
Maison >base de données >tutoriel mysql >Compréhension approfondie des principes MySQL : pool de tampons (explication graphique et textuelle détaillée)
Compréhension approfondie des principes MySQL : pool de tampons (explication graphique et textuelle détaillée)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-01-18 16:52:203719parcourir
Cet article vous apporte des connaissances pertinentes sur le pool de tampons dans MySQL, y compris les pages de données, les listes liées sans page de cache, les listes liées vides, les morceaux de liste liée LRU, etc. J'espère qu'il vous sera utile.

L'importance de la mise en cache
Grâce aux discussions précédentes, nous savons que pour les tables qui utilisent InnoDB comme moteur de stockage, peu importe qu'il s'agisse d'un index utilisé pour stocker les données utilisateur (y compris le clustering Les index et index secondaires), ou diverses données système, sont stockés dans l'espace table sous la forme de pages, et dans ce que l'on appelle espace table code> n'est rien de plus que l'abstraction par InnoDB d'un ou plusieurs fichiers réels sur le système de fichiers, ce qui signifie que nos données sont toujours stockées sur le disque après tout. Mais tout le monde sait aussi que la vitesse d'un disque est aussi lente qu'une tortue. Comment peut-il être digne d'un CPU « rapide comme le vent et aussi rapide que l'électricité » ? Par conséquent, lorsque le moteur de stockage InnoDB traite la demande du client, lorsqu'il a besoin d'accéder aux données d'une certaine page, il chargera toutes les données de la page complète dans la mémoire. même si nous n'avons besoin d'accéder qu'à un seul enregistrement par page, les données de la page entière doivent d'abord être chargées en mémoire. Après avoir chargé la page entière en mémoire, vous pouvez effectuer un accès en lecture et en écriture. Après avoir terminé l'accès en lecture et en écriture, vous n'êtes pas pressé de libérer l'espace mémoire correspondant à la page, mais de la mettre en cache. . De cette façon, lorsqu'il y aura une demande d'accès à la page à nouveau dans le futur, la surcharge du disque IO peut être économisée. InnoDB作为存储引擎的表来说,不管是用于存储用户数据的索引(包括聚簇索引和二级索引),还是各种系统数据,都是以页的形式存放在表空间中的,而所谓的表空间只不过是InnoDB对文件系统上一个或几个实际文件的抽象,也就是说我们的数据说到底还是存储在磁盘上的。但是各位也都知道,磁盘的速度慢的跟乌龟一样,怎么能配得上“快如风,疾如电”的CPU呢?所以InnoDB存储引擎在处理客户端的请求时,当需要访问某个页的数据时,就会把完整的页的数据全部加载到内存中,也就是说即使我们只需要访问一个页的一条记录,那也需要先把整个页的数据加载到内存中。将整个页加载到内存中后就可以进行读写访问了,在进行完读写访问之后并不着急把该页对应的内存空间释放掉,而是将其缓存起来,这样将来有请求再次访问该页面时,就可以省去磁盘IO的开销了。
InnoDB的Buffer Pool
啥是个Buffer Pool
设计InnoDB的大叔为了缓存磁盘中的页,在MySQL服务器启动的时候就向操作系统申请了一片连续的内存,他们给这片内存起了个名,叫做Buffer Pool(中文名是缓冲池)。那它有多大呢?这个其实看我们机器的配置,如果你是土豪,你有512G内存,你分配个几百G作为Buffer Pool也可以啊,当然你要是没那么有钱,设置小点也行呀~ 默认情况下Buffer Pool只有128M大小。当然如果你嫌弃这个128M太大或者太小,可以在启动服务器的时候配置innodb_buffer_pool_size参数的值,它表示Buffer Pool的大小,就像这样:
[server] innodb_buffer_pool_size = 268435456
其中,268435456的单位是字节,也就是我指定Buffer Pool的大小为256M。需要注意的是,Buffer Pool也不能太小,最小值为5M(当小于该值时会自动设置成5M)。
Buffer Pool内部组成
Buffer Pool中默认的缓存页大小和在磁盘上默认的页大小是一样的,都是16KB。为了更好的管理这些在Buffer Pool中的缓存页,设计InnoDB的大叔为每一个缓存页都创建了一些所谓的控制信息,这些控制信息包括该页所属的表空间编号、页号、缓存页在Buffer Pool中的地址、链表节点信息、一些锁信息以及LSN信息(锁和LSN我们之后会具体唠叨,现在可以先忽略),当然还有一些别的控制信息,我们这就不全唠叨一遍了,挑重要的说嘛~
每个缓存页对应的控制信息占用的内存大小是相同的,我们就把每个页对应的控制信息占用的一块内存称为一个控制块吧,控制块和缓存页是一一对应的,它们都被存放到 Buffer Pool 中,其中控制块被存放到 Buffer Pool 的前边,缓存页被存放到 Buffer Pool 后边,所以整个Buffer Pool对应的内存空间看起来就是这样的:
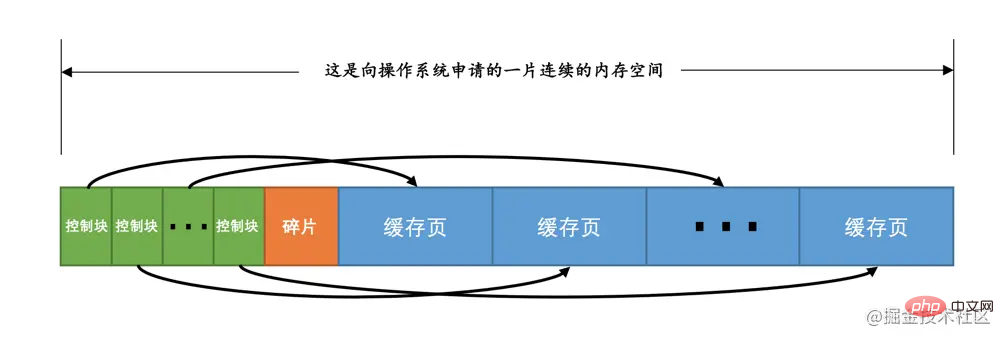
咦?控制块和缓存页之间的那个碎片是个什么玩意儿?你想想啊,每一个控制块都对应一个缓存页,那在分配足够多的控制块和缓存页后,可能剩余的那点儿空间不够一对控制块和缓存页的大小,自然就用不到喽,这个用不到的那点儿内存空间就被称为碎片了。当然,如果你把Buffer Pool的大小设置的刚刚好的话,也可能不会产生碎片
Qu'est-ce qu'un Buffer Pool
🎜L'oncle qui a conçuInnoDB afin de mettre en cache les pages du disque, dans MySQLLorsque le serveur a démarré, il a demandé un morceau de mémoire continue au système d'exploitation. Ils ont donné à cette mémoire un nom, appelé Buffer Pool (le nom chinois est . Pool de tampons >). Alors, quelle est sa taille ? Cela dépend en fait de la configuration de notre machine. Si vous êtes riche et disposez de 512G de mémoire, vous pouvez allouer quelques centaines de Go comme Buffer Pool. Je n'ai pas ça. Si vous avez de l'argent, vous pouvez le réduire. ~ Par défaut, le Buffer Pool n'a qu'une taille de 128 M. Bien entendu, si vous n'aimez pas que ce 128M soit trop grand ou trop petit, vous pouvez configurer la valeur du paramètre innodb_buffer_pool_size au démarrage du serveur, qui représente le Buffer Pool La taille est comme ceci : 🎜mysql> SHOW VARIABLES LIKE 'innodb_old_blocks_pct'; +-----------------------+-------+ | Variable_name | Value | +-----------------------+-------+ | innodb_old_blocks_pct | 37 | +-----------------------+-------+ 1 row in set (0.01 sec)🎜 Parmi eux, l'unité de
268435456 est l'octet, c'est-à-dire que j'ai spécifié la taille du Buffer Pool à 256M. Il convient de noter que le Buffer Pool ne peut pas être trop petit. La valeur minimale est 5M (lorsqu'elle est inférieure à cette valeur, elle sera automatiquement définie sur 5M). ). 🎜Composition interne du pool de tampons
🎜La taille de page de cache par défaut dansBuffer Pool est la même que la taille de page par défaut sur le disque, les deux sont 16 Ko. Afin de mieux gérer ces pages de cache dans Buffer Pool, l'oncle qui a conçu InnoDB a créé ce que l'on appelle des informations de contrôle pour chaque page de cache. code>, ces informations de contrôle incluent le numéro d'espace table, le numéro de page, l'adresse de la page de cache dans le Buffer Pool, les informations de nœud de liste chaînée, certaines informations de verrouillage et les informations LSN (verrous et LSN dont nous parlerons en détail plus tard, vous pouvez l'ignorer pour l'instant), et bien sûr quelques autres informations de contrôle, nous n'en parlerons pas toutes ici, choisissons les plus importantes~🎜 🎜 Les informations de contrôle correspondant à chaque page de cache occupent la même taille de mémoire. Appelons la mémoire occupée par les informations de contrôle correspondant à chaque page un bloc de contrôle. -one correspondance.Ils sont tous stockés dans le Buffer Pool. Le bloc de contrôle est stocké devant le Buffer Pool, et la page de cache est stockée à l'arrière du Buffer Pool. Par conséquent, l'espace mémoire correspondant à l'intégralité du fragmentation. Bien sûr, si vous définissez correctement la taille du Buffer Pool, les fragments risquent de ne pas être générés~🎜
Conseils : Chaque bloc de contrôle occupe environ 5 % de la taille de la page du cache. Dans la version de MySQL 5.7.21, la taille de chaque bloc de contrôle est de 808 octets. Le innodb_buffer_pool_size que nous avons défini n'inclut pas l'espace mémoire occupé par cette partie du bloc de contrôle, c'est-à-dire que lorsque InnoDB demande un espace mémoire continu au système d'exploitation pour le pool de tampons, cet espace mémoire continu sera généralement 5 plus grand que. la valeur de innodb_buffer_pool_size %about.
