
Maison >base de données >Oracle >Création et utilisation d'index dans Oracle (partage de synthèse)
Création et utilisation d'index dans Oracle (partage de synthèse)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2021-12-31 18:53:5212158parcourir
Cet article vous apporte des connaissances pertinentes sur la création et l'utilisation d'index dans Oracle. J'espère qu'il vous sera utile.

Création d'index du système OLTP
Le rôle de la création d'index
1. En créant un index unique, l'unicité de chaque ligne de données dans la table de base de données peut être garantie.
2. Cela peut considérablement accélérer la récupération des données, ce qui est également la principale raison de la création d'un index.
3. Cela peut accélérer la connexion entre les tables, ce qui est particulièrement important pour atteindre l'intégrité référentielle des données.
4. Lors de l'utilisation de clauses de regroupement et de tri pour la récupération de données, le temps de regroupement et de tri dans les requêtes peut également être considérablement réduit.
5. En utilisant des index, vous pouvez utiliser des caches d'optimisation pendant le processus de requête pour améliorer les performances du système
Comment choisir les colonnes d'index
1) Caractéristiques des colonnes d'index qui doivent être construites
1) Colonnes qui doivent souvent l'être. recherché, peut accélérer la recherche ;
2) Sur la colonne qui est la clé primaire, appliquer l'unicité de la colonne et organiser la structure de disposition des données dans le tableau
3) Sur les colonnes souvent utilisées ; dans les connexions, ces colonnes sont principalement des clés étrangères qui peuvent accélérer la connexion ;
4) Créez un index sur la colonne qui doit souvent être recherchée en fonction de la plage, car l'index a été trié et de sa plage spécifiée ; est continu ;
5) Dans la colonne qui doit souvent être triée. Créez un index sur la colonne, car l'index a été trié, afin que la requête puisse utiliser le tri de l'index pour accélérer le temps de requête de tri ; 6) Créez un index sur la colonne qui est souvent utilisée dans la clause WHERE pour accélérer le jugement des conditions.
2. Caractéristiques des colonnes qui ne doivent pas être indexées
1) Les index ne doivent pas être créés pour les colonnes rarement utilisées ou référencées dans les requêtes. En effet, ces colonnes étant rarement utilisées, l’indexation ou non n’améliore pas la vitesse des requêtes. Au contraire, du fait de l’ajout d’index, la vitesse de maintenance du système est réduite et les besoins en espace sont augmentés.
2) Les index ne doivent pas être augmentés pour les colonnes avec peu de valeurs de données. En effet, comme ces colonnes ont très peu de valeurs, comme la colonne sexe de la table personnel, dans les résultats de la requête, les lignes de données du jeu de résultats représentent une grande proportion des lignes de données de la table, c'est-à-dire : les données qui doivent être recherchées dans le tableau La proportion de lignes est énorme. L'augmentation de l'index n'accélère pas significativement la récupération.
3) Les index ne doivent pas être ajoutés aux colonnes définies comme types de données blob. En effet, le volume de données de ces colonnes est soit assez important, soit très peu de valeurs.
4) Lorsque les performances de modification sont bien supérieures aux performances de récupération, l'index ne doit pas être créé. En effet, les performances de modification et les performances de récupération sont contradictoires. Lors de l'ajout d'index, les performances de récupération seront améliorées, mais les performances de modification seront réduites. Lors de la réduction des index, les performances de modification augmenteront et les performances de récupération diminueront. Par conséquent, lorsque les performances de modification sont bien supérieures aux performances de récupération, les index ne doivent pas être créés. (La quantité de données est énorme, pensez à créer un index de partition)
Syntaxe de création d'index
CREATEUNIUQE | BITMAP INDEX <schema>.<index_name> ON <schema>.<table_name> (<column_name> | <expression> ASC | DESC, <column_name> | <expression> ASC | DESC,...) TABLESPACE <tablespace_name> STORAGE <storage_settings> LOGGING | NOLOGGING COMPUTE STATISTICS NOCOMPRESS | COMPRESS<nn> NOSORT | REVERSE PARTITION | GLOBAL PARTITION<partition_setting>
Instructions associées
1) UNIQUE | BITMAP : spécifiez UNIQUE comme index de valeur unique, BITMAP comme index bitmap, omettez-le comme index de partition. Indice B-Tree.
