
Maison >Opération et maintenance >exploitation et maintenance Linux >qu'est-ce que le swap Linux
qu'est-ce que le swap Linux

- 青灯夜游original
- 2022-02-24 13:57:3312793parcourir
Le swap Linux fait référence à la partition de swap Linux, qui est une zone du disque. Il peut s'agir d'une partition, d'un fichier ou d'une combinaison des deux ; le swap est similaire à la mémoire virtuelle de Windows, c'est-à-dire lorsque la mémoire. est insuffisante, virtualisez une partie de l'espace disque dur en mémoire pour résoudre le problème de capacité mémoire insuffisante.

L'environnement d'exploitation de ce tutoriel : système linux5.9.8, ordinateur Dell G3.
linux swap
La partition d'échange Linux (swap), ou espace de remplacement de mémoire (espace d'échange), est une zone du disque, qui peut être une partition, un fichier ou leur combinaison.
Fonctions SWAP similaires à la "mémoire virtuelle" sous le système Windows. Lorsque la mémoire physique est insuffisante, une partie de l'espace disque dur est utilisée comme partition SWAP (virtuellement convertie en mémoire) pour résoudre le problème de capacité mémoire insuffisante.
SWAP signifie swap. Comme son nom l'indique, lorsqu'un processus demande de la mémoire au système d'exploitation et constate qu'elle est insuffisante, le système d'exploitation échange les données temporairement inutilisées dans la mémoire et les place dans la partition SWAP. ÉCHANGEZ. Lorsqu'un processus a besoin de ces données et que le système d'exploitation constate qu'il y a de la mémoire physique libre, il échange les données de la partition SWAP vers la mémoire physique. Ce processus est appelé SWAP IN.
Bien sûr, il existe une limite supérieure à la taille du swap. Une fois le swap épuisé, le système d'exploitation déclenchera le mécanisme OOM-Killer pour tuer le processus qui consomme le plus de mémoire afin de libérer de la mémoire.
Pourquoi le système de base de données n'aime-t-il pas le swap ?
De toute évidence, l'intention initiale du mécanisme d'échange est d'atténuer l'embarras lié au manque de mémoire physique et de rendre directement difficile le processus MOO. Mais franchement, presque toutes les bases de données n'aiment pas le swap, que ce soit MySQL, Oracal, MongoDB ou HBase. Pourquoi ? Ceci est principalement lié aux deux aspects suivants :
1. Les systèmes de bases de données sont généralement sensibles aux délais de réponse. Si le swap est utilisé à la place de la mémoire, les performances du service de base de données seront inévitablement inacceptables. Pour les systèmes extrêmement sensibles aux délais de réponse, il n'y a pas de différence entre un retard trop important et une indisponibilité du service. Ce qui est plus grave que l'indisponibilité du service, c'est que le processus ne s'arrêtera pas dans le scénario d'échange, ce qui signifie que le système a toujours été indisponible. ... Pensez-y à nouveau. Est-ce un meilleur choix de oom directement sans utiliser de swap ? De cette façon, de nombreux systèmes à haute disponibilité basculeront directement entre maître et esclave, et les utilisateurs n'en seront pratiquement pas conscients.
2. De plus, pour les systèmes distribués tels que HBase, nous ne nous inquiétons pas réellement de la panne d'un certain nœud, mais nous craignons qu'un certain nœud soit bloqué. Si un nœud tombe en panne, tout au plus un petit nombre de requêtes seront temporairement indisponibles et pourront être récupérées en réessayant. Cependant, si un nœud est bloqué, toutes les requêtes distribuées seront bloquées et les ressources des threads côté serveur seront occupées, entraînant le blocage de l'intégralité de la requête du cluster, et même le cluster sera arrêté.
Considérant ces deux perspectives, il est logique que toutes les bases de données n'aiment pas le swap !
Le mécanisme de fonctionnement du swap
Étant donné que les bases de données n'aiment pas le swap, est-il nécessaire d'utiliser la commande swapoff pour désactiver la fonction de cache disque ? Non, vous pouvez y réfléchir, que signifie désactiver le cache disque ? Aucun système dans l’environnement de production actuel ne sera aussi radical. Il faut savoir que le monde n’est jamais ni 0 ni 1. Tout le monde choisira plus ou moins de marcher au milieu, mais certains sont orientés vers 0 et d’autres vers 1. Évidemment, lorsqu'il s'agit de swap, la base de données doit choisir de l'utiliser le moins possible. Plusieurs exigences dans les documents officiels de HBase visent en fait à mettre en œuvre cette politique : réduire autant que possible l'impact du swap. Ce n'est qu'en vous connaissant et en connaissant votre ennemi que vous pourrez gagner chaque bataille. Pour réduire l'impact du swap, vous devez comprendre comment fonctionne le recyclage de la mémoire Linux, afin de ne manquer aucun doute possible.