Gestion gratuite des listes chaînées
Lorsque nous démarrons pour la première fois le serveur MySQL, nous devons terminer le processus d'initialisation du Buffer Pool, qui doit d'abord s'appliquer à le système d'exploitationBuffer Pool est ensuite divisé en plusieurs paires de blocs de contrôle et de pages de cache. Cependant, aucune page de disque réelle n'est mise en cache dans Buffer Pool pour le moment (car elles n'ont pas encore été utilisées. Plus tard, au fur et à mesure de l'exécution du programme, les pages du disque continueront à être mises en cache dans >Pool de tampons. La question est donc la suivante : lors de la lecture d'une page du disque dans le Buffer Pool, où doit-elle être placée dans la page de cache ? Ou comment distinguer quelles pages de cache dans Buffer Pool sont libres et lesquelles ont été utilisées ? Nous ferions mieux d'enregistrer quelque part quelles pages de cache sont disponibles dans le pool de tampons. À ce stade, le bloc de contrôle correspondant à la page de cache est utile. Nous pouvons mapper toutes les pages de cache libres au bloc de contrôle. est placé en nœud dans une liste chaînée. Cette liste chaînée peut également être appelée liste chaînée gratuite (ou liste chaînée gratuite). Toutes les pages de cache du Buffer Pool qui viennent d'être initialisées sont libres, donc le bloc de contrôle correspondant à chaque page de cache sera ajouté à la liste chaînée libre. Le nombre de pages de cache pouvant être hébergées dans le code>Buffer Pool est n. L'effet de l'ajout d'une liste chaînée gratuite est le suivant : MySQL服务器的时候,需要完成对Buffer Pool的初始化过程,就是先向操作系统申请Buffer Pool的内存空间,然后把它划分成若干对控制块和缓存页。但是此时并没有真实的磁盘页被缓存到Buffer Pool中(因为还没有用到),之后随着程序的运行,会不断的有磁盘上的页被缓存到Buffer Pool中。那么问题来了,从磁盘上读取一个页到Buffer Pool中的时候该放到哪个缓存页的位置呢?或者说怎么区分Buffer Pool中哪些缓存页是空闲的,哪些已经被使用了呢?我们最好在某个地方记录一下Buffer Pool中哪些缓存页是可用的,这个时候缓存页对应的控制块就派上大用场了,我们可以把所有空闲的缓存页对应的控制块作为一个节点放到一个链表中,这个链表也可以被称作free链表(或者说空闲链表)。刚刚完成初始化的Buffer Pool中所有的缓存页都是空闲的,所以每一个缓存页对应的控制块都会被加入到free链表中,假设该Buffer Pool中可容纳的缓存页数量为n,那增加了free链表的效果图就是这样的:
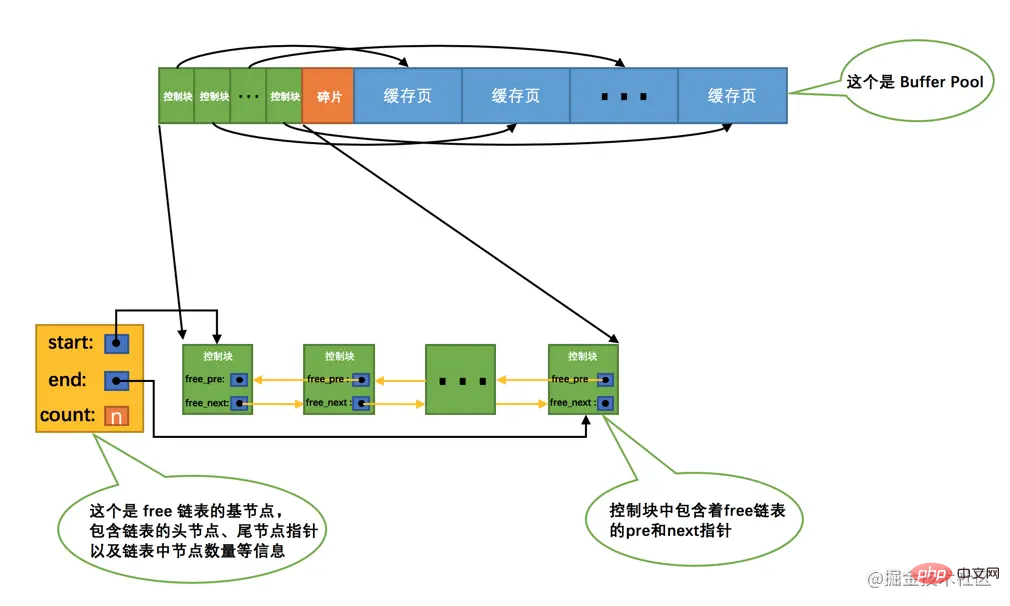
从图中可以看出,我们为了管理好这个free链表,特意为这个链表定义了一个基节点,里边儿包含着链表的头节点地址,尾节点地址,以及当前链表中节点的数量等信息。这里需要注意的是,链表的基节点占用的内存空间并不包含在为Buffer Pool申请的一大片连续内存空间之内,而是单独申请的一块内存空间。
小贴士: 链表基节点占用的内存空间并不大,在MySQL5.7.21这个版本里,每个基节点只占用40字节大小。后边我们即将介绍许多不同的链表,它们的基节点和free链表的基节点的内存分配方式是一样一样的,都是单独申请的一块40字节大小的内存空间,并不包含在为Buffer Pool申请的一大片连续内存空间之内。
有了这个free链表之后事儿就好办了,每当需要从磁盘中加载一个页到Buffer Pool中时,就从free链表中取一个空闲的缓存页,并且把该缓存页对应的控制块的信息填上(就是该页所在的表空间、页号之类的信息),然后把该缓存页对应的free链表节点从链表中移除,表示该缓存页已经被使用了~
缓存页的哈希处理
我们前边说过,当我们需要访问某个页中的数据时,就会把该页从磁盘加载到Buffer Pool中,如果该页已经在Buffer Pool中的话直接使用就可以了。那么问题也就来了,我们怎么知道该页在不在Buffer Pool中呢?难不成需要依次遍历Buffer Pool中各个缓存页么?一个Buffer Pool中的缓存页这么多都遍历完岂不是要累死?
再回头想想,我们其实是根据表空间号 + 页号来定位一个页的,也就相当于表空间号 + 页号是一个key,缓存页就是对应的value,怎么通过一个key来快速找着一个value呢?哈哈,那肯定是哈希表喽~
小贴士: 啥?你别告诉我你不知道哈希表是个啥?我们这个文章不是讲哈希表的,如果你不会那就去找本数据结构的书看看吧~ 啥?外头的书看不懂?别急,等我~
所以我们可以用表空间号 + 页号作为key,缓存页作为value创建一个哈希表,在需要访问某个页的数据时,先从哈希表中根据表空间号 + 页号看看有没有对应的缓存页,如果有,直接使用该缓存页就好,如果没有,那就从free链表
liste chaînée gratuite, nous avons spécialement défini un nœud de base pour cette liste chaînée, qui contient le l'adresse du nœud principal de la liste chaînée, l'adresse du nœud final et le nombre de nœuds dans la liste chaînée actuelle et d'autres informations. Ce qui doit être noté ici est que l'espace mémoire occupé par le nœud de base de la liste chaînée n'est pas inclus dans le grand espace mémoire contigu appliqué pour le Buffer Pool, mais constitue un espace mémoire distinct appliqué pour. 🎜🎜🎜Conseils : L'espace mémoire occupé par le nœud de base de la liste chaînée n'est pas grand. Dans la version de MySQL5.7.21, chaque nœud de base n'occupe que 40 octets. Nous présenterons plus tard de nombreuses listes chaînées différentes. Les méthodes d'allocation de mémoire de leurs nœuds de base et des nœuds de base des listes chaînées gratuites sont toutes appliquées séparément pour un espace mémoire de 40 octets, qui n'est pas inclus dans l'application. Pool de tampons dans un grand espace mémoire contigu. 🎜🎜🎜Avec cette liste chaînée gratuite, les choses seront plus faciles. Chaque fois que vous aurez besoin de charger une page du disque dans le Buffer Pool, chargez-la simplement depuis . Prenez une page de cache libre dans la liste chaînée libre, et renseignez les informations du bloc de contrôle correspondant à la page de cache (c'est-à-dire l'espace table où se trouve la page, page numéro, etc.), puis supprimez le nœud liste chaînée gratuite correspondant à la page cache de la liste chaînée, indiquant que la page cache a été utilisée~🎜🎜🎜Traitement de hachage de la page cache🎜 🎜🎜Nous l'avons déjà dit : lorsque nous avons besoin d'accéder aux données d'une certaine page, nous chargerons la page à partir du disque dans le Buffer Pool si la page est déjà dans le Buffer Pool. code>, utilisez-le directement. La question se pose alors : comment savoir si la page se trouve dans le Buffer Pool ? Est-il nécessaire de parcourir chaque page de cache dans le Buffer Pool dans l'ordre ? Ne serait-il pas épuisant de parcourir autant de pages de cache dans un Buffer Pool ? 🎜🎜Avec le recul, nous localisons en fait une page basée sur numéro d'espace table + numéro de page, ce qui équivaut à numéro d'espace table + numéro de page étant une clé, la <code>page de cache est la valeur correspondante. Comment trouver rapidement une valeurclé Qu'en est-il de /code>. ? Haha, ça doit être une table de hachage~🎜🎜🎜Conseils : Quoi ? Ne me dites pas que vous ne savez pas ce qu'est une table de hachage ? Notre article ne concerne pas les tables de hachage. Si vous ne savez pas comment faire, alors allez chercher un livre sur les structures de données et lisez-le ~ Quoi ? Tu ne peux pas lire les livres dehors ? Ne vous inquiétez pas, attendez-moi ~🎜🎜🎜Nous pouvons donc utiliser numéro d'espace table + numéro de page comme clé et page de cache comme value Créez une table de hachage. Lorsque vous devez accéder aux données d'une certaine page, vérifiez d'abord s'il existe une page de cache correspondante basée sur le numéro d'espace table + numéro de page dans. la table de hachage. Si oui, utilisez simplement la page de cache directement. Sinon, sélectionnez une page de cache libre dans la liste de liens gratuits, puis chargez la page correspondante depuis le disque vers l'emplacement du cache. page. 🎜Gestion des listes chaînées flush
