
Maison >Java >javaDidacticiel >Analyse détaillée du cadre de collecte Java
Analyse détaillée du cadre de collecte Java

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-03-15 18:21:082218parcourir
Cet article vous apporte des connaissances pertinentes sur java, qui présente principalement les problèmes liés au framework de collection. Le framework de collection Java fournit un ensemble d'interfaces et de classes avec d'excellentes performances et une utilisation facile. j'espère que cela aide tout le monde.

Étude recommandée : "Tutoriel d'apprentissage Java"
1. Introduction
1 Introduction au framework de collection
Le framework de collection Java fournit un ensemble d'interfaces et de classes avec d'excellentes performances et une utilisation facile. situé dans le package java.util. Les conteneurs incluent principalement Collection et Map. Collection stocke une collection d'objets, tandis que Map stocke une table de mappage de paires clé-valeur (deux objets)java.util包中。容器主要包括 Collection 和 Map 两种,Collection 存储着对象的集合,而 Map 存储着键值对(两个对象)的映射表

2、相关容器介绍
2.1 Set相关
-
TreeSet
基于红黑树实现,支持有序性操作,例如根据一个范围查找元素的操作。但是查找效率不如 HashSet,HashSet 查找的时间复杂度为 O(1),TreeSet 则为 O(logN) -
HashSet
基于哈希表实现,支持快速查找,但不支持有序性操作。并且失去了元素的插入顺序信息,也就是说使用 Iterator 遍历 HashSet 得到的结果是不确定的。 -
LinkedHashSet
具有 HashSet 的查找效率,且内部使用双向链表维护元素的插入顺序。
2.2 List相关
-
ArrayList
基于动态数组实现,支持随机访问。 -
Vector
和 ArrayList 类似,但它是线程安全的。 -
LinkedList
基于双向链表实现,只能顺序访问,但是可以快速地在链表中间插入和删除元素。不仅如此,LinkedList 还可以用作栈、队列和双向队列。
2.3 Queue相关
-
LinkedList
可以实现双向队列。 -
PriorityQueue
基于堆结构实现,可以用它来实现优先队列。
2.4 Map相关
-
TreeMap
基于红黑树实现。 -
HashMap
基于哈希表实现。 -
HashTable
和 HashMap 类似,但它是线程安全的,这意味着同一时刻多个线程可以同时写入 HashTable 并且不会导致数据不一致。它是遗留类,不应该去使用它。现在可以使用ConcurrentHashMap来支持线程安全,并且ConcurrentHashMap的效率会更高,因为ConcurrentHashMap -
2. Introduction aux conteneurs associés
2.1 Ensemble associé

- HashSet
- est basée sur une table de hachage et prend en charge rapidement. recherche, mais ne prend pas en charge les opérations ordonnées. Et les informations sur l'ordre d'insertion des éléments sont perdues, ce qui signifie que le résultat obtenu en utilisant Iterator pour parcourir le HashSet est incertain.
- LinkedHashSet
- a l'efficacité de recherche de HashSet et utilise en interne une liste doublement chaînée pour maintenir l'ordre d'insertion des éléments.
2.2 Lié à la liste
- ArrayList
- est basé sur l'implémentation d'un tableau dynamique et prend en charge l'accès aléatoire.
| est implémenté sur la base d'une liste doublement chaînée et n'est accessible que de manière séquentielle, mais les éléments peuvent être rapidement insérés et supprimés au milieu de la liste chaînée. De plus, LinkedList peut également être utilisé comme pile, file d'attente et deque. | LinkedList |
|---|---|
| est basé sur la structure du tas et peut être utilisé pour implémenter des files d'attente prioritaires. | |
| TreeMap | est implémenté sur la base d'un arbre rouge-noir. | HashMap
| HashTable | |
| LinkedHashMap | Utilisez une liste doublement chaînée pour conserver l'ordre des éléments, dans l'ordre d'insertion ou dans l'ordre des moins récemment utilisés (LRU) |
| L'interface de collection stocke un ensemble d'éléments non uniques et non ordonnés. objets | L'interface Liste stocke un ensemble d'objets ordonnés non uniques. |
| L'interface Map stocke un ensemble d'objets clé-valeur, fournissant un mappage clé-valeur | ArrayList implémente des tableaux de longueur variable et alloue un espace continu en mémoire. L'efficacité de la traversée des éléments et de l'accès aléatoire aux éléments est relativement élevée |
| HashSet utilise un algorithme de hachage pour implémenter Set | La couche inférieure de HashSet est implémentée à l'aide de HashMap, l'efficacité de la requête est donc élevée puisque l'algorithme hashCode est utilisé pour déterminer directement l'adresse mémoire. de l'élément, l'efficacité d'ajout et de suppression est élevée |
2. Introduction à ArrayList
- ArrayList est une séquence d'index qui peut être agrandie et réduite dynamiquement. Il s'agit d'une classe List basée sur l'implémentation d'un tableau
- Cette classe encapsule un tableau Object[] réalloué dynamiquement, et chaque objet de classe a un. L'attribut capacité [capacity] indique la longueur du tableau Object[] qu'ils encapsulent. Lorsque des éléments sont ajoutés à ArrayList, la valeur de l'attribut augmente automatiquement. Si vous souhaitez ajouter un grand nombre d'éléments à ArrayList, vous pouvez utiliser la méthode EnsureCapacity pour augmenter la capacité à la fois, ce qui peut réduire le nombre de réallocations et améliorer les performances. L'utilisation d'ArrayList est similaire à celle de Vector, mais. Vector est une collection plus ancienne et présente de nombreux défauts. Il est recommandé d'utiliser
- De plus, la différence entre ArrayList et Vector est la suivante : ArrayList n'est pas sécurisé pour les threads. Lorsque plusieurs threads accèdent à la même collection ArrayList, le programme doit s'assurer manuellement. la synchronisation de la collection, tandis que Vector est thread-safe.