Voyons d'abord comment le swap est déclenché ?
Pour faire simple, Linux déclenchera le recyclage de la mémoire dans deux scénarios. L'un est que le recyclage de la mémoire sera déclenché immédiatement lorsqu'il s'avère qu'il n'y a pas assez de mémoire libre lors de l'allocation de mémoire. L'autre est qu'il s'agit d'un processus démon (swapd) ; (processus) est démarré. Vérifie en permanence la mémoire système et déclenche activement la récupération de la mémoire une fois que la mémoire disponible atteint un seuil spécifique. Il n'y a rien à dire sur le premier scénario. Concentrons-nous sur le deuxième scénario, comme le montre la figure ci-dessous :

Voici le premier paramètre qui nous préoccupe : vm.min_free_kbytes, qui représente la mémoire libre. réservé par le système. Le filigrane minimum [min] et affecte le filigrane [bas] et le filigrane [élevé]. Cela peut être simplement considéré comme :
watermark[min] = min_free_kbytes watermark[low] = watermark[min] * 5 / 4 = min_free_kbytes * 5 / 4 watermark[high] = watermark[min] * 3 / 2 = min_free_kbytes * 3 / 2 watermark[high] - watermark[low] = watermark[low] - watermark[min] = min_free_kbytes / 4
On voit que ces niveaux d'eau de LInux sont indissociables du paramètre min_free_kbytes. L'importance de min_free_kbytes pour le système va de soi. Il ne peut pas être trop grand ou trop petit.
Si min_free_kbytes est trop petit, le tampon de niveau d'eau entre [min, low] sera très petit Pendant le processus de recyclage kswapd, une fois que la couche supérieure demande de la mémoire trop rapidement (application typique : base de données), la mémoire libre diminuera facilement. . sous watermark[min], à ce moment-là, le noyau effectuera une récupération directe, récupérera directement dans le contexte de processus de l'application, puis utilisera les pages libres récupérées pour satisfaire la demande de mémoire, il bloquera donc l'application et y provoquera Il y aura un certain délai de réponse. Bien sûr, min_free_kbytes ne doit pas être trop grand. D'une part, s'il est trop grand, cela réduira la mémoire du processus d'application et gaspillera les ressources mémoire du système. D'autre part, cela entraînera également une consommation du processus kswapd. beaucoup de temps sur le recyclage de la mémoire. Regardez à nouveau ce processus. Est-il similaire au mécanisme de déclenchement de recyclage d'ancienne génération dans l'algorithme CMS du mécanisme de récupération de place Java, n'est-ce pas ? Le document officiel exige que min_free_kbytes ne puisse pas être inférieur à 1 Go (fixé à 8 Go dans les systèmes à grande mémoire), c'est-à-dire qu'il ne déclenche pas facilement un recyclage direct.
Jusqu'à présent, le mécanisme de déclenchement du recyclage de mémoire de Linux et le premier paramètre vm.min_free_kbytes qui nous préoccupe ont été essentiellement expliqués. Examinons ensuite brièvement ce que recycle le recyclage de la mémoire Linux. Les objets de recyclage de mémoire Linux sont principalement divisés en deux types :
1. Cache de fichiers, ceci est facile à comprendre. Afin d'éviter que les données des fichiers ne soient lues à chaque fois sur le disque dur, le système stockera les données des points d'accès dans la mémoire. pour améliorer les performances. Si vous lisez uniquement le fichier, le recyclage de la mémoire n'a besoin que de libérer cette partie de la mémoire. La prochaine fois que vous lirez les données du fichier, vous pourrez les lire directement à partir du disque dur (similaire au cache de fichiers HBase). Si les fichiers sont non seulement lus, mais que les données du fichier mis en cache sont également modifiées (données sales), pour recycler la mémoire, cette partie du fichier de données doit être écrite sur le disque dur puis libérée (similaire au fichier MySQL). cache).
2. Mémoire anonyme, cette partie de la mémoire n'a pas de support réel, contrairement au cache de fichiers qui a un support tel que les fichiers du disque dur, tels que les données typiques du tas et de la pile. Cette partie de la mémoire ne peut pas être directement libérée ou réécrite sur un support de type fichier lors du recyclage. C'est pourquoi le mécanisme d'échange a été développé pour échanger ce type de mémoire sur le disque dur et le recharger en cas de besoin.