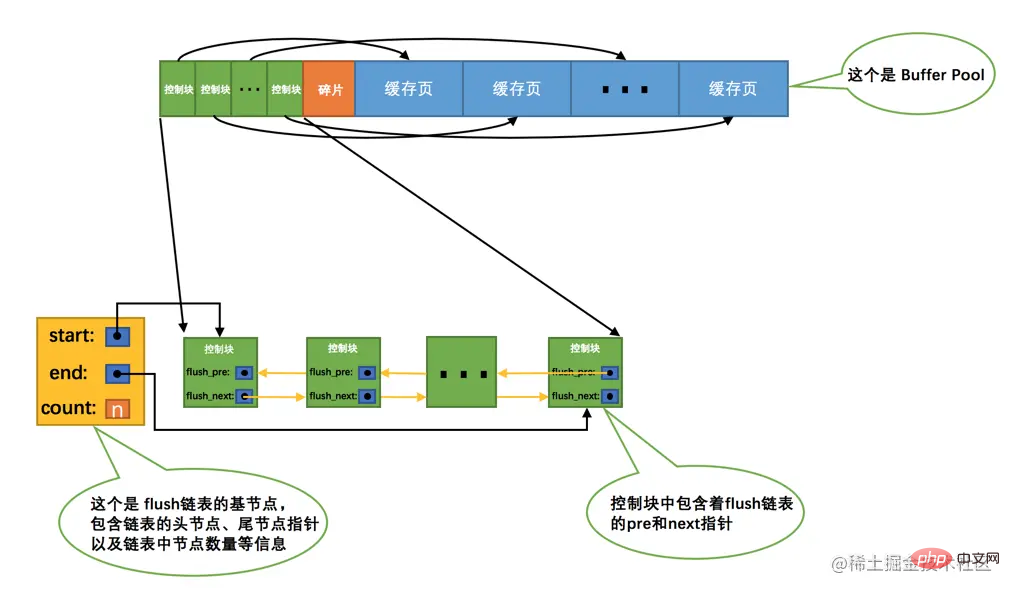
Si nous modifions les données d'une page de cache dans Buffer Pool, alors elle sera incohérente avec la page sur le disque. Une telle page de cache est également appelée <. code>Dirty page
dirty page). Bien sûr, le moyen le plus simple est de le synchroniser avec la page correspondante du disque immédiatement à chaque fois qu'une modification se produit, mais l'écriture fréquente de données sur le disque affectera sérieusement les performances du programme (après tout, le disque est aussi lent qu'un ordinateur). tortue). Ainsi, chaque fois que nous modifions la page de cache, nous ne sommes pas pressés de synchroniser la modification sur le disque immédiatement, mais de la synchroniser à un certain moment dans le futur. Quant à ce moment de synchronisation, nous l'expliquerons plus tard, alors ne le faites pas. Ne vous inquiétez pas maintenant. Ha~Buffer Pool中某个缓存页的数据,那它就和磁盘上的页不一致了,这样的缓存页也被称为脏页(英文名:dirty page)。当然,最简单的做法就是每发生一次修改就立即同步到磁盘上对应的页上,但是频繁的往磁盘中写数据会严重的影响程序的性能(毕竟磁盘慢的像乌龟一样)。所以每次修改缓存页后,我们并不着急立即把修改同步到磁盘上,而是在未来的某个时间点进行同步,至于这个同步的时间点我们后边会作说明说明的,现在先不用管哈~但是如果不立即同步到磁盘的话,那之后再同步的时候我们怎么知道Buffer Pool中哪些页是脏页,哪些页从来没被修改过呢?总不能把所有的缓存页都同步到磁盘上吧,假如Buffer Pool被设置的很大,比方说300G,那一次性同步这么多数据岂不是要慢死!所以,我们不得不再创建一个存储脏页的链表,凡是修改过的缓存页对应的控制块都会作为一个节点加入到一个链表中,因为这个链表节点对应的缓存页都是需要被刷新到磁盘上的,所以也叫flush链表。链表的构造和free链表差不多,假设某个时间点Buffer Pool中的脏页数量为n,那么对应的flush链表就长这样:
LRU链表的管理
缓存不够的窘境
Buffer Pool对应的内存大小毕竟是有限的,如果需要缓存的页占用的内存大小超过了Buffer Pool大小,也就是free链表中已经没有多余的空闲缓存页的时候岂不是很尴尬,发生了这样的事儿该咋办?当然是把某些旧的缓存页从Buffer Pool中移除,然后再把新的页放进来喽~ 那么问题来了,移除哪些缓存页呢?
为了回答这个问题,我们还需要回到我们设立Buffer Pool的初衷,我们就是想减少和磁盘的IO交互,最好每次在访问某个页的时候它都已经被缓存到Buffer Pool中了。假设我们一共访问了n次页,那么被访问的页已经在缓存中的次数除以n就是所谓的缓存命中率,我们的期望就是让缓存命中率越高越好~ 从这个角度出发,回想一下我们的微信聊天列表,排在前边的都是最近很频繁使用的,排在后边的自然就是最近很少使用的,假如列表能容纳下的联系人有限,你是会把最近很频繁使用的留下还是最近很少使用的留下呢?废话,当然是留下最近很频繁使用的了~
简单的LRU链表
管理Buffer Pool的缓存页其实也是这个道理,当Buffer Pool中不再有空闲的缓存页时,就需要淘汰掉部分最近很少使用的缓存页。不过,我们怎么知道哪些缓存页最近频繁使用,哪些最近很少使用呢?呵呵,神奇的链表再一次派上了用场,我们可以再创建一个链表,由于这个链表是为了按照最近最少使用的原则去淘汰缓存页的,所以这个链表可以被称为LRU链表(LRU的英文全称:Least Recently Used)。当我们需要访问某个页时,可以这样处理LRU链表:
如果该页不在
Buffer Pool中,在把该页从磁盘加载到Buffer Pool中的缓存页时,就把该缓存页对应的控制块作为节点塞到链表的头部。如果该页已经缓存在
Buffer Pool中,则直接把该页对应的控制块移动到LRU链表的头部。
也就是说:只要我们使用到某个缓存页,就把该缓存页调整到LRU链表的头部,这样LRU链表尾部就是最近最少使用的缓存页喽~ 所以当Buffer Pool中的空闲缓存页使用完时,到LRU链表的尾部找些缓存页淘汰就OK啦,真简单,啧啧...
划分区域的LRU链表
高兴的太早了,上边的这个简单的LRU链表
Buffer Pool sont des pages sales et quelles pages n'ont jamais été synchronisées ? A-t-elle été modifiée ? Vous ne pouvez pas synchroniser toutes les pages de cache sur le disque. Si le Buffer Pool est défini sur une grande taille, telle que 300G, ne serait-il pas nécessaire de synchroniser. autant de données à la fois ? Mourir lentement ! Par conséquent, nous devons créer une autre liste chaînée pour stocker les pages sales. Les blocs de contrôle correspondant aux pages de cache modifiées seront ajoutés à une liste chaînée en tant que nœud, car les pages de cache correspondant aux nœuds de la liste chaînée doivent être actualisées. disk , on l'appelle donc également vider la liste chaînée. La structure de la liste chaînée est similaire à la liste chaînée gratuite Supposons que le nombre de pages sales dans le Buffer Pool à un moment donné est n. , puis le La liste des liens flush correspondant ressemble à ceci : 🎜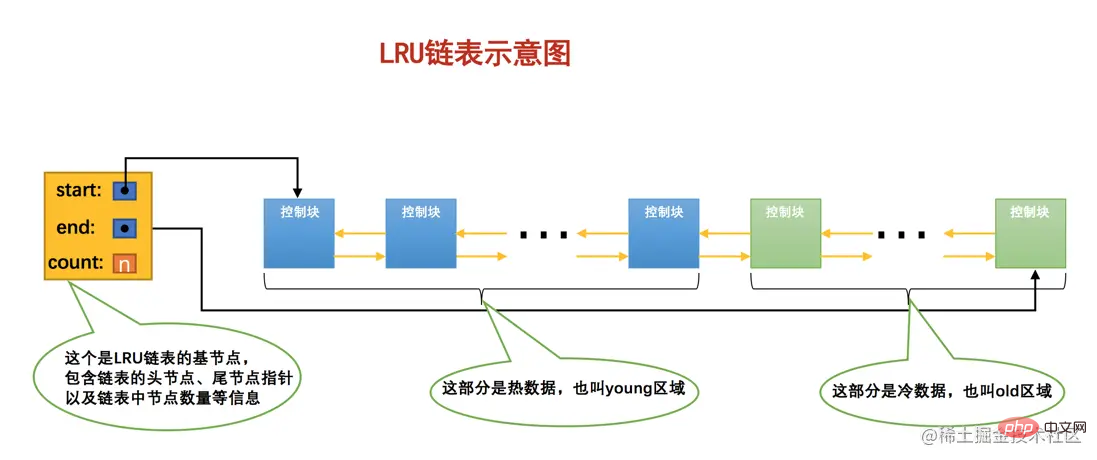 🎜🎜Gestion des listes chaînées LRU🎜🎜Le dilemme du cache insuffisant🎜🎜La taille mémoire correspondant à Le
🎜🎜Gestion des listes chaînées LRU🎜🎜Le dilemme du cache insuffisant🎜🎜La taille mémoire correspondant à Le Buffer Pool est limité après tout. Si ce n'est pas gênant lorsque la taille de la mémoire occupée par les pages qui doivent être mises en cache dépasse la taille du Buffer Pool, c'est-à-dire qu'il y a il n'y a plus de pages de cache gratuites dans la liste de liens gratuits. Que dois-je faire ? Bien sûr, certaines anciennes pages de cache sont supprimées du Buffer Pool, puis de nouvelles pages sont placées ~ La question est donc de savoir quelles pages de cache doivent être supprimées ? 🎜🎜Afin de répondre à cette question, nous devons revenir à l'intention initiale de configurer le Buffer Pool. Nous voulons simplement réduire l'interaction IO avec le disque. Il est préférable d'accéder à un certain pool à chaque fois qu'il a été mis en cache dans le Buffer Pool au moment où il atteint la page. En supposant que nous avons visité la page n fois au total, alors le nombre de fois où la page visitée a été dans le cache divisé par n est ce qu'on appelle taux de réussite du cache , notre attente est de rendre le taux de réussite du cache aussi élevé que possible ~ De ce point de vue, repensez à notre liste de discussion WeChat, ceux en haut sont ceux qui ont ont été fréquemment utilisés récemment, et ceux à l'arrière le sont. Naturellement, ce sont ceux qui ont été rarement utilisés récemment. Si la liste ne peut accueillir qu'un nombre limité de contacts, conserverez-vous ceux qui ont été fréquemment utilisés récemment ou ceux qui ont été fréquemment utilisés récemment. qui ont été rarement utilisés récemment ? C'est absurde, bien sûr, je laisse ceux qui ont été fréquemment utilisés récemment ~ 🎜🎜Liste chaînée LRU simple🎜🎜Gérer la page de cache de Buffer Pool est en fait la même chose quand Buffer Pool. Lorsqu'il n'y a plus de pages de cache libres, certaines pages de cache qui ont été rarement utilisées récemment doivent être supprimées. Cependant, comment savoir quelles pages mises en cache ont été fréquemment utilisées récemment et lesquelles ont été rarement utilisées ? Haha, la liste chaînée magique est à nouveau utile. Nous pouvons créer une autre liste chaînée Puisque cette liste chaînée est utilisée pour éliminer les pages de cache sur la base du principe le moins récemment utilisé, cette liste chaînée peut être appelée <. code>Liste chaînée LRU (le nom anglais complet de LRU : Les moins récemment utilisés). Lorsque nous avons besoin d'accéder à une page, nous pouvons gérer la Liste chaînée LRU comme ceci : 🎜