3. Analyse du code source
3.1 Structure d'héritage et relation hiérarchique
public class ArrayList<e> extends AbstractList<e> implements List<e>, RandomAccess, Cloneable, java.io.Serializable</e></e></e>
Voici quelques interfaces brièvement expliquées
- Interface RandomAccess
-
Il s'agit d'une interface marquée En regardant le document API, sa fonction. is Il est utilisé pour un accès aléatoire rapide. Concernant les problèmes d'efficacité, si cette interface est implémentée, alors une boucle for ordinaire peut être utilisée pour parcourir, qui a des performances plus élevées, comme ArrayList. Si cette interface n'est pas implémentée, utilisez Iterator pour itérer, ce qui offre des performances plus élevées, comme linkedList. Ce marquage sert donc simplement à nous faire savoir quelle méthode nous utilisons pour obtenir les données est la plus performante.
Interface clonable -
Après avoir implémenté cette interface, vous pouvez utiliser la méthode Object.Clone().
Interface sérialisable -
Implémentez cette interface de sérialisation, indiquant que cette classe peut être sérialisée. Qu'est-ce que la sérialisation ? Pour faire simple, cela signifie qu'il peut être transféré d'une classe vers un flux d'octets, puis d'un flux d'octets vers la classe d'origine.
 3.2 Propriétés
3.2 Propriétés
//版本号
private static final long serialVersionUID = 8683452581122892189L;
//缺省容量
private static final int DEFAULT_CAPACITY = 10;
//空对象数组
private static final Object[] EMPTY_ELEMENTDATA = {};
//缺省空对象数组
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
//存储的数组元素
transient Object[] elementData; // non-private to simplify nested class access
//实际元素大小,默认为0
private int size;
//最大数组容量
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
3.3 Méthode de construction
/**
* 构造具有指定初始容量的空列表
* 如果指定的初始容量为负,则为IllegalArgumentException
*/public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}}/**
* 默认空数组的大小为10
* ArrayList中储存数据的其实就是一个数组,这个数组就是elementData
*/public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;}/**
* 按照集合迭代器返回元素的顺序构造包含指定集合的元素的列表
*/public ArrayList(Collection extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// 转换为数组
//每个集合的toarray()的实现方法不一样,所以需要判断一下,如果不是Object[].class类型,那么久需要使用ArrayList中的方法去改造一下。
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// 否则就用空数组代替
this.elementData = EMPTY_ELEMENTDATA;
}}
3.4 Expansion automatique
Chaque fois qu'un élément est ajouté au tableau, Vérifiez si le nombre d'éléments ajoutés dépassera la longueur du tableau actuel. Si tel est le cas, le tableau sera étendu pour répondre aux besoins d'ajout de données. L'expansion du tableau est réalisée via une méthode publique ensureCapacity(int minCapacity).
Avant d'ajouter un grand nombre d'éléments, je peux également utiliser ensureCapacity pour augmenter manuellement la capacité de l'instance ArrayList afin de réduire la quantité de réallocation incrémentielle. ensureCapacity(int minCapacity)来实现。在实际添加大量元素前,我也可以使用ensureCapacity来手动增加ArrayList实例的容量,以减少递增式再分配的数量。
数组进行扩容时,会将**老数组中的元素重新拷贝一份到新的数组中,每次数组容量的增长大约是其原容量的1.5倍。**这种操作的代价是很高的,因此在实际使用时,我们应该尽量避免数组容量的扩张。当我们可预知要保存的元素的多少时,要在构造ArrayList实例时,就指定其容量,以避免数组扩容的发生。或者根据实际需求,通过调用ensureCapacity方法来手动增加ArrayList实例的容量。
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));}private static int calculateCapacity(Object[] elementData, int minCapacity) {
//判断初始化的elementData是不是空的数组,也就是没有长度
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
//因为如果是空的话,minCapacity=size+1;其实就是等于1,空的数组没有长度就存放不了
//所以就将minCapacity变成10,也就是默认大小,但是在这里,还没有真正的初始化这个elementData的大小
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
//确认实际的容量,上面只是将minCapacity=10,这个方法就是真正的判断elementData是否够用
return minCapacity;}private void ensureExplicitCapacity(int minCapacity) {
modCount++;
//minCapacity如果大于了实际elementData的长度,那么就说明elementData数组的长度不够用
/*第一种情况:由于elementData初始化时是空的数组,那么第一次add的时候,
minCapacity=size+1;也就minCapacity=1,在上一个方法(确定内部容量ensureCapacityInternal)
就会判断出是空的数组,就会给将minCapacity=10,到这一步为止,还没有改变elementData的大小。
第二种情况:elementData不是空的数组了,那么在add的时候,minCapacity=size+1;也就是
minCapacity代表着elementData中增加之后的实际数据个数,拿着它判断elementData的length
是否够用,如果length不够用,那么肯定要扩大容量,不然增加的这个元素就会溢出。*/
if (minCapacity - elementData.length > 0)
grow(minCapacity);}//ArrayList核心的方法,能扩展数组大小的真正秘密。private void grow(int minCapacity) {
//将扩充前的elementData大小给oldCapacity
int oldCapacity = elementData.length;
//newCapacity就是1.5倍的oldCapacity
int newCapacity = oldCapacity + (oldCapacity >> 1);
/*这句话就是适应于elementData就空数组的时候,length=0,那么oldCapacity=0,newCapacity=0,
所以这个判断成立,在这里就是真正的初始化elementData的大小了,就是为10.前面的工作都是准备工作。
*/
if (newCapacity - minCapacity 0)
newCapacity = hugeCapacity(minCapacity);
//新的容量大小已经确定好就copy数组,改变容量大小。
elementData = Arrays.copyOf(elementData, newCapacity);}//用来赋最大值private static int hugeCapacity(int minCapacity) {
if (minCapacity MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;}
3.5 add()方法
/**
* 添加一个特定的元素到list的末尾。
* 先size+1判断数组容量是否够用,最后加入元素
*/public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;}/**
* Inserts the specified element at the specified position in this
* list. Shifts the element currently at that position (if any) and
* any subsequent elements to the right (adds one to their indices).