L'algorithme spécifique utilisé par Linux pour déterminer quels caches de fichiers ou mémoire anonyme doivent être recyclés n'est pas concerné ici. Si vous êtes intéressé, vous pouvez vous y référer ici. Mais il y a une question à laquelle nous devons réfléchir : puisqu’il existe deux types de mémoire qui peuvent être recyclés, comment Linux décide-t-il quel type de mémoire recycler alors que les deux types de mémoire peuvent être recyclés ? Ou les deux seront-ils recyclés ? Cela nous amène au deuxième paramètre qui nous intéresse : swappiness. Cette valeur est utilisée pour définir l'activité avec laquelle le noyau utilise le swap. Plus la valeur est élevée, plus le noyau utilisera activement le swap. Positivité. La valeur est comprise entre 0 et 100 et la valeur par défaut est 60. Comment cet échange est-il réalisé ? Le principe spécifique est très compliqué. Pour le dire simplement, le swappiness obtient cet effet en contrôlant si davantage de pages anonymes sont recyclées ou si davantage de caches de fichiers sont recyclés lors du recyclage de la mémoire. swappiness est égal à 100, ce qui signifie que la mémoire anonyme et le cache de fichiers seront recyclés avec la même priorité. La valeur par défaut de 60 signifie que le cache de fichiers sera recyclé en premier. Quant à savoir pourquoi le cache de fichiers doit être recyclé en premier, vous pourriez aussi bien le faire. réfléchissez-y (la situation habituelle du recyclage du cache de fichiers ne provoquera pas d'opérations d'E/S et a peu d'impact sur les performances du système). Pour les bases de données, le swap doit être évité autant que possible, il doit donc être défini sur 0. Il convient de noter ici que le mettre à 0 ne signifie pas que le swap n'est pas exécuté !
Jusqu'à présent, nous avons parlé du mécanisme de déclenchement du recyclage de la mémoire Linux, des objets de recyclage de la mémoire Linux et du swap, et avons expliqué les paramètres min_free_kbytes et swappiness. Examinons ensuite un autre paramètre lié au swap : zone_reclaim_mode. Le document indique que définir ce paramètre sur 0 peut désactiver la récupération de zone de NUMA. En ce qui concerne NUMA, les bases de données ne sont plus satisfaites. De nombreux administrateurs de base de données ont été trompés. Voici donc trois petites questions : Qu’est-ce que NUMA ? Quelle est la relation entre NUMA et swap ? Quelle est la signification spécifique de zone_reclaim_mode ?
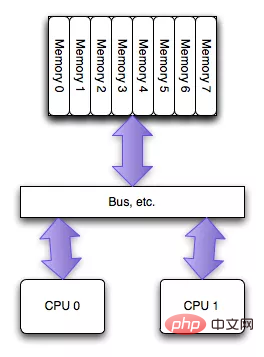
NUMA (Non-Uniform Memory Access) est relatif à UMA. Les deux sont des architectures de conception de processeur. Les premiers processeurs ont été conçus comme des structures UMA, comme le montre l'image ci-dessous (images provenant d'Internet) :
Pour To. Pour atténuer le problème de goulot d'étranglement des canaux rencontré par les processeurs multicœurs lisant la même mémoire, les ingénieurs en puces ont conçu une structure NUMA, comme le montre la figure ci-dessous (photo d'Internet) :
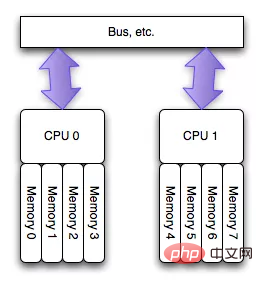
Cette architecture peut bien résoudre le problème de l'UMA, c'est-à-dire que différents CPU ont des zones de mémoire exclusives. Afin d'obtenir une "isolation mémoire" entre les CPU, deux points d'appui au niveau logiciel sont nécessaires :
1. 内存分配需要在请求线程当前所处CPU的专属内存区域进行分配。如果分配到其他CPU专属内存区,势必隔离性会受到一定影响,并且跨越总线的内存访问性能必然会有一定程度降低。
2. 另外,一旦local内存(专属内存)不够用,优先淘汰local内存中的内存页,而不是去查看远程内存区是否会有空闲内存借用。
