
Maison >base de données >tutoriel mysql >Résumer et organiser les questions d'entretien courantes sur la base de données MySQL
Résumer et organiser les questions d'entretien courantes sur la base de données MySQL

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-04-27 19:40:022961parcourir
Cet article vous apporte des connaissances pertinentes sur mysql Il présente principalement quelques résumés de questions d'entretien pour les fabricants de bases de données. Examinons-les ensemble, j'espère qu'il sera utile à tout le monde.

Apprentissage recommandé : Tutoriel vidéo mysql
1. Paradigmes courants des bases de données :
- Première forme normale (1NF) : fait référence aux colonnes du tableau qui ne peuvent pas être davantage divisées, et chacune La colonne du tableau dans la base de données est C'est une donnée de base indivisible, et il ne peut pas y avoir plusieurs valeurs dans la même colonne
- Deuxième forme normale (2NF) : Sur la base de 1NF, elle contient également deux parties : premièrement, la table doit avoir une clé primaire ; deuxièmement, les colonnes de clé non primaire du tableau doivent dépendre entièrement de la clé primaire, et ne peuvent pas s'appuyer uniquement sur une partie de la clé primaire
- Troisième forme normale (3NF) : sur la base ; de 2NF, la dépendance transitive des colonnes de clé non primaire sur la clé primaire est éliminée, et les colonnes de clé non primaire doivent dépendre directement de la clé primaire.
- Forme normale BC (BCNF) : Basée sur 3NF, la dépendance transitive de l'attribut principal sur la partie code est éliminée
2 Le processus d'exécution de l'instruction SQL :
2.1. pool de connexion au pilote et à la base de données :
(1) Avant que le client ne communique avec la base de données, il établit une connexion avec MySQL via le pilote de base de données. Une fois l'établissement terminé, il envoie l'instruction SQL
(2) Afin de. réduire la dégradation des performances du système causée par la création et la destruction fréquentes de connexions, grâce au pool de connexions à la base de données maintient un certain nombre de threads de connexion. Lorsqu'une connexion est nécessaire, elle est obtenue directement à partir du pool de connexions. Après utilisation, elle est renvoyée. le pool de connexions. Les pools de connexions de base de données courants incluent Druid, C3P0, DBCP
2.2 et le processus d'exécution de la couche serveur de l'architecture MySQL :
(1) Connecteur : principalement responsable de l'établissement des connexions avec les clients, de l'obtention des autorisations, de la maintenance et de la gestion. connexions
(2) Requête dans le cache : interrogez d'abord dans le cache. Si elle est trouvée, retournez directement. Si la requête est introuvable dans le cache, interrogez dans la base de données.
(4) Optimiseur : Il utilise principalement l'arbre syntaxique obtenu après analyse lexicale et analyse syntaxique de SQL, à travers le contenu du dictionnaire de données et des informations statistiques, puis à travers une série d'opérations pour finalement en dériver un plan d'exécution, y compris le choix quel index utiliser.Le cache MySQL est désactivé par défaut, ce qui signifie que l'utilisation du cache n'est pas recommandée et que toute la fonction de cache de requêtes a été supprimée dans la version MySQL8.0. Ceci est principalement dû aux limitations de ses scénarios d'utilisation :
- Parlons d'abord du format de stockage des données dans le cache : clé (instruction sql) - valeur (valeur des données), donc si l'instruction SQL (clé) est légèrement différente , il s'agira d'une requête directe sur la base de données ;
- Étant donné que les données de la table ne sont pas statiques, la plupart d'entre elles changent fréquemment, et lorsque les données de la base de données changent, les données mises en cache correspondantes liées à cette table doivent être supprimées ;
(3) Analyseur/analyseur : le travail de l'analyseur consiste principalement à effectuer une analyse lexicale et une analyse syntaxique sur l'instruction SQL à exécuter, et enfin à obtenir l'arbre de syntaxe abstraite, puis à utiliser le préprocesseur pour effectuer une correction sémantique sur l'arbre de syntaxe abstraite. . Vérifiez si la table dans l'arbre de syntaxe abstraite existe. Si elle existe, déterminez si le champ de colonne de projection de sélection existe dans la table, etc.
Lors de l'analyse de l'utilisation d'une requête d'index, elle est obtenue par
analyse statistique d'échantillonnage de données dynamiques; tant qu'elle est analysée statistiquement, il peut y avoir deserreurs d'analyse, donc lorsque SQL est exécuté sans en utilisant index , ce facteur doit également être pris en compte (5) Exécuteur : selon une série de plans d'exécution, l'interface API fournie par le moteur de stockage est appelée pour appeler les données d'opération et terminer l'exécution de SQL.
2.3. Processus d'exécution du moteur de stockage Innodb :
- (1) Tout d'abord, l'exécuteur MySQL appelle l'API du moteur de stockage pour interroger les données selon le plan d'exécution
- (2) Le moteur de stockage interroge d'abord les données du pool de tampons. Sinon, il interrogera. le disque. Si la requête est trouvée, placez-la dans le pool de cache
- (3) Lors du chargement des données dans le pool de tampons, l'enregistrement original de ces données sera enregistré dans le fichier journal d'annulation
- (4) innodb le fera. effectuer des opérations de mise à jour dans le Buffer Pool
- (5) Les données mises à jour seront enregistrées dans le tampon de journalisation
- (6) La transaction de validation fera les trois choses suivantes en même temps qu'elle est soumise
- (7) (La première chose) Enregistrez les données dans le tampon de journalisation Flash dans le fichier de journalisation
- (8) (La deuxième chose) Écrivez l'enregistrement de l'opération dans le fichier journal bin
- (9) (La troisième chose) Mettez le nom du fichier journal bin et contenu de la mise à jour dans La position dans le journal bin est enregistrée dans le journal redo et une marque de validation est ajoutée à la fin du journal redo
- (10) À l'aide d'un thread d'arrière-plan, il videra les données mises à jour dans notre pool de tampons vers la base de données MySQL à une certaine opportunité, afin que les données en mémoire et dans la base de données soient unifiées
3. Moteurs de stockage couramment utilisés ? Quelle est la différence entre InnoDB et MyISAM ?
Le moteur de stockage est un composant qui effectue des opérations réelles sur les données physiques sous-jacentes et fournit diverses API pour exploiter les données pour la couche de service Serveur. Les moteurs de stockage couramment utilisés incluent InnoDB, MyISAM et Memory. Ici, nous présentons principalement les différences entre InnoDB et MyISAM :
(1) Transaction : MyISAM ne prend pas en charge les transactions, InnoDB prend en charge les transactions
(2) Niveau de verrouillage : MyISAM ne prend en charge que les verrous au niveau de la table, InnoDB prend en charge les verrous au niveau de la ligne et les verrous au niveau de la table sont utilisés par défaut, mais les verrous de ligne ne seront utilisés que lorsque les données sont interrogées via l'index, sinon les verrous de table seront utilisés. Les verrous au niveau des lignes consomment plus de ressources que les verrous de table lors de chaque opération d'acquisition et de libération des verrous. Il peut y avoir une impasse lors de l'utilisation des verrous de ligne, mais il n'y a pas d'impasse avec les verrous au niveau de la table
(3) Clés primaires et clés étrangères : MyISAM permet aux tables sans index ni clé primaire d'exister et ne prend pas en charge les clés étrangères. La clé primaire d'InnoDB ne peut pas être vide et prend en charge la croissance automatique de la clé primaire. Si la clé primaire ou l'index unique non vide n'est pas défini, une clé primaire de 6 octets sera automatiquement générée et prendra en charge les contraintes d'intégrité des clés étrangères
(4) Index. structure : MyISAM et InnoDB utilisent tous des index arborescents B+. Les champs de données de l'index de clé primaire et de l'index auxiliaire de MyISAM sont les adresses où les enregistrements de données de ligne sont enregistrés. Cependant, le champ Data de l'index de clé primaire d'InnoDB enregistre non pas l'adresse de l'enregistrement de données de la ligne, mais tout le contenu des données de la ligne, tandis que le champ Data de l'index auxiliaire enregistre la valeur de l'index primaire.
Étant donné que l'index auxiliaire d'InnoDB enregistre la valeur de l'index de clé primaire, l'utilisation de l'index auxiliaire nécessite de récupérer l'index deux fois : d'abord, récupérer l'index auxiliaire pour obtenir la clé primaire, puis utiliser la clé primaire pour récupérer les enregistrements dans le indice primaire. C'est pourquoi il n'est pas recommandé d'utiliser des champs trop longs comme clés primaires : puisque l'index auxiliaire contient la colonne de clé primaire, si la clé primaire utilise des champs trop longs, cela fera grossir les autres index auxiliaires, essayez donc de définir le clé primaire aussi petite que possible.
(5) Index de texte intégral : MyISAM prend en charge l'index de texte intégral. InnoDB ne prenait pas en charge l'index de texte intégral avant la version 5.6 et les versions ultérieures ont commencé à prendre en charge l'index de texte intégral
(6) Le numéro spécifique. de lignes dans le tableau :
- ① MyISAM : Enregistre le nombre total de lignes dans le tableau. Si vous utilisez select count() from table, la valeur sera extraite directement sans avoir besoin d'une analyse complète du tableau.
- ② InnoDB : Le nombre total de lignes dans la table n'est pas enregistré. Si vous utilisez select count() from table, vous devez parcourir toute la table, ce qui consomme beaucoup d'argent.