*
* @param index index at which the specified element is to be inserted
* @param element element to be inserted
* @throws IndexOutOfBoundsException {@inheritDoc}
*/public void add(int index, E element) {
//检查index也就是插入的位置是否合理。
rangeCheckForAdd(index);
//检查容量是否够用,不够就自动扩容
ensureCapacityInternal(size + 1); // Increments modCount!!
//这个方法就是用来在插入元素之后,要将index之后的元素都往后移一位
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;}
当调用add()方法时,实际函数调用:
add→ensureCapacityInternal→ensureExplicitCapacity(→grow→hugeCapacity)
例如刚开始初始化一个空数组后add一个值,会首先进行自动扩容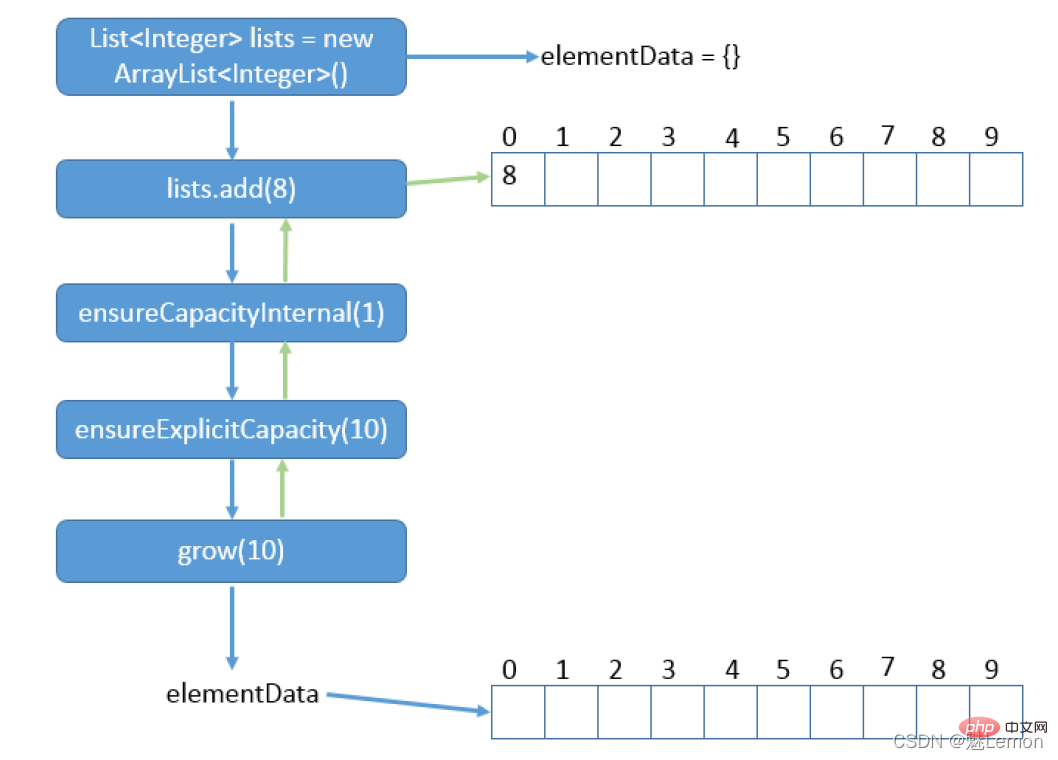
3.6 trimToSize()
将底层数组的容量调整为当前列表保存的实际元素的大小的功能
public void trimToSize() {
modCount++;
if (size <h3>3.7 remove()方法</h3><p><code>remove()</code>方法也有两个版本,一个是<code>remove(int index)</code>删除指定位置的元素,另一个是<code>remove(Object o)</code>删除第一个满足<code>o.equals(elementData[index])</code>的元素。删除操作是<code>add()</code>操作的逆过程,需要将删除点之后的元素向前移动一个位置。需要注意的是为了让GC起作用,必须显式的为最后一个位置赋<code>null</code>值。</p><pre class="brush:php;toolbar:false">public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; //清除该位置的引用,让GC起作用
return oldValue;
}3.8 其他方法
这里简单介绍了核心方法,其他方法查看源码可以很快了解
3.9 Fail-Fast机制
ArrayList采用了快速失败的机制,通过记录modCount参数来实现。在面对并发的修改时,迭代器很快就会完全失败,并抛出ConcurrentModificationException
public class LinkedList<e> extends AbstractSequentialList<e> implements List<e>, Deque<e>, Cloneable, java.io.Serializable</e></e></e></e>🎜3.5 méthode add()🎜
//实际元素个数transient int size = 0; //头结点transient Node<e> first; //尾结点transient Node<e> last;</e></e>🎜Lorsque la méthode add() est appelée, la fonction réelle est appelée : 🎜🎜🎜add→ensureCapacityInternal→ensureExplicitCapacity(→grow→hugeCapacity)🎜🎜🎜Par exemple, après avoir initialisé un vide tableau, ajoutez une valeur, elle sera automatiquement développée en premier🎜
🎜🎜3.6 trimToSize()🎜🎜La fonction d'ajustement de la capacité du tableau sous-jacent à la taille des éléments réels enregistrés dans la liste actuelle🎜public LinkedList() {}public LinkedList(Collection extends E> c) {
this();
//将集合c中的各个元素构建成LinkedList链表
addAll(c);}🎜3.7 méthode remove()🎜🎜Le remove( ) a également deux versions, l'une est remove(int index) pour supprimer l'élément à la position spécifiée, et l'autre est remove(Object o) pour supprimer le premier élément qui satisfait l'élément o.equals(elementData[ index]). L'opération de suppression est le processus inverse de l'opération add(), qui nécessite de déplacer l'élément après le point de suppression vers l'avant d'une position. Il convient de noter que pour que GC fonctionne, la dernière position doit se voir explicitement attribuer une valeur null. 🎜//根据前面介绍双向链表就知道这个代表什么了,linkedList的奥秘就在这里private static class Node<e> {
// 数据域(当前节点的值)
E item;
//后继
Node<e> next;
//前驱
Node<e> prev;
// 构造函数,赋值前驱后继
Node(Node<e> prev, E element, Node<e> next) {
this.item = element;
this.next = next;
this.prev = prev;
}}</e></e></e></e></e>🎜3.8 Autres méthodes🎜🎜La méthode principale est brièvement présentée ici. Vous pouvez rapidement comprendre d'autres méthodes en consultant le code source🎜🎜3.9 Mécanisme Fail-Fast🎜🎜ArrayList adopte un mécanisme de défaillance rapide en enregistrant modCount code> Paramètres à réaliser. Lorsqu'il est confronté à des modifications simultanées, l'itérateur échouera rapidement complètement et lancera une exception <code>ConcurrentModificationException, plutôt que de risquer un comportement arbitraire non spécifié à un moment indéterminé dans le futur🎜4. Résumé
- ArrayList peut stocker null
- ArrayList est essentiellement un tableau elementData
