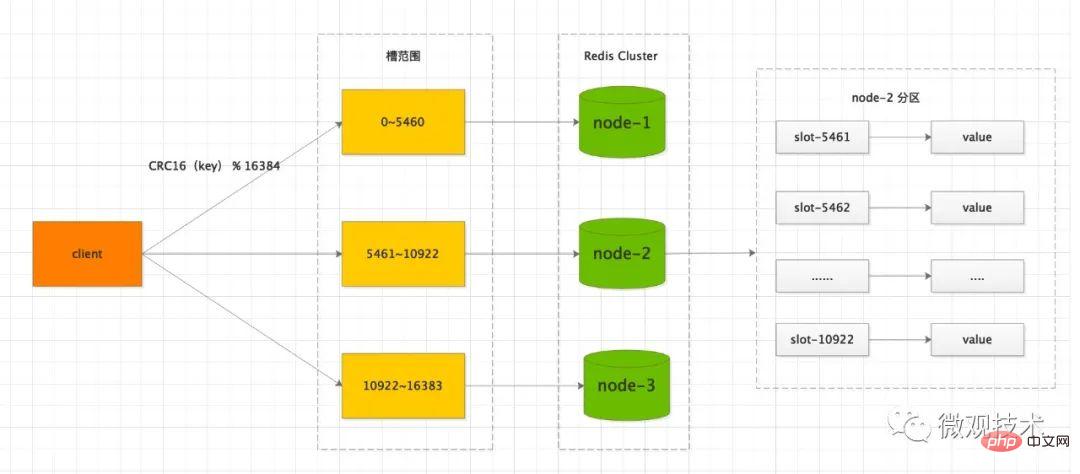
参考 Redis Cluster 模式, 集群网络拓扑通常是 3主 3从,主节点既负责写,也负责读。
通过水平分片,支持数据的横向扩展。由于每个节点都是独立的服务器,可以提高整体集群的吞吐量。
转换到数据库方面
常见的解决方式,是分库分表,每次读写都是操作主库的一个分表,从库只用来做数据备份。当主库发生故障时,主从切换,保证集群的高可用性。
推荐学习:mysql视频教程
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!