
Maison >développement back-end >Tutoriel Python >Analysons comment Python exploite les fichiers XML
Analysons comment Python exploite les fichiers XML

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-05-05 18:55:403542parcourir
Cet article vous apporte des connaissances pertinentes sur python Il présente principalement des problèmes connexes sur la façon dont Python exploite les fichiers XML, y compris un aperçu de base de XML, l'analyse des fichiers XML par Python, l'écriture de fichiers XML, la mise à jour des fichiers XML, etc. au contenu ci-dessous, j’espère que cela sera utile à tout le monde.

Apprentissage recommandé : Tutoriel vidéo Python
1. Présentation des bases de XML
1.
XML (Extensible Markup Language) : langage de balisage extensible. XML est un outil important pour la transmission de données sur Internet. Il peut couvrir n'importe quelle plate-forme sur Internet et n'est pas limité par les langages de programmation. de l'Internet. XML est une technologie très puissante pour traiter actuellement les informations structurées des documents. XML permet de transférer des données structurées entre les serveurs, ce qui permet aux développeurs de contrôler plus facilement le stockage et la transmission des données.
Xml est un langage de balisage utilisé pour marquer les fichiers électroniques afin de les rendre structurels. Il peut être utilisé pour marquer des données et définir des types de données. C'est un langage source qui permet aux utilisateurs de définir leur propre langage de balisage. XML est un sous-ensemble du langage SGML (Standard Generalized Markup Language) et convient parfaitement à la transmission sur le Web. XML fournit un moyen unifié de décrire et d'échanger des données structurées indépendamment des applications ou des fournisseurs.
2. Caractéristiques et fonctions de XML
Caractéristiques :
- xm|Cela n'a rien à voir avec la plate-forme de développement du langage de programmation
- Réalise l'interaction des données entre différents systèmes.
Fonction :
Configuration d'applications et de sites Web ;
interaction avec les données ;
3. Format de fichier XML
- Élément enfant
- Attributs
- Espace de noms
- Nom qualifié
- Semblable au HTML, XML est une autre façon de stocker des données dans un langage de balisage de balises. Il est lisible par l'homme et extensible ; c'est-à-dire que nous sommes libres de définir notre propre balisage. Les attributs, éléments et balises en XML sont similaires à ceux en HTML. Les fichiers XML peuvent contenir ou non des déclarations. Cependant, s'il contient une déclaration, il doit s'agir de la première ligne du fichier XML. Par exemple :
<?xml version="1.0” encoding=' "UTF-8" standalone=" no”?>
Cette déclaration comporte trois parties : version, encodage et indépendance. Version spécifie la version du standard XML utilisé ; Encoding indique le type de codage de caractères utilisé dans ce fichier ; Standalone indique à l'analyseur s'il souhaite que des informations externes interprètent le contenu du fichier XML.
Les fichiers XML peuvent être représentés comme : des arbres XML. Cette arborescence XML commence à partir de l'élément racine (élément parent). Cet élément racine se ramifie ensuite vers des éléments enfants. Chaque élément d'un fichier XML est un nœud dans l'arborescence XML. Les éléments qui n'ont pas de nœuds enfants sont des nœuds feuilles. La figure suivante distingue clairement le fichier XML d'origine et la représentation arborescente du fichier XML :

 2. Python analyse le fichier XML
2. Python analyse le fichier XML  Créez un nouveau fichier
Créez un nouveau fichier
<collection>
<class>
<code>2022001</code>
<number>10</number>
<teacher>小白</teacher>
</class>
<class>
<code>2022002</code>
<number>20</number>
<teacher>小红</teacher>
</class>
<class>
<code>2022003</code>
<number>30</number>
<teacher>小黑</teacher>
</class></collection>
1. Méthode ElementTree 1.xml
Méthodes objets élément :
| Méthode de classe | Description |
|---|---|
Element.iter(tag=None)Element.iter(tag=None)
|
遍历该Element所有后代,也可以指定tag进行遍历寻找。 |
Element.iterfind(path, namespaces=None) |
根据tag或path查找所有的后代。 |
Element.itertext() |
遍历所有后代并返回text值。 |
Element.findall(path) |
查找当前元素下tag或path能够匹配的直系节点 |
Element.findtext(path, default=None, namespaces=None) |
寻找第一个匹配子元素,返回其text值。匹配对象可以为tag或path。 |
Element.find(path) |
查找当前元素下tag或path能够匹配的首个直系节点。 |
Element.text |
获取当前元素的text值。 |
Element.get(key, default=None) |
获取元素指定key对应的属性值,如果没有该属性,则返回default值。 |
Element.keys() |
返回元素属性名称列表 |
Element.items() |
返回(name,value)列表 |
Element.getchildren() |
|
Element.getiterator(tag=None) |
|
Element.getiterator(self, tag=None) |
属性方法:
| 方法名 | 说明 |
|---|---|
Element.tag |
节点名(tag)(str) |
Element.attrib |
属性(attributes)(dict) |
Element.text |
文本(text)(str) |
Element.tail |
附加文本(tail) (str) |
Element[:] | Parcourez tous les descendants de l'élément, ou vous pouvez spécifier une balise à parcourir et à rechercher.