- La différence entre ArrayList et array est qu'il peut automatiquement augmenter la taille. La méthode clé est la méthode gorw()
- removeAll(collection. dans ArrayList La différence entre c) et clear() est que removeAll peut supprimer les éléments spécifiés par lots, tandis que clear supprime tous les éléments de la collection. Étant donné qu'ArrayList est essentiellement un tableau, il sera très rapide dans la requête de données, ainsi que dans l'insertion et. suppression Dans ces aspects, les performances diminuent beaucoup et beaucoup de données doivent être déplacées pour obtenir l'effet souhaité
- ArrayList implémente RandomAccess, il est donc recommandé d'utiliser une boucle for lors de sa traversée
- 3.
1. Utilisation de LinkedList
| Nom de la méthode | Explication oVoid Addfirst (Object O) |
|---|---|
| V oid AddLast (Objet O) | |
2、LinkedList介绍
LinkedList同时实现了List接口和Deque接口,也就是说它既可以看作一个顺序容器,又可以看作一个队列(Queue),同时又可以看作一个栈(Stack)。这样看来,LinkedList简直就是个全能冠军。当你需要使用栈或者队列时,可以考虑使用LinkedList,一方面是因为Java官方已经声明不建议使用Stack类,更遗憾的是,Java里根本没有一个叫做Queue_的类(它是个接口名字)。关于栈或队列,现在的首选是ArrayDeque,它有着比LinkedList(当作栈或队列使用时)有着更好的性能。
LinkedList的实现方式决定了所有跟下标相关的操作都是线性时间,而在首段或者末尾删除元素只需要常数时间。为追求效率LinkedList没有实现同步(synchronized),如果需要多个线程并发访问,可以先采用Collections.synchronizedList()方法对其进行包装
3、源码分析
3.1 继承结构与层次
public class LinkedList<e> extends AbstractSequentialList<e> implements List<e>, Deque<e>, Cloneable, java.io.Serializable</e></e></e></e>


这里可以发现LinkedList多了一层AbstractSequentialList的抽象类,这是为了减少实现顺序存取(例如LinkedList)这种类的工作。如果自己想实现顺序存取这种特性的类(就是链表形式),那么就继承 这个AbstractSequentialList抽象类,如果想像数组那样的随机存取的类,那么就去实现AbstracList抽象类。
-
List接口
列表add、set等一些对列表进行操作的方法 -
Deque接口
有队列的各种特性 -
Cloneable接口
能够复制,使用那个copy方法 -
Serializable接口
能够序列化。 -
没有RandomAccess
推荐使用iterator,在其中就有一个foreach,增强的for循环,其中原理也就是iterator,我们在使用的时候,使用foreach或者iterator
3.2 属性与构造方法
transient关键字修饰,这也意味着在序列化时该域是不会序列化的
//实际元素个数transient int size = 0; //头结点transient Node<e> first; //尾结点transient Node<e> last;</e></e>
public LinkedList() {}public LinkedList(Collection extends E> c) {
this();
//将集合c中的各个元素构建成LinkedList链表
addAll(c);}
3.3 内部类Node
//根据前面介绍双向链表就知道这个代表什么了,linkedList的奥秘就在这里private static class Node<e> {
// 数据域(当前节点的值)
E item;
//后继
Node<e> next;
//前驱
Node<e> prev;
// 构造函数,赋值前驱后继
Node(Node<e> prev, E element, Node<e> next) {
this.item = element;
this.next = next;
this.prev = prev;
}}</e></e></e></e></e>
3.4 核心方法add()和addAll()
public boolean add(E e) {
linkLast(e);
return true;}void linkLast(E e) {
//临时节点l(L的小写)保存last,也就是l指向了最后一个节点
final Node<e> l = last;
//将e封装为节点,并且e.prev指向了最后一个节点
final Node<e> newNode = new Node(l, e, null);
//newNode成为了最后一个节点,所以last指向了它
last = newNode;
if (l == null)
//判断是不是一开始链表中就什么都没有,如果没有,则new Node就成为了第一个结点,first和last都指向它
first = newNode;
else
//正常的在最后一个节点后追加,那么原先的最后一个节点的next就要指向现在真正的 最后一个节点,原先的最后一个节点就变成了倒数第二个节点
l.next = newNode;
//添加一个节点,size自增
size++;
modCount++;}</e></e>
addAll()有两个重载函数,addAll(Collection extends E>)型和addAll(int,Collection extends E>)型,我们平时习惯调用的addAll(Collection<?extends E>)型会转化为addAll(int,Collection extends<e>)</e>型
public boolean addAll(Collection extends E> c) {
return addAll(size, c);}public boolean addAll(int index, Collection extends E> c) {
//检查index这个是否为合理
checkPositionIndex(index);
//将集合c转换为Object数组
Object[] a = c.toArray();
//数组a的长度numNew,也就是由多少个元素
int numNew = a.length;
if (numNew == 0)
//如果空的就什么也不做
return false;
Node<e> pred, succ;
//构造方法中传过来的就是index==size
//情况一:构造方法创建的一个空的链表,那么size=0,last、和first都为null。linkedList中是空的。
//什么节点都没有。succ=null、pred=last=null
//情况二:链表中有节点,size就不是为0,first和last都分别指向第一个节点,和最后一个节点,
//在最后一个节点之后追加元素,就得记录一下最后一个节点是什么,所以把last保存到pred临时节点中。