这样实现,隔离性确实好了,但问题也来了:NUMA这种特性可能会导致CPU内存使用不均衡,部分CPU专属内存不够使用,频繁需要回收,进而可能发生大量swap,系统响应延迟会严重抖动。而与此同时其他部分CPU专属内存可能都很空闲。这就会产生一种怪现象:使用free命令查看当前系统还有部分空闲物理内存,系统却不断发生swap,导致某些应用性能急剧下降。见叶金荣老师的MySQL案例分析:《找到MySQL服务器发生SWAP罪魁祸首》。
所以,对于小内存应用来讲,NUMA所带来的这种问题并不突出,相反,local内存所带来的性能提升相当可观。但是对于数据库这类内存大户来说,NUMA默认策略所带来的稳定性隐患是不可接受的。因此数据库们都强烈要求对NUMA的默认策略进行改进,有两个方面可以进行改进:
1. 将内存分配策略由默认的亲和模式改为interleave模式,即会将内存page打散分配到不同的CPU zone中。通过这种方式解决内存可能分布不均的问题,一定程度上缓解上述案例中的诡异问题。对于MongoDB来说,在启动的时候就会提示使用interleave内存分配策略:
WARNING: You are running on a NUMA machine. We suggest launching mongod like this to avoid performance problems: numactl –interleave=all mongod [other options]
2. 改进内存回收策略:此处终于请出今天的第三个主角参数zone_reclaim_mode,这个参数定义了NUMA架构下不同的内存回收策略,可以取值0/1/3/4,其中0表示在local内存不够用的情况下可以去其他的内存区域分配内存;1表示在local内存不够用的情况下本地先回收再分配;3表示本地回收尽可能先回收文件缓存对象;4表示本地回收优先使用swap回收匿名内存。可见,HBase推荐配置zone_reclaim_mode=0一定程度上降低了swap发生的概率。
不都是swap的事
至此,我们探讨了三个与swap相关的系统参数,并且围绕Linux系统内存分配、swap以及NUMA等知识点对这三个参数进行了深入解读。除此之外,对于数据库系统来说,还有两个非常重要的参数需要特别关注:
1. IO调度策略:这个话题网上有很多解释,在此并不打算详述,只给出结果。通常对于sata盘的OLTP数据库来说,deadline算法调度策略是最优的选择。
2. THP(transparent huge pages)特性关闭。THP特性笔者曾经疑惑过很久,主要疑惑点有两点,其一是THP和HugePage是不是一回事,其二是HBase为什么要求关闭THP。经过前前后后多次查阅相关文档,终于找到一些蛛丝马迹。这里分四个小点来解释THP特性:
(1)什么是HugePage?
网上对HugePage的解释有很多,大家可以检索阅读。简单来说,计算机内存是通过表映射(内存索引表)的方式进行内存寻址,目前系统内存以4KB为一个页,作为内存寻址的最小单元。随着内存不断增大,内存索引表的大小将会不断增大。一台256G内存的机器,如果使用4KB小页, 仅索引表大小就要4G左右。要知道这个索引表是必须装在内存的,而且是在CPU内存,太大就会发生大量miss,内存寻址性能就会下降。
HugePage就是为了解决这个问题,HugePage使用2MB大小的大页代替传统小页来管理内存,这样内存索引表大小就可以控制的很小,进而全部装在CPU内存,防止出现miss。
(2)什么是THP(Transparent Huge Pages)?
HugePage是一种大页理论,那具体怎么使用HugePage特性呢?目前系统提供了两种使用方式,其一称为Static Huge Pages,另一种就是Transparent Huge Pages。前者根据名称就可以知道是一种静态管理策略,需要用户自己根据系统内存大小手动配置大页个数,这样在系统启动的时候就会生成对应个数的大页,后续将不再改变。而Transparent Huge Pages是一种动态管理策略,它会在运行期动态分配大页给应用,并对这些大页进行管理,对用户来说完全透明,不需要进行任何配置。另外,目前THP只针对匿名内存区域。
(3)HBase(数据库)为什么要求关闭THP特性?
THP est une stratégie de gestion dynamique qui alloue et gère des pages volumineuses pendant l'exécution. Il y aura donc un certain degré de retard d'allocation, ce qui est inacceptable pour les systèmes de bases de données qui recherchent des délais de réponse. De plus, THP présente de nombreux autres inconvénients. Vous pouvez vous référer à cet article "pourquoi-tokudb-hates-transparent-hugepages"
(4) Quel est l'impact de l'activation/désactivation de THP sur les performances de lecture et d'écriture de HBase ?
Afin de vérifier l'impact de l'activation et de la désactivation de THP sur les performances de HBase, j'ai effectué un test simple dans l'environnement de test : le cluster de test n'a qu'un seul RegionServer et la charge de test est un rapport lecture-écriture de 1:1. . THP propose deux options : toujours et jamais dans certains systèmes, et une option supplémentaire appelée madvise dans certains systèmes. Vous pouvez utiliser la commande echo never/always > /sys/kernel/mm/transparent_hugepage/enabled pour désactiver/activer THP. Les résultats des tests sont présentés dans la figure ci-dessous :

Comme le montre la figure ci-dessus, dans le scénario d'arrêt de TPH (jamais), HBase a les meilleures performances et est relativement stable. Dans la scène où THP est activé (toujours), les performances chutent d'environ 30 % par rapport à la scène où THP est désactivé, et la courbe tremble considérablement. On peut voir que n'oubliez pas de désactiver THP en ligne dans HBase.
Recommandations associées : "Tutoriel vidéo Linux"
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!