- 🎜Si la page n'est pas dans le
Buffer Pool, supprimer la page de Lorsque le disque est chargé dans la page de cache dansBuffer Pool, lebloc de contrôlecorrespondant à la page de cache est inséré en tête de la liste chaînée en tant que nœud. 🎜 - 🎜Si la page a été mise en cache dans le
Buffer Pool, déplacez directement lebloc de contrôlecorrespondant de la page vers la liste chaînéeLRU en-tête. 🎜
Liste chaînée LRU, de sorte que LRU linked list est la page de cache la moins récemment utilisée ~ Ainsi, lorsque les pages de cache gratuites du Buffer Pool sont épuisées, allez à la queue de LRU linked list pour trouver des pages de cache à éliminer C'est OK, c'est vraiment simple, wow...🎜🎜Liste chaînée LRU divisée en régions🎜🎜Je suis tellement contente, la simple liste chaînée LRU ci-dessus code> n'a pas mis longtemps à trouver le problème, car il y a deux situations embarrassantes : 🎜-
Situation 1 :
InnoDBfournit un service apparemment prévenant -read forward(nom anglais :read forward). Ce qu'on appelle lapré-lecturesignifie queInnoDBpense que certaines pages peuvent être lues après l'exécution de la requête en cours, il les charge donc dans leBuffer Poolà l'avance. Selon les différentes méthodes de déclenchement, lesPré-lecturepeuvent être subdivisées en deux types suivants :InnoDB提供了一个看起来比较贴心的服务——预读(英文名:read ahead)。所谓预读,就是InnoDB认为执行当前的请求可能之后会读取某些页面,就预先把它们加载到Buffer Pool中。根据触发方式的不同,预读又可以细分为下边两种:-
线性预读
设计
InnoDB的大叔提供了一个系统变量innodb_read_ahead_threshold,如果顺序访问了某个区(extent)的页面超过这个系统变量的值,就会触发一次异步读取下一个区中全部的页面到Buffer Pool的请求,注意异步读取意味着从磁盘中加载这些被预读的页面并不会影响到当前工作线程的正常执行。这个innodb_read_ahead_threshold系统变量的值默认是56,我们可以在服务器启动时通过启动参数或者服务器运行过程中直接调整该系统变量的值,不过它是一个全局变量,注意使用SET GLOBAL命令来修改哦。小贴士: InnoDB是怎么实现异步读取的呢?在Windows或者Linux平台上,可能是直接调用操作系统内核提供的AIO接口,在其它类Unix操作系统中,使用了一种模拟AIO接口的方式来实现异步读取,其实就是让别的线程去读取需要预读的页面。如果你读不懂上边这段话,那也就没必要懂了,和我们主题其实没太多关系,你只需要知道异步读取并不会影响到当前工作线程的正常执行就好了。其实这个过程涉及到操作系统如何处理IO以及多线程的问题,找本操作系统的书看看吧,什么?操作系统的书写的都很难懂?没关系,等我~
-
随机预读
如果
Buffer Pool中已经缓存了某个区的13个连续的页面,不论这些页面是不是顺序读取的,都会触发一次异步读取本区中所有其的页面到Buffer Pool的请求。设计InnoDB的大叔同时提供了innodb_random_read_ahead系统变量,它的默认值为OFF,也就意味着InnoDB并不会默认开启随机预读的功能,如果我们想开启该功能,可以通过修改启动参数或者直接使用SET GLOBAL命令把该变量的值设置为ON。
预读本来是个好事儿,如果预读到Buffer Pool中的页成功的被使用到,那就可以极大的提高语句执行的效率。可是如果用不到呢?这些预读的页都会放到LRU链表的头部,但是如果此时Buffer Pool的容量不太大而且很多预读的页面都没有用到的话,这就会导致处在LRU链表尾部的一些缓存页会很快的被淘汰掉,也就是所谓的劣币驱逐良币,会大大降低缓存命中率。 -
-
情况二:有的小伙伴可能会写一些需要扫描全表的查询语句(比如没有建立合适的索引或者压根儿没有WHERE子句的查询)。
扫描全表意味着什么?意味着将访问到该表所在的所有页!假设这个表中记录非常多的话,那该表会占用特别多的
页,当需要访问这些页时,会把它们统统都加载到Buffer Pool中,这也就意味着吧唧一下,Buffer Pool中的所有页都被换了一次血,其他查询语句在执行时又得执行一次从磁盘加载到Buffer Pool的操作。而这种全表扫描的语句执行的频率也不高,每次执行都要把Buffer Pool中的缓存页换一次血,这严重的影响到其他查询对Buffer Pool的使用,从而大大降低了缓存命中率。
总结一下上边说的可能降低Buffer Pool的两种情况:
加载到
Buffer Pool中的页不一定被用到。如果非常多的使用频率偏低的页被同时加载到
Buffer Pool时,可能会把那些使用频率非常高的页从Buffer Pool中淘汰掉。
因为有这两种情况的存在,所以设计InnoDB的大叔把这个LRU链表按照一定比例分成两截,分别是:
一部分存储使用频率非常高的缓存页,所以这一部分链表也叫做
热数据,或者称young区域。另一部分存储使用频率不是很高的缓存页,所以这一部分链表也叫做
冷数据,或者称old区域
InnoDB a fourni un variable systèmeinnodb_read_ahead_threshold, si les pages accédées séquentiellement dans une certaine zone (extent) dépassent la valeur de cette variable système, une lecture asynchrone sera déclenché Toutes les pages de la zone sont demandées au Buffer Pool Notez que la lecture asynchrone signifie que le chargement de ces pages pré-lues à partir du disque n'affectera pas le thread de travail actuel. . La valeur de cette variable système innodb_read_ahead_threshold est par défaut 56. Nous pouvons ajuster directement la valeur de cette variable système via les paramètres de démarrage au démarrage du serveur ou pendant le processus d'exécution du serveur, mais. il s'agit d'une variable globale, veuillez utiliser la commande SET GLOBAL pour les modifier. 🎜🎜Conseils : Comment InnoDB implémente-t-il la lecture asynchrone ? Sur les plateformes Windows ou Linux, il peut être possible d'appeler directement l'interface AIO fournie par le noyau du système d'exploitation. Dans d'autres systèmes d'exploitation de type Unix, une méthode de simulation de l'interface AIO est utilisée pour réaliser une lecture asynchrone. pour laisser les autres fils de discussion lire Récupérez la page qui doit être lue à l'avance. Si vous ne comprenez pas le paragraphe ci-dessus, alors il n'est pas nécessaire de le comprendre. Cela n'a rien à voir avec notre sujet. Vous devez seulement savoir que la lecture asynchrone n'affectera pas l'exécution normale du thread de travail actuel. En fait, ce processus implique la manière dont le système d'exploitation gère les problèmes d'E/S et de multithread. Cherchons un livre sur le système d'exploitation. L’écriture du système d’exploitation est-elle difficile à comprendre ? C'est bon, attendez-moi ~🎜🎜🎜🎜Prélecture aléatoire🎜🎜Si 13 pages consécutives dans une certaine zone ont été mises en cache dans
Buffer Pool, que ces pages soient lues ou non séquentiellement, déclenchera une requête asynchrone pour lire toutes les pages de cette zone dans le Buffer Pool. L'oncle qui a conçu InnoDB a également fourni la variable système innodb_random_read_ahead. Sa valeur par défaut est OFF, ce qui signifie InnoDBLe. la fonction de lecture anticipée aléatoire n'est pas activée par défaut. Si nous voulons activer cette fonction, nous pouvons définir la valeur de cette variable sur ON en modifiant les paramètres de démarrage ou directement en utilisant le <code>SET GLOBALcode>commande>. 🎜🎜🎜🎜Pré-lecture est à l'origine une bonne chose. Si les pages du Buffer Pool de pré-lecture sont utilisées avec succès, cela peut grandement améliorer l'exécution des instructions. efficacité. Mais que se passe-t-il s’il n’est pas utilisé ? Ces pages prélues seront placées en tête de la liste chaînée LRU, mais si la capacité du Buffer Pool n'est pas trop grande à ce moment et que de nombreuses pages prélues les pages ne sont pas utilisées, cela entraînera l'élimination rapide de certaines pages de cache à la fin de la Liste chaînée LRU, ce qu'on appelle les mauvaises pièces chassent les bonnes pièces, ce qui réduira considérablement le taux de réussite du cache. 