//情况三index!=size,说明不是前面两种情况,而是在链表中间插入元素,那么就得知道index上的节点是谁,
//保存到succ临时节点中,然后将succ的前一个节点保存到pred中,这样保存了这两个节点,就能够准确的插入节点了
if (index == size) {
succ = null;
pred = last;
} else {
succ = node(index);
pred = succ.prev;
}
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
Node<e> newNode = new Node(pred, e, null);
if (pred == null)
first = newNode;
else
pred.next = newNode;
pred = newNode;
}
if (succ == null) {
/*如果succ==null,说明是情况一或者情况二,
情况一、构造方法,也就是刚创建的一个空链表,pred已经是newNode了,
last=newNode,所以linkedList的first、last都指向第一个节点。
情况二、在最后节后之后追加节点,那么原先的last就应该指向现在的最后一个节点了,
就是newNode。*/
last = pred;
} else {
pred.next = succ;
succ.prev = pred;
}
size += numNew;
modCount++;
return true;}//根据引下标找到该结点并返回Node<e> node(int index) {
//判断插入的位置在链表前半段或者是后半段
if (index > 1)) {
Node<e> x = first;
//从头结点开始正向遍历
for (int i = 0; i x = last;
//从尾结点开始反向遍历
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}}</e></e></e></e>
3.5 remove()
/*如果我们要移除的值在链表中存在多个一样的值,那么我们
会移除index最小的那个,也就是最先找到的那个值,如果不存在这个值,那么什么也不做
*/public boolean remove(Object o) {
if (o == null) {
for (Node<e> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<e> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;}不能传一个null值E unlink(Node<e> x) {
// assert x != null;
final E element = x.item;
final Node<e> next = x.next;
final Node<e> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
//x的前后指向都为null了,也把item为null,让gc回收它
x.item = null;
size--;
modCount++;
return element;}</e></e></e></e></e>
3.6 其他方法
**get(index)、indexOf(Object o)**等查看源码即可
3.7 LinkedList的迭代器
在LinkedList中除了有一个Node的内部类外,应该还能看到另外两个内部类,那就是ListItr,还有一个是DescendingIterator内部类

/*这个类,还是调用的ListItr,作用是封装一下Itr中几个方法,让使用者以正常的思维去写代码,
例如,在从后往前遍历的时候,也是跟从前往后遍历一样,使用next等操作,而不用使用特殊的previous。
*/private class DescendingIterator implements Iterator<e> {
private final ListItr itr = new ListItr(size());
public boolean hasNext() {
return itr.hasPrevious();
}
public E next() {
return itr.previous();
}
public void remove() {
itr.remove();
}}</e>
4、总结
- linkedList本质上是一个双向链表,通过一个Node内部类实现的这种链表结构。linkedList能存储null值
- 跟ArrayList相比较,就真正的知道了,LinkedList在删除和增加等操作上性能好,而ArrayList在查询的性能上好,从源码中看,它不存在容量不足的情况
- linkedList不光能够向前迭代,还能像后迭代,并且在迭代的过程中,可以修改值、添加值、还能移除值
- linkedList不光能当链表,还能当队列使用,这个就是因为实现了Deque接口
四、List总结
1、ArrayList和LinkedList区别
- ArrayList底层是用数组实现的顺序表,是随机存取类型,可自动扩增,并且在初始化时,数组的长度是0,只有在增加元素时,长度才会增加。默认是10,不能无限扩增,有上限,在查询操作的时候性能更好
- LinkedList底层是用链表来实现的,是一个双向链表,注意这里不是双向循环链表,顺序存取类型。在源码中,似乎没有元素个数的限制。应该能无限增加下去,直到内存满了在进行删除,增加操作时性能更好。
两个都是线程不安全的,在iterator时,会发生fail-fast:快速失效。
2. La différence entre ArrayList et Vector
- ArrayList est thread-unsafe Lors de l'utilisation d'un itérateur, un échec rapide se produira
- Vector est thread-safe, car le mot-clé Synchronized est ajouté avant la méthode, fail-fast se produira également. se produit
3, la différence et l'explication de la situation entre fail-fast et fail-safe
Toutes les collections sous java.util sont fail-fast, tandis que toutes les collections sous java.util.concurrent sont fail-safe
- fail-fast
Échoue rapidement.Par exemple, lors de l'utilisation d'un itérateur pour parcourir arrayList, un autre thread modifie le tableau de stockage de arrayList, comme l'ajout, la suppression, etc., provoquant des changements structurels, de sorte que l'itérateur sera rapide. une exceptionjava.util.ConcurrentModificationException(exception de modification simultanée), qui est un échec rapidejava.util.ConcurrentModificationException异常(并发修改异常),这就是快速失败 -
fail-safe
安全失败,在java.util.concurrent下的类,都是线程安全的类,他们在迭代的过程中,如果有线程进行结构的改变,不会报异常,而是正常遍历,这就是安全失败 -
为什么在java.util.concurrent包下对集合有结构的改变却不会报异常?