2) f4c55dd52f1b37a9debd48ac1ff8dbb5 |41256fb142f22f4bfc3f76fe922f5535 ASC | DESC : plusieurs colonnes peuvent être indexées conjointement, lorsqu'il s'agit d'une expression, il s'agit d'un index basé sur une fonction
3) TABLESPACE : spécifiez l'espace table où se trouve l'index. stocké (index et C'est plus efficace lorsque la table d'origine n'est pas dans le même espace table)
4) STOCKAGE : Vous pouvez définir davantage les paramètres de stockage de l'espace table
5) LOGGING : S'il faut générer des journaux redo pour l'espace d'index (essayez d'utiliser NOLOGGING pour les grandes tables afin de réduire l'occupation et d'améliorer l'efficacité)
6) COMPUTESTATISTICS : collectez des informations statistiques lors de la création d'un nouvel index
7) NOCOMPRESS COMPRESSe3893df0bf62425a743f89f707bc0058 : s'il faut utiliser la "clé compression" (l'utilisation de la compression de clé peut supprimer les valeurs en double apparaissant dans une colonne clé)
8) NOSORT | REVERSE : NOSORT signifie créer l'index dans le même ordre que dans le tableau, REVERSE signifie stocker les valeurs d'index dans le ordre inverse
9) PARTITION | NOPARTITION : L'index créé peut être partitionné sur des tables partitionnées et non partitionnées
Malentendus dans l'utilisation des index
Index restreints
Les index restreints sont l'une des erreurs souvent commises par les développeurs inexpérimentés. Il existe de nombreux pièges dans SQL qui peuvent rendre certains index inutilisables. Certains problèmes courants sont abordés ci-dessous :
1. Utilisation de l'opérateur d'inégalité (a8093152e673feb7aba1828c43532094, !=) Même si la requête suivante a un index sur la colonne cust_rating, l'instruction de requête effectue toujours une analyse complète de la table. . select cust_Id,cust_name from customers wherecust_rating<> 'aa';
Remplacez l'instruction ci-dessus par l'instruction de requête suivante, afin que l'index soit utilisé lors de l'utilisation de l'optimiseur basé sur des règles au lieu de l'optimiseur basé sur les coûts (plus intelligent).
select cust_Id,cust_name fromcustomers where cust_rating<'aa' orcust_rating > 'aa';
Remarque spéciale : en remplaçant l'opérateur d'inégalité par une condition OR, vous pouvez utiliser un index pour éviter une analyse complète de la table.
