
Maison >Opération et maintenance >Docker >Quelles ressources Docker isole
Quelles ressources Docker isole

- 青灯夜游original
- 2022-01-28 15:35:514452parcourir
Docker isole les ressources : 1. Système de fichiers ; 2. Réseau ; 3. Communication entre les processus ; 4. Utilisateurs et groupes d'utilisateurs pour les autorisations ; 5. PID au sein du processus et PID de l'hôte 6, nom d'hôte et nom de domaine, etc.

L'environnement d'exploitation de ce tutoriel : système linux5.9.8, version docker-1.13.1, ordinateur Dell G3.
L'essence d'un conteneur Docker
L'essence d'un conteneur Docker est un processus sur l'hôte.
Docker implémente l'isolation des ressources via namespace, la limitation des ressources via cgroups et des opérations de fichiers efficaces via la *copie sur écriture*.
Mécanisme d'espace de noms Linux
Le mécanisme d'espace de noms fournit une solution d'isolation des ressources.
Les ressources PID, IPC, réseau et autres ressources système ne sont plus globales, mais appartiennent à un espace de noms spécifique.
Les ressources sous chaque espace de noms sont transparentes et invisibles pour les ressources sous d'autres espaces de noms.
L'un des principaux objectifs de l'espace de noms implémentant le noyau Linux est d'implémenter des services de virtualisation légers (conteneur). Les processus dans le même espace de noms peuvent percevoir les changements les uns des autres et ne rien savoir des processus externes pour atteindre l'objectif d'indépendance et d'isolement.
Ce qui peut être isolé par espace de noms
Si un conteneur n'interfère pas avec d'autres conteneurs, il doit pouvoir :
Le système de fichiers doit être isolé
Le réseau a également besoin être isolé
La communication inter-processus doit également être isolée
Pour les autorisations, les utilisateurs et les groupes d'utilisateurs doivent également être isolés
Le PID au sein du processus doit également être isolé du PID dans l'hôte
Le conteneur doit également avoir son propre nom d'hôte
Avec l'isolement ci-dessus, nous pensons qu'un conteneur peut être isolé de l'hôte et des autres conteneurs.
Il arrive que l'espace de noms Linux puisse faire cela.
| espace de noms | Contenu isolé | Paramètres d'appel système |
|---|---|---|
| UTS | Nom d'hôte et nom de domaine | CLONE_NEWUTS |
| IPC | Sémaphore, file d'attente de messages et mémoire partagée | CLONE_NEWIPC |
| Réseau | Périphériques réseau, piles réseau, ports, etc. | CLONE_NEWNET |
| PID | Numéro de processus | CLONE_NEWPID |
| Mount | Point de montage (système de fichiers) | CLONE_NEWNS |
| Utilisateur | Utilisateurs et groupes d'utilisateurs | CLONE_NEWUSER |
Espace de noms UTS
L'espace de noms UTS (UNIX TIme-sharing System) permet d'isoler l'hôte et le nom de domaine, de sorte que chaque conteneur Docker puisse avoir un nom d'hôte et un nom de domaine indépendants et puisse être considéré comme un nœud indépendant sur le réseau. . plutôt qu'un processus sur la machine hôte.
Dans Docker, chaque image est essentiellement nommée nom d'hôte d'après le nom du service qu'elle fournit, et n'aura aucun impact sur l'hôte.
Espace de noms IPC
Les ressources IPC conçues par Inter-Process Communication (IPC) comprennent des sémaphores communs, des files d'attente de messages et une mémoire partagée.
Lorsque vous postulez pour des ressources IPC, vous demandez un identifiant 32 bits unique au monde.
L'espace de noms IPC contient l'identifiant IPC du système et le système de fichiers qui implémente la file d'attente de messages POSIX.
Les processus dans le même espace de noms IPC sont visibles les uns aux autres, mais les processus dans des espaces de noms différents sont invisibles les uns aux autres.
Espace de noms PID
L'isolation de l'espace de noms PID est très pratique. Elle renumérote le PID du processus, c'est-à-dire que les processus sous deux espaces de noms différents peuvent avoir le même PID, et chaque espace de noms PID a son propre programme de comptage.