Element.itertext()🎜🎜Parcourt tous les descendants et renvoie la valeur du texte. 🎜🎜🎜🎜Element.findall(path)🎜🎜Trouver des nœuds directs pouvant correspondre à la balise ou au chemin sous l'élément actuel🎜🎜🎜🎜Element.findtext(path, default=Aucun, espaces de noms = Aucun)🎜🎜Trouvez le premier élément enfant correspondant et renvoyez sa valeur texte. L'objet correspondant peut être une balise ou un chemin. 🎜🎜🎜🎜Element.find(path)🎜🎜Trouvez le premier nœud direct auquel la balise ou le chemin sous l'élément actuel peut correspondre. 🎜🎜🎜🎜Element.text🎜🎜Obtenir la valeur texte de l'élément actuel. 🎜🎜🎜🎜Element.get(key, default=None)🎜🎜Obtenir la valeur d'attribut correspondant à la clé spécifiée de l'élément. S'il n'y a pas un tel attribut, la valeur par défaut est renvoyée. 🎜🎜🎜🎜Element.keys()🎜🎜Renvoie une liste de noms d'attributs d'éléments🎜🎜🎜🎜Element.items()🎜🎜Renvoie une liste de (nom, valeur)🎜🎜 🎜🎜Element.getchildren()🎜🎜🎜🎜🎜🎜
Element.getiterator(tag=None)🎜🎜🎜 🎜🎜🎜Element.getiterator(self, tag=None)🎜🎜
🎜🎜🎜🎜
Méthode d'attribut :
🎜🎜🎜 🎜Nom de la méthode🎜 🎜Description🎜🎜🎜🎜🎜🎜Element.tag🎜🎜Nom du nœud (tag) (str)🎜🎜🎜🎜Element.attrib🎜🎜Attributs ( dict) )🎜🎜🎜🎜Element.text🎜🎜text (str)🎜🎜🎜🎜Element.tail🎜🎜Texte supplémentaire (tail) (str)🎜🎜 🎜 🎜Element[:]🎜🎜Liste des nœuds enfants (liste)🎜🎜🎜🎜1)接下来,我们加载这个文档,并进行解析:
>>> import xml.etree.ElementTree as ET>>> tree = ET.ElementTree(file='1.xml')
2) 然后,我们获取根元素(root element):
>>> tree.getroot()<element></element>
3)根元素(root)是一个Element对象。我们看看根元素都有哪些属性:
>>> root = tree.getroot()>>> root.tag, root.attrib('collection', {'shelf': 'New Arrivals'})
4)根元素也具备遍历其直接子元素的接口:
>>> for child_of_root in root:... print(child_of_root.tag, child_of_root.attrib)...class {'className': '1班'}class {'className': '2班'}class {'className': '3班'}
5)通过索引值来访问特定的子元素:
>>> root[0].tag, root[0].text('class', '\n\t ')
6) 查找需要的元素
从上面的示例中,可以明显发现我们能够通过简单的递归方法(对每一个元素,递归式访问其所有子元素)获取树中的所有元素。但是,由于这是十分常见的工作,ET提供了一些简便的实现方法。
Element对象有一个iter方法,可以对某个元素对象之下所有的子元素进行深度优先遍历(DFS)。ElementTree对象同样也有这个方法。下面是查找XML文档中所有元素的最简单方法:
>>> for elem in tree.iter():... print(elem.tag, elem.attrib)...collection {'shelf': 'New Arrivals'}class {'className': '1班'}code {}number {}teacher {}class {'className': '2班'}code {}number {}teacher {}class {'className': '3班'}code {}number {}teacher {}