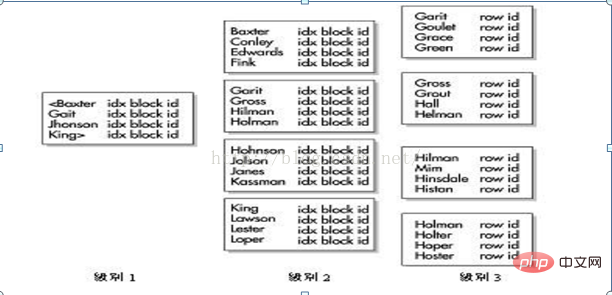
2. Utiliser IS NULL ou IS NOT NULLUtiliser ISNULL ou ISNOT NULL limitera également l'utilisation des index. Parce que la valeur NULL n'est pas définie. 在 SQL语句中使用NULL会有很多的麻烦。因此建议开发人员在建表时,把需要索引的列设成NOT NULL。如果被索引的列在某些行中存在NULL值,就不会使用这个索引(除非索引是一个位图索引,关于位图索引在稍后在详细讨论)。 3、使用函数 如果不使用基于函数的索引,那么在 SQL语句的 WHERE子句中对存在索引的列使用函数时,会使优化器忽略掉这些索引。 下面的查询不会使用索引(只要它不是基于函数的索引) 把上面的语句改成下面的语句,这样就可以通过索引进行查找。 4、比较不匹配的数据类型 也是比较难于发现的性能问题之一。 注意下面查询的例子,account_number是一个VARCHAR2类型,在 account_number字段上有索引。 下面的语句将执行全表扫描: Oracle 可以自动把 where子句变成to_number(account_number)=990354,这样就限 制了索引的使用,改成下面的查询就可以使用索引: 特别注意: 不匹配的数据类型之间比较会让Oracle自动限制索引的使用,即便对这个查询执行ExplainPlan也不能让您明白为什么做了一次―全表扫描。 5、查询索引 查 询 DBA_INDEXES视 图 可 得 到 表 中 所 有 索 引 的 列表 , 注 意 只 能 通 过USER_INDEXES的方法来检索模式(schema)的索引。访问 USER_IND_COLUMNS视图可得到一个给定表中被索引的特定列。 6、 组合索引 当某个索引包含有多个已索引的列时,称这个索引为组合(concatented)索引。在Oracle9i引入跳跃式扫描的索引访问方法之前,查询只能在有限条件下使用该索引。比如:表 emp 有一个组合索引键,该索引包含了 empno、 ename和 deptno。在Oracle9i之前除非在 where之句中对第一列(empno)指定一个值,否则就不能使用这个索引键进行一次范围扫描。 特别注意:在Oracle9i之前,只有在使用到索引的前导索引时才可以使用组合索引 Oracle提供了大量索引选项。知道在给定条件下使用哪个选项对于一个应用程序的性能来说非常重要。一个错误的选择可能会引发死锁,并导致数据库性能急剧下降或进程终止。而如果做出正确的选择,则可以合理使用资源,使那些已经运行了几个小时甚至几天的进程在几分钟得以完成,下面就将简单的讨论每个索引选项。 在这里讨论如下的索引类型: B树索引(默认类型) 位图索引 HASH索引 索引组织表索引 反转键(reverse key)索引 基于函数的索引 分区索引(本地和全局索引) 位图连接索引 B树索引在Oracle中是一个通用索引。在创建索引时它就是默认的索引类型。B树索引可以是一个列的(简单)索引,也可以是组合/复合(多个列)的索引。B树索引最多可以包括32列。 在下图的例子中,B树索引位于雇员表的last_name列上。这个索引的二元高度为3;接下来,Oracle会穿过两个树枝块(branch block),到达包含有ROWID的树叶块。在每个树枝块中,树枝行包含链中下一个块的ID号。 树叶块包含了索引值、ROWID,以及指向前一个和后一个树叶块的指针。Oracle可以从两个方向遍历这个二叉树。B树索引保存了在索引列上有值的每个数据行的ROWID值。Oracle不会对索引列上包含NULL值的行进行索引。如果索引是多个列的组合索引,而其中列上包含NULL值,这一行就会处于包含NULL值的索引列中,且将被处理为空(视为NULL)
技巧:索引列的值都存储在索引中。因此,可以建立一个组合(复合)索引,这些索引可以直接满足查询,而不用访问表。这就不用从中检索数据,从而减少了I/O量。 B-tree特点: 适合与大量的增、删、改(OLTP) 不能用包含OR操作符的查询; 适合高基数的列(唯一值多) 典型的树状结构; 每个结点都是数据块; 大多都是物理上一层、两层或三层不定,逻辑上三层; 叶子块数据是排序的,从左向右递增; 在分支块和根块中放的是索引的范围; 位图索引 位图索引非常适合于决策支持系统(Decision Support System,DSS)和数据仓库,它们不应该用于通过事务处理应用程序访问的表。它们可以使用较少到中等基数(不同值的数量)的列访问非常大的表。 尽管位图索引最多可达30个列,但通常它们都只用于少量的列。 例如,您的表可能包含一个称为Sex的列,它有两个可能值:男和女。这个基数只为2,如果用户频繁地根据Sex列的值查询该表,这就是位图索引的基列。当一个表内包含了多个位图索引时,您可以体会到位图索引的真正威力。如果有多个可用的位图索引,Oracle就可以合并从每个位图索引得到的结果集,快速删除不必要的数据。 Bitmapt特点: 适合与决策支持系统;做 UPDATE代价非常高 非常适合 OR操作符的查询;基数比较少的时候才能建位图索引; 技巧:对于有较低基数的列需要使用位图索引。性别列就是这样一个例子,它有两个可能值:男或女(基数仅为2)。位图对于低基数(少量的不同值)列来说非常快,这是因为索引的尺寸相对于B树索引来说小了很多。因为这些索引是低基数的 B 树索引,所以非常小,因此您可以经常检索表中超过半数的行,并且仍使用位图索引。 当大多数条目不会向位图添加新的值时,位图索引在批处理(单用户)操作中加载表(插入操作)方面通常要比B树做得好。当多个会话同时向表中插入行时不应该使用位图索引,在大多数事务处理应用程序中都会发生这种情况。 示例 下面来看一个示例表PARTICIPANT,该表包含了来自个人的调查数据。列Age_Code、Income_Level、Education_Level和Marital_Status都包括了各自的位图索引。 下图显示了每个直方图中的数据平衡情况,以及对访问每个位图索引的查询的执行路径。图中的执行路径显示了有多少个位图索引被合并,可以看出性能得到了显著的提高。