(7) Structure de stockage :
- ① MyISAM stockera trois fichiers sur le disque : le fichier .frm pour stocker la définition de la table, le fichier .MYD pour stocker les données et le fichier .MYI pour stocker l'index.
- ② InnoDB : stockez les données et les index dans l'espace table. Toutes les tables sont stockées dans le même fichier de données. La taille de la table InnoDB n'est limitée que par la taille du fichier du système d'exploitation, qui est généralement de 2 Go.
(8) Espace de stockage :
- ① MyISAM : peut être compressé et dispose d'un espace de stockage plus petit. Prend en charge trois formats de stockage différents : table statique (par défaut, mais veuillez noter qu'il ne doit y avoir aucun espace à la fin des données, elles seront supprimées), table dynamique et table compressée.
- ② InnoDB : nécessite plus de mémoire et de stockage, il établira son propre pool de tampons dédié dans la mémoire principale pour la mise en cache des données et des index.
(9) Scénarios applicables :
- ① Si des capacités de transaction ACID qui fournissent des capacités de restauration et de récupération après incident sont requises, et qu'un contrôle de simultanéité au niveau du verrouillage des lignes est requis, InnoDB est un bon choix
- ② Si la table de données est ; principalement utilisé pour interroger des enregistrements, s'il y a beaucoup plus d'opérations de lecture que d'opérations d'écriture et qu'aucune prise en charge des transactions de base de données n'est requise, le moteur MyISAM peut fournir une efficacité de traitement plus élevée
Remarque : le moteur de stockage MyISAM a été abandonné dans mysql8.0 ; version
4. ACID et principe de mise en œuvre des transactions ?
Une transaction de base de données est l'unité de base du contrôle de concurrence. Elle fait référence à un ensemble logique d'opérations, soit toutes sont exécutées, soit aucune d'entre elles n'est exécutée.
4.1. ACIDE de transaction :
- (1) Atomicité : une transaction est une unité de travail indivisible. Les opérations dans une transaction réussissent ou échouent. Si la transaction échoue, elle doit être annulée.
- (2) Isolement : le degré auquel les données exploitées par une transaction sont visibles par les autres transactions avant leur soumission.
- (3) Persistance : Une fois qu'une transaction est validée, ses modifications apportées aux données de la base de données sont permanentes.
- (4) Cohérence : les transactions ne peuvent pas détruire l'intégrité des données et la cohérence de l'entreprise. Par exemple, lors d’un transfert d’argent, que la transaction réussisse ou échoue, le montant total d’argent entre les deux parties reste inchangé.
4.2. Principe d'implémentation d'ACID :
4.2.1 : L'atomicité est obtenue grâce au journal d'annulation du journal de restauration de MySQL来 : lorsqu'une transaction modifie la base de données, InnoDB génère le journal d'annulation correspondant si l'exécution de la transaction est effectuée. échoue ou si la restauration est appelée, entraînant l'annulation de la transaction, vous pouvez utiliser les informations contenues dans le journal d'annulation pour restaurer les données telles qu'elles étaient avant la modification.
4.2.2. Isolation :
(1) Niveau d'isolation des transactions :
Pour garantir l'intégrité et la cohérence des données lues dans un environnement simultané, la base de données fournit quatre niveaux d'isolation des transactions, plus le niveau d'isolation est élevé , plus les données peuvent être garanties complètes et cohérentes, mais plus l'impact sur les performances de concurrence élevée est grand et plus l'efficacité d'exécution est faible. (Les quatre niveaux d'isolement augmentent de haut en bas)
- Lecture non validée : permet aux transactions de lire les données non validées d'autres transactions pendant l'exécution
- Lecture validée : permet aux transactions de lire pendant l'exécution Obtenez les données qui ont été soumises par d'autres. transactions ;
- Lecture répétable (niveau par défaut) : au sein d'une même transaction, les résultats de la requête sont cohérents à tout moment ;
- Sérialisation de lecture : toutes les transactions sont exécutées une par une et chaque lecture de verrous partagés au niveau de la table doit être obtenue ; , et la lecture et l'écriture se bloqueront.
(2) Problèmes de concurrence des transactions :
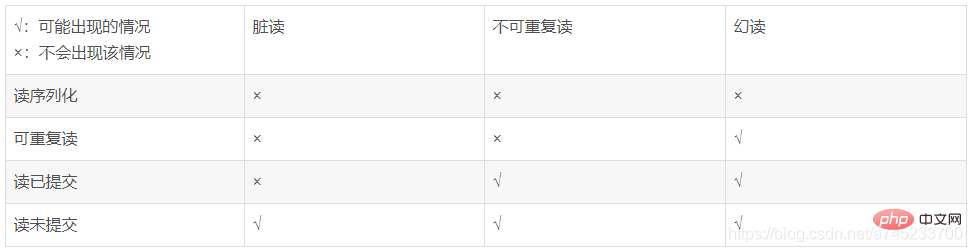
Si l'isolement des transactions n'est pas pris en compte, dans un environnement de concurrence des transactions, il peut y avoir des problèmes :
- Perte de mise à jour : deux opérations de transaction ou plus lorsque la même les données sont alors mises à jour en fonction de la valeur sélectionnée, puisque chaque transaction ignore l'existence d'autres transactions, un problème de perte de mise à jour se produit : la dernière mise à jour écrase les mises à jour effectuées par d'autres transactions.
- Lecture sale : signifie que la transaction A accède aux données et a modifié les données (la transaction n'est pas validée à ce moment-là, la transaction B utilise également ces données. Plus tard, la transaction A annule la restauration et restaure les données modifiées dans son fichier). valeur d'origine. , les données lues par B sont incohérentes avec les données de la base de données, c'est-à-dire que les données lues par B sont des données sales.
- Lecture non répétable : au sein d'une transaction, les mêmes données sont lues plusieurs fois, mais comme une autre transaction a modifié et validé les données pendant cette période, les données lues avant et après sont incohérentes.
- Lecture fantôme : dans une transaction, les mêmes données (généralement une requête de plage) sont lues deux fois, mais comme une autre transaction ajoute ou supprime des données, les résultats des deux fois sont incohérents.
Différents niveaux d'isolation des transactions auront différents problèmes de concurrence dans un environnement concurrent :
(3) Principe de mise en œuvre de l'isolation des transactions :
Le niveau d'isolation des transactions Innodb est déterminé par MVVC et le mécanisme de verrouillage Mis en œuvre :
① MVCC (Multi-Version Concurrency Control, contrôle de concurrence multi-version) est un moyen spécifique pour le moteur de stockage InnoDB de MySQL d'implémenter les niveaux d'isolation des transactions. Il est utilisé pour implémenter les deux niveaux d'isolation de lecture validée et de lecture répétable. Le niveau d'isolement de lecture non validée lit toujours la dernière ligne de données sans utiliser MVCC. Le niveau d'isolement de sérialisation en lecture nécessite le verrouillage de toutes les lignes de lecture, ce qui ne peut pas être réalisé simplement à l'aide de MVCC.
MVCC est implémenté en enregistrant deux colonnes masquées derrière chaque ligne d'enregistrements, l'une enregistrant l'ID de transaction de la ligne et l'autre en enregistrant le pointeur de segment d'annulation de la ligne. Chaque fois qu'une nouvelle transaction est démarrée, un nouvel identifiant de transaction sera automatiquement incrémenté. Lorsqu'une transaction démarre, l'ID de transaction sera placé dans le champ ID de transaction de la ligne affectée par la transaction en cours, et le pointeur du segment d'annulation contient toutes les données de version sur l'enregistrement de ligne, qui est organisé sous la forme d'un lien lié. list dans le journal d'annulation du journal d'annulation, c'est-à-dire que la valeur pointe en fait vers la liste liée de l'historique de la ligne dans le journal d'annulation.
Lors de l'accès simultané à la base de données, la gestion multi-version MVCC est effectuée sur les données de la transaction pour éviter que les opérations d'écriture ne bloquent les opérations de lecture, et le problème de lecture fantôme de la méthode de lecture instantanée peut être résolu en comparant les versions, mais pour le fantôme lecture de la lecture actuelle, MVCC ne peut pas la résoudre et doit être résolu par un verrouillage temporaire des touches.
② Mécanisme de verrouillage :
Le principe de fonctionnement de base du mécanisme de verrouillage MySQL est le suivant : avant qu'une transaction ne modifie la base de données, elle doit obtenir le verrou correspondant. Seule la transaction qui obtient le verrou peut modifier les données pendant l'opération de transaction ; , cette partie des données est verrouillée, si d'autres transactions doivent modifier les données, elles doivent attendre que la transaction en cours soit validée ou annulée pour libérer le verrou.
- Les verrous exclusifs résolvent les lectures sales
- Les verrous partagés résolvent les lectures non répétables
- Les verrous à clé professionnelle résolvent les lectures fantômes
4.2.3 Persistance :
La persistance s'appuie sur le journal de rétablissement pour obtenir ,Lors de l'exécution de SQL. L'instruction SQL exécutée sera enregistrée dans un fichier de journalisation, mais afin d'améliorer l'efficacité, avant d'écrire les données dans le journal de rétablissement, elles seront d'abord écrites dans la zone tampon du tampon de journalisation de la mémoire. Le processus d'écriture est le suivant : lors de l'écriture de données dans la base de données, le processus d'exécution écrira d'abord dans le tampon de journalisation. Les données modifiées dans le tampon de journalisation seront régulièrement actualisées dans le fichier de journalisation sur le disque. appelé vidage du disque (c'est-à-dire que le tampon de journalisation écrit le journal dans le fichier de journalisation sur le disque).
