
Maison >base de données >Redis >Analysons ensemble les solutions aux problèmes de données chaudes de Redis
Analysons ensemble les solutions aux problèmes de données chaudes de Redis

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-04-20 13:12:175246parcourir
Cet article vous apporte des connaissances pertinentes sur Redis, qui présente principalement les problèmes liés à la solution de grande valeur des touches de raccourci Redis. Examinons-le ensemble, j'espère qu'il sera utile à tout le monde.

Apprentissage recommandé : Tutoriel vidéo Redis
À propos de Redis, les données chaudes et les grandes questions clés à grande valeur sont également faciles à poser des questions de haut niveau, il est préférable de les terminer en une seule fois et de laisser l'intervieweur sans voix. Personnellement, d'après mon expérience professionnelle, les problèmes de données chaudes sont plus susceptibles de se produire au travail que les avalanches. Cependant, la plupart du temps, les points chauds ne sont pas assez chauds et seront alertés et résolus à l'avance. Cependant, une fois ce problème impossible à contrôler. , les problèmes en ligne causés seront suffisants pour vous mettre au bas des performances de cette année. Bon, arrêtons de dire des bêtises et allons droit au but.
Dans des circonstances normales, les données du cluster Redis sont réparties uniformément sur chaque nœud et les requêtes sont réparties uniformément sur chaque fragment. Cependant, dans certains scénarios particuliers, tels que les robots d'exploration externes, les attaques, les produits chauds, etc., les plus typiques. Ce qui s'est passé, c'est que des célébrités ont annoncé leur divorce sur Weibo et que les gens ont afflué pour laisser des messages, provoquant le blocage de la fonction de commentaires de Weibo. Le nombre de visites sur certaines touches en si peu de temps était trop important et les mêmes données le feraient. être demandé pour la même clé. Sur les fragments, la charge élevée sur les fragments devient un problème de goulot d'étranglement, conduisant à une série de problèmes tels que des avalanches.
1. Intervieweur : Avez-vous déjà rencontré des problèmes de données chaudes Redis dans votre projet ?
Analyse du problème : On m'a posé cette question la dernière fois lorsque j'ai entendu un grand patron dans l'interview de groupe Ali p7. L'indice de difficulté est de cinq étoiles, ce qui est vraiment un plus pour les novices comme moi.
Réponse : J'ai quelque chose à dire sur le problème des hot data. Je suis conscient de ce problème depuis que j'ai appris à utiliser Redis, je l'éviterai donc délibérément lorsque je l'utiliserai et je ne creuserai jamais de trou pour cela. moi-même, le plus gros problème avec les données des points d'accès provoquera des échecs causés par le déséquilibre de charge du cluster Redis (c'est-à-dire le biais des données). Ces problèmes sont des coups fatals pour le cluster Redis.
Parlons d'abord des principales causes de l'échec du déséquilibre de charge du cluster Reids :
- Clés avec un volume d'accès élevé, c'est-à-dire des touches de raccourci. Selon l'expérience de maintenance passée, si le QPS accessible par une clé dépasse 1 000, vous. devrait y prêter une attention particulière, comme les produits populaires, les sujets d'actualité, etc.
- Grande valeur. Bien que certains QPS d'accès aux clés ne soient pas élevés, en raison de leur valeur élevée, la charge de la carte réseau est importante, le trafic de la carte réseau est plein et une seule machine peut rencontrer des gigabits/secondes et des pannes d'E/S.
- Hotspot Key + Big Value existent en même temps, tueur de serveur.
Alors, quels défauts seront causés par des touches de raccourci ou des valeurs élevées :
- Problème d'asymétrie des données : des valeurs élevées entraîneront une distribution inégale des données sur différents nœuds du cluster, provoquant des problèmes d'asymétrie des données. avec un taux de lecture-écriture très élevé tombera sur le même serveur Redis, la charge du Redis sera sérieusement augmentée et il sera facile de planter.
- QPS Skew : QPS inégaux entre les fragments.
- Une valeur élevée entraînera une insuffisance du tampon du serveur Redis, ce qui entraînera un délai d'attente d'obtention.