如上图图所示,优化器依次使用4个单独的位图索引,这些索引的列在WHERE子句中被引用。每个位图记录指针(例如0或1),用于示表中的哪些行包含位图中的已知值。有了这些信息后,Oracle就执行BITMAP AND操作以查找将从所有4个位图中返回哪些行。该值然后被转换为ROWID值,并且查询继续完成剩余的处理工作。注意,所有4个列都有非常低的基数,使用索引可以非常快速地返回匹配的行。 技巧:在一个查询中合并多个位图索引后,可以使性能显著提高。位图索引使用固定长度的数据类型要比可变长度的数据类型好。较大尺寸的块也会提高对位图索引的存储和读取性能。 下面的查询可显示索引类型。 B 树索引作为NORMAL列出;而位图索引的类型值为BITMAP。 技巧:如果要查询位图索引列表,可以在USER_INDEXES视图中查询index_type列。 建议不要在一些联机事务处理(OLTP)应用程序中使用位图索引。B树索引的索引值中包含ROWID,这样Oracle就可以在行级别上锁定索引。位图索引存储为压缩的索引值,其中包含了一定范围的ROWID,因此Oracle必须针对一个给定值锁定所有范围内的ROWID 这种锁定类型可能在某些DML语句中造成死锁。SELECT语句不会受到这种锁定问题的影响。 位图索引的使用限制: 基于规则的优化器不会考虑位图索引。 当执行 ALTER TABLE语句并修改包含有位图索引的列时,会使位图索引失效。位图索引不包含任何列数据,并且不能用于任何类型的完整性检查。位图索引不能被声明为唯一索引。位图索引的最大长度为30。 Astuce : n'utilisez pas d'index bitmap dans des environnements OLTP lourds. L'utilisation d'index HASH nécessite l'utilisation d'un cluster HASH. Lorsqu'un cluster ou un cluster HASH est établi, une clé de cluster est également définie. Cette clé indique à Oracle comment stocker la table dans le cluster. Lors du stockage des données, toutes les lignes liées à cette clé de cluster sont stockées sur un bloc de base de données. Si les données sont toutes stockées sur le même bloc de base de données et que l'index HASH est utilisé comme correspondance exacte dans la clause WHERE, Oracle peut accéder aux données en exécutant une fonction HASH et des E/S - au lieu d'utiliser une hauteur binaire Pour accéder aux données à l'aide d'un index B-tree de 4, vous devez utiliser 4 E/S lors de la récupération des données. Comme le montre la figure ci-dessous, la requête est une requête équivalente pour faire correspondre la colonne HASH et la valeur exacte. Oracle peut rapidement utiliser cette valeur pour déterminer l'emplacement de stockage physique de la ligne en fonction de la fonction HASH. L'index HASH est peut-être le moyen le plus rapide d'accéder aux données de la base de données, mais il présente également ses propres inconvénients. Le nombre de valeurs distinctes sur la clé du cluster doit être connu avant de créer un cluster HASH. Cette valeur doit être spécifiée lors de la création d'un cluster HASH. Sous-estimer le nombre de valeurs de clés de cluster différentes peut provoquer des conflits de cluster (deux clés de cluster avec la même valeur de hachage). Ce type de conflit nécessite beaucoup de ressources. Les conflits peuvent provoquer un débordement du tampon utilisé pour stocker des lignes supplémentaires, ce qui entraîne des E/S supplémentaires. Si le nombre de valeurs de hachage différentes a été sous-estimé, vous devez modifier cette valeur après avoir reconstruit le cluster. La commande ALTER CLUSTER