在concurrent下的集合类增加元素的时候使用Arrays.copyOf()来拷贝副本,在副本上增加元素,如果有其他线程在此改变了集合的结构,那也是在副本上的改变,而不是影响到原集合,迭代器还是照常遍历,遍历完之后,改变原引用指向副本,所以总的一句话就是如果在此包下的类进行增加删除,就会出现一个副本。所以能防止fail-fast,这种机制并不会出错,所以我们叫这种现象为fail-safe -
vector也是线程安全的,为什么是fail-fast呢?
出现fail-safe是因为他们在实现增删的底层机制不一样,就像上面说的,会有一个副本,而像arrayList、linekdList、verctor等他们底层就是对着真正的引用进行操作,所以才会发生异常
4、为什么现在都不提倡使用Vector
- vector实现线程安全的方法是在每个操作方法上加锁,这些锁并不是必须要的,在实际开发中,一般都是通过锁一系列的操作来实现线程安全,也就是说将需要同步的资源放一起加锁来保证线程安全
- 如果多个Thread并发执行一个已经加锁的方法,但是在该方法中,又有Vector的存在,Vector
本身实现中已经加锁了,那么相当于锁上又加锁,会造成额外的开销 - Vector还有fail-fast的问题,也就是说它也无法保证遍历安全,在 遍历时又得额外加锁,又是额外的开销,还不如直接用arrayList,然后再加锁
总结:Vector在你不需要进行线程安全的时候,也会给你加锁,也就导致了额外开销,所以在jdk1.5之后就被弃用了,现在如果要用到线程安全的集合,都是从java.util.concurrent包下去拿相应的类。
五、HashMap分析
1、HashMap介绍
1.1 Java8以前的HashMap
通过key、value封装成一个entry对象,然后通过key的值来计算该entry的hash值,通过entry的hash 值和数组的长度length来计算出entry放在数组中的哪个位置上面,每次存放都是将entry放在第一个位置。
HashMap实现了Map接口,即允许放入key为null的元素,也允许插入value为null的元素;除该类未实现同步外,其余跟Hashtablefail-safe
échec sûr, sous java.util.concurrent Les classes sont toutes thread-safe.Pendant le processus d'itération, si un thread modifie la structure, aucune exception ne sera signalée, mais le parcours sera normal. Pourquoi est-ce dans le package java.util.concurrent ? Aucune exception ne sera-t-elle signalée en cas de changement structurel dans la collection ? 
Arrays.copyOf() pour copier la copie et ajouter des éléments à la copie. Si d'autres threads modifient la structure de la collection ici, cela modifiera également. sur la copie n'affecte pas la collection d'origine. L'itérateur parcourt toujours comme d'habitude. Après le parcours, la référence d'origine est modifiée pour pointer vers la copie. Donc, en un mot, si une classe sous ce package est ajoutée ou supprimée, une copie. apparaîtra. Cela peut donc empêcher les échecs rapides. Ce mécanisme ne fonctionnera pas mal, c'est pourquoi nous appelons ce phénomène fail-safe🎜🎜🎜le vecteur est également thread-safe. Pourquoi est-il fail-safe ? 🎜🎜 La raison pour laquelle la sécurité apparaît est qu'ils utilisent différents mécanismes sous-jacents pour implémenter les ajouts et les suppressions. Comme mentionné ci-dessus, il y aura une copie, tandis que la couche inférieure de arrayList, linekdList, verctor, etc. opère sur des références réelles. c'est pourquoi Une exception se produira🎜🎜🎜4. Pourquoi n'est-il pas recommandé d'utiliser Vector maintenant🎜🎜🎜La façon dont Vector assure la sécurité des threads est d'ajouter des verrous à chaque méthode d'opération. Ces verrous ne sont pas nécessaires dans le développement réel. sont généralement la sécurité des threads est obtenue en verrouillant une série d'opérations, c'est-à-dire en verrouillant les ressources qui doivent être synchronisées ensemble pour assurer la sécurité des threads🎜🎜Si plusieurs threads exécutent simultanément une méthode verrouillée, mais dans cette méthode, il existe de Vector, Vector🎜 a été verrouillé dans sa propre implémentation, cela équivaut donc à verrouiller et verrouiller à nouveau, ce qui entraînera une surcharge supplémentaire🎜🎜Vector a également un problème de défaillance rapide, ce qui signifie qu'il ne peut pas garantir la sécurité de traversée. pour ajouter des verrous supplémentaires lors du parcours, ce qui représente une surcharge supplémentaire. Il est préférable d'utiliser arrayList directement, puis de le verrouiller🎜🎜🎜Résumé : Vector vous verrouillera également lorsque vous n'avez pas besoin d'être thread-safe, ce qui entraîne cela. surcharge supplémentaire, il est donc obsolète après jdk1.5. Désormais, si vous souhaitez utiliser des collections thread-safe, vous obtenez les classes correspondantes du package java.util.concurrent. 🎜🎜5. Analyse HashMap🎜🎜1. Introduction à HashMap🎜1.1 HashMap avant Java8
🎜🎜Encapsule un objet d'entrée via la clé et la valeur, puis calcule la valeur de hachage de l'entrée via la valeur clé. La valeur de hachage de l'entrée et la longueur du tableau sont utilisées pour calculer où l'entrée est placée dans le tableau. Chaque fois que l'entrée est stockée, l'entrée est placée en première position. 🎜🎜🎜HashMap implémente l'interface Map, qui permet d'insérer des éléments aveckey null, et permet également l'insertion de value dans être des éléments null ; sauf que cette classe n'implémente pas la synchronisation, le reste est à peu près le même que Hashtable contrairement à TreeMap, ce conteneur ne garantit pas l'ordre des éléments, et le conteneur peut re-hacher les éléments selon les besoins. L'ordre des éléments sera également remanié, de sorte que l'ordre d'itération du même HashMap à différents moments peut être différent. Selon la façon dont les conflits sont gérés, il existe deux façons d'implémenter une table de hachage, l'une est la méthode d'adressage ouvert (Adressage ouvert) et l'autre est la méthode de liste chaînée de conflit (Chaînage séparé avec des listes chaînées). 🎜Java7 HashMap utilise la méthode de liste chaînée de conflit🎜. 🎜🎜🎜🎜1.2 Java8后的HashMap