- La valeur étant trop grande, le trafic de la carte réseau dans la salle informatique est insuffisant.
- L'échec du cache Redis entraîne une réaction en chaîne de rupture de la couche de base de données.
2. Intervieweur : Dans des projets réels, comment localiser avec précision les problèmes de données chauds ?
Réponse : La solution à ce problème est relativement large. Elle dépend de différents scénarios commerciaux. Par exemple, si une entreprise organise des activités promotionnelles, il doit y avoir un moyen de compter à l'avance les produits participant à la promotion. Dans ce scénario, la méthode d'estimation peut être utilisée . En cas d'urgence et d'incertitude, Redis surveillera lui-même les données des points d'accès. Pour résumer :
-
Comment savoir à l'avance :
Selon l'entreprise, les statistiques de chair humaine ou les statistiques du système peuvent devenir des données chaudes, comme des produits promotionnels, des sujets d'actualité, des sujets de vacances, des activités d'anniversaire, etc. -
Méthode de collecte du client Redis :
L'appelant compte le nombre de demandes de clés en comptant, mais le nombre de clés ne peut pas être prédit et le code est très intrusif.public Connection sendCommand(final ProtocolCommand cmd, final byte[]... args) { //从参数中获取key String key = analysis(args); //计数 counterKey(key); //ignore } -
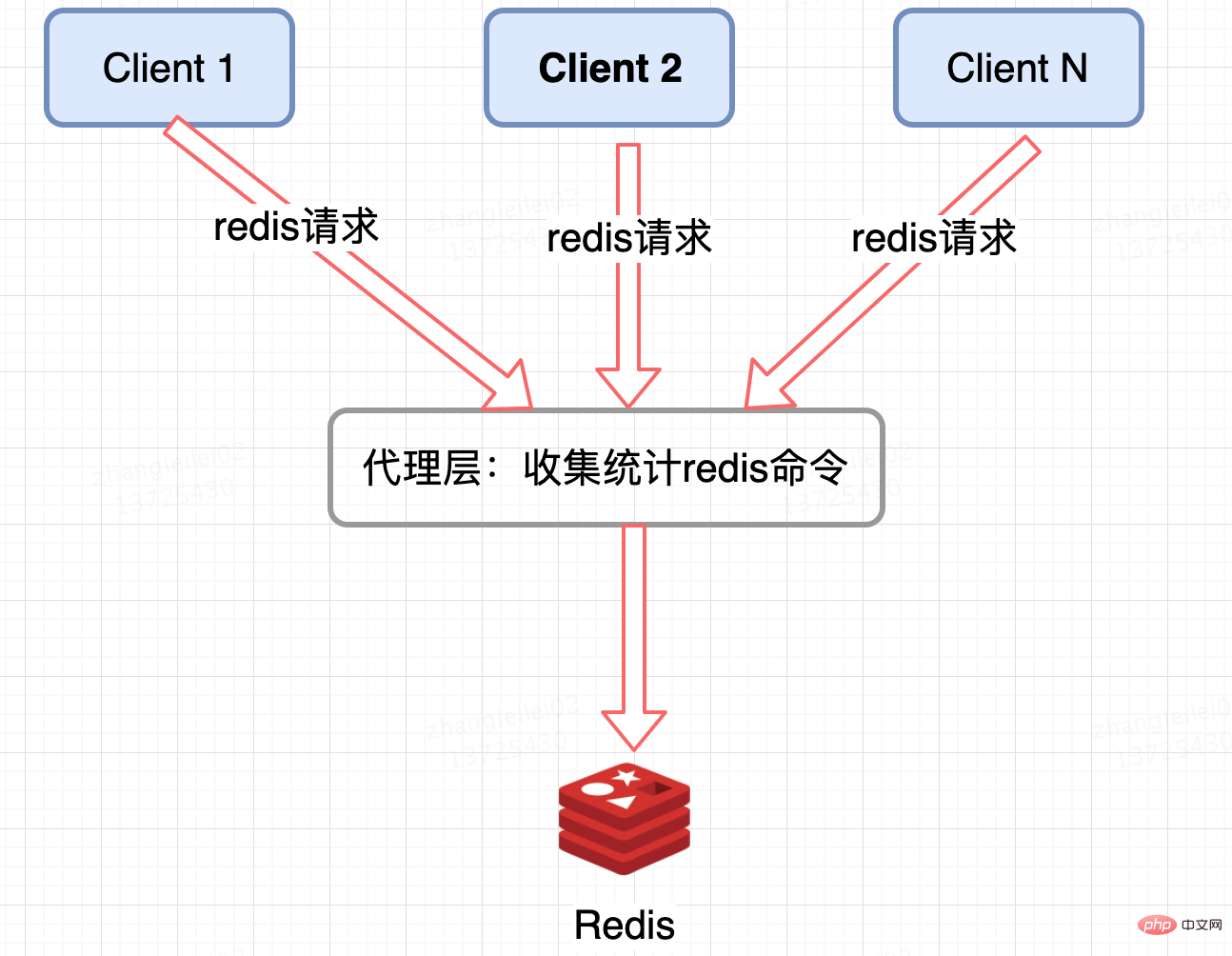
Statistiques de la couche proxy du cluster Redis :
Les architectures distribuées Redis basées sur un proxy comme Twemproxy et codis ont une entrée unifiée et peuvent être collectées et signalées au niveau de la couche proxy. Cependant, les lacunes ne sont pas toutes évidentes. sont Il y a un proxy.