ne peut pas modifier le nombre de clés HASH. Les clusters HASH peuvent également gaspiller de l'espace. Si vous ne parvenez pas à déterminer la quantité d'espace requise pour conserver toutes les lignes d'une clé de cluster, vous risquez de perdre de l'espace. Si un espace supplémentaire ne peut pas être alloué pour la croissance future du cluster, un cluster HASH n'est peut-être pas le meilleur choix. Si l'application effectue fréquemment des analyses complètes de la table en cluster, le clustering HASH n'est peut-être pas le meilleur choix. Les analyses de table complètes peuvent être très gourmandes en ressources en raison de la nécessité d'allouer l'espace restant dans le cluster pour une croissance future. Soyez prudent avant d'implémenter le cluster HASH. Vous devez examiner attentivement l'application pour vous assurer que vous comprenez bien les tables et les données avant de mettre en œuvre cette option. Généralement, HASH est très efficace pour certaines données statiques contenant des valeurs ordonnées. Astuces : les index HASH sont très utiles lorsqu'il y a des restrictions (nécessité de spécifier une certaine valeur plutôt qu'une plage de valeurs)
Les tables organisées en index modifieront la structure de stockage de la table en une structure B-tree et trieront par la clé primaire de la table. Cette table spéciale, comme d'autres types de tables, peut exécuter toutes les instructions DML et DDL de la table. En raison de la structure particulière du tableau, ROWID n'est pas associé aux lignes du tableau. Pour certaines instructions impliquant des correspondances exactes et des recherches par plage, les tables organisées en index fournissent un mécanisme d'accès rapide aux données basé sur des clés. Les performances des instructions UPDATE et DELETE basées sur les valeurs de clé primaire sont également améliorées car les lignes sont physiquement ordonnées. Étant donné que les valeurs des colonnes clés ne sont pas répétées dans la table et l'index, l'espace requis pour le stockage est également réduit. Si les données ne sont pas fréquemment interrogées sur la colonne de clé primaire, vous devrez créer des index secondaires sur d'autres colonnes de la table organisée en index. Les applications qui n'interrogent pas fréquemment une table en fonction de sa clé primaire ne bénéficieront pas de tous les avantages de l'utilisation d'un index pour organiser une table. Pour les tables auxquelles on accède toujours via une correspondance exacte de la clé primaire ou une analyse de plage, envisagez d'utiliser un index pour organiser la table. Astuce : Vous pouvez créer un index secondaire sur une table