Le noyau maintient une structure arborescente pour tous les espaces de noms PID. Le niveau supérieur est créé lorsque le système est initialisé et est appelé espace de noms racine. L'espace de noms PID nouvellement créé est appelé espace de noms enfant, et l'espace de noms PID d'origine est l'espace de noms enfant de l'espace de noms PID nouvellement créé, et l'espace de noms PID d'origine est l'espace de noms parent de l'espace de noms PID nouvellement créé.
De cette façon, différents espaces de noms PID formeront un système hiérarchique. Le nœud parent auquel ils appartiennent peut voir les processus dans les nœuds enfants et peut affecter les processus dans les nœuds enfants via des signaux et d'autres méthodes. Cependant, le nœud enfant ne peut rien voir dans l'espace de noms PID du nœud parent.
espace de noms de montage
l'espace de noms de montage prend en charge l'isolation des systèmes de fichiers en isolant les points de montage du système de fichiers.
Après l'isolement, les modifications apportées aux structures de fichiers dans différents espaces de noms de montage ne s'affecteront pas les unes les autres.
espace de noms réseau
l'espace de noms réseau fournit principalement l'isolation des ressources réseau, y compris l'équipement réseau, IPv4, la pile de protocoles IPv6, la table de routage IP, le pare-feu, le répertoire /proc/net, le répertoire /sys/class/net, la suite Recevoir des mots etc.
espace de noms utilisateur
l'espace de noms utilisateur isole les identifiants et les attributs liés à l'installation
opérations d'espace de noms
L'API d'espace de noms comprend clone() setns() unshare() et des parties sous /proc File
Afin de déterminer quels espaces de noms doivent être isolés, vous devez spécifier un ou plusieurs des 6 paramètres suivants pour les séparer. Les 6 paramètres sont CLONE_NEWUTS, CLONE_NEWIPC, CLONE_NEWPID, CLONE_NEWNET, CLONE_NEWUSER mentionnés dans le tableau ci-dessus
clone()
Utiliser clone() pour créer un processus avec un espace de noms indépendant est la méthode la plus courante, et c'est également. l'espace de noms utilisé par Docker. La méthode la plus basique.
int clone(int(*child_func)(void *),void *child_stack,int flags, void *arg);
clone() est une implémentation plus générale de l'appel système Linux fork(). Vous pouvez contrôler le nombre de fonctions utilisées via des indicateurs.
Il existe plus de 20 types d'indicateurs CLONE_*, qui contrôlent tous les aspects du processus de clonage.
- child_func passe dans la fonction principale du programme exécuté par le processus enfant
- child_stack passe dans l'espace de pile utilisé par le processus enfant
- flags identifie les indicateurs CLONE_* utilisés Ceux liés à l'espace de noms sont principalement les 6. mentionné ci-dessus.
- args sont utilisés pour transmettre les paramètres utilisateur
/proc/[pid]/ns
Les utilisateurs peuvent voir les fichiers pointant vers différents espaces de noms sous le fichier /proc/[pid]/ns.
ls -l /proc/10/ns
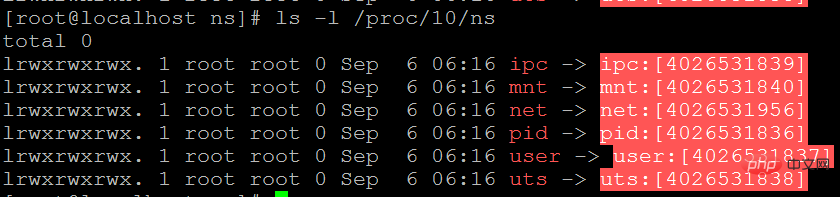
Le numéro d'espace de noms entre crochets
Si les numéros d'espace de noms pointés par deux processus sont les mêmes, cela signifie qu'ils sont dans le même espace de noms
Le but de la définition du lien est que même si tous les processus sous l'espace de noms ont Lorsqu'il se termine, cet espace de noms existera toujours et les processus suivants pourront y participer.