-
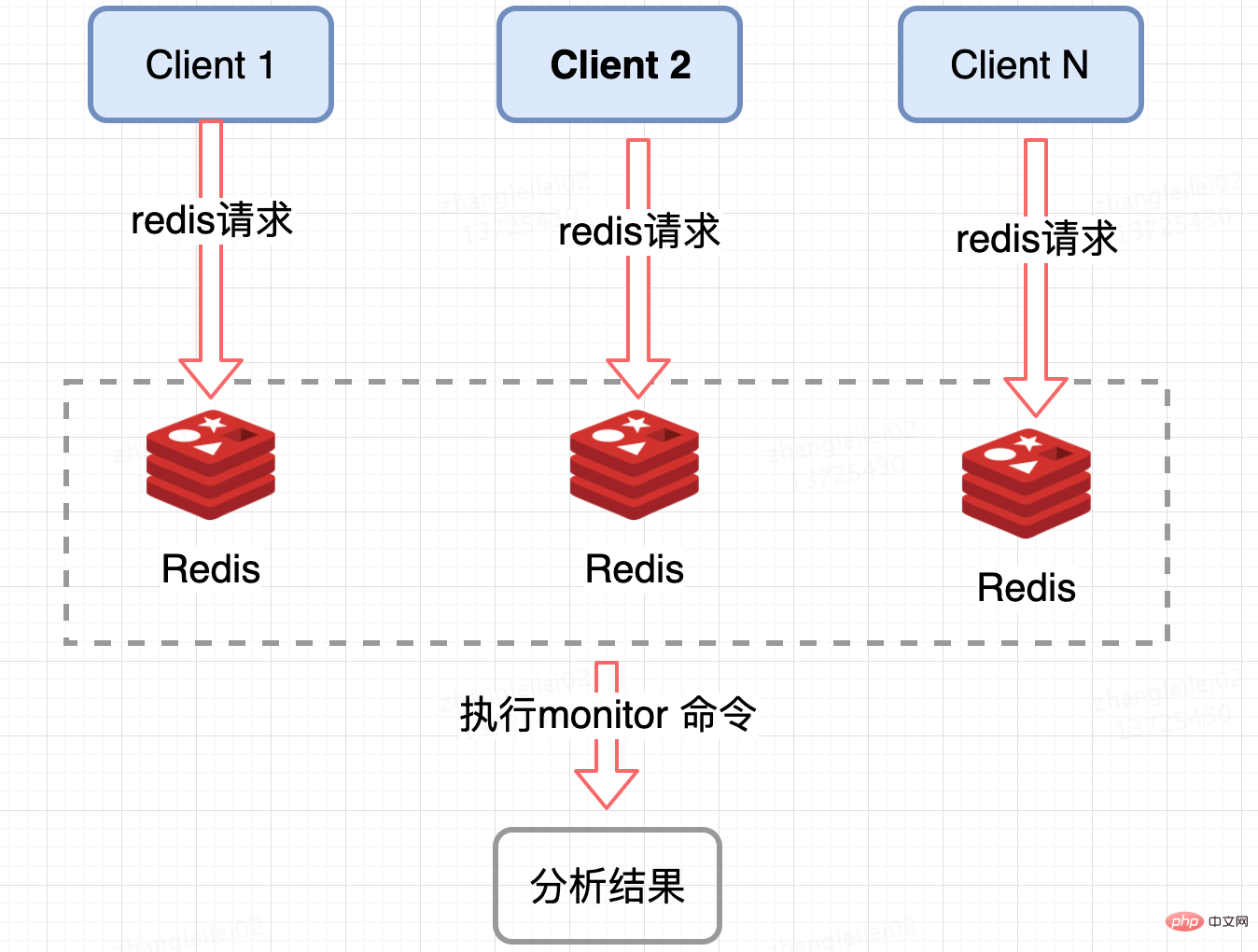
Collection de serveurs Redis :
Surveillez le QPS d'un seul fragment Redis et surveillez les nœuds dont le QPS est incliné dans une certaine mesure pour obtenir les clés de point d'accès. Redis fournit la commande de surveillance, qui peut compter un certain nœud Redis à l'intérieur. une période de temps.Toutes les commandes sont activées, analysez les clés de point d'accès. Dans des conditions de concurrence élevée, il y aura des dangers cachés d'explosion de mémoire et de performances Redis, cette méthode peut donc être utilisée sur une courte période ; Clés de point d'accès d'un nœud Redis. Pour les besoins du cluster. Les statistiques récapitulatives sont un peu plus gênantes d'un point de vue commercial.
Les quatre méthodes mentionnées ci-dessus sont toutes couramment utilisées dans l'industrie. J'ai une nouvelle idée en étudiant le code source de Redis. Type 5 : modifiez le code source Redis.
-
Modifier le code source de Redis : (En réfléchissant à des idées en lisant le code source)
J'ai trouvé que Redis4.0 nous a apporté de nombreuses nouvelles fonctionnalités, notamment le mécanisme de découverte de clés de point d'accès basé sur LFU Avec ceci Avec. Avec la nouvelle fonctionnalité, nous pouvons réaliser les statistiques des touches de hotspot sur cette base. C'est juste mon idée personnelle.