organisée en index. Lors du chargement de certaines données triées, l'index rencontrera certainement des goulots d'étranglement liés aux E/S. Lors du chargement des données, certaines parties de l'index et du disque seront forcément utilisées beaucoup plus fréquemment que d'autres. Pour résoudre ce problème, l'espace table d'index peut être stocké sur une architecture de disque capable de diviser physiquement les fichiers sur plusieurs disques. Pour résoudre ce problème, Oracle propose également une méthode pour inverser l'index clé. Si les données sont stockées avec un index à clé inversé, les valeurs des données seront à l'opposé des valeurs initialement stockées. De cette manière, les données 1234, 1235 et 1236 sont stockées sous les noms 4321, 5321 et 6321. Le résultat est que l'index met à jour un bloc d'index différent pour chaque ligne nouvellement insérée. Astuce : Si vous disposez d'une capacité de disque limitée et que vous effectuez un grand nombre de chargements ordonnés, vous pouvez utiliser l'indexation par clé inversée. Vous ne pouvez pas utiliser d'index à clé inversée avec des index bitmap ou des tables organisées en index. Parce que les index bitmap et les tables organisées en index ne peuvent pas être inversés. Vous pouvez créer des index basés sur des fonctions dans des tableaux. Sans index basé sur une fonction, toute requête qui exécute une fonction sur une colonne ne peut pas utiliser l'index sur cette colonne. Par exemple, la requête suivante ne peut pas utiliser un index sur la colonne JOB sauf s'il s'agit d'un index basé sur une fonction : 下面的查询使用 JOB列上的索引,但是它将不会返回JOB列具有Mgr或mgr值的行: 可以创建这样的索引,允许索引访问支持基于函数的列或数据。可以对列表达式 UPPER(job)创建索引,而不是直接在JOB列上建立索引,如: 能限制在这个列上使用的函数吗?如果能,能限制所有在这个列上执行的所有函数吗?是否有足够应付额外索引的存储空间?在每列上增加的索引数量会对针对该表执行的DML语句的性能带来何种影响? 基于函数的索引非常有用,但在实现时必须小心。在表上创建的索引越多,INSERT、UPDATE和DELETE语句的执行就会花费越多的时间。 注意:对于优化器所使用的基于函数的索引来说,必须把初始参数QUERY_REWRITE _ ENABLED 设定为 TRUE。 示例: 分区索引就是简单地把一个索引分成多个片断。通过把一个索引分成多个片断,可以访问更小的片断(也更快),并且可以把这些片断分别存放在不同的磁盘驱动器上(避免I/O问题)。 B树和位图索引都可以被分区,而HASH索引不可以被分区。可以有好几种分区方法:表被分区而索引未被分区;表未被分区而索引被分区;表和索引都被分区。 不管采用哪种方法,都必须使用基于成本的优化器。分区能够提供更多可以提高性能和可维护性的可能性有两种类型的分区索引:本地分区索引和全局分区索引。 每个类型都有两个子类型,有前缀索引和无前缀索引。表各列上的索引可以有各种类型索引的组合。如果使用了位图索引,就必须是本地索引。 把索引分区最主要的原因是可以减少所需读取的索引的大小,另外把分区放在不同的表空间中可以提高分区的可用性和可靠性。在使用分区后的表和索引时,Oracle还支持并行查询和并行DML。这样就可以同时执行多个进程,从而加快处理这条语句。
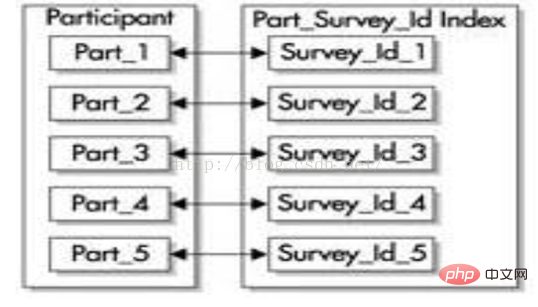
可以使用与表相同的分区键和范围界限来对本地索引分区。每个本地索引的分区只包含了它所关联的表分区的键和ROWID。本地索引可以是B树或位图索引。如果是 B树索引,它可以是唯一或不唯一的索引。 这种类型的索引支持分区独立性,这就意味着对于单独的分区,可以进行增加、截取、删除、分割、脱机等处理,而不用同时删除或重建索引。Oracle自动维护这些本地索引。本地索引分区还可以被单独重建,而其他分区不会受到影响。 (1) 有前缀的索引 有前缀的索引包含了来自分区键的键,并把它们作为索引的前导。例如,让我们再次回顾 participant表。在创建该表后,使用survey_id和survey_date这两个列进行范围分区,然后在survey_id列上建立一个有前缀的本地索引,如下图所示。这个索引的所有分区都被等价划分,就是说索引的分区都使用表的相同范围界限来创建。