🎜🎜🎜🎜Scénario 2 : certains amis peuvent écrire des instructions de requête qui doivent analyser la table entière (telles que des requêtes qui ne créent pas d'index appropriés ou qui n'ont pas de clause WHERE du tout). 🎜🎜Que signifie scanner l'intégralité du tableau ? Cela signifie que toutes les pages où se trouve le tableau seront accessibles ! En supposant qu'il y ait de très nombreux enregistrements dans cette table, la table occupera un nombre particulièrement important de pages. Lorsqu'il faudra accéder à ces pages, elles seront toutes chargées dans le Buffer Pool<.> , cela signifie également que toutes les pages du <code>Buffer Pool ont été remplacées une fois et que d'autres instructions de requête doivent être chargées du disque vers le Buffer Pool lorsqu'elles le sont. exécuté. code> opération. La fréquence d'exécution de ce type d'instruction d'analyse de table complète n'est pas élevée. Chaque fois qu'elle est exécutée, la page de cache dans le Buffer Pool doit être remplacée. Cela affecte sérieusement l'utilisation d'autres requêtes dans le . code>Buffer L'utilisation de Pool réduit considérablement le taux de réussite du cache. 🎜🎜🎜🎜 Résumons les deux situations évoquées ci-dessus qui peuvent ralentir le Buffer Pool : 🎜🎜🎜🎜Les pages chargées dans le Buffer Pool ne seront peut-être pas forcément utilisées. 🎜🎜🎜🎜Si de nombreuses pages à faible fréquence d'utilisation sont chargées dans le Buffer Pool en même temps, les pages à très haute fréquence d'utilisation peuvent être supprimées du Buffer Pool. code> Supprimer. 🎜🎜🎜🎜Parce que ces deux situations existent, l'oncle qui a conçu InnoDB a divisé cette liste chaînée LRU en deux parties selon une certaine proportion, qui sont : 🎜🎜🎜🎜 Une partie de la page de cache stocke les pages de cache très fréquemment utilisées, donc cette partie de la liste chaînée est également appelée données chaudes, ou zone jeune. 🎜🎜🎜🎜L'autre partie stocke les pages de cache qui ne sont pas utilisées très fréquemment, donc cette partie de la liste chaînée est également appelée données froides, ou ancienne zone. 🎜🎜🎜🎜Afin de faciliter la compréhension de chacun, nous avons simplifié le schéma de principe. Il suffit de comprendre l'esprit : 🎜
大家要特别注意一个事儿:我们是按照某个比例将LRU链表分成两半的,不是某些节点固定是young区域的,某些节点固定是old区域的,随着程序的运行,某个节点所属的区域也可能发生变化。那这个划分成两截的比例怎么确定呢?对于InnoDB存储引擎来说,我们可以通过查看系统变量innodb_old_blocks_pct的值来确定old区域在LRU链表中所占的比例,比方说这样:
mysql> SHOW VARIABLES LIKE 'innodb_old_blocks_pct'; +-----------------------+-------+ | Variable_name | Value | +-----------------------+-------+ | innodb_old_blocks_pct | 37 | +-----------------------+-------+ 1 row in set (0.01 sec)
从结果可以看出来,默认情况下,old区域在LRU链表中所占的比例是37%,也就是说old区域大约占LRU链表的3/8。这个比例我们是可以设置的,我们可以在启动时修改innodb_old_blocks_pct参数来控制old区域在LRU链表中所占的比例,比方说这样修改配置文件:
[server] innodb_old_blocks_pct = 40
这样我们在启动服务器后,old区域占LRU链表的比例就是40%。当然,如果在服务器运行期间,我们也可以修改这个系统变量的值,不过需要注意的是,这个系统变量属于全局变量,一经修改,会对所有客户端生效,所以我们只能这样修改:
SET GLOBAL innodb_old_blocks_pct = 40;
有了这个被划分成young和old区域的LRU链表之后,设计InnoDB的大叔就可以针对我们上边提到的两种可能降低缓存命中率的情况进行优化了:
-
针对预读的页面可能不进行后续访问情况的优化
设计
InnoDB的大叔规定,当磁盘上的某个页面在初次加载到Buffer Pool中的某个缓存页时,该缓存页对应的控制块会被放到old区域的头部。这样针对预读到Buffer Pool却不进行后续访问的页面就会被逐渐从old区域逐出,而不会影响young区域中被使用比较频繁的缓存页。 -
针对全表扫描时,短时间内访问大量使用频率非常低的页面情况的优化
在进行全表扫描时,虽然首次被加载到
Buffer Pool的页被放到了old区域的头部,但是后续会被马上访问到,每次进行访问的时候又会把该页放到young区域的头部,这样仍然会把那些使用频率比较高的页面给顶下去。有同学会想:可不可以在第一次访问该页面时不将其从old区域移动到young区域的头部,后续访问时再将其移动到young区域的头部。回答是:行不通!因为设计InnoDB的大叔规定每次去页面中读取一条记录时,都算是访问一次页面,而一个页面中可能会包含很多条记录,也就是说读取完某个页面的记录就相当于访问了这个页面好多次。咋办?全表扫描有一个特点,那就是它的执行频率非常低,谁也不会没事儿老在那写全表扫描的语句玩,而且在执行全表扫描的过程中,即使某个页面中有很多条记录,也就是去多次访问这个页面所花费的时间也是非常少的。所以我们只需要规定,在对某个处在
old区域的缓存页进行第一次访问时就在它对应的控制块中记录下来这个访问时间,如果后续的访问时间与第一次访问的时间在某个时间间隔内,那么该页面就不会被从old区域移动到young区域的头部,否则将它移动到young区域的头部。上述的这个间隔时间是由系统变量innodb_old_blocks_time控制的,你看:
mysql> SHOW VARIABLES LIKE 'innodb_old_blocks_time'; +------------------------+-------+ | Variable_name | Value | +------------------------+-------+ | innodb_old_blocks_time | 1000 | +------------------------+-------+ 1 row in set (0.01 sec)
这个innodb_old_blocks_time的默认值是1000,它的单位是毫秒,也就意味着对于从磁盘上被加载到LRU链表的old区域的某个页来说,如果第一次和最后一次访问该页面的时间间隔小于1s(很明显在一次全表扫描的过程中,多次访问一个页面中的时间不会超过1s),那么该页是不会被加入到young区域的~ 当然,像innodb_old_blocks_pct一样,我们也可以在服务器启动或运行时设置innodb_old_blocks_time的值,这里就不赘述了,你自己试试吧~ 这里需要注意的是,如果我们把innodb_old_blocks_time的值设置为0,那么每次我们访问一个页面时就会把该页面放到young区域的头部。
En résumé, c'est précisément parce que la liste chaînée LRU est divisée en deux parties : les zones jeunes et anciennes, et est ajouté La variable système innodb_old_blocks_time a limité le problème de réduction du taux de réussite du cache causé par le mécanisme de lecture anticipée et l'analyse complète de la table, car les pages prélues inutilisées et les pages d'analyse complète de la table ne seront placées que dans old sans affecter les pages mises en cache dans la zone <code>young. LRU链表划分为young和old区域这两个部分,又添加了innodb_old_blocks_time这个系统变量,才使得预读机制和全表扫描造成的缓存命中率降低的问题得到了遏制,因为用不到的预读页面以及全表扫描的页面都只会被放到old区域,而不影响young区域中的缓存页。
更进一步优化LRU链表
LRU链表这就说完了么?没有,早着呢~ 对于young区域的缓存页来说,我们每次访问一个缓存页就要把它移动到LRU链表的头部,这样开销是不是太大啦,毕竟在young区域的缓存页都是热点数据,也就是可能被经常访问的,这样频繁的对LRU链表进行节点移动操作是不是不太好啊?是的,为了解决这个问题其实我们还可以提出一些优化策略,比如只有被访问的缓存页位于young区域的1/4的后边,才会被移动到LRU链表头部,这样就可以降低调整LRU链表的频率,从而提升性能(也就是说如果某个缓存页对应的节点在young区域的1/4中,再次访问该缓存页时也不会将其移动到LRU链表头部)。
小贴士: 我们之前介绍随机预读的时候曾说,如果Buffer Pool中有某个区的13个连续页面就会触发随机预读,这其实是不严谨的(不幸的是MySQL文档就是这么说的[摊手]),其实还要求这13个页面是非常热的页面,所谓的非常热,指的是这些页面在整个young区域的头1/4处。
还有没有什么别的针对LRU链表的优化措施呢?当然有啊,你要是好好学,写篇论文,写本书都不是问题,可是这毕竟是一个介绍MySQL基础知识的文章,再说多了篇幅就受不了了,也影响大家的阅读体验,所以适可而止,想了解更多的优化知识,自己去看源码或者更多关于LRU链表的知识喽~ 但是不论怎么优化,千万别忘了我们的初心:尽量高效的提高 Buffer Pool 的缓存命中率。
其他的一些链表
为了更好的管理Buffer Pool中的缓存页,除了我们上边提到的一些措施,设计InnoDB的大叔们还引进了其他的一些链表,比如unzip LRU链表用于管理解压页,zip clean链表用于管理没有被解压的压缩页,zip free数组中每一个元素都代表一个链表,它们组成所谓的伙伴系统来为压缩页提供内存空间等等,反正是为了更好的管理这个Buffer Pool引入了各种链表或其他数据结构,具体的使用方式就不啰嗦了,大家有兴趣深究的再去找些更深的书或者直接看源代码吧,也可以直接来找我哈~
小贴士: 我们压根儿没有深入唠叨过InnoDB中的压缩页,对上边的这些链表也只是为了完整性顺便提一下,如果你看不懂千万不要抑郁,因为我压根儿就没打算向大家介绍它们。
刷新脏页到磁盘
后台有专门的线程每隔一段时间负责把脏页刷新到磁盘,这样可以不影响用户线程处理正常的请求。主要有两种刷新路径:
-
从
LRU链表的冷数据中刷新一部分页面到磁盘。后台线程会定时从
LRU链表尾部开始扫描一些页面,扫描的页面数量可以通过系统变量innodb_lru_scan_depth来指定,如果从里边儿发现脏页,会把它们刷新到磁盘。这种刷新页面的方式被称之为BUF_FLUSH_LRU。 -
从
flush链表中刷新一部分页面到磁盘。后台线程也会定时从
flush链表中刷新一部分页面到磁盘,刷新的速率取决于当时系统是不是很繁忙。这种刷新页面的方式被称之为BUF_FLUSH_LIST。
有时候后台线程刷新脏页的进度比较慢,导致用户线程在准备加载一个磁盘页到Buffer Pool时没有可用的缓存页,这时就会尝试看看LRU链表尾部有没有可以直接释放掉的未修改页面,如果没有的话会不得不将LRU链表尾部的一个脏页同步刷新到磁盘(和磁盘交互是很慢的,这会降低处理用户请求的速度)。这种刷新单个页面到磁盘中的刷新方式被称之为BUF_FLUSH_SINGLE_PAGE
Liste chaînée LRU C'est tout ? Non, il est tôt ~ Pour les pages de cache dans la zone jeune, chaque fois que nous accédons à une page de cache, nous devons la déplacer en tête de la liste chaînée LRU, donc La surcharge n'est pas trop importante. Après tout, les pages de cache dans la zone young sont des données chaudes, c'est-à-dire qu'elles peuvent être fréquemment consultées. Des opérations de déplacement de nœuds aussi fréquentes sur le LRU lié. list sont nécessaires. N'est-ce pas bon ? Oui, afin de résoudre ce problème, nous pouvons effectivement proposer quelques stratégies d'optimisation. Par exemple, seule la page de cache consultée située après 1/4 dans la zone jeune sera. mis en cache. Déplacer vers l'en-tête de la Liste chaînée LRU, de sorte que la fréquence d'ajustement de la Liste chaînée LRU puisse être réduite, améliorant ainsi les performances (c'est-à-dire si le nœud est mis en cache). correspondant à une page cache se trouve dans Dans <code>1/4 de la zone jeune, lors d'un nouvel accès à la page cache, elle ne sera pas déplacée en tête du LRU liste chaînée). 🎜🎜Conseils : Lorsque nous avons introduit la prélecture aléatoire auparavant, nous avons dit que s'il y avait 13 pages consécutives dans une certaine zone du Buffer Pool, la prélecture aléatoire serait déclenchée. Ce n'est en fait pas rigoureux (malheureusement). C'est ce que dit le document MySQL [montrer les mains]). En fait, ces 13 pages doivent être des pages très chaudes. Le soi-disant très chaud fait référence à ces pages se trouvant dans le premier quart de l'ensemble de la zone jeune. 🎜🎜Existe-t-il d'autres mesures d'optimisation pour la
Liste chaînée LRU ? Bien sûr, si vous étudiez dur, ce ne sera pas un problème d'écrire un article ou un livre. Mais après tout, c'est un article qui présente les connaissances de base de MySQL. est trop long, cela sera insupportable et cela affectera l'expérience de lecture de tout le monde, donc ça suffit. Si vous voulez en savoir plus sur l'optimisation, accédez au code source vous-même ou apprenez-en plus sur les listes chaînées LRU. ~ Mais quelle que soit la manière dont nous optimisons, n'oubliez pas notre intention initiale : essayer d'améliorer le taux de réussite du cache du Buffer Pool aussi efficacement que possible. 🎜Quelques autres listes chaînées
🎜Afin de mieux gérer les pages de cache dansBuffer Pool, en plus de certaines des mesures mentionnées ci-dessus, concevez InnoDB code> Les oncles ont également introduit d'autres <code>listes liées, telles que la liste liée unzip LRU pour gérer les pages décompressées, et la liste chaînée zip clean pour la gestion. pages décompressées. Pour les pages compressées décompressées, chaque élément du zip free array représente une liste chaînée. Ils forment ce que l'on appelle un système partenaire pour fournir de l'espace mémoire pour les pages compressées. etc. Quoi qu'il en soit, c'est pour une meilleure gestion de ce Buffer Pool qui introduit diverses listes chaînées ou autres structures de données. Les méthodes d'utilisation spécifiques ne seront pas fastidieuses. Si vous souhaitez en savoir plus, vous pouvez en trouver. des livres plus approfondis ou lire directement le code source. Eh bien, vous pouvez également venir me voir directement ~🎜🎜Conseils : nous n'avons pas du tout parlé en profondeur des pages de compression dans InnoDB, et les listes de liens ci-dessus le sont. je viens de le mentionner par souci d’exhaustivité. Si vous regardez, ne soyez pas déprimé si vous ne les comprenez pas, car je n’ai pas du tout l’intention de vous les présenter. 🎜
Actualiser les pages sales sur le disque
🎜Il y a un thread spécial en arrière-plan qui est responsable de l'actualisation des pages sales sur le disque à intervalles réguliers, afin qu'il n'affecte pas le traitement des tâches du thread utilisateur. demandes normales. Il existe deux chemins de rafraîchissement principaux : 🎜- 🎜 Actualisez une partie des pages à partir des données froides de la
Liste chaînée LRUsur le disque. 🎜🎜Le fil d'arrière-plan analysera périodiquement certaines pages à partir de la fin de laListe chaînée LRU. Le nombre de pages numérisées peut être spécifié via la variable systèmeinnodb_lru_scan_degree. Une page sale est trouvée à l'intérieur, elle sera vidée sur le disque. Cette méthode de rafraîchissement de la page s'appelleBUF_FLUSH_LRU. 🎜 - 🎜Actualisez certaines pages de la
vider la liste des lienssur le disque. 🎜🎜Le fil d'arrière-plan actualisera également périodiquement certaines pages de lavider la liste des lienssur le disque. Le taux de rafraîchissement dépend du fait que le système est très occupé à ce moment-là. Cette méthode de rafraîchissement de la page s'appelleBUF_FLUSH_LIST. 🎜
Buffer Pool à ce moment-là. Il essaiera de voir s'il y a des pages non modifiées à la fin de la Liste chaînée LRU qui peuvent être directement publiées. Sinon, il devra actualiser de manière synchrone une page sale à la fin du BUF_FLUSH_SINGLE_PAGE. 🎜当然,有时候系统特别繁忙时,也可能出现用户线程批量的从flush链表中刷新脏页的情况,很显然在处理用户请求过程中去刷新脏页是一种严重降低处理速度的行为(毕竟磁盘的速度慢的要死),这属于一种迫不得已的情况,不过这得放在后边唠叨redo日志的checkpoint时说了。
多个Buffer Pool实例
我们上边说过,Buffer Pool本质是InnoDB向操作系统申请的一块连续的内存空间,在多线程环境下,访问Buffer Pool中的各种链表都需要加锁处理啥的,在Buffer Pool特别大而且多线程并发访问特别高的情况下,单一的Buffer Pool可能会影响请求的处理速度。所以在Buffer Pool特别大的时候,我们可以把它们拆分成若干个小的Buffer Pool,每个Buffer Pool都称为一个实例,它们都是独立的,独立的去申请内存空间,独立的管理各种链表,独立的吧啦吧啦,所以在多线程并发访问时并不会相互影响,从而提高并发处理能力。我们可以在服务器启动的时候通过设置innodb_buffer_pool_instances的值来修改Buffer Pool实例的个数,比方说这样:
[server] innodb_buffer_pool_instances = 2
这样就表明我们要创建2个Buffer Pool实例,示意图就是这样:
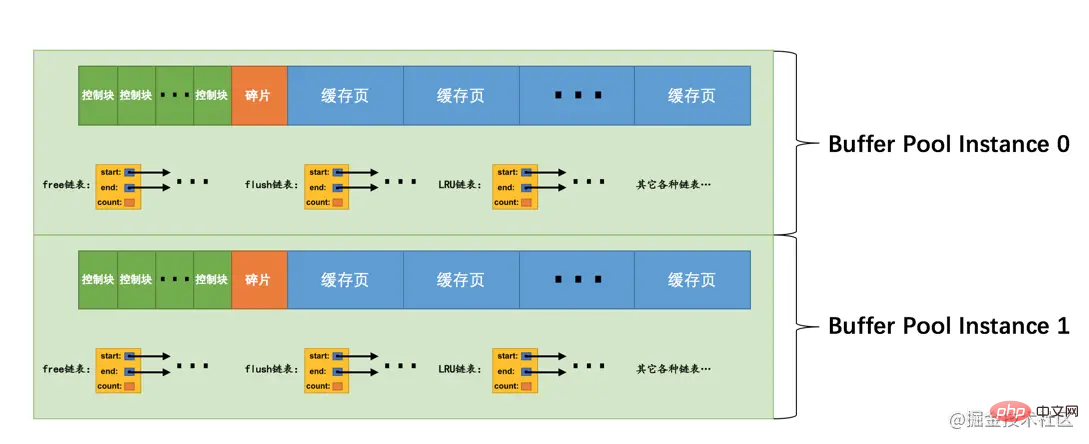
小贴士: 为了简便,我只把各个链表的基节点画出来了,大家应该心里清楚这些链表的节点其实就是每个缓存页对应的控制块!