Le montage du fichier de répertoire /proc/[pid]/ns à l'aide de la méthode --bind peut également fonctionner comme un lien
touch ~/utsmount --bind /proc/10/ns/uts ~/uts
setns()
Utilisez la commande docker exec dans Docker pour exécuter une nouvelle commande sur un fichier déjà commande en cours d'exécution La commande nécessite l'utilisation de setns().
Grâce à l'appel système setns(), le processus rejoint un espace de noms existant à partir de l'espace de noms d'origine
Habituellement, afin de ne pas affecter l'appelant du processus et pour que l'espace de noms pid nouvellement ajouté prenne effet, il sera utilisé après l'appel setns( ) est exécutée. clone() crée un processus enfant pour continuer à exécuter la commande, permettant ainsi au processus d'origine de terminer son exécution.
int setns(int fd, in nstype); #fd 表示要加入namespace的文件描述符。是一个指向/proc/[pid]/ns目录的文件描述符,打开目录链接可以获得 #nstype 调用者可以检查fd指向的namespace类型是否符合实际要求,该参数为0则不检查
Afin d'utiliser l'espace de noms nouvellement ajouté, il est nécessaire d'introduire la série de fonctions execve(), qui peuvent exécuter des commandes utilisateur. La plus couramment utilisée est d'appeler /bin/bash et d'accepter les paramètres
. unshare()
via unshare() Isolation de l'espace de noms sur le processus d'origine
Unshare est très similaire au clone Unshare n'a pas besoin de démarrer un nouveau processus et peut être utilisé sur le processus d'origine.
docker n'utilise pas l'appel système
fork()
fork n'appartient pas à l'API de l'espace de noms
Cgroups d'outil de noyau puissant
cgroups est un mécanisme fourni par le noyau Linux. Ce mécanisme peut intégrer (ou séparer) une série de tâches système et leurs sous-tâches en différents groupes hiérarchisés par ressources en fonction des besoins, fournissant ainsi une gestion des ressources système fournissant un cadre unifié.
cgroups est un autre outil puissant du noyau sous Linux. Avec les cgroups, vous pouvez non seulement limiter les ressources isolées par espace de noms, mais également définir des pondérations pour les ressources, calculer l'utilisation, contrôler le démarrage et l'arrêt des tâches (processus ou comtés), etc. Pour parler franchement : les groupes de contrôle peuvent limiter et enregistrer les ressources physiques (y compris le processeur, la mémoire, les E/S, etc.) utilisées par les groupes de tâches. C'est la pierre angulaire de la construction d'une série d'outils de gestion de virtualisation tels que Docker.
Le rôle des groupes de contrôle
cgroups fournit une interface unifiée pour la gestion des ressources à différents niveaux d'utilisateurs, du contrôle des ressources individuelles à la virtualisation au niveau du système d'exploitation, les groupes de contrôle fournissent 4 fonctions principales.
- Limitation des ressources
- cgroups peut limiter le total des ressources utilisées par les tâches.
- Si vous définissez la limite supérieure de mémoire utilisée par l'application lors de son exécution, une invite MOO sera émise une fois le quota dépassé
- cgroups peut limiter le total des ressources utilisées par les tâches.
- Allocation de priorité
- Grâce au nombre alloué de tranches de temps CPU et de disque Taille de la bande passante IO, elle équivaut en fait à contrôler la priorité de l'exécution des tâches
- Statistiques des ressources
- les groupes de cgroups peuvent compter l'utilisation des ressources du système
- telles que le temps d'utilisation du processeur, l'utilisation de la mémoire, etc. Cette fonction est très adaptée à la facturation
- les groupes de cgroups peuvent compter l'utilisation des ressources du système
- contrôle des tâches
- les groupes de contrôle peuvent suspendre et reprendre des tâches
Apprentissage recommandé : "Tutoriel vidéo Docker"
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quelle est la différence entre arg et env dans docker
- Quelle est la différence entre l'installation Docker de MySQL et l'installation directe ?
- Quelle est la différence entre jvm et docker
- Quelle est la différence entre docker et openvz
- Quelle est la différence entre exécuter et démarrer dans Docker
- Que sont Docker et Jenkins