7)对树进行任意遍历——遍历所有元素,iter方法可以接受tag名称,然后遍历所有具备所提供tag的元素:
>>> for elem in tree.iter(tag='teacher'):... print(elem.tag, elem.text)...teacher 小白 teacher 小红 teacher 小黑
8)支持通过XPath查找元素
>>> for elem in tree.iterfind('class/teacher'):... print(elem.tag, elem.text)...teacher 小白
teacher 小红
teacher 小黑
9)查找所有具备某个name属性的className元素:
>>> for elem in tree.iterfind('class[@className="1班"]'):... print(elem.tag, elem.attrib)...class {'className': '1班'}
10)完整解析代码
import xml.etree.ElementTree as ET
tree = ET.ElementTree(file='1.xml')print(type(tree))root = tree.getroot() # root是根元素print(type(root))print(root.tag)for index, child in enumerate(root):
print("第%s个%s元素,属性:%s" % (index, child.tag, child.attrib))
for i, child_child in enumerate(child):
print("标签:%s,内容:%s" % (child_child.tag, child_child.text))
输出结果:
<class><class>collection
第0个class元素,属性:{'className': '1班'}标签:code,内容:2022001标签:number,内容:10标签:teacher,内容:小白
第1个class元素,属性:{'className': '2班'}标签:code,内容:2022002标签:number,内容:20标签:teacher,内容:小红
第2个class元素,属性:{'className': '3班'}标签:code,内容:2022003标签:number,内容:30标签:teacher,内容:小黑</class></class>
2、DOM 方式
DOM (Document Object Model)将XML文档作为一棵树状结构进行分析,获取节点的内容以及相关属性,或是新增、删除和修改节点的内容。XML解析器在加载XML文件以后,DQM模式将XML文件的元素视为一个树状结构的节点,一次性读入内存。
解析代码:
from xml.dom.minidom import parse# 读取文件dom = parse('1.xml')# 获取文档元素对象elem = dom.documentElement# 获取 classclass_list_obj = elem.getElementsByTagName('class')print(class_list_obj)print(type(class_list_obj))for class_element in class_list_obj:
# 获取标签中内容
code = class_element.getElementsByTagName('code')[0].childNodes[0].nodeValue
number = class_element.getElementsByTagName('number')[0].childNodes[0].nodeValue
teacher = class_element.getElementsByTagName('teacher')[0].childNodes[0].nodeValue print('code:', code, ', number:', number, ', teacher:', teacher)
输出结果:
[<dom>, <dom>, <dom>]<class>code: 2022001 , number: 10 , teacher: 小白 code: 2022002 , number: 20 , teacher: 小红 code: 2022003 , number: 30 , teacher: 小黑</class></dom></dom></dom>
三、Python写入XML文件
doc.writexml():生成xml文档,将创建的存在于内存中的xml文档写入本地硬盘中,这时才能看到新建的xml文档
语法格式:writexml(file,indent=’’,addindent=’’,newl=’’,endocing=None)
参数说明:
-
file:要保存为的文件对象名 -
indent:根节点的缩进方式 -
allindent:子节点的缩进方式 -
newl:针对新行,指明换行方式 -
encoding:保存文件的编码方式