L'utilisation du tampon de journalisation peut grandement améliorer l'efficacité de la lecture et de l'écriture des données, mais elle entraîne également de nouveaux problèmes : si MySQL tombe en panne et que les données modifiées dans le tampon de journalisation n'ont pas été vidées sur le disque en mémoire , cela entraînera une perte de données et la durabilité de la transaction ne pourra être garantie. Afin d'assurer la durabilité de la transaction, lorsque la transaction est validée, l'interface fsync sera appelée pour vider le redo log. La fréquence de rafraîchissement est contrôlée par la variable innodb_flush_log_at_trx_commit :
- 0 : signifie ne pas vider le disque ;
- 1 : chaque transaction Lorsque la transaction est soumise, les données du pool de tampons sont vidées sur le disque ;
- 2 : Lorsque la transaction est soumise, les données du pool de tampons sont écrites dans le cache du système d'exploitation correspondant au disque ; fichier, au lieu de saisir directement le fichier disque . Cela peut prendre 1 seconde avant que les données du cache du système d'exploitation ne soient écrites dans le fichier disque.
4.2.4. Cohérence :
La cohérence fait référence au fait que les transactions ne peuvent pas détruire l'intégrité des données et la cohérence de l'entreprise :
Intégrité des données : intégrité de l'entité, intégrité des colonnes (telles que le type, la taille et la longueur des champs doit répondre aux exigences), les contraintes de clé étrangère, etc.
Cohérence commerciale : Par exemple, lors d'un virement bancaire, que la transaction réussisse ou échoue, le montant total d'argent entre les deux parties reste inchangé.
5. Mécanisme de verrouillage dans la base de données ?
Lorsque plusieurs transactions dans la base de données accèdent simultanément aux mêmes données, si les opérations simultanées ne sont pas contrôlées, des données incorrectes peuvent être lues et stockées, détruisant la cohérence de la base de données. Le principe de fonctionnement de base du mécanisme de verrouillage MySQL est qu'avant qu'une transaction ne modifie la base de données, elle doit d'abord obtenir le verrou correspondant. Seule la transaction qui obtient le verrou peut modifier les données pendant l'opération de transaction ; verrouillé. Si d'autres transactions doivent le modifier, Data doit attendre que la transaction en cours soit validée ou annulée pour libérer le verrou.
Selon différentes méthodes de classification, les types de verrous peuvent être divisés dans les types suivants :Divisés selon la granularité du verrou : verrous au niveau de la table, verrous au niveau de la ligne, verrous au niveau de la page ; Divisé par le type de verrouillage : partagé (verrouillage Lock S), verrouillage exclusif (verrouillage X) ;
5.1, verrouillage au niveau de la table, au niveau de la ligne ; verrouillage, verrouillage au niveau de la page :- Divisé par stratégie d'utilisation du verrouillage : verrouillage optimiste, verrouillage pessimiste
Verrouillage au niveau de la table : le niveau de verrouillage avec la plus grande granularité, la probabilité de conflit de verrouillage est la plus élevée, la concurrence est la plus faible, mais la surcharge est faible, le verrouillage est rapide, et l'impasse ne se produira pas ;
Le moteur de stockage InnoDB prend en charge les verrous au niveau des lignes et les verrous au niveau de la table, les verrous au niveau de la ligne sont utilisés par défaut, mais les verrous au niveau de la ligne ne sont utilisés que lorsque les données sont interrogées via l'index, sinon des verrous au niveau de la table sont utilisés.Verrouillage au niveau de la ligne : le niveau avec la plus petite granularité, l'occurrence La probabilité de conflit de verrouillage est la plus faible et la concurrence est la plus élevée, mais il est coûteux, lent d'ajouter des verrous et les blocages le feront. se produisent ;
- Verrous au niveau de la page : la granularité du verrouillage est limitée entre les verrous au niveau de la table et les verrous au niveau de la ligne. Le verrouillage est un compromis et la concurrence est moyenne. La surcharge et le temps de verrouillage sont également limités entre les verrous de table et les verrous de ligne, et des blocages se produiront
- Différents moteurs de stockage prennent en charge différents mécanismes de verrouillage :
Les moteurs de stockage MyISAM et MEMORY utilisent des verrous au niveau de la table ;
Verrous exclusifs (verrous X, écriture ; lock) : Une fois qu'une transaction a acquis un verrou exclusif, elle peut effectuer des opérations d'écriture sur les lignes de données situées dans la plage de verrouillage, les autres transactions ne peuvent plus acquérir de verrous sur cette partie des lignes de données (verrous partagés, verrous exclusifs). ), seule la transaction qui obtient le verrou exclusif met à jour les données.- Le moteur de stockage BDB utilise des verrous de page, mais prend également en charge les verrous au niveau de la table ; types de verrous :
- Verrous partagés (verrous S, verrous de lecture) : plusieurs transactions peuvent partager un verrou S sur la même ligne de données, mais elles ne peuvent être lues et ne peuvent pas être modifiées
Pour les opérations de mise à jour, de suppression et d'insertion, InnoDB ajoutera automatiquement des verrous exclusifs aux lignes de données impliquées ; pour les instructions SELECT ordinaires, InnoDB n'ajoutera aucun verrou.
- 5.3. Verrous de table et verrous d'intention InnoDB :
- Parce que le moteur InnoDB permet aux verrous de ligne et aux verrous de table de coexister, implémentant un mécanisme de verrouillage multi-granularité. Cependant, bien que les verrous de table et les verrous de ligne aient des plages de verrouillage différentes, ils entreront en conflit les uns avec les autres. Lorsque vous souhaitez ajouter un verrou de table, vous devez d'abord parcourir tous les enregistrements de la table pour déterminer s'il existe un verrou exclusif. Cette méthode de vérification de traversée est évidemment inefficace. MySQL introduit des verrous d'intention pour détecter les conflits entre les verrous de table et les verrous de ligne.
- Gap Locks : lors de l'utilisation de requêtes de plage au lieu de requêtes précises pour récupérer des données et demander des verrous partagés ou exclusifs. Quand, InnoDB verrouillera les éléments d'index des enregistrements de données existants qui remplir les conditions de plage ; pour les enregistrements dont les valeurs clés se trouvent dans la plage de conditions mais n'existent pas, cela s'appelle un écart (GAP).
- Verrouillage d'enregistrement : lorsque vous utilisez un index unique et une requête précise sur l'existence d'un enregistrement, utilisez le verrouillage d'enregistrement
- Le verrouillage X résout les lectures sales
- Le verrouillage S résout la lecture non répétable
- Le verrouillage Pro-key résout la lecture fantôme
- Réduire le nombre de lignes qui doivent être récupérées par la requête, vitesse la requête et évitez les analyses de table complètes. C'est également la principale raison de la création d'index.
- Si la structure de données de l'index est un arbre B+, lors de l'utilisation du regroupement et du tri, le temps de regroupement et de tri dans la requête peut être considérablement réduit.
- En créant un index unique, vous pouvez garantir l'unicité de chaque ligne de données dans la table de la base de données.
- Lorsque les données du tableau sont ajoutées, supprimées et modifiées, l'index doit également être mis à jour et le temps de maintenance augmente avec l'augmentation de la quantité de données.
- Les index doivent occuper de l'espace physique. Si vous souhaitez créer un index clusterisé, l'espace requis sera plus grand.
- Créez des index sur les colonnes qui apparaissent souvent dans la clause WHERE pour accélérer le jugement des conditions.
- Colonnes accessibles par plage ou colonnes utilisées en groupe par ou en ordre par, car l'index a été trié, l'index peut être utilisé pour accélérer le temps de requête de tri.
- Souvent utilisées sur des colonnes connectées, ces colonnes sont principalement des clés étrangères, ce qui peut accélérer la connexion ;
- En tant que colonne de clé primaire, elle renforce l'unicité de la colonne et organise la structure de disposition des données dans la table ;
- Les colonnes contenant peu de colonnes dans la requête ne doivent pas être indexées. Étant donné que ces colonnes sont rarement utilisées, l’ajout d’index réduira en réalité la vitesse de maintenance du système et augmentera les besoins en espace.
- Lorsque l'ajout d'un index entraîne une augmentation du coût de modification bien supérieure à l'amélioration des performances de récupération, l'index ne doit pas être créé. Lors de l'ajout d'index, les performances de récupération seront améliorées, mais les performances de modification seront réduites. Lors de la réduction des index, les performances de modification augmenteront et les performances de récupération diminueront.
- Les colonnes définies comme types de données texte, image et bits ne doivent pas être indexées. Le volume de données de ces colonnes est soit assez important, soit très peu de valeurs.
- Index ordinaire : L'index le plus basique, sans aucune restriction
- Indice unique : Mais la valeur de la colonne d'index doit être unique, les valeurs nulles sont autorisées et il peut y avoir plusieurs valeurs NULL. Dans le cas d'un index composite, la combinaison des valeurs des colonnes doit être unique.
- Indice de clé primaire : un index unique spécial qui n'autorise pas les valeurs nulles.
- Index de texte intégral : l'index de texte intégral ne peut être utilisé que pour les tables MyISAM et ne prend en charge que les types CHAR, VARCHAR ou TEXT. Il est utilisé pour remplacer les opérations de correspondance floue moins efficaces et peut être utilisé pour des opérations complètes ponctuelles. correspondance floue via des index de texte intégral combinés multi-champs.