技巧:本地的有前缀索引可以让Oracle快速剔除一些不必要的分区。也就是说
(2) Index sans préfixe L'index sans préfixe n'utilise pas la première colonne de la clé de partition comme première colonne de l'index. Si vous utilisez la même table partitionnée avec les mêmes clés de partition (survey_id et Survey_date), l'index construit sur la colonne Survey_date est un index local sans préfixe, comme le montre la figure ci-dessous. Un index local sans préfixe peut être créé sur n'importe quelle colonne de la table, mais chaque partition de l'index ne contient que les valeurs clés de la partition correspondante de la table. Si vous souhaitez définir un index sans préfixe comme index unique, l'index doit contenir un sous-ensemble de la clé de partition.
Dans cet exemple, nous devons combiner les colonnes contenant ou (
分区的、全局有前缀索引
( 2) 无前缀的索引
位图连接索引是基于两个表的连接的位图索引,在数据仓库环境中使用这种索引改进连接维度表和事实表的查询的性能。创建位图连接索引时,标准方法是 连接索引中常用的维度表和事实表。当用户在一次查询中结合查询事实表和维度表时,就不需要执行连接,因为在位图连接索引中已经有可用的连接结果。通过压缩位图连接索引中的ROWID进一步改进性能,并且减少访问数据所需的I/O数量。 创建位图连接索引时,指定涉及的两个表。相应的语法应该遵循如下模式: 位图连接的语法比较特别,其中包含 FROM子句和WHERE子句,并且引用两个单独的表。索引列通常是维度表中的描述列——就是说,如果维度是 CUSTOMER,并且它的主键是CUSTOMER_ID,则通常索引Customer_Name 这样的列。如果事实表名为 SALES,可以使用如下的命令创建索引: 如果用户接下来使用指定 Customer_Name列值的WHERE子句查询 SALES和CUSTOMER表,优化器就可以使用位图连接索引快速返回匹配连接 条件和 Customer_Name条件的行。 位图连接索引的使用一般会受到限制: 1) 只可以索引维度表中的列。 2) 用于连接的列必须是维度表中的主键或唯一约束;如果是复合主键,则 必须使用连接中的每一列。 3) 不可以对索引组织表创建位图连接索引,并且适用于常规位图索引的限 制也适用于位图连接索引。
注意:以上总结是对oracle数据库中索引创建的一些知识的介绍和关键点。需要读懂理解之后结合系统业务情况合理创建索引,以求达到预期性能。 本文部分内容摘自《Oracle超详细讲解.pdf》 推荐教程:《Oracle教程》select empno,ename,deptno from emp where trunc(hiredate)='01-MAY-81';
select empno,ename,deptno from emp where hiredate<(to_date('01-MAY-81')+0.9999);
select bank_name,address,city,state,zip from banks whereaccount_number = 990354;
select bank_name,address,city,state,zip from banks where account_number='990354';
索引分类
B树索引 (默认类型)

SQL> select index_name, index_type from user_indexes;
INDEX_NAME INDEX_TYPE
------------------------------ ----------------------
TT_INDEX NORMAL
IX_CUSTADDR_TP NORMAL
Index HASH
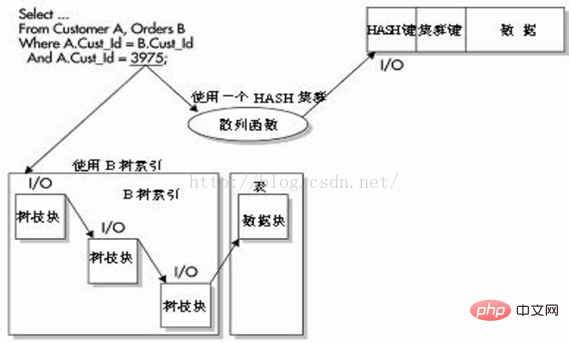
Table organisée d'index
Index de clé inversé
Index basés sur des nombres
select * from emp where UPPER(job) = 'MGR';
select * from emp where job = 'MGR';
create index EMP$UPPER_JOB on emp(UPPER(job));尽管基于函数的索引非常有用,但在建立它们之前必须先考虑下面一些问题:
select count(*) from sample where ratio(balance,limit) >.5;
Elapsed time: 20.1 minutes
create index ratio_idx1 on sample (ratio(balance, limit));
select count(*) from sample where ratio(balance,limit) >.5;
Elapsed time: 7 seconds!!!