Psychologie de l'intervieweur : Le jeune homme a pas mal d'idées et un esprit très large. Il fait même attention à modifier le code source. Je n'ai pas cette ambition. Nous avons besoin de personnes comme ça dans notre équipe.
(Découvrez les problèmes, analysez les problèmes, résolvez les problèmes et expliquez directement comment résoudre les problèmes de données brûlantes sans attendre que l'intervieweur pose des questions. C'est le contenu principal)
3.
Réponse : Concernant la façon de gérer les problèmes de données brûlants, nous considérons principalement deux aspects pour résoudre ce problème. Le premier est le partage des données, qui permet de répartir uniformément la pression sur plusieurs fragments du cluster pour empêcher une seule machine de se produire. être raccroché. Le deuxième est l’isolement migratoire.
Résumé :
- key split : Si le type de la clé actuelle est une structure de données secondaire, telle qu'un type de hachage. Si le nombre d'éléments de hachage est important, vous pouvez envisager de diviser le hachage actuel, afin que la touche de raccourci puisse être divisée en plusieurs nouvelles clés et distribuée à différents nœuds Redis, réduisant ainsi la pression
- Migrez la touche de raccourci : En prenant Redis Cluster comme exemple, l'emplacement où se trouve la clé de hotspot peut être migré séparément vers un nouveau nœud Redis, même si le QPS de cette clé de hotspot est très élevé, cela n'affectera pas les autres activités de l'ensemble. cluster. Il peut également être personnalisé et développé. La clé est automatiquement migrée vers un nœud indépendant. Cette solution nécessite également davantage de copies.