- Index combiné : principalement pour améliorer l'efficacité de MySQL, lors de la création d'un index composite, les colonnes les plus couramment utilisées comme conditions restrictives doivent être placées à l'extrême gauche, par ordre décroissant.
- Index clusterisé : L'ordre physique de stockage des données dans la table est cohérent avec l'ordre des valeurs d'index. Une table de base ne peut avoir qu'un seul index clusterisé lors de la mise à jour des données sur la colonne d'index clusterisé. entraîne une modification de l'ordre physique des enregistrements dans la table. Les modifications sont coûteuses, il n'est donc pas approprié d'établir des index clusterisés pour les colonnes fréquemment mises à jour : une organisation d'index dans laquelle l'ordre physique des données dans la table est incohérent. avec l'ordre des valeurs d'index. Une table de base peut avoir plusieurs index de cluster.
- Lors de la création d'un index composite, vous ne pouvez pas utiliser uniquement certaines colonnes de l'index composite pour la requête. Étant donné que l'index de hachage combine les données de plusieurs colonnes et calcule ensuite la valeur de hachage, cela n'a aucun sens de calculer la valeur de hachage pour les données de colonnes individuelles.
- Lorsqu'une collision de hachage se produit, l'index de hachage ne peut pas éviter l'analyse des données de la table. Parce qu'il ne suffit pas de comparer simplement la valeur de hachage, vous devez comparer la valeur réelle pour déterminer si elle répond aux exigences.
- B+Tree avec pointeurs d'accès séquentiels : Toutes les données d'index de B+Tree sont stockées sur les nœuds feuilles et des pointeurs d'accès séquentiels sont ajoutés. Chaque nœud feuille a un pointeur vers le nœud feuille adjacent. Ceci est fait pour améliorer l'efficacité de la requête d'intervalle.
- (1) Arbre B+. est bénéfique Analyse de la base de données : bien que l'arbre B améliore les performances des E/S du disque, il ne résout pas le problème de l'inefficacité de la traversée des éléments, tandis que l'arborescence B+ n'a besoin que de parcourir les nœuds feuilles pour résoudre le problème de l'analyse de toutes les informations de mots clés, donc requête de plage et tri Pour d'autres opérations, l'arborescence B+ a des performances plus élevées.
- (2) Le coût d'E/S disque de l'arbre B+ est inférieur : le champ de données du nœud interne de l'arbre B+ ne stocke pas de données, donc son nœud interne est plus petit que celui de l'arbre B. Si tous les mots-clés du même nœud interne sont stockés dans le même bloc disque, plus le bloc disque peut contenir de mots-clés. Plus les mots-clés à rechercher sont lus dans la mémoire en même temps, et le nombre de lectures et d'écritures d'E/S est relativement réduit.
- (3) L'efficacité des requêtes de l'arbre B+ est plus stable : comme les nœuds internes de l'arbre B+ ne sont que des index de mots-clés dans les nœuds feuilles, ils ne stockent pas de données. Par conséquent, toute recherche par mot-clé doit emprunter un chemin allant du nœud racine au nœud feuille. La longueur du chemin de toutes les requêtes par mot-clé est la même, ce qui entraîne une efficacité de requête égale pour chaque donnée.
- Pour l'index combiné d'Innodb, si la longueur de chaque colonne dépasse 767 octets, un index de préfixe sera utilisé pour les colonnes dépassant 767 octets pour l'index à colonne unique d'Innodb, si la colonne a la longueur ; dépasse 767, prenez l'index du préfixe (prenez les 255 premiers caractères)
- Pour l'index combiné de MyISAM, la somme des longueurs d'index créées ne peut pas dépasser 1000 octets, sinon une erreur sera signalée et la création échouera pour la colonne unique de MyISAM ; index, la longueur maximale Il ne peut pas dépasser 1000, sinon cela déclenchera une alarme, mais la création est réussie, et la création finale est un index de préfixe (prendre les 333 premiers caractères)
- La même valeur d'identifiant : exécutée séquentiellement de haut en bas
- La colonne id est nulle : indique qu'il s'agit de un ensemble de résultats, et non Il est requis pour l'interrogation.
- const : Elle est trouvée une fois via l'index, indiquant l'utilisation de index de clé primaire ou index unique
- eq_ref : clé primaire ou unique Les champs de l'index sont utilisés pour la connexion, et une seule ligne de données correspondantes sera renvoyée
- ref : analyse d'index ordinaire, qui peut renvoyer plusieurs lignes qui se rencontrent. les conditions de requête.
- fulltext : Récupération de l'index de texte intégral. La priorité de l'index de texte intégral est très élevée. Si l'index de texte intégral et l'index ordinaire existent en même temps, MySQL donnera la priorité à l'utilisation de l'index de texte intégral. du coût.
- ref_or_null : similaire à la méthode ref, sauf que la comparaison des valeurs nulles est ajoutée.
- index_merge : indique que la requête utilise plus de deux index, la méthode d'optimisation de la fusion d'index, et prend finalement l'intersection ou l'union. Les conditions communes et/ou utilisent des index différents.
- unique_subquery : utilisé pour une sous-requête dans le formulaire où, la sous-requête renvoie une valeur unique sans valeurs en double ;
- index_subquery : utilisé pour une sous-requête dans le formulaire utilisant un index auxiliaire ou dans une liste constante, la sous-requête peut renvoyer des valeurs répétées, vous pouvez Utilisez des index pour dédupliquer les sous-requêtes.
- range : analyse de plage d'index, couramment utilisée dans les requêtes utilisant >, <, between, in, like et d'autres opérateurs.
- index : analyse complète de la table, parcourez l'arborescence d'index du début à la fin ;
- all : parcourez la table entière pour trouver les lignes correspondantes (bien que Index et ALL lisent tous deux la table entière, l'index est lu à partir de l'index. ALL est lu depuis le disque dur)
- NULL : MySQL décompose l'instruction pendant le processus d'optimisation et n'a même pas besoin d'accéder à la table ou à l'index pendant l'exécution
- using index condition : la colonne interrogée n'est pas couverte par l'index, et la condition de filtre Where utilise l'index
- using Temporary : en utilisant une table temporaire L'enregistrement des résultats intermédiaires est souvent utilisé dans les opérations group by et order by. Généralement, c'est parce qu'il n'y a pas d'index sur la colonne de group by. Cela peut aussi être dû au fait qu'il y a à la fois group by et order by, mais les colonnes. de group by et order by sont différents. Généralement, le voir indique que la requête doit être optimisée
- à l'aide du tri de fichiers : MySQL a deux façons de trier les résultats de la requête, l'une consiste à utiliser des index et l'autre est le tri de fichiers (un tri externe). basé sur un tri rapide, avec des performances médiocres). Lorsque la quantité de données est importante, ce sera un processus gourmand en CPU, donc les performances du tri peuvent être optimisées en établissant des index appropriés
- (1) Thread SQL esclave : créé pour lire le journal du relais et exécuter les mises à jour contenues dans le journal, situé côté Esclave
- (2) Thread d'E/S esclave : lisez le contenu envoyé par le thread Binlog Dump du serveur maître et enregistrez-le dans le journal de relais du serveur esclave, situé du côté esclave :
- (3) Thread Binlog dump (également connu sous le nom de IO thread) : Envoyez le contenu du journal binaire bin-log au serveur esclave, situé du côté maître
- (1) Une fois que le serveur maître a exécuté l'instruction SQL, elle est enregistrée dans le fichier. fichier binaire binlog ;
- (2) Le thread IO du côté esclave se connecte au côté maître et demande que le contenu du journal suivant soit copié à partir de la position spécifiée du nœud pos du fichier journal bin log spécifié (ou depuis le tout début de le journal).
- (3) Après avoir reçu la demande de thread IO du côté esclave, le côté maître informe le thread IO responsable du processus de réplication et lit les informations du journal après la position spécifiée du nœud pos du journal binlog spécifié en fonction des informations de la demande. du thread IO côté esclave, puis renvoyé au thread IO du côté esclave. En plus des informations contenues dans le journal binlog, les informations renvoyées incluent également le nom du fichier binlog des informations renvoyées côté maître et la position du nœud POS dans le journal binlog.
- (4) Après avoir reçu les informations renvoyées par l'IO du côté maître, le thread IO du côté esclave écrit à son tour le contenu du journal binlog reçu à la fin du fichier journal de relais côté esclave et lit le binlog fichier côté maître. Le nom et l'emplacement du nœud pos sont enregistrés dans le fichier master-info (le fichier est stocké côté esclave), afin que le maître puisse savoir à partir de quelle position démarrer la synchronisation des données lors de la prochaine synchronisation ;
- (5) Le thread SQL côté esclave détecte le journal de relais. Une fois le contenu ajouté au fichier, le contenu du fichier journal de relais est immédiatement analysé, puis restauré dans les instructions SQL réellement exécutées du côté maître, puis exécuté afin d'obtenir une cohérence des données entre le côté maître et le côté esclave ;
- (1) Séparation en lecture et en écriture, améliore les performances de la base de données. ajouter dynamiquement des serveurs esclaves, effectuer des écritures et des mises à jour sur le serveur maître et effectuer des mises à jour sur le serveur esclave. Exécuter la fonction de lecture.