分区索引
本地分区索引(通常使用的索引)
没有包含 WHERE条件子句中任何值的分区将不会被访问,这样也提高了语句
的性能。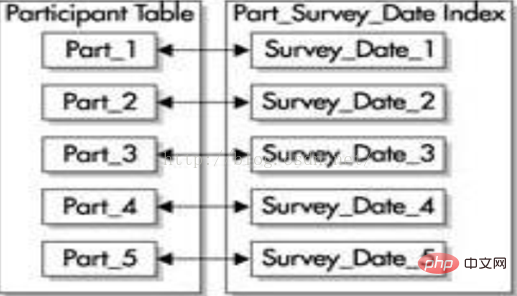 survey et
survey et
Tant que survey_id n'est pas la première colonne de l'index, c'est un index avec un préfixe ).
Astuce : Pour un index unique sans préfixe, il doit contenir un sous-ensemble de la clé de partition. Un index partitionné global contient les clés de plusieurs partitions de table dans une seule partition d'index. La clé de partition d'un index partitionné global est une plage de valeurs distincte ou spécifiée dans la table partitionnée. Lors de la création d'un index partitionné global, la plage et la valeur de la clé de partition doivent être définies. L'index global ne peut être qu'un index B-tree. Oracle ne gère pas les index partitionnés globaux par défaut. Si une partition est tronquée, ajoutée, divisée, supprimée, etc., l'index de partition global doit être reconstruit sauf si la clause UPDATE GLOBAL INDEXES de la commande ALTER TABLE est spécifiée lors de la modification de la table. (2) Index préfixés En règle générale, les index préfixés globaux ne sont pas partitionnés en homologues dans la table sous-jacente. Il n'y a aucun facteur qui limite le partitionnement homologue d'un index, mais Oracle ne tirera pas pleinement parti du partitionnement homologue lors de la génération de plans de requête ou de l'exécution d'opérations de maintenance de partition. Si l'index est partitionné entre homologues, il doit être créé en tant qu'index local afin qu'Oracle puisse le conserver et l'utiliser pour supprimer les partitions inutiles, comme illustré dans la figure ci-dessous. Dans ce diagramme, chacune des 3 partitions d'index contient des entrées d'index qui pointent vers des lignes dans plusieurs partitions de table.
技巧:如果一个全局索引将被对等分区,就必须把它创建为一个本地索引,
这样 Oracle可以维护这个索引,并使用它来删除不必要的分区。
Oracle不支持无前缀的全局索引。位图连接索引
create bitmap index FACT_DIM_COL_IDX on FACT(DIM.Descr_Col) from
FACT, DIM where FACT.JoinCol = DIM.JoinCol;
create bitmap index SALES_CUST_NAME_IDX
on SALES(CUSTOMER.Customer_Name) from SALES, CUSTOMER
where SALES.Customer_ID=CUSTOMER.Customer_ID;
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!