Limite actuelle de la clé hotspot : - Pour les commandes de lecture, nous pouvons résoudre le problème en migrant la clé du hotspot puis en ajoutant des nœuds esclaves. Pour les commandes d'écriture, nous pouvons limiter le courant en ciblant cette clé du hotspot seule.
Augmenter le cache local : - Pour les entreprises dont la cohérence des données n'est pas si élevée, vous pouvez mettre en cache la clé du point d'accès dans le cache local de la machine métier, car elle se trouve dans la mémoire locale de l'entreprise, éliminant ainsi les E/S distantes. appel. Cependant, lorsque les données sont mises à jour, cela peut entraîner une incohérence entre les données métier et Redis.
Intervieweur : Vous avez très bien répondu et réfléchi de manière très approfondie.
4. Intervieweur : Concernant la dernière question sur Redis, Redis prend en charge les types de données riches, alors comment résoudre le problème de la grande valeur stockée dans ces types de données ? Avez-vous rencontré cette situation en ligne ?
Analyse du problème :
Par rapport au grand concept de raccourci clavier, le concept de grande valeur est mieux compris. Puisque Redis fonctionne sur un seul thread, si la valeur d'une opération est grande, cela aura un impact négatif. sur le temps de réponse de l'ensemble de Redis, car Redis Il s'agit d'une base de données à structure clé-valeur. Une valeur élevée signifie qu'une seule valeur occupe une grande quantité de mémoire. L'impact le plus direct sur le cluster Redis estle biais des données. Réponse :
(Vous voulez me surprendre ? Je suis prêt.)Permettez-moi d'abord de parler de l'ampleur de la valeur. Selon la valeur d'expérience donnée par l'infrastructure de l'entreprise, elle peut être divisée comme suit :
Remarque : (La valeur d'expérience n'est pas une norme, elle est résumée sur la base de l'observation à long terme de cas en ligne par le personnel d'exploitation et de maintenance du cluster)
Big
- : valeur de type chaîne > 10K, dans l'ensemble , list, hash, zset et autres types de données de collection Le nombre d'éléments > 1000.
- Extra large : valeur du type de chaîne > 100 000, le nombre d'éléments dans l'ensemble, la liste, le hachage, le zset et d'autres types de données de collection > 10 000.
- Étant donné que Redis s'exécute dans un seul thread, si la valeur d'une opération est très grande, cela aura un impact négatif sur le temps de réponse de l'ensemble de Redis. Par conséquent, elle peut être divisée si elle peut être divisée en termes de. entreprise. Voici quelques plans de fractionnement typiques :
- 一个较大的 key-value 拆分成几个 key-value ,将操作压力平摊到多个 redis 实例中,降低对单个 redis 的 IO 影响
- 将分拆后的几个 key-value 存储在一个 hash 中,每个 field 代表一个具体的属性,使用 hget,hmget 来获取部分的 value,使用 hset,hmset 来更新部分属性。
- hash、set、zset、list 中存储过多的元素
类似于场景一中的第一个做法,可以将这些元素分拆。
以 hash 为例,原先的正常存取流程是:
hget(hashKey, field); hset(hashKey, field, value)
现在,固定一个桶的数量,比如 10000,每次存取的时候,先在本地计算 field 的 hash 值,模除 10000,确定该 field 落在哪个 key 上,核心思想就是将 value 打散,每次只 get 你需要的。
newHashKey = hashKey + (hash(field) % 10000); hset(newHashKey, field, value); hget(newHashKey, field)
推荐学习:Redis学习教程
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Analyse détaillée Redis de la réplication maître-esclave, des sentinelles et des clusters
- Exemple détaillé de comment déployer un cluster Redis
- Compréhension approfondie des solutions de cluster Redis (mode maître-esclave, mode sentinelle, mode Redis Cluster)
- Le cache Redis apprend un hachage et un emplacement de hachage cohérents
- En savoir plus sur l'utilisation de la fonction de cluster Redis dans le nœud [configuration détaillée]