- (2) Améliorez la sécurité des données, car les données ont été copiées sur le serveur esclave et le serveur esclave peut terminer le processus de réplication, afin qu'elles puissent être sauvegardées sur le serveur esclave sans détruire les données correspondantes du serveur maître.
- (3) Générez des données en temps réel sur le serveur maître et analysez ces données sur le serveur esclave, améliorant ainsi les performances du serveur maître.
- ① Parce qu'il enregistre les instructions SQL, il prend moins d'espace de stockage. Le journal binlog contient des événements décrivant les opérations de base de données, mais ces événements incluent uniquement les opérations qui modifient la base de données, telles que l'insertion, la mise à jour, la création, la suppression et d'autres opérations. Au contraire, des opérations similaires telles que select et desc ne seront pas enregistrées.
- ② Le fichier journal binlog enregistre toutes les instructions qui modifient la base de données, ce fichier peut donc être utilisé comme base pour auditer la base de données.
- ① Ce n'est pas sûr, toutes les déclarations modifiant les données ne seront pas enregistrées. Les comportements non déterministes ne seront pas enregistrés. Par exemple : pour les instructions delete ou update, si limit est utilisé mais qu'il n'y a pas d'ordre par, il s'agit d'une instruction non déterministe et ne sera pas enregistrée.
- ② Pour les instructions update, insert...select sans conditions d'index, davantage de données doivent être verrouillées, ce qui réduit les performances de la base de données.
- ① Toutes les modifications seront copiées, ce qui est le plus sûr. moyen de copier ;
- ② Moins de lignes sont verrouillées pour la mise à jour, l'insertion... select et d'autres instructions ;
- ① Ce qui ne peut pas être visualisé via le fichier journal binlog Une fois l'instruction exécutée, nous n'avons plus moyen de savoir quelle déclaration a été reçue sur le serveur esclave. Nous pouvons seulement voir quelles données ont changé.
- ② Parce qu'il enregistre les données, l'espace de stockage occupé par les fichiers journaux binlog est plus grand que celui basé sur les instructions.
- ③ Les opérations avec de grandes quantités de données prendront plus de temps.
- (1) Ajoutez des serveurs physiques pour partager la charge
- (2) Le maître et l'esclave ne sont responsables que de leur propre écriture et lecture, ce qui atténue considérablement les conflits entre les verrous X et S ;
- (3) La bibliothèque esclave peut configurer le moteur MyISAM pour améliorer les performances des requêtes et économiser la surcharge du système
- (4) Une autre fonction majeure de la réplication maître-esclave est d'augmenter la redondance et d'améliorer disponibilité Lorsqu'une fois le serveur de base de données tombé en panne, le service peut être restauré le plus rapidement possible en ajustant une autre base de données esclave.
- (1) Basée sur l'implémentation interne du code du programme : la classification du routage est effectuée en fonction de la sélection et de l'insertion dans le code. L'avantage est que les performances sont meilleures, car le programme est implémenté dans le code et ne nécessite pas de dépenses matérielles supplémentaires. L'inconvénient est qu'il nécessite la mise en œuvre des développeurs et que le personnel d'exploitation et de maintenance n'a aucun moyen de démarrer.
- (2) Implémentation basée sur la couche proxy intermédiaire : Le proxy se situe généralement entre le serveur d'applications et le serveur de base de données. Le serveur de base de données proxy reçoit la requête du serveur d'applications et la transmet à la base de données back-end en fonction du jugement. Il existe les couches proxy représentatives suivantes.
(1) Évitez la compétition IO et réduisez la probabilité de verrouiller la table. Parce que les grands champs sont moins efficaces, premièrement, les grands champs occupent plus d'espace et le nombre de lignes stockées dans une seule page est réduit, ce qui augmentera les opérations d'E/S. Deuxièmement, la quantité de données est importante et cela prend beaucoup de temps ; lire.
(2) peut mieux améliorer l'efficacité des requêtes sur les données populaires.
- Réduire le couplage dans l'entreprise et faciliter la gestion hiérarchique des différentes entreprises
- Peut augmenter le nombre de connexions d'E/S et de base de données et résoudre le problème de goulot d'étranglement des ressources de stockage matériel sur une seule machine
- La clé primaire est redondante et les colonnes redondantes doivent être gérées
- Le traitement des transactions devient compliqué
- Il existe toujours le problème du volume de données excessif dans une seule table
- Résolvez le problème du volume de données excessif dans une seule table
- Évitez la concurrence des E/S et réduisez la probabilité de verrouillage de table
- Résolvez le problème de goulot d'étranglement d'un grand volume de données dans une seule base de données
- Les conflits d'E/S sont réduits, la concurrence entre les verrous est réduite, les problèmes dans une base de données n'affecteront pas les autres bases de données, améliorant ainsi la stabilité et la disponibilité du système.
- La cohérence des transactions fragmentées est difficile à résoudre
- Les performances de JOIN entre nœuds sont médiocres et la logique deviendra complexe
- Données l'expansion est difficile et difficile à maintenir
- Avantages : géré par base de données, simple et efficace.
- Inconvénients : Le coût en performances est élevé, d'autant qu'il y a de plus en plus de fragments.
- Avantages : Avantages en termes de performances ;
- Inconvénients : Un contrôle flexible des transactions dans l'application est requis. Si vous utilisez la gestion des transactions de Spring, vous rencontrerez certaines difficultés pour apporter des modifications.
- Avantages : L'ID est généré localement, aucun appel à distance n'est requis et il est globalement unique et non répétitif.
- Inconvénients : Il prend beaucoup de place et ne convient pas à l'indexation.
- Avantages : Simple et facile à mettre en œuvre.
- Inconvénients : il existe un goulot d'étranglement en cas de concurrence élevée.
- Avantages : ne dépend pas de la base de données et a de meilleures performances.
- Inconvénients : L'introduction de nouveaux composants augmentera la complexité du système
- 1bit : Le premier bit est par défaut 0, car si le premier bit en binaire est 1, c'est un nombre négatif, mais l'ID ne peut pas être un nombre négatif
- 41bit : Il représente l'horodatage et l'unité l'est. millisecondes.
- 10 bits : enregistrez l'ID de la machine en fonctionnement, dont 5 bits représentent l'ID de la salle informatique et 5 bits représentent l'ID de la machine.
- 12 bits : utilisé pour enregistrer différents identifiants générés dans la même milliseconde.
- (1) Partitionnement de plage : Partition selon la plage d'intervalles continus
- (2) Partitionnement de liste : Sélectionnez la partition en fonction des valeurs de l'ensemble donné.
- (3) Partitionnement de hachage : Partitionnement basé sur la valeur de retour d'une expression définie par l'utilisateur qui est calculée à l'aide des valeurs de colonne de ces lignes qui seront insérées dans le tableau. Cette fonction peut contenir n'importe quelle expression valide dans MySQL qui produit une valeur entière non négative.
- (4) Partitionnement de clé : similaire au partitionnement HASH, la différence est que le partitionnement de clé ne prend en charge que le calcul d'une ou plusieurs colonnes et que la fonction de hachage du partitionnement de clé est fournie par le serveur MySQL.
- La division des partitions en différents disques peut résoudre le problème du goulot d'étranglement de la capacité d'un seul disque, stocker plus de données et également résoudre le problème du disque unique problème de goulot d’étranglement de capacité.
- Réduisez la quantité de données qui doivent être parcourues lors de la récupération de la base de données. Lors de l'interrogation, il vous suffit d'interroger la partition correspondant aux données.
- Évitez les restrictions d'accès mutuellement exclusives de l'index unique d'Innodb
- Pour les fonctions d'agrégation, telles que sum() et count(), elles peuvent être traitées en parallèle dans chaque partition. Au final, il vous suffit de compter les résultats obtenus. par toutes les partitions
- Gestion pratique Pour les données qui ont perdu leur sens de conservation, elles peuvent être rapidement supprimées en supprimant la partition correspondante. Par exemple, pour supprimer des données historiques à un certain moment, exécutez directement la troncature ou supprimez directement la partition entière, ce qui est plus efficace que la suppression
- Dans certains scénarios, la sauvegarde et la récupération d'une seule table de partition seront plus efficaces ;
- La longueur du champ sera beaucoup plus petite que l'UUID.
- La base de données est automatiquement numérotée et stockée dans l'ordre, ce qui est pratique pour la récupération
- Pas besoin de s'inquiéter de la duplication des clés primaires
- Parce qu'il est auto-croissant, en certains scénarios commerciaux, il est facile d'être trouvé par d'autres Volume d'activité.
- Ce sera très gênant lors de la migration des données ou lorsque les tables sont fusionnées
- Dans les scénarios de concurrence élevée, la concurrence pour les verrous à incrémentation automatique réduira le débit de la base de données
- Identification unique, pas besoin de prendre en compte les problèmes de duplication et l'unicité globale peut être obtenue lorsque les données sont divisées et fusionnées.
- Peut être généré au niveau de la couche application pour améliorer le débit de la base de données.
- Pas besoin de vous soucier des fuites de volume d’affaires.
- Étant donné que l'UUID est généré de manière aléatoire, des E/S aléatoires se produiront, affectant la vitesse d'insertion et entraînant une faible utilisation du disque dur.
- UUID prend beaucoup de place. Plus vous créez d'index, plus l'impact est grand.
- La comparaison des tailles entre les UUID est beaucoup plus lente que celle des ID à croissance automatique, ce qui affecte la vitesse des requêtes.