那每个Buffer Pool实例实际占多少内存空间呢?其实使用这个公式算出来的:
innodb_buffer_pool_size/innodb_buffer_pool_instances
也就是总共的大小除以实例的个数,结果就是每个Buffer Pool实例占用的大小。
不过也不是说Buffer Pool实例创建的越多越好,分别管理各个Buffer Pool也是需要性能开销的,设计InnoDB的大叔们规定:当innodb_buffer_pool_size的值小于1G的时候设置多个实例是无效的,InnoDB会默认把innodb_buffer_pool_instances 的值修改为1。而我们鼓励在Buffer Pool大于或等于1G的时候设置多个Buffer Pool实例。
innodb_buffer_pool_chunk_size
在MySQL 5.7.5之前,Buffer Pool的大小只能在服务器启动时通过配置innodb_buffer_pool_size启动参数来调整大小,在服务器运行过程中是不允许调整该值的。不过设计MySQL的大叔在5.7.5以及之后的版本中支持了在服务器运行过程中调整Buffer Pool大小的功能,但是有一个问题,就是每次当我们要重新调整Buffer Pool大小时,都需要重新向操作系统申请一块连续的内存空间,然后将旧的Buffer Pool中的内容复制到这一块新空间,这是极其耗时的。所以设计MySQL的大叔们决定不再一次性为某个Buffer Pool实例向操作系统申请一大片连续的内存空间,而是以一个所谓的chunk为单位向操作系统申请空间。也就是说一个Buffer Pool实例其实是由若干个chunk组成的,一个chunk就代表一片连续的内存空间,里边儿包含了若干缓存页与其对应的控制块,画个图表示就是这样:
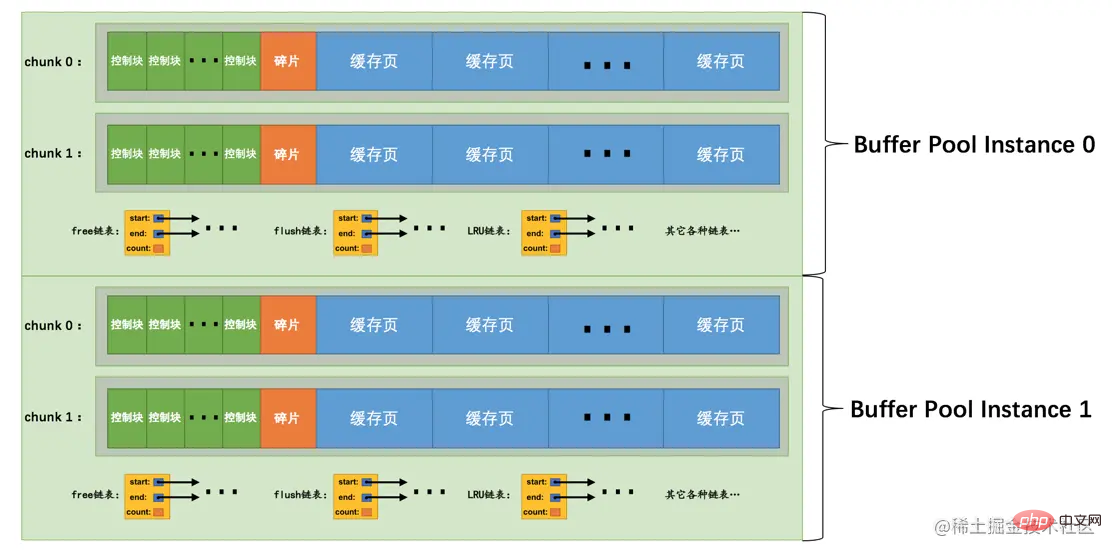
上图代表的Buffer Pool就是由2个实例组成的,每个实例中又包含2个chunk。
正是因为发明了这个chunk的概念,我们在服务器运行期间调整Buffer Pool的大小时就是以chunk为单位增加或者删除内存空间,而不需要重新向操作系统申请一片大的内存,然后进行缓存页的复制。这个所谓的chunk的大小是我们在启动操作MySQL服务器时通过innodb_buffer_pool_chunk_size启动参数指定的,它的默认值是134217728,也就是128M。不过需要注意的是,innodb_buffer_pool_chunk_size的值只能在服务器启动时指定,在服务器运行过程中是不可以修改的。
小贴士: 为什么不允许在服务器运行过程中修改innodb_buffer_pool_chunk_size的值?还不是因为innodb_buffer_pool_chunk_size的值代表InnoDB向操作系统申请的一片连续的内存空间的大小,如果你在服务器运行过程中修改了该值,就意味着要重新向操作系统申请连续的内存空间并且将原先的缓存页和它们对应的控制块复制到这个新的内存空间中,这是十分耗时的操作! 另外,这个innodb_buffer_pool_chunk_size的值并不包含缓存页对应的控制块的内存空间大小,所以实际上InnoDB向操作系统申请连续内存空间时,每个chunk的大小要比innodb_buffer_pool_chunk_size的值大一些,约5%。
配置Buffer Pool时的注意事项
-
innodb_buffer_pool_size必须是innodb_buffer_pool_chunk_size × innodb_buffer_pool_instances的倍数(这主要是想保证每一个Buffer Pool实例中包含的chunk数量相同)。假设我们指定的
innodb_buffer_pool_chunk_size的值是128M,innodb_buffer_pool_instances的值是16,那么这两个值的乘积就是2G,也就是说innodb_buffer_pool_size的值必须是2G或者2G的整数倍。比方说我们在启动MySQL服务器是这样指定启动参数的:mysqld --innodb-buffer-pool-size=8G --innodb-buffer-pool-instances=16
默认的
innodb_buffer_pool_chunk_size值是128M,指定的innodb_buffer_pool_instances的值是16,所以innodb_buffer_pool_size的值必须是2G或者2G的整数倍,上边例子中指定的innodb_buffer_pool_size的值是8G,符合规定,所以在服务器启动完成之后我们查看一下该变量的值就是我们指定的8G(8589934592字节):mysql> show variables like 'innodb_buffer_pool_size'; +-------------------------+------------+ | Variable_name | Value | +-------------------------+------------+ | innodb_buffer_pool_size | 8589934592 | +-------------------------+------------+ 1 row in set (0.00 sec)
如果我们指定的
innodb_buffer_pool_size大于2G并且不是2G的整数倍,那么服务器会自动的把innodb_buffer_pool_size的值调整为2G的整数倍,比方说我们在启动服务器时指定的innodb_buffer_pool_size的值是9G:mysqld --innodb-buffer-pool-size=9G --innodb-buffer-pool-instances=16
那么服务器会自动把
innodb_buffer_pool_size的值调整为10G(10737418240字节),不信你看:mysql> show variables like 'innodb_buffer_pool_size'; +-------------------------+-------------+ | Variable_name | Value | +-------------------------+-------------+ | innodb_buffer_pool_size | 10737418240 | +-------------------------+-------------+ 1 row in set (0.01 sec)
-
如果在服务器启动时,
innodb_buffer_pool_chunk_size × innodb_buffer_pool_instances的值已经大于innodb_buffer_pool_size的值,那么innodb_buffer_pool_chunk_size的值会被服务器自动设置为innodb_buffer_pool_size/innodb_buffer_pool_instances的值。比方说我们在启动服务器时指定的
innodb_buffer_pool_size的值为2G,innodb_buffer_pool_instances的值为16,innodb_buffer_pool_chunk_size的值为256M:mysqld --innodb-buffer-pool-size=2G --innodb-buffer-pool-instances=16 --innodb-buffer-pool-chunk-size=256M
由于
256M × 16 = 4G,而4G > 2G,所以innodb_buffer_pool_chunk_size值会被服务器改写为innodb_buffer_pool_size/innodb_buffer_pool_instances的值,也就是:2G/16 = 128M(134217728字节),不信你看:mysql> show variables like 'innodb_buffer_pool_size'; +-------------------------+------------+ | Variable_name | Value | +-------------------------+------------+ | innodb_buffer_pool_size | 2147483648 | +-------------------------+------------+ 1 row in set (0.01 sec) mysql> show variables like 'innodb_buffer_pool_chunk_size'; +-------------------------------+-----------+ | Variable_name | Value | +-------------------------------+-----------+ | innodb_buffer_pool_chunk_size | 134217728 | +-------------------------------+-----------+ 1 row in set (0.00 sec)
Buffer Pool中存储的其它信息
Buffer Pool的缓存页除了用来缓存磁盘上的页面以外,还可以存储锁信息、自适应哈希索引等信息,这些内容等我们之后遇到了再详细讨论哈~
查看Buffer Pool的状态信息
设计MySQL的大叔贴心的给我们提供了SHOW ENGINE INNODB STATUS语句来查看关于InnoDB存储引擎运行过程中的一些状态信息,其中就包括Buffer Pool的一些信息,我们看一下(为了突出重点,我们只把输出中关于Buffer Pool的部分提取了出来):
mysql> SHOW ENGINE INNODB STATUS\G (...省略前边的许多状态) ---------------------- BUFFER POOL AND MEMORY ---------------------- Total memory allocated 13218349056; Dictionary memory allocated 4014231 Buffer pool size 786432 Free buffers 8174 Database pages 710576 Old database pages 262143 Modified db pages 124941 Pending reads 0 Pending writes: LRU 0, flush list 0, single page 0 Pages made young 6195930012, not young 78247510485 108.18 youngs/s, 226.15 non-youngs/s Pages read 2748866728, created 29217873, written 4845680877 160.77 reads/s, 3.80 creates/s, 190.16 writes/s Buffer pool hit rate 956 / 1000, young-making rate 30 / 1000 not 605 / 1000 Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s LRU len: 710576, unzip_LRU len: 118 I/O sum[134264]:cur[144], unzip sum[16]:cur[0] -------------- (...省略后边的许多状态) mysql>
我们来详细看一下这里边的每个值都代表什么意思:
Total memory allocated:代表Buffer Pool向操作系统申请的连续内存空间大小,包括全部控制块、缓存页、以及碎片的大小。Dictionary memory allocated:为数据字典信息分配的内存空间大小,注意这个内存空间和Buffer Pool没啥关系,不包括在Total memory allocated中。Buffer pool size:代表该Buffer Pool可以容纳多少缓存页,注意,单位是页!Free buffers:代表当前Buffer Pool还有多少空闲缓存页,也就是free链表中还有多少个节点。Pages de la base de données: représente le nombre de pages dans la liste chaînéeLRU, comprenant deux zones :jeuneetvieux code> nombre de nœuds. <code>Database pages:代表LRU链表中的页的数量,包含young和old两个区域的节点数量。Old database pages:代表LRU链表old区域的节点数量。Modified db pages:代表脏页数量,也就是flush链表中节点的数量。-
Pending reads:正在等待从磁盘上加载到Buffer Pool中的页面数量。当准备从磁盘中加载某个页面时,会先为这个页面在
Buffer Pool中分配一个缓存页以及它对应的控制块,然后把这个控制块添加到LRU的old区域的头部,但是这个时候真正的磁盘页并没有被加载进来,Pending reads的值会跟着加1。 Pending writes LRU:即将从LRU链表中刷新到磁盘中的页面数量。Pending writes flush list:即将从flush链表中刷新到磁盘中的页面数量。Pending writes single page:即将以单个页面的形式刷新到磁盘中的页面数量。-
Pages made young:代表LRU链表中曾经从old区域移动到young区域头部的节点数量。这里需要注意,一个节点每次只有从
old区域移动到young区域头部时才会将Pages made young的值加1,也就是说如果该节点本来就在young区域,由于它符合在young区域1/4后边的要求,下一次访问这个页面时也会将它移动到young区域头部,但这个过程并不会导致Pages made young的值加1。 -
Page made not young:在将innodb_old_blocks_time设置的值大于0时,首次访问或者后续访问某个处在old区域的节点时由于不符合时间间隔的限制而不能将其移动到young区域头部时,Page made not young的值会加1。这里需要注意,对于处在
young区域的节点,如果由于它在young区域的1/4处而导致它没有被移动到young区域头部,这样的访问并不会将Page made not young的值加1。 youngs/s:代表每秒从old区域被移动到young区域头部的节点数量。non-youngs/s:代表每秒由于不满足时间限制而不能从old区域移动到young区域头部的节点数量。Pages read、created、written:代表读取,创建,写入了多少页。后边跟着读取、创建、写入的速率。Buffer pool hit rate:表示在过去某段时间,平均访问1000次页面,有多少次该页面已经被缓存到Buffer Pool了。-