Java8 对 HashMap 进行了一些修改,最大的不同就是利用了红黑树,所以其由 数组+链表+红黑树 组成。根据 Java7 HashMap 的介绍,我们知道,查找的时候,根据 hash 值我们能够快速定位到数组的具体下标,但是之后的话,需要顺着链表一个个比较下去才能找到我们需要的,时间复杂度取决于链表的长度为 O(n)。为了降低这部分的开销,在 Java8 中,当链表中的元素达到了 8 个时,会将链表转换为红黑树,在这些位置进行查找的时候可以降低时间复杂度为 O(logN)。
Java7 中使用 Entry 来代表每个 HashMap 中的数据节点,Java8 中使用 Node,基本没有区别,都是 key,value,hash 和 next 这四个属性,不过,Node 只能用于链表的情况,红黑树的情况需要使用 TreeNode
2、Java8 HashMap源码分析
2.1 继承结构与层次
public class HashMap<k> extends AbstractMap<k> implements Map<k>, Cloneable, Serializable</k></k></k>

2.2 属性
//序列号private static final long serialVersionUID = 362498820763181265L; //默认的初始容量static final int DEFAULT_INITIAL_CAPACITY = 1 [] table; //存放具体元素的集transient Set<map.entry>> entrySet; //存放元素的个数,注意这个不等于数组的长度transient int size; //每次扩容和更改map结构的计数器transient int modCount; //临界值,当实际大小(容量*填充因子)超过临界值时,会进行扩容int threshold; //填充因子,计算HashMap的实时装载因子的方法为:size/capacityfinal float loadFactor;</map.entry>
2.3 构造方法
public HashMap(int initialCapacity, float loadFactor) {
// 初始容量不能小于0,否则报错
if (initialCapacity MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//填充因子不能小于或等于0,不能为非数字
if (loadFactor >> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n = MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;}/**
* 自定义初始容量,加载因子为默认
*/public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);}/**
* 使用默认的加载因子等字段
*/public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted}public HashMap(Map extends K, ? extends V> m) {
//初始化填充因子
this.loadFactor = DEFAULT_LOAD_FACTOR;
//将m中的所有元素添加至HashMap中
putMapEntries(m, false);}//将m的所有元素存入该实例final void putMapEntries(Map extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
//判断table是否已经初始化
if (table == null) { // pre-size
//未初始化,s为m的实际元素个数
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft threshold)
threshold = tableSizeFor(t);
}
else if (s > threshold)
resize();
//将m中的所有元素添加至HashMap中
for (Map.Entry extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}}
2.4 核心方法
put()方法
先计算key的hash值,然后根据hash值搜索在table数组中的索引位置,如果table数组在该位置处有元素,则查找是否存在相同的key,若存在则覆盖原来key的value,否则将该元素保存在链表尾部,注意JDK1.7中采用的是头插法,即每次都将冲突的键值对放置在链表头,这样最初的那个键值对最终就会成为链尾,而JDK1.8中使用的是尾插法。此外,若table在该处没有元素,则直接保存。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);}final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<k>[] tab; Node<k> p; int n, i;
//第一次put元素时,table数组为空,先调用resize生成一个指定容量的数组
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//hash值和n-1的与运算结果为桶的位置,如果该位置空就直接放置一个Node
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
//如果计算出的bucket不空,即发生哈希冲突,就要进一步判断
else {
Node<k> e; K k;
//判断当前Node的key与要put的key是否相等
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//判断当前Node是否是红黑树的节点
else if (p instanceof TreeNode)
e = ((TreeNode<k>)p).putTreeVal(this, tab, hash, key, value);
//以上都不是,说明要new一个Node,加入到链表中
else {
for (int binCount = 0; ; ++binCount) {
//在链表尾部插入新节点,注意jdk1.8是在链表尾部插入新节点
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 如果当前链表中的元素大于树化的阈值,进行链表转树的操作
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//在链表中继续判断是否已经存在完全相同的key
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//走到这里,说明本次put是更新一个已存在的键值对的value
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
//在hashMap中,afterNodeAccess方法体为空,交给子类去实现
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//如果当前size超过临界值,就扩容。注意是先插入节点再扩容
if (++size > threshold)
resize();
//在hashMap中,afterNodeInsertion方法体为空,交给子类去实现
afterNodeInsertion(evict);
return null;}</k></k></k></k>
resize() 数组扩容
用于初始化数组或数组扩容,每次扩容后,容量为原来的 2 倍,并进行数据迁移
final Node<k>[] resize() {
Node<k>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) { // 对应数组扩容
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 将数组大小扩大一倍
else if ((newCap = oldCap = DEFAULT_INITIAL_CAPACITY)
// 将阈值扩大一倍
newThr = oldThr 0) // 对应使用 new HashMap(int initialCapacity) 初始化后,第一次 put 的时候
newCap = oldThr;
else {// 对应使用 new HashMap() 初始化后,第一次 put 的时候