- Simplifie les opérations et définit les données fréquemment utilisées sous forme de vues
- Sécurité, les utilisateurs ne peuvent interroger et modifier que les données visibles
- Indépendance logique, blindage Il élimine l'impact de la structure du réel table
- Mauvaises performances. La base de données doit convertir la requête pour la vue en requête pour la table de base Si la vue est composée d'une multi-table complexe Si la requête est définie. , même s'il s'agit d'une simple requête de vue, la base de données la transformera en une combinaison complexe, ce qui prendra un certain temps.
- (1) Programmation de composants standard : une fois qu'une procédure stockée est créée, elle peut être appelée plusieurs fois dans le programme sans avoir à réécrire l'instruction SQL de la procédure stockée. Et le DBA peut modifier la procédure stockée à tout moment sans aucun impact sur le code source de l'application.
- (2) Vitesse d'exécution plus rapide : si une opération contient une grande quantité de code Transaction-SQL ou est exécutée plusieurs fois, la procédure stockée s'exécutera beaucoup plus rapidement que le traitement par lots. Les procédures stockées étant précompilées, lorsque vous exécutez une procédure stockée pour la première fois, l'optimiseur analyse et optimise la requête et fournit un plan d'exécution qui est finalement stocké dans la table système. L'instruction batch Transaction-SQL doit être compilée et optimisée à chaque exécution, et la vitesse est relativement plus lente.
- (3) Améliorer la fonction et la flexibilité du langage SQL : les procédures stockées peuvent être écrites avec des instructions de contrôle, ont une grande flexibilité et peuvent effectuer des jugements et des opérations complexes.
- (4) Réduire le trafic réseau : Pour les opérations sur le même objet de base de données (telles que requête, modification), si les instructions Transaction-SQL impliquées dans cette opération sont organisées en procédures stockées, alors lorsque la procédure stockée est appelée sur le client ordinateur À l'heure actuelle, seule la déclaration d'appel est transmise sur le réseau, réduisant ainsi considérablement le trafic réseau et la charge du réseau.
- (5) Utilisez-le pleinement comme mécanisme de sécurité : en restreignant les autorisations pour exécuter un certain processus stocké, vous pouvez limiter les autorisations d'accès aux données correspondantes, éviter l'accès des utilisateurs non autorisés aux données et assurer la sécurité des données. .
Les verrous d'intention sont également des verrous au niveau de la table, divisés en verrous d'intention de lecture (verrous IS) et de verrous d'intention d'écriture (verrous IX). Lorsqu'une transaction souhaite ajouter un verrou de ligne à un enregistrement, elle ajoute d'abord le verrou d'intention correspondant à la table. Si une transaction souhaite verrouiller la table ultérieurement, il lui suffit d'abord de déterminer si le verrou prévu existe. S'il existe, elle peut revenir rapidement à la table. Le verrouillage de la table ne peut pas être activé, sinon il devra attendre pour améliorer l'efficacité.
5.4. Implémentation des verrous de ligne et des verrous à clé InnoDB :
Les verrous de ligne InnoDB sont implémentés en verrouillant les éléments d'index sur l'index. Les verrous de ligne ne peuvent être utilisés que lorsque les données sont récupérées via un index, sinon les verrous de table seront utilisés.
Dans InnoDB, afin de résoudre le phénomène de lecture fantôme, le verrou à clé suivante (next-key) est introduit. Selon l'index, il est divisé en intervalles avec la gauche ouverte et la droite fermée. Lors de l'exécution d'une requête de plage, si l'index est atteint et que les données peuvent être récupérées, l'intervalle où se trouve l'enregistrement et son intervalle suivant sont verrouillés. En fait, Next-Key = Record Locks + Gap Locks
5.5, utilisez le mécanisme de verrouillage pour résoudre les problèmes de concurrence :
Pour plus de détails sur le mécanisme de verrouillage du moteur de stockage InnoDB et le mécanisme de verrouillage du moteur de stockage MyISAM, vous pouvez lire cet article : Base de données MySQL : Mécanisme de verrouillage_Zhang Mécanisme Blog-CSDN Blog_Lock de Weipeng dans la base de données
6. Principe de mise en œuvre de l'index MySQL :
L'index est essentiellement une structure de données qui accélère les performances des requêtes en réduisant le nombre de lignes à parcourir et évite les analyse des tables dans la base de données, comme la table des matières d'un livre, vous permettant de trouver du contenu plus rapidement. (Une table peut avoir jusqu'à 16 index)
6.1. Avantages et inconvénients des index :
(1) Avantages des index :
(2) Inconvénients de l'index :
6.2. Scénarios d'utilisation d'index :
(1) Sur quelles colonnes créer des index :
(2) Quelles colonnes ne doivent pas être indexées ?
Colonnes peu différenciées. Étant donné que ces colonnes contiennent très peu de valeurs, telles que le sexe, dans les résultats de la requête, les lignes de données du jeu de résultats représentent une grande proportion des lignes de données de la table, c'est-à-dire qu'une grande proportion des lignes de données doivent être recherché dans le tableau. L'augmentation de l'index n'accélère pas significativement la récupération.
6.3. Classification des index :
(1) Index ordinaire, index unique, index de clé primaire, index de texte intégral, index combiné.(2) Index clusterisé et index non clusterisé :
S'il est classé selon l'ordre physique de stockage des données et l'ordre des valeurs d'index, l'index peut être divisé en deux catégories : index clusterisé et index non clusterisé :
6.4. Structure de données d'index :
Les structures de données d'index courantes incluent : B+Tree, index de hachage.
(1) Index de hachage : seul le moteur de stockage mémoire de MySQL prend en charge l'index de hachage, qui est le type d'index par défaut de la table mémoire. L'index de hachage organise les données sous forme de valeurs de hachage, de sorte que l'efficacité des requêtes est très élevée et peut être localisée en même temps.
Inconvénients de l'index de hachage :L'index de hachage ne peut satisfaire que les requêtes de valeur égale, mais ne peut pas satisfaire les requêtes par plage et le tri. Parce qu'une fois les données passées par l'algorithme de hachage, leur relation de taille peut changer.Avantages de l'index B+Tree :(2) Index B+Tree : B+Tree est la structure de données d'index la plus fréquemment utilisée dans MySQL. C'est le type d'index des modes de moteur de stockage Innodb et Myisam. L'index B+Tree nécessite plusieurs opérations d'E/S du nœud racine au nœud feuille lors de la recherche. La vitesse de requête n'est pas aussi bonne que l'index Hash, mais elle est plus adaptée aux opérations telles que le tri.
Les nœuds dans la page ne stockent pas de contenu, plus de lignes peuvent être lues par IO, réduisant considérablement le nombre de lectures d'E/S disque6.5. Pourquoi utiliser B+Tree comme index :
L'index lui-même est également très volumineux et il est impossible de tout stocker en mémoire, donc
les index sont souvent stockés sur disque sous forme d'index. fichiers. Dans ce cas, la consommation d'E/S disque sera générée lors du processus de recherche d'index. Par rapport à l'accès à la mémoire, la consommation d'accès aux E/S disque est plusieurs ordres de grandeur plus élevée, le plus important est donc d'évaluer la qualité d'un accès disque. structure des données comme index. L'indicateur est la complexité asymptotique du nombre d'opérations d'E/S disque pendant le processus de recherche. En d'autres termes, la structure des données duindex doit minimiser le nombre d'accès aux E/S disque pendant le processus de recherche. (1) Principe de localité et pré-lecture du programme :
Étant donné que le disque lui-même est beaucoup plus lent à accéder que la mémoire principale, couplé au coût du mouvement mécanique, afin d'améliorer l'efficacité, les E/S du disque doivent être minimisé. Afin d'atteindre cet objectif, le disque ne lit souvent pas strictement à la demande, mais lit à l'avance à chaque fois. Même si un seul octet est nécessaire, le disque démarre à partir de cette position et lit séquentiellement une certaine longueur de données vers l'arrière. mémoire. La base théorique en est le fameux principe de localité en informatique : lorsqu’une donnée est utilisée, les données proches seront généralement utilisées immédiatement. Les données requises lors de l'exécution du programme sont généralement concentrées.Étant donné que les lectures séquentielles sur disque sont très efficaces (aucun temps de recherche requis, très peu de temps de rotation), la lecture anticipée peut améliorer l'efficacité des E/S pour les programmes avec localité. La longueur de lecture anticipée est généralement un multiple entier de la page. Lorsque les données à lire par le programme ne sont pas dans la mémoire principale, une exception de défaut de page sera déclenchée. À ce moment, le système enverra un signal de lecture au disque et le disque trouvera la position de départ des données. et lisez une ou plusieurs pages à l'envers. Chargez-les en mémoire, puis revenez anormalement et le programme continue de s'exécuter.