案例代码:
import xml.dom.minidom
# 1、在内存中创建一个空的文档doc = xml.dom.minidom.Document()
# 2、创建根元素root = doc.createElement('collection ')# print('添加的xml标签为:',root.tagName)
# 3、设置根元素的属性root.setAttribute('type', 'New Arrivals')
# 4、将根节点添加到文档对象中doc.appendChild(root)
# 5、创建子元素book = doc.createElement('book')
# 6、添加注释book.appendChild(doc.createComment('这是一条注释'))
# 7、设置子元素的属性book.setAttribute('语言', 'java')
# 8、子元素中嵌套子元素,并添加文本节点name = doc.createElement('name')name.appendChild(doc.createTextNode('java基础'))price = doc.createElement('价格')price.appendChild(doc.createTextNode('99元'))number = doc.createElement('number')number.appendChild(doc.createTextNode('剩余100本'))# 9、将子元素添加到boot节点中book.appendChild(name)book.appendChild(price)book.appendChild(number)# 10、将book节点添加到root根元素中root.appendChild(book)# 创建子元素book = doc.createElement('book')# 设置子元素的属性book.setAttribute('语言', 'python')# 子元素中嵌套子元素,并添加文本节点name = doc.createElement('name')name.appendChild(doc.createTextNode('python基础'))price = doc.createElement('价格')price.appendChild(doc.createTextNode('50元'))number = doc.createElement('number')number.appendChild(doc.createTextNode('剩余20本'))# 将子元素添加到boot节点中book.appendChild(name)book.appendChild(price)book.appendChild(number)# 将book节点添加到root根元素中root.appendChild(book)print(root.toxml())fp = open('./书籍.xml', 'w', encoding='utf-8') # 需要指定utf-8的文件编码格式,不然notepad中显示十六进制doc.writexml(fp, indent='', addindent='\t', newl='\n', encoding='utf-8')fp.close()
生成书籍.xml文件:
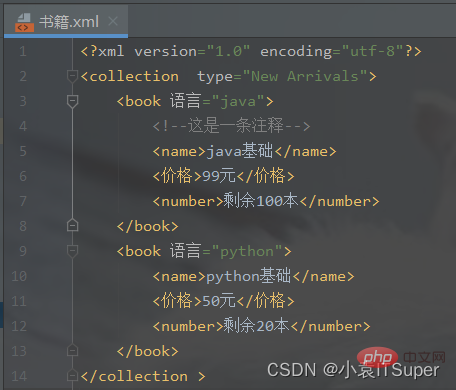
四、Python更新XML文件
向xml中插入新的子元素
案例代码:
import xml.dom.minidomfrom xml.dom.minidom import parse# 对book.xml新增一个子元素english,并删除math元素xml_file = './书籍.xml'# 拿到根节点domTree = parse(xml_file)rootNode = domTree.documentElement# rootNode.removeChild(rootNode.getElementsByTagName('book')[0])# print(rootNode.toxml())# 在内存中创建一个空的文档doc = xml.dom.minidom.Document()book = doc.createElement('book')book.setAttribute('语言', 'c++')# 子元素中嵌套子元素,并添加文本节点name = doc.createElement('name')name.appendChild(doc.createTextNode('c++基础'))price = doc.createElement('价格')price.appendChild(doc.createTextNode('200元'))number = doc.createElement('number')number.appendChild(doc.createTextNode('剩余300本'))# 将子元素添加到boot节点中book.appendChild(name)book.appendChild(price)book.appendChild(number)math_book = rootNode.getElementsByTagName('book')[0]# insertBefore方法 父节点.insertBefore(新节点,父节点中的子节点)rootNode.insertBefore(book, math_book)# appendChild将新产生的子元素在最后插入rootNode.appendChild(book)print(rootNode.toxml())with open(xml_file, 'w', encoding='utf-8') as fh:
domTree.writexml(fh, indent='', addindent='\t', newl='', encoding='utf-8')
输出结果:添加了新节点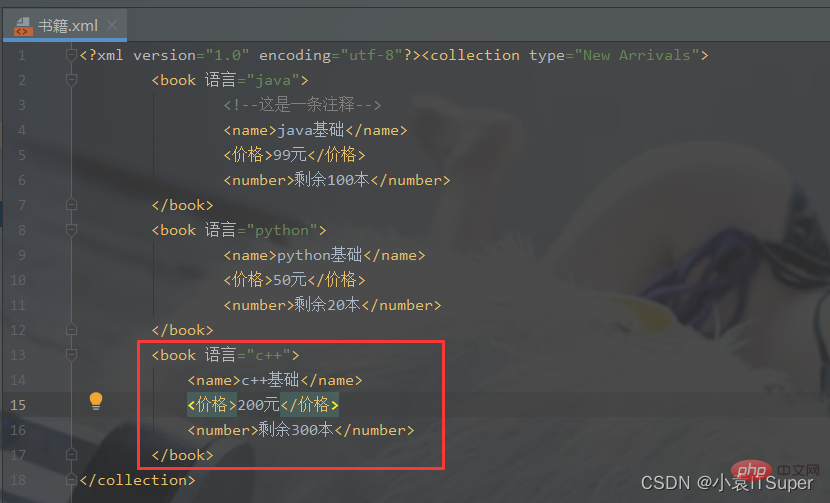
五、XML文件和JSON文件互转
记录工作中常用的一个小技巧
cmd控制台安装第三方模块:
pip install xmltodict
1、XML文件转为JSON文件
新建一个1.xml文件:
<note> <to>tom</to> <from>mary</from> <msg>love</msg></note>
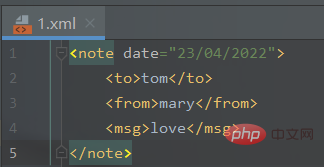
转换代码实现:
import jsonimport xmltodictdef xml_to_json(xml_str): """parse是的xml解析器,参数需要 :param xml_str: xml字符串 :return: json字符串 """ xml_parse = xmltodict.parse(xml_str) # json库dumps()是将dict转化成json格式,loads()是将json转化成dict格式。 # dumps()方法的ident=1,格式化json json_str = json.dumps(xml_parse, indent=1) return json_str XML_PATH = './1.xml' # xml文件的路径with open(XML_PATH, 'r') as f: xmlfile = f.read() with open(XML_PATH[:-3] + 'json', 'w') as newfile: newfile.write(xml_to_json(xmlfile))
输出结果(生成json文件):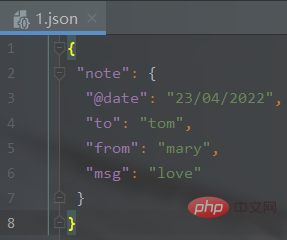
2、JSON文件转换为XML文件
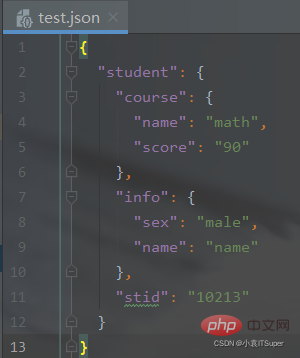
新建test.json文件:
{
"student": {
"course": {
"name": "math",
"score": "90"
},
"info": {
"sex": "male",
"name": "name"
},
"stid": "10213"
}}
转换代码实现:
import xmltodictimport jsondef json_to_xml(python_dict): """xmltodict库的unparse()json转xml :param python_dict: python的字典对象 :return: xml字符串 """ xml_str = xmltodict.unparse(python_dict) return xml_str JSON_PATH = './test.json' # json文件的路径with open(JSON_PATH, 'r') as f: jsonfile = f.read() python_dict = json.loads(jsonfile) # 将json字符串转换为python字典对象 with open(JSON_PATH[:-4] + 'xml', 'w') as newfile: newfile.write(json_to_xml(python_dict))
输出结果(生成xml文件):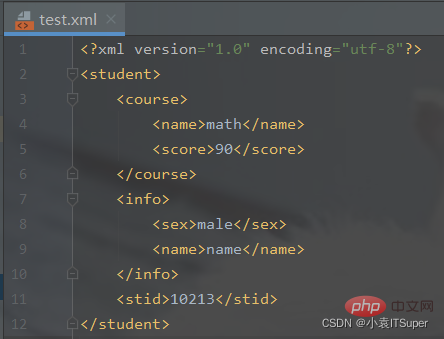
推荐学习:python视频教程
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Trois méthodes pour utiliser la boucle For pour parcourir le dictionnaire Python (exemples détaillés)
- Maîtriser complètement les modules liés aux mathématiques Python
- Maîtriser complètement les compétences communes du proxy IP Python
- Comment vérifier le répertoire d'installation de Python sous Linux
- Résumé Python de la bibliothèque standard json