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap [] newTab = (Node<k>[])new Node[newCap];
table = newTab; // 如果是初始化数组,到这里就结束了,返回 newTab 即可
if (oldTab != null) {
// 开始遍历原数组,进行数据迁移。
for (int j = 0; j e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
// 如果该数组位置上只有单个元素,那就简单了,简单迁移这个元素就可以了
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
// 如果是红黑树,具体我们就不展开了
else if (e instanceof TreeNode)
((TreeNode<k>)e).split(this, newTab, j, oldCap);
else {
// 这块是处理链表的情况,
// 需要将此链表拆成两个链表,放到新的数组中,并且保留原来的先后顺序
// loHead、loTail 对应一条链表,hiHead、hiTail 对应另一条链表,代码还是比较简单的
Node<k> loHead = null, loTail = null;
Node<k> hiHead = null, hiTail = null;
Node<k> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
// 第一条链表
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
// 第二条链表的新的位置是 j + oldCap,这个很好理解
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;}</k></k></k></k></k></k></k>
get()过程
public V get(Object key) {
Node<k> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;}final Node<k> getNode(int hash, Object key) {
Node<k>[] tab; Node<k> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 判断第一个节点是不是就是需要的
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
// 判断是否是红黑树
if (first instanceof TreeNode)
return ((TreeNode<k>)first).getTreeNode(hash, key);
// 链表遍历
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;}</k></k></k></k></k>
2.5 其他方法
HashSet是对HashMap的简单包装,其他还有迭代器等
3、总结
关于数组扩容,从putVal源代码中我们可以知道,当插入一个元素的时候size就加1,若size大于threshold的时候,就会进行扩容。假设我们的capacity大小为32,loadFator为0.75,则threshold为24 = 32 * 0.75,此时,插入了25个元素,并且插入的这25个元素都在同一个桶中,桶中的数据结构为红黑树,则还有31个桶是空的,也会进行扩容处理,其实此时,还有31个桶是空的,好像似乎不需要进行扩容处理,但是是需要扩容处理的,因为此时我们的capacity大小可能不适当。我们前面知道,扩容处理会遍历所有的元素,时间复杂度很高;前面我们还知道,经过一次扩容处理后,元素会更加均匀的分布在各个桶中,会提升访问效率。所以说尽量避免进行扩容处理,也就意味着,遍历元素所带来的坏处大于元素在桶中均匀分布所带来的好处。
- HashMap在JDK1.8以前是一个链表散列这样一个数据结构,而在JDK1.8以后是一个数组加链表加红黑树的数据结构
- 通过源码的学习,HashMap是一个能快速通过key获取到value值得一个集合,原因是内部使用的是hash查找值得方法
另外LinkedHashMap是HashMap的直接子类,二者唯一的区别是LinkedHashMap在HashMap的基础上,采用双向链表(doubly-linked list)的形式将所有**entry**连接起来,这样是为保证元素的迭代顺序跟插入顺序相同
六、Collections工具类
1、概述
此类完全由在 collection 上进行操作或返回 collection 的静态方法组成。它包含在 collection 上操作的多态算法,即“包装器”,包装器返回由指定 collection 支持的新 collection,以及少数其他内容。如果为此类的方法所提供的 collection 或类对象为 null,则这些方法都将抛出NullPointerException
2、排序常用方法
//反转列表中元素的顺序 static void reverse(List> list) //对List集合元素进行随机排序 static void shuffle(List> list) //根据元素的自然顺序 对指定列表按升序进行排序 static void sort(List<t> list) //根据指定比较器产生的顺序对指定列表进行排序 static <t> void sort(List<t> list, Comparator super T> c) //在指定List的指定位置i,j处交换元素 static void swap(List> list, int i, int j) //当distance为正数时,将List集合的后distance个元素“整体”移到前面;当distance为负数时,将list集合的前distance个元素“整体”移到后边。该方法不会改变集合的长度 static void rotate(List> list, int distance)</t></t></t>
3、查找、替换操作
//使用二分搜索法搜索指定列表,以获得指定对象在List集合中的索引 //注意:此前必须保证List集合中的元素已经处于有序状态 static <t> int binarySearch(List extends Comparable super T>>list, T key) //根据元素的自然顺序,返回给定collection 的最大元素 static Object max(Collection coll) //根据指定比较器产生的顺序,返回给定 collection 的最大元素 static Object max(Collection coll,Comparator comp): //根据元素的自然顺序,返回给定collection 的最小元素 static Object min(Collection coll): //根据指定比较器产生的顺序,返回给定 collection 的最小元素 static Object min(Collection coll,Comparator comp): //使用指定元素替换指定列表中的所有元素 static <t> void fill(List super T> list,T obj) //返回指定co1lection中等于指定对象的出现次数 static int frequency(collection>c,object o) //返回指定源列表中第一次出现指定目标列表的起始位置;如果没有出现这样的列表,则返回-1 static int indexofsubList(List>source, List>target) //返回指定源列表中最后一次出现指定目标列表的起始位置;如果没有出现这样的列表,则返回-1 static int lastIndexofsubList(List>source,List>target) //使用一个新值替换List对象的所有旧值o1dval static <t> boolean replaceA1l(list<t> list,T oldval,T newval)</t></t></t></t>
4、同步控制
Collectons提供了多个synchronizedXxx()方法,该方法可以将指定集合包装成线程同步的集合,从而解决多线程并发访问集合时的线程安全问题。正如前面介绍的HashSet,TreeSet,arrayList,LinkedList,HashMap,TreeMap都是线程不安全的。Collections提供了多个静态方法可以把他们包装成线程同步的集合。
//返回指定 Collection 支持的同步(线程安全的)collection static <T> Collection<T> synchronizedCollection(Collection<T> c) //返回指定列表支持的同步(线程安全的)列表 static <T> List<T> synchronizedList(List<T> list) //返回由指定映射支持的同步(线程安全的)映射 static <K,V> Map<K,V> synchronizedMap(Map<K,V> m) //返回指定 set 支持的同步(线程安全的)set static <T> Set<T> synchronizedSet(Set<T> s)
5、Collection设置不可变集合
//返回一个空的、不可变的集合对象,此处的集合既可以是List,也可以是Set,还可以是Map。 emptyXxx() //返回一个只包含指定对象(只有一个或一个元素)的不可变的集合对象,此处的集合可以是:List,Set,Map。 singletonXxx(): //返回指定集合对象的不可变视图,此处的集合可以是:List,Set,Map unmodifiableXxx()
推荐学习:《java教程》
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!