(2) Analyse des performances de l'indice B+Tree : Comme mentionné ci-dessus, le nombre d'E/S disque est généralement utilisé pour évaluer la qualité de la structure de l'index. Commençons par l'analyse B-tree. Une récupération B-tree nécessite l'accès à jusqu'à h nœuds. Dans le même temps, la base de données utilise intelligemment le principe de lecture anticipée du disque pour définir la taille d'un nœud égale à une page. c'est-à-dire que chaque fois qu'un nouveau nœud est créé, une application directe est créée dans l'espace de page, ce qui garantit qu'un nœud est physiquement stocké dans une page et que l'allocation de stockage informatique est alignée sur la page, de sorte que chaque nœud puisse être entièrement chargé. avec une seule E/S. Une récupération dans l'arbre B nécessite au plus h-1 E/S (le nœud racine réside en mémoire) et la complexité temporelle est O(h)=O(logdN). Dans les applications pratiques générales, le degré sortant d est un nombre très grand, généralement supérieur à 100, donc h est très petit. Pour résumer, utiliser B-tree comme structure d’index est très efficace. Pour les structures comme les arbres rouge-noir, bien que la complexité temporelle soit également O(h), h est évidemment beaucoup plus profond, et comme les nœuds logiquement proches peuvent être physiquement éloignés, la localité ne peut pas être exploitée. Par conséquent, l'efficacité des IO. est évidemment bien pire que celui de B-tree. De plus, B+Tree est plus adapté comme structure de données d'index. La raison est liée au degré extérieur d du nœud interne. D'après l'analyse ci-dessus, nous pouvons voir que plus d est grand, meilleures sont les performances de l'index et la limite supérieure du degré sortant d dépend de la taille de la clé et des données dans le nœud puisque le domaine de données est supprimé. à partir des nœuds du B+Tree, il peut avoir un degré de sortie plus grand, le nombre d'E/S disque sera moindre. (3) Comparaison entre l'indice d'arbre B+ et l'indice d'arbre B ? Selon les structures de B-Tree et B+Tree, nous pouvons constater que l'arbre B+ a plus d'avantages que le B-tree dans les systèmes de fichiers ou les systèmes de bases de données. Les raisons sont les suivantes : (4) Implémentation de l'index B+Tree dans les moteurs de stockage InnoDB et MyISAM de MySQL ? MyISAM et InnoDB utilisent tous deux des index d'arbre B+. Les champs de données de l'index de clé primaire et de l'index auxiliaire de MyISAM enregistrent tous deux l'adresse de la ligne, mais l'index de clé primaire d'InnoDB enregistre non pas l'adresse de la ligne, mais toutes les données de la ligne. . et le champ Données de l'index auxiliaire enregistre la valeur de l'index principal. Limite de longueur de l'index : (1) Optimisation MySQL SQL et optimisation de l'index : https://blog.csdn.net/a745233700/article/details/84455241 (2) Optimisation de la structure des tables MySQL : https://blog.csdn .net/a745233700/article/details /84405087 MySQL est une application gourmande en E/S et sa principale responsabilité est la gestion et le stockage des données. Et nous savons que le temps nécessaire pour lire une base de données à partir de la mémoire est de l'ordre de la microseconde, tandis que le temps nécessaire pour lire une E/S à partir d'un disque dur ordinaire est de l'ordre de la milliseconde. La différence entre les deux est de 3 ordres de grandeur. Par conséquent, pour optimiser la base de données, la première étape pour optimiser est l'E/S et convertir autant que possible l'E/S du disque en E/S de la mémoire. Par conséquent, lors de l'optimisation des paramètres de la base de données MySQL, nous optimisons principalement les paramètres qui réduisent les E/S du disque : par exemple, utilisez query_cache_size pour ajuster la taille du cache de requêtes, et utilisez innodb_buffer_pool_size pour ajuster la taille du tampon Le plan d'exécution est un plan de requête basé sur l'arbre de syntaxe abstraite et les informations statistiques des tables associées obtenues par l'instruction SQL après passage par l'analyseur de requêtes. Ce plan est automatiquement analysé. par l'optimiseur de requêtes généré. Puisqu'il s'agit du résultat d'un échantillonnage dynamique de données et d'une analyse statistique, il peut y avoir des erreurs d'analyse, c'est-à-dire que le plan d'exécution n'est pas optimal. Utilisez le mot-clé expliquer pour savoir comment MySQL exécute les instructions de requête SQL, analysez les goulots d'étranglement des performances des instructions select et améliorez nos requêtes. Les résultats d'explication sont les suivants : ; 10.1. Le principe de la réplication maître-esclave MySQL : L'esclave obtient le fichier journal binaire binlog du maître, puis analyse le fichier journal dans le instruction SQL correspondante. Réexécutez les opérations du serveur principal sur le serveur esclave pour assurer la cohérence des données. Le processus de réplication maître-esclave étant asynchrone, les données entre l'esclave et le maître peuvent être retardées, et seule la cohérence finale des données peut être garantie. L'ensemble du processus de réplication entre maître et esclave est principalement complété par trois threads : Remarque : Si un serveur maître est équipé de deux serveurs esclaves, il y aura deux serveurs esclaves dessus. le serveur maître. Binlog dump threads, et chaque serveur esclave a deux threads 10.2. Processus de réplication maître-esclave : 10.3 Avantages de la réplication maître-esclave : 10.4. Les types de réplication pris en charge par MySQL et leurs avantages et inconvénients : Le fichier journal binlog a deux formats, l'un est basé sur des instructions (réplication basée sur des instructions) et l'autre est basé sur des lignes (basé sur des instructions). sur la copie de ligne). Le format par défaut est basé sur une instruction. Si vous souhaitez modifier le format, utilisez l'option -binlog-format lors du démarrage du service. La commande spécifique est la suivante : mysqld_safe –user=msyql –binlog-format=format& (1) Réplication basée sur les instructions : une instruction SQL exécutée sur le serveur maître et la même instruction exécutée sur le serveur esclave. L'efficacité est relativement élevée. Une fois qu'il s'avère qu'une copie exacte n'est pas possible, la copie basée sur les lignes sera automatiquement sélectionnée. Avantages : Inconvénients : (2) Basé sur les lignes : copiez le contenu modifié au lieu d'exécuter la commande sur le serveur esclave. Pris en charge depuis mysql5.0 ; Avantages : Inconvénients : (3) Réplication de type mixte : la réplication basée sur les instructions est adoptée par défaut. Une fois qu'il est constaté que la réplication basée sur les instructions ne peut pas être exacte, la réplication basée sur les lignes sera adoptée. Pour plus de détails sur la réplication maître-esclave, veuillez lire cet article : https://blog.csdn.net/a745233700/article/details/85256818 11.1. Principe : La séparation de la lecture et de l'écriture résout le problème selon lequel l'opération d'écriture de la base de données affecte l'efficacité de la requête et convient aux scénarios où la lecture est bien supérieure à l'écriture. La base pour réaliser la séparation lecture-écriture est la réplication maître-esclave. La base de données maître utilise la réplication maître-esclave pour synchroniser ses propres modifications de données avec le cluster de base de données esclave. Ensuite, la base de données maître est responsable du traitement des opérations d'écriture (bien sûr, elle peut le faire). effectue également des opérations de lecture), et la base de données esclave est responsable du traitement des opérations de lecture, les opérations d'écriture ne peuvent pas être effectuées. Et selon la situation de pression, plusieurs bases de données esclaves peuvent être déployées pour augmenter la vitesse des opérations de lecture, réduire la pression sur la base de données principale et améliorer les performances globales du système. 11.2 Raisons pour lesquelles la séparation en lecture et en écriture améliore les performances : 11.3. Méthode d'implémentation de la lecture et de l'écriture Mysql : La séparation de la lecture et de l'écriture résout la pression de la lecture de la base de données. et les opérations d'écriture, mais ne disperse pas le stockage de la base de données. Pression, l'utilisation de sous-bases de données et de sous-tables peut résoudre le goulot d'étranglement de stockage de la base de données et améliorer l'efficacité des requêtes de la base de données. 12.1. Division verticale : (1) Partitionnement vertical de la table : Divisez une table en plusieurs tables selon les champs, et chaque table stocke une partie des champs. Généralement, les champs fréquemment utilisés sont placés dans une table et les champs moins fréquemment utilisés sont placés dans une autre table. Avantages : (2) Division verticale de la base de données : divisez les tables en différentes bases de données selon différents modules métier, ce qui convient aux systèmes avec un très faible couplage entre les entreprises et une logique métier claire. Avantages : ( 3) Division verticale Inconvénients de (sous-base de données, sous-table) : 12.2 , répartition horizontale : (1) Fractionnement horizontal des tables : Dans la même base de données, divisez les données de la même table en plusieurs tables selon certaines règles. Avantages : (2) Fractionnement horizontal de la base de données : divisez les données de la même table en fonction à certaines règles dans différentes bases de données, et différentes bases de données peuvent être placées sur différents serveurs. Avantages : (3) Inconvénients du fractionnement horizontal (sharding de tables et de bases de données) : 12.3. Solution aux problèmes de sous-base de données et de sous-table : (1) Problème de transaction : ① Option 1 : Utiliser des transactions distribuées : ② Option 2 : Le programme et la base de données contrôlent conjointement la mise en œuvre. Le principe est de décomposer une transaction distribuée sur plusieurs bases de données en plusieurs petites transactions qui n'existent que sur une seule base de données, et de laisser le programme d'application contrôler globalement chaque petite transaction. affaires. (2) Problème de jointure entre nœuds : La manière courante de résoudre ce problème est de l'interroger en deux étapes : rechercher l'identifiant des données associées dans le jeu de résultats de la première requête et lancer la deuxième requête basée sur ces identifiants. Demandez la deuxième fois pour obtenir les données associées. (3) Problèmes de comptage de nœuds croisés, de tri, de regroupement, de pagination et d'agrégation : Parce que de tels problèmes nécessitent un calcul basé sur l'ensemble de la collecte de données. La plupart des agents ne gèrent pas automatiquement le travail de fusion. La solution est similaire à la résolution du problème de jointure entre nœuds. Les résultats sont obtenus sur chaque nœud puis fusionnés du côté de l'application. Contrairement à la jointure, la requête de chaque nœud peut être exécutée en parallèle, la vitesse est donc beaucoup plus rapide qu'une seule grande table. Mais si le jeu de résultats est volumineux, la consommation de mémoire de l’application pose problème. 