young-making rate:表示在过去某段时间,平均访问1000次页面,有多少次访问使页面移动到young区域的头部了。需要大家注意的一点是,这里统计的将页面移动到
young区域的头部次数不仅仅包含从old区域移动到young区域头部的次数,还包括从young区域移动到young区域头部的次数(访问某个young区域的节点,只要该节点在young区域的1/4处往后,就会把它移动到young区域的头部)。 -
not (young-making rate):表示在过去某段时间,平均访问1000次页面,有多少次访问没有使页面移动到young区域的头部。需要大家注意的一点是,这里统计的没有将页面移动到
young区域的头部次数不仅仅包含因为设置了innodb_old_blocks_time系统变量而导致访问了old区域中的节点但没把它们移动到young区域的次数,还包含因为该节点在young区域的前1/4处而没有被移动到young区域头部的次数。 LRU len:代表LRU链表中节点的数量。unzip_LRU:代表unzip_LRU链表中节点的数量(由于我们没有具体唠叨过这个链表,现在可以忽略它的值)。I/O sum:最近50s读取磁盘页的总数。I/O cur:现在正在读取的磁盘页数量。I/O unzip sum:最近50s解压的页面数量。-
🎜🎜I/O unzip curAnciennes pages de base de données: représente le nombre de nœuds dans la zoneanciennede la liste chaînéeLRU. 🎜🎜🎜🎜Pages de base de données modifiées: représente le nombre de pages sales, qui est le nombre de nœuds dans laliste de liens flush. 🎜🎜🎜🎜Lectures en attente: le nombre de pages qui attendent d'être chargées du disque dans leBuffer Pool. 🎜🎜Lors de la préparation du chargement d'une page à partir du disque, il allouera d'abord une page de cache et son bloc de contrôle correspondant dans leBuffer Poolpour cette page, puis ajoutera ce bloc de contrôle àL'en-tête de la <code>anciennezone de LRU, mais la vraie page du disque n'a pas été chargée pour le moment, et la valeur deLectures en attentesera augmentée de 1 . 🎜🎜🎜🎜En attente d'écritures LRU: Le nombre de pages qui seront vidées sur le disque à partir de la liste chaînéeLRU. 🎜🎜🎜🎜Liste de vidage des écritures en attente: Le nombre de pages qui seront vidées sur le disque à partir de la liste chaînéevidage. 🎜🎜🎜🎜En attente d'écriture d'une seule page: le nombre de pages qui seront vidées sur le disque en tant que page unique. 🎜🎜🎜🎜Pages rendues jeunes: représente que la liste chaînéeLRUest passée de la zoneancienneà la tête dujeunenuméro de zone de nœuds. 🎜🎜Il est à noter ici qu'un nœud aura la valeur dePages rendues jeunesuniquement lorsqu'il passera de la zoneancienneà la tête dujeune Ajoutez 1, c'est-à-dire si le nœud est déjà dans la zone <code>jeune, car il répond à l'exigence d'être derrière 1/4 dujeune. >, ce sera également la prochaine fois que vous visiterez cette page. Déplacez-la en tête de la zonejeune, mais ce processus ne provoque pas la valeur dePages rendues jeunes
Page rendue pas jeune : lorsque la valeur de innodb_old_blocks_time est définie sur supérieure à 0, la première visite ou la visite ultérieure d'un emplacement est ancienne Lorsqu'un nœud d'une région ne peut pas être déplacé vers la tête de la région <code>jeune car il ne respecte pas la limite d'intervalle de temps, la valeur de Page rendue non jeune sera augmenté de 1. 🎜🎜Il est à noter ici que pour un nœud dans la zone jeune, s'il n'est pas déplacé vers jeune car il est à 1/4 de la zone <code>jeune Area En-tête de région, un tel accès n'augmentera pas la valeur de Page rendue non jeune de 1. 🎜🎜🎜🎜youngs/s : Représente le nombre de nœuds déplacés de la zone old vers la tête de la zone young par seconde. 🎜🎜🎜🎜non-jeunes : représente chaque seconde qui ne peut pas être déplacée de la zone ancienne vers la tête de la zone jeune car le délai n'est pas respecté. 🎜🎜🎜🎜Pages lues, créées, écrites : représente le nombre de pages lues, créées et écrites. Suivi du rythme de lecture, de création et d’écriture. 🎜🎜🎜🎜Taux de réussite du pool de tampons : indique combien de fois la page a été mise en cache dans le Pool de tampons pour une moyenne de 1 000 visites de pages au cours de la période écoulée. 🎜🎜🎜🎜taux de création de jeunes : indique qu'au cours d'une certaine période de temps dans le passé, la page a été visitée en moyenne 1 000 fois, et combien de visites ont déplacé la page vers l'en-tête de la page. Quartier jeune . 🎜🎜Une chose à laquelle tout le monde doit prêter attention est que le nombre de fois où la page est déplacée vers la zone jeune comptée ici n'inclut pas seulement le déplacement depuis la zone ancienne. vers young Le nombre de fois en tête de la région code>, y compris le nombre de fois passés de la région young à la tête de la région young région (en visitant un nœud dans une région jeune, tant que le nœud est à 1/4 derrière la zone jeune, il sera déplacé vers la tête de la région quartier jeune). 🎜🎜🎜🎜pas (taux de création de jeunes) : indique qu'au cours d'une certaine période de temps dans le passé, la page a été visitée en moyenne 1 000 fois, et combien de visites n'ont pas déplacé la page au responsable de la zone jeune. 🎜🎜Une chose à laquelle tout le monde doit prêter attention est que le nombre de fois où la page n'est pas déplacée vers l'en-tête de la zone young compté ici n'inclut pas seulement les visites provoquées par la définition du innodb_old_blocks_time Variable système Nœuds dans la zone old mais non déplacés vers la zone young, notamment parce que le nœud se trouve dans le premier quart de la zone young Zone Le nombre de fois qu'il a été déplacé en tête de la zone jeune. 🎜🎜🎜🎜LRU len : représente le nombre de nœuds dans la Liste chaînée LRU. 🎜🎜🎜🎜unzip_LRU : Représente le nombre de nœuds dans la unzip_LRU linked list (comme nous n'avons pas parlé spécifiquement de cette liste chaînée, sa valeur peut être ignorée maintenant). 🎜🎜🎜🎜Somme E/S : Le nombre total de pages disque lues au cours des 50 dernières secondes. 🎜🎜🎜🎜I/O cur : Le nombre de pages du disque en cours de lecture. 🎜🎜🎜🎜Somme de décompression des E/S : Le nombre de pages décompressées au cours des 50 dernières secondes. 🎜🎜🎜🎜I/O unzip cur : Le nombre de pages en cours de décompression. 🎜总结
磁盘太慢,用内存作为缓存很有必要。
Buffer Pool本质上是InnoDB向操作系统申请的一段连续的内存空间,可以通过innodb_buffer_pool_size来调整它的大小。Buffer Pool向操作系统申请的连续内存由控制块和缓存页组成,每个控制块和缓存页都是一一对应的,在填充足够多的控制块和缓存页的组合后,Buffer Pool剩余的空间可能产生不够填充一组控制块和缓存页,这部分空间不能被使用,也被称为碎片。InnoDB使用了许多链表来管理Buffer Pool。free链表中每一个节点都代表一个空闲的缓存页,在将磁盘中的页加载到Buffer Pool时,会从free链表中寻找空闲的缓存页。为了快速定位某个页是否被加载到
Buffer Pool,使用表空间号 + 页号作为key,缓存页作为value,建立哈希表。在
Buffer Pool中被修改的页称为脏页,脏页并不是立即刷新,而是被加入到flush链表中,待之后的某个时刻同步到磁盘上。LRU链表分为young和old两个区域,可以通过innodb_old_blocks_pct来调节old区域所占的比例。首次从磁盘上加载到Buffer Pool的页会被放到old区域的头部,在innodb_old_blocks_time间隔时间内访问该页不会把它移动到young区域头部。在Buffer Pool没有可用的空闲缓存页时,会首先淘汰掉old区域的一些页。我们可以通过指定
innodb_buffer_pool_instances来控制Buffer Pool实例的个数,每个Buffer Pool实例中都有各自独立的链表,互不干扰。自
MySQL 5.7.5版本之后,可以在服务器运行过程中调整Buffer Pool大小。每个Buffer Pool实例由若干个chunk组成,每个chunk的大小可以在服务器启动时通过启动参数调整。-
可以用下边的命令查看
Buffer Pool的状态信息:SHOW ENGINE INNODB STATUS\G
推荐学习:mysql视频教程
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!