12.4. Une fois la base de données divisée en tables, comment gérer la clé d'identification ? Une fois la base de données divisée en tables, l'ID de chaque table ne peut pas commencer à 1, un ID global est donc nécessaire. Il existe principalement les méthodes suivantes pour définir l'ID global : (1) UUID : (2) ID d'incrémentation automatique de la base de données : L'utilisation de l'ID d'incrémentation automatique de la base de données après avoir divisé la base de données en tables nécessite une bibliothèque dédiée à la génération de clés primaires. Chaque fois que le service reçoit une requête, cela n'a aucun sens d'insérer une entrée. dans cette bibliothèque en premier. Pour les données, obtenez un ID qui est automatiquement incrémenté par la base de données et utilisez cet ID pour écrire des données dans des sous-bases de données et des sous-tables. (3) ID généré par Redis : (4) L'algorithme en flocon de neige de Twitter : il s'agit d'un identifiant de 64 bits, dont 1 bit est inutilisé, 41 bits sont utilisés en millisecondes et 10 bits sont utilisés comme ID de machine de travail, 12 bits comme numéro de série. (5) Système de génération d'ID distribué Meituan's Leaf, système de génération d'ID distribué Meituan-Dianping : Le partitionnement consiste à stocker les données de la table à différents endroits selon des règles spécifiques Région, c'est-à-dire. , divisant le fichier de données de la table en plusieurs petits blocs lors de l'interrogation des données, il vous suffit de savoir dans quelles régions les données sont stockées, puis d'interroger directement la région correspondante. Il n'est pas nécessaire d'interroger toutes les données de la table. Améliorez les performances des requêtes. Dans le même temps, si les données de la table sont particulièrement volumineuses et ne peuvent pas tenir sur un seul disque, nous pouvons également allouer les données à différents disques pour résoudre le problème de goulot d'étranglement du stockage. L'utilisation de plusieurs disques peut également améliorer l'efficacité des E/S du disque et améliorer la performance. performances de la base de données. Lorsque vous utilisez une table partitionnée, vous devez noter que le champ de partition doit être placé dans la clé primaire ou l'index unique, et que le nombre maximum de partitions par table est de 1024. Les types de partitions courants sont : partition de plage, partition de liste, partition de hachage ; , Partition de clé, (1) Avantages du partitionnement de table : ① Évolutivité : ② Améliorez les performances de la base de données : ③ Gestion pratique de l'exploitation et de la maintenance des données : (1) ID à incrémentation automatique : Avantages de l'utilisation de l'ID à incrémentation automatique : Inconvénients de l'utilisation d'identifiants auto-croissants : (2) UUID : code d'identification unique universel , L'UUID est basé sur Il est généré par le calcul de données telles que l'heure actuelle, le compteur et l'identification du matériel. Avantages de l'utilisation de l'UUID : Inconvénients de l'utilisation de l'UUID : Dans des circonstances normales, MySQL recommande d'utiliser un ID à incrémentation automatique, car dans le moteur de stockage InnoDB de MySQL, l'index de clé primaire est un index clusterisé et les nœuds feuilles de l'arborescence B+ de l'index de clé primaire stockent la clé primaire. valeur et données dans l'ordre. Si l'index de clé primaire est un ID à incrémentation automatique, il suffit de l'organiser dans l'ordre. S'il s'agit d'un UUID, l'ID est généré de manière aléatoire, ce qui entraînera une grande quantité de mouvements de données pendant le traitement des données. l'insertion, génèrent un grand nombre de fragments de mémoire et entraînent une diminution des performances d'insertion. Une vue est une table dérivée d'une ou plusieurs tables (ou vues), et son contenu est défini par une requête. Une vue est une table virtuelle. Seule la définition de la vue est stockée dans la base de données, et les données correspondant à la vue ne sont pas stockées. Lors de l'exploitation des données de la vue, le système exploite la table de base correspondante selon la définition de. la vue. On peut dire qu'une vue est une table construite sur une table de base. Sa structure et son contenu proviennent de la table de base et existent en fonction de l'existence de la table de base. Une vue peut correspondre à une table de base ou à plusieurs tables de base. Les vues sont des abstractions de tables de base et de nouvelles relations établies dans un sens logique. (1) Avantages des vues : (2) Inconvénients des vues : Les instructions SQL doivent d'abord être compilées puis exécutées, et les procédures stockées sont un ensemble d'instructions SQL pour remplir des fonctions spécifiques. l'utilisateur peut spécifier le stockage. Appelez-le avec le nom de la procédure et les arguments donnés. Une logique complexe de fonctionnement de la base de données peut également être implémentée à l'aide de programmes, alors pourquoi avons-nous besoin de procédures stockées ? La raison principale est que l'efficacité de l'utilisation des programmes pour appeler l'API est relativement lente. L'application doit transmettre les instructions SQL au moteur MYSQL via le moteur pour l'exécution. Il est préférable de laisser MySQL prendre directement en charge le travail en cours. le plus compétent et capable de terminer. Avantages des procédures stockées : Un déclencheur est un objet de base de données lié à une table lorsqu'un événement spécifié se produit sur la table où se trouve le déclencheur et que les conditions définies sont remplies, l'ensemble des instructions définies dans. le déclencheur sera exécuté. La fonction de déclenchement peut être appliquée côté base de données pour garantir l'intégrité des données. Un déclencheur est une procédure stockée spéciale. La différence est que la procédure stockée doit être appelée à l'aide d'un appel, tandis que le déclencheur n'a pas besoin d'utiliser un appel ou un appel manuel. Il déclenche l'exécution lors de l'insertion, de la suppression ou de la modification de données dans une table spécifique. Il dispose de capacités de contrôle des données plus sophistiquées et complexes que les fonctions standard de la base de données elle-même. Le curseur est l'identifiant de la natation et peut servir de pointeur. Le curseur peut être utilisé pour parcourir tous les enregistrements de l'ensemble de résultats renvoyés par la base de données de requête, mais un seul. L'enregistrement peut être extrait à la fois. Autrement dit, une seule ligne de données peut être pointée et récupérée à la fois afin d'effectuer les opérations correspondantes. Lorsque vous n'utilisez pas le curseur, cela équivaut à quelqu'un qui vous donne tout d'un coup et vous laisse le retirer ; après avoir utilisé le curseur, cela équivaut à quelqu'un qui vous le donne un par un. À ce moment-là, vous pouvez d'abord. voyez si cette chose est bonne ou non, puis faites votre propre choix. Apprentissage recommandé : Tutoriel vidéo mysql
7. optimisation de la structure :
8. Optimisation des paramètres de base de données :
9. Plan d'exécution d'explication :
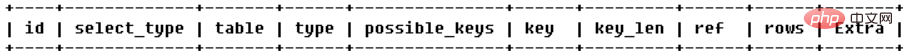
(2) select_type : Le type de requête, principalement utilisé pour distinguer les requêtes complexes telles que les requêtes ordinaires, les requêtes conjointes, les sous-requêtes, etc. (3) table : Indique à quelle table une ligne d'explication accède Différentes valeurs d'identifiant : plus la valeur de l'identifiant est grande, plus la priorité est élevée et plus elle est exécutée tôt
(5) possible_keys : index pouvant être utilisés lors de la requête (6) key : Quel index est réellement utilisé pour optimiser l'accès à cette table (7) key_len : La longueur de l'index réellement utilisée pour optimiser la requête, c'est-à-dire le nombre d'octets utilisés dans l'index. Grâce à cette valeur, vous pouvez calculer quels champs de l'index sont réellement utilisés dans un index multi-colonnes. (8)ref : indique quel champ ou quelle constante est utilisé avec la clé(9)rows : en fonction des statistiques de la table et de la sélection d'index, estimez approximativement le nombre de lignes qui doivent être lues pour la requête ici, pas une valeur exacte valeur. (10)extra : quelques autres informations supplémentaires
system : Il n'y a qu'une seule correspondance de données dans la table (égale à la table système), qui peut être considérée comme un cas particulier de type const
Lecteurs intéressés à expliquer le les détails du plan d'exécution peuvent lire cet article : https://blog.csdn.net/a745233700/article/details/84335453
using index : utilisation de l'index de couverture
10. Réplication maître-esclave MySQL :
11. Séparation en lecture et en écriture :
12. Sous-base de données et sous-table : sous-table verticale, sous-base de données verticale, sous-table horizontale, sous-base de données horizontale
13 Partitionnement :
14. L'ID ou l'UUID à incrémentation automatique est-il généralement utilisé comme clé primaire ?
15. Vue :
16. Procédure stockée Procédure :
17. Déclencheur :
18. Curseur :
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment supprimer MySQL en utilisant Yum sous Linux
- MySQL résume le principe MVCC d'InnoDB
- Résumé mysql partage DML avancé, recherche de pagination, contraintes SQL et opérations multi-tables
- Technologie de réplication MySQL réplication asynchrone et réplication semi-synchrone
- Y a-t-il une différence entre la manière dont PHP